

1.前言
隨着 征程 6 芯片家族的陣容不斷壯大,算法工具鏈在量化精度方向的優化也在持續深入,具體體現在兩個方面:
- 征程 6P 與 征程 6H 工具鏈已陸續進入發佈和試用階段,在此背景下,QAT(量化感知訓練)需要以更高效的方式適配算子的浮點計算能力,以確保量化精度和用户的使用體驗;
- MatMul、Conv、Linear 等 Gemm 類算子目前已正式支持雙 int16 輸入,這一改進有助於提升相關算子在量化計算時的精度和調優時的效率。
為了更全面、穩妥地支持上述新功能,同時對當前的 qconfig 量化配置以及回退邏輯進行優化升級,工具鏈從 OE3.5.0 開始支持新版 qconfig 量化模板。新版本針對 qconfig 模板開展了大量的重構工作,重構後的 qconfig 模板不僅能更好地適配新的芯片特性和算子功能,還同時保持對舊版本 qconfig 的維護,保障了用户在升級過程中的平滑過渡,減少了因版本迭代帶來的適配成本。
2.新版 qconfig 模板配置流程
本章將系統且全面地為大家呈現新版 qconfig 模板的核心內容,涵蓋其關鍵更新點、規範的基本使用流程以及對相關產出物的詳細介紹。
2.1 主要更新點
在更新點方面,新版 qconfig 模板的迭代升級緊密貼合 征程 6 平台家族的持續發展以及工具鏈不斷優化的實際需求,通過針對性的設計與調整,進一步提升了量化配置的效率、靈活性與適配性。其與舊版流程的區別主要體現在以下四個方面:
- 模板與回退機制的統一管理:將模板和回退進行了統一,在同一個流程下管理;
- 強化對特定量化配置的友好性:對浮點計算的量化配置、Conv/Matmul 等 Gemm 算子單/雙 int16 輸入配置更加友好;
- fuse 默認行為的調整與優化:舊模板默認 conv-bn-add-relu 全部 fuse,然後再根據硬件限制回退至 int8。為了實現更高的計算精度,新模板首先配置 dtype,若不符合要求則不做 fuse,最終 dtype 結果更加符合預期,而且針對不同芯片架構的硬件特性設計了不同的 fuse 行為;
- 新增量化配置文件保存功能:支持保存量化配置文件
qconfig_dtypes.pt、qconfig_dtypes.pt.py以及qconfig_changelogs.txt。其中,qconfig_dtypes.pt為可供用户加載的算子級別的量化配置文件,實現了配置的便捷遷移與共享;qconfig_dtypes.pt.pyqconfig_changelogs.txt則記錄了配置過程中的算子變更日誌,包括量化參數調整記錄、模板使用信息等,為配置的追溯、調試提供了清晰的依據,進一步提升了量化配置的可解釋性與可複用性。
2.2 基本使用流程
新版 qconfig 模板在使用流程上圍繞基礎 qconfig 配置 reference\_qconfig、templates 量化模板配置展開,各環節緊密關聯,共同助力用户實現高效、精準的量化配置。新版 qconfig 模板的基本使用流程如下所示:
import torch
import torch.nn as nn
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.dtype import qint8,qint16
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization.observer_v2 import MinMaxObserver,MSEObserver,FixedScaleObserver
my_qconfig_setter=QconfigSetter(
#1.基礎qconfig,獲取默認配置和observer
reference_qconfig=get_qconfig(observer=MSEObserver),
#2.模板,僅關注dype,按照順序生效,前面模板的配置可被後面的模板覆蓋。因此模板的順序很重要
templates=[
...
],
#3.採用默認的優化模板
enable_optimize=True,
#4.qconfig模板配置文件保存路徑
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)以上就是新版 qconfig 模板的基本使用流程,下面將對其核心部分 QconfigSetter 接口和工具鏈提供的多個 templates 進行介紹。
2.2.1 QconfigSetter 接口介紹
QconfigSetter 接口的定義如下所示:
代碼路徑:horizon_plugin_pytorch/quantization/qconfig_setter/qconfig_setter.py
class QconfigSetter(ModernQconfigSetterBase):
"""Manage qconfig settings of a model.
Args:
reference_qconfig: Qconfig to provide observer.
templates: Qconfig templates, will be applyed in order.
enable_optimize: Whether enable the default optimize.
save_dir: Save directory of qconfig settings.
custom_qconfig_mapping: Custom mapping from mod name to qconfig.
CAUTION: This mapping will overwrite the dtype setted by templates.
You'd better not change dtype through this argument, or
the config result will not be optimal (Model may contain
CPU ops on board, for example).
Defaults to None.
enable_attribute_setting: Whether enable the qconfig setted through
qconfig attribute.
enable_propagate: Whether enable propagate for custom_qconfig_mapping
and qconfig attr. Defaults to False.
"""
def __init__(
self,
reference_qconfig: QConfig,
templates: Sequence[TemplateBase],
enable_optimize: bool = True,
save_dir: str = "./qconfig_setting",
custom_qconfig_mapping: Optional[Dict[str, QConfig]] = None,
enable_attribute_setting: bool = False,
enable_propagate: bool = False,
):
super().__init__(reference_qconfig)
self.templates = list(templates)
self.enable_optimize = enable_optimize
self.save_dir = save_dir
if custom_qconfig_mapping is None:
custom_qconfig_mapping = {}
self.custom_qconfig_mapping = {
k: canonicalize_qconfig(v)
for k, v in custom_qconfig_mapping.items()
}
self.enable_attribute_setting = enable_attribute_setting
self.enable_propagate = enable_propagate
if save_dir is not None:
os.makedirs(save_dir, exist_ok=True)- reference\_qconfig【必要配置】:配置 observer,可選項包括 MSEObserver 、MinMaxObserver 等。
- templates【必要配置】:配置使用到的 qconfig 模板,僅關注 dtype,按照順序依次生效。
-
enable\_optimize【必要配置-用户可不關注】: 是否採用默認的優化 pass,默認配置為 True,相關優化如下:
-
CanonicalizeTemplate: 按算子類型對 dtype 配置進行合法化,當前默認規則有:- Gemm 類算子輸入不支持 float
- 插值類算子:在不同 march 下有不同的限制
- DPP、RPP 等特殊算子僅支持 int8
- 其他算子的通用規則:算子的 input dtype 和 output dtype 不能同時存在 qint 和 float
-
EqualizeInOutScaleTemplate:對於 relu,concat,stack 算子,應該在算子輸出統計 scale,否則精度或性能存在損失。為此:- 將前面算子的 output dtype 配置為 float32
- Relu,concat,stack 算子在 export hbir 時,在 input 處插入偽量化,scale 複用 output scale
FuseConvAddTemplate:硬件支持 conv + add 的 fuse,不同的芯片架構的融合條件不一致,滿足融合條件會有以下行為:- 將 conv 的 output dtype 配置為 float32
- 將 add 對應的 input dtype 配置為 float32
GridHighPrecisionTemplate:根據經驗,grid sample 的 grid 計算過程用 qint8 精度不夠,因此自動將相關算子配置為 qint16 計算。InternalQuantsTemplate:模型分段部署場景下,會在分段點處插入 QuantStub,用於記錄此處的 dtype 和 scale,此類 QuantStub 的 dtype 配置必須和輸入保持一致。OutputHighPrecisionTemplate:當 Gemm 類算子作為模型輸出時,將其配置為高精度輸出。PropagateTemplate:對於拆分為子圖實現的算子,存在經驗性配置,如LayerNorm和Softmax內部小算子應該使用高精度。-
SimpleIntPassTemplate:性能優化,對於 op0->op1->op2 此類計算圖,若以下條件同時成立,則將 op1 輸出類型修改為 int:- op2 需要 int 輸入
- op0 可以輸出 int
-
op1 當前輸出為 float16,且屬於以下類型
- cat, stack
- mul\_scalar
- 無精度風險的查表算子(即在 fp16 上默認使用查表實現的算子)
SimplifyTemplate:刪除多餘的量化節點配置(將對應的 dtype 修改為 None)
進一步的説明可以參考用户手冊<u>【Qconfig 詳解】</u>。
-
- save\_dir【必要配置】:量化配置文件保存的路徑。
2.2.2 templates 介紹
horizon_plugin_pytorch 中提供了比較齊全的量化配置 templates 供用户使用,下面將逐一對這些模板進行介紹:
- ModuleNameTemplate(必要配置):通過 module name 指定 dtype 配置或量化閾值,包括激活/weight 量化配置,固定 scale 配置;配置粒度支持全局、模型片段和算子等;配置 dtype 包括 qint8、qint16、torch.float16、torch.float32 等,相關配置項可以參考用户手冊<u>【Qconfig 詳解】</u>;
- MatmulDtypeTemplate(必要配置):通過名稱或前綴配置 Matmul 算子單 int16/雙 int16 輸入,支持批量配置,相關配置項可以參考用户手冊<u>【Qconfig 詳解】</u>;
- ConvDtypeTemplate(必要配置):通過名稱或前綴配置 Conv/Linear 算子單 int16/雙 int16 輸入,支持批量配置,相關配置項可以參考用户手冊<u>【Qconfig 詳解】</u>;
- SensitivityTemplate(可選配置):通過量化敏感度列表提升數據類型精度,默認將敏感算子配置為 int16,支持激活敏感和 weight 敏感算子分別配置高精度,相關配置項可以參考用户手冊<u>【Qconfig 詳解】</u>。
- LoadFromFileTemplate:從
qconfig_dtypes.pt文件中加載量化配置,僅可加載全局及每個算子的量化類型,暫時無法加載 fix\_scale 配置,且不支持對 qconfig 進行修改。而且需要注意,此時 enable\_optimize 必須配置為 False,否則無法保證配置結果的正確性,部署時可能存在 CPU 算子。
用户配置的模板按順序生效,前面模板的配置會被後面的模板覆蓋。
一般來説,用户會使用到 ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate 和 SensitivityTemplate 這 4 個模板,其中前 3 個模板為必要配置。以下是 templates 的常用配置,如下所示:
from horizon_plugin_pytorch.quantization.qconfig_setter import *
import torch
#加載精度debug工具產出的敏感度列表
table1=torch.load("xxx_optput1_L1.pt")
table2=torch.load("xxx_optput2_L1.pt")
templates=[
#1. 基礎配置部分
ModuleNameTemplate({"":qint8}), #全局feat int8,此時weight 默認為int16
#conv類算子的 input配置為 int8,weight配置為int8
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
#matmul類算子兩個輸入均配置為 int8
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{"quant":{"dtype":qint8,"threshold":1.0}},#quant int8,固定scale,配置
),
#2. Matmul 單/雙int16輸入配置
MatmulDtypeTemplate(
input_dtypes=[qint8/qint16,qint8/qint16],
prefix=["head","xxxxx"]#prefix中配置的名稱與torch.nn.Module.name_module()返回的一致
),
#3.Conv 單/雙int16輸入配置
ConvDtypeTemplate(
input_dtype=qint8/qint16,
weight_dtype=qint8/qint16,
prefix= ["backbone","xxxxx"],#prefix中配置的名稱與torch.nn.Module.name_module()返回的一致
),
# 4. 敏感度模板配置
#配置top10 weight敏感的算子為int16
SensitivityTemplate(
sensitive_table=table1,#精度debug工具產出的敏感度列表
topk_or_ratio=10, #配置整數的時候是topk,小數的時候是ratio
sensitive_type= 'weight',#只配置weight敏感的算子,還可以選擇 'activation'、 'both',默認是both
),
#配置50%激活敏感的算子為int16
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.5, #配置整數的時候是topk,小數的時候是ratio
sensitive_type= 'activation',#配置激活敏感的算子
),
]2.3 產出物介紹
在完成新版 qconfig 模板配置並執行 prepare 操作後,工具鏈將自動生成並保存 5 個文件,分別為 model_check_result.txt、fx_graph.txt、qconfig_changelogs.txt、qconfig_dtypes.pt.py 及 qconfig_dtypes.pt,各文件功能與技術細節如下:
model_check_result.txt、fx_graph.txt:二者均由prepare接口自動生成,model_check_result.txt中包括未 fuse 的 pattern、每個 op 輸出/weight 的 qconfig 配置、異常 qconfig 配置提示等,fx_graph.txt保存的是模型的 fx trace 圖;qconfig_dtypes.pt.py和qconfig_dtypes.pt:為QconfigSetter接口輸出的量化配置載體,完整記錄全局及算子級別的量化精度參數,包括每個算子的 input、weight 和 output 的量化精度,如 qint8、qint16 和 torch.float16 等,其中。py 文件供用户閲讀,。pt 文件可以使用LoadFromFileTemplate接口加載,qconfig_dtypes.pt.py中信息如下所示;
{
#算子級別量化配置
'backbone.conv1.conv1_1.conv': {'input': None, 'weight': 'qint8', 'output': None}, 'backbone.conv1.conv1_1.act': None,
'backbone.conv1.conv1_2.conv': {'input': torch.float32, 'weight': torch.float32, 'output': None},
'backbone.conv1.conv1_2.act': {'input': None, 'weight': None, 'output': 'qint16'}
...
}qconfig_changelogs.txt:每個算子 qconfig 根據 Templates 的變化邏輯,頁面如下所示:
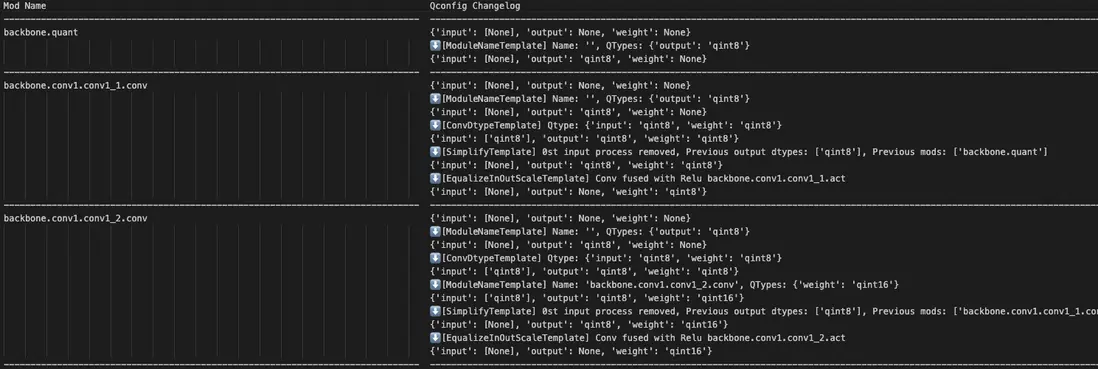
3. 使用示例
本章節將會提供上述模板的使用方法以及在典型場景下的配置示例。
3.1 配置全局 fp16/int16/int8
3.1.1 配置全局 int8
配置全局 qconfig 時必須要配置 ModuleNameTemplate、ConvDtypeTemplate、MatmulDtypeTemplate 這 3 個模板,以下為使用示例:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.qconfig_template import ModuleNameQconfigSetter,
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.全部算子配置為 int8 輸出
ModuleNameTemplate({"":qint8}),
#2.conv 的 input配置為 int8,weight配置為int8
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
#3.matmul 兩個輸入均配置為 int8
MatmulDtypeTemplate(input_dtypes=qint8),
],
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)配置全局 int16 的方式與全局 int8 類似,將上述示例中的 qint8 修改為 qint16 即可。
注意:
- 配置全局 feat 為 int8/int16/fp16 的時候必須要對 Conv 類算子的 weight 進行配置,否則 weight 會自動做 int16 計算,並可能出現不符合預期的 CPU 算子;
- 配置全局 int8 後,model\_check\_result.txt 可能會顯示模型中仍然存在 int16 計算的算子,這是工具為了提升量化精度做的自動化行為,比如 norm 這種進行拆分實現的算子,內部採用 int16 較高精度的計算,然後輸出為 int8。
3.1.2 配置全局 feature int16+weight int8+prefix 批量配置
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.配置全局feat int16,weight int8
ModuleNameTemplate({"":qint16}),
ConvDtypeTemplate(input_dtype=qint16, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint16),
#2.配置backbone部分全int8
ModuleNameTemplate({"backbone":qint8}),
MatmulDtypeTemplate(
input_dtypes=[qint8,qint8],
prefix=["backbone"]
),
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
prefix= ["backbone"],
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.2 fixscale 配置
模型中的某些地方很難依靠統計的方式獲得最佳的量化 scale,比如物理量,此時當算子的輸出值域確定時就可以設置 fixed scale。新版 qconfig 模板配置 fixed scale 的方式為配置輸入/輸出的量化類型“dtype”和閾值“threshold”,其中 scale 的計算為:

其中 threshold 一般為算子輸入/輸出的絕對值的最大值;n 則為量化位寬,比如 int8 量化位寬 n=8。
如下為配置 quantstub 算子輸出 scale 和 conv 算子輸入 scale 的示例:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 配置全局int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{
#2.fixscale:配置算子輸出的dtype和threshold,此時scale=1/128=0.0078125
"backbone.quant":{"dtype":qint8,"threshold":1.0},
#3.fixscale:配置conv的weight輸入為fix_scale的int16量化,
#scale=1/32768=3.0518e-05
"backbone.conv1.conv1_2.conv":{"dtype": {"weight": qint16}, "threshold": {"weight": 1.0}},
},
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)通過 prepare 後生成的 model_check_result.txt 可以驗證配置是否生效:
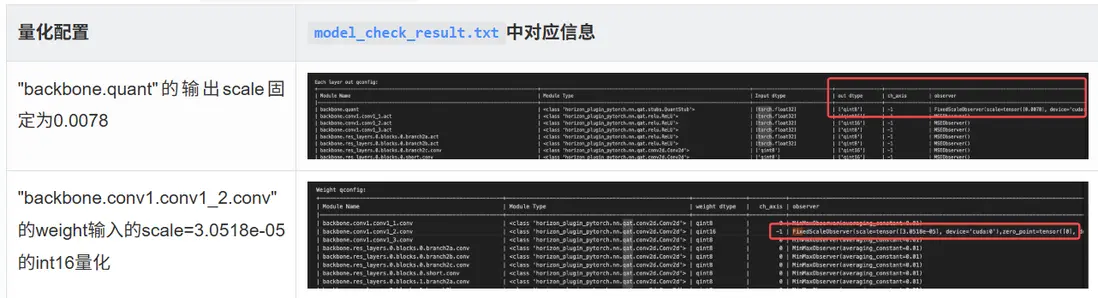
3.3 批量配置 conv/matmul 單/雙 int16 輸入
ConvDtypeTemplate 和 MatmulDtypeTemplate 支持單/雙 int16 輸入的批量配置,相關示例如下:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基礎配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.Conv 單int16輸入配置:將激活輸入為int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint16,
weight_dtype=qint8,
prefix= ["backbone.res_layers.0","encoder.encoder.0.layers.0"],
),
#3.Conv 單int16輸入配置:將weight配置int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_2.conv"],
),
#4.Conv 雙int16輸入配置(按需配置)
ConvDtypeTemplate(
input_dtype=qint16,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_1.conv"],
),
#5.matmul單int16配置:將第0個輸入配置為int8,第1個輸入配置成int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint8,qint16],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul","encoder.encoder.1.layers.0.self_attn.matmul"]
),
#6.matmul單int16配置:第0個輸入配置成int16,將第1個輸入配置為int8(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.1.self_attn.matmul"]
),
#7.matmul雙int16配置:將2個輸入都配置為雙int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint16],
prefix=["encoder.encoder.0.layers.2.self_attn.matmul"]
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.4 LoadFromFileTemplate 使用示例
當從舊模板遷移到新的 qconfig 量化模板時,推薦的做法是先把舊版本的量化配置 qconfig\_dtypes.pt 保存下來,然後使用 LoadFromFileTemplate 進行加載,這裏僅介紹此接口的用法,後續章節有完整的遷移教程。
LoadFromFileTemplate 接口使用時需要注意以下問題:
- qconfig\_dtypes.pt 不保存算子的 fix\_scale 信息,如果原 qconfig 裏存在 fix\_scale 的算子,需要在加載 qconfig\_dtypes.pt 後再次進行配置。
- 使用 LoadFromFileTemplate 接口時 enable\_optimize 必須配置為 False,因為保存下來的 dtype 一般是優化後的,優化過程不可重入,Load qconfig\_dtypes.pt 後不再支持對 qconfig 中 dtype 的修改。
LoadFromFileTemplate 使用示例如下:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.加載量化配置pt文件
LoadFromFileTemplate("qconfig_dtypes.pt"),
#2.對fix_scale的算子進行補充配置
ModuleNameTemplate({"backbone.quant":{"dtype":qint8,"threshold":1.0}})
],
#3.無需開啓任何優化
enable_optimize=False,
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.5 典型場景配置
由於征程 6 系列平台的差異,qconfig 的配置自然也會有所區別。本節將結合平台差異,提供新版 qconfig 模板在典型場景下的配置示例。
3.5.1 征程 6E/M 平台一般配置
征程 6E/M 平台以定點算力為主,在進行混合量化精度調優過程中,建議以全局 int8 精度為例,針對部分對量化較為敏感的算子,可將其配置為更高的 int16 精度。以下為配置示例。
配置示例 1:全局 int8+ 手動配置量化敏感度高的算子為 int16
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.配置全局feat int8,weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.根據精度debug工具分析,將敏感算子配置為int16(按需配置)
#將weight敏感的conv配置為int16(按需配置),支持批量配置
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_3.conv"],
),
#3.將敏感的Matmul配置為int16輸入(按需配置)
#將第0個輸入敏感的matmul配置為int16(按需配置),支持批量配置
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul"]
),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)配置示例 2:全局 int8+ 使用敏感度模板配置部分敏感算子為 int16
除了手動將部分敏感算子配置為 int16,新版 qconfig 模板提供了 SensitivityTemplate,該模板用於將精度 debug 工具所產出的敏感度列表中,量化敏感度排序 topk 或者佔一定比率 ratio 的敏感算子,配置為更高的量化精度。相關示例如下:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
#精度debug工具跑出來的算子量化敏感度列表
table1=torch.load("output1_ATOL_sensitive_ops.pt")
table2=torch.load("output2_ATOL_sensitive_ops.pt")
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 基礎配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
#2.配置output1輸出敏感度Top10的算子為int16(按需配置)
SensitivityTemplate(
sensitive_table=table1,
topk_or_ratio=10,
),
#3.配置output2輸出敏感度10%的算子為int16(按需配置)
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.1,
),
],
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)topk\_or\_ratio 參數的選擇:需要用户根據量化精度和部署性能進行權衡,一般來説,配置的高精度算子越多,量化精度越好,而部署性能影響則會越大。
3.5.2 征程 6P/H 平台一般配置
對於征程 6 P/H 這種有浮點算力的平台,推薦將 feature 輸出配置為 fp16+conv 和 matmul 類算子全部配置為 int8 作為基礎配置,然後再將量化敏感的算子配置為 int16。如下為配置示例。
配置示例 1:基礎配置 + 手動配置量化敏感度高的算子為 int16
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.qconfig_template import ModuleNameQconfigSetter,
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基本配置
#全局 feat fp16
ModuleNameTemplate({"": torch.float16}),
#將conv和matmul類算子配置為全int8輸入
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
),
MatmulDtypeTemplate(
input_dtypes=[qint8, qint8],
),
#2.根據debug工具分析結果,將敏感的Conv/Matmul配置為int16輸入(按需配置)
#將conv中敏感的weight輸入配置為int16(按需配置)
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint16,
prefix= ["backbone.conv1.conv1_3.conv"],
),
#將matmul中敏感的輸入配置為int16(按需配置)
MatmulDtypeTemplate(
input_dtypes=[qint16,qint8],
prefix=["encoder.encoder.0.layers.0.self_attn.matmul"] ),
],
save_dir=args.save_path,
)
float_model.eval()
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)配置示例 2:基礎配置 + 使用敏感度模板配置部分敏感算子為 int16
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
#精度debug工具跑出來的算子量化敏感度列表
table1=torch.load("output1_ATOL_sensitive_ops.pt")
table2=torch.load("output2_ATOL_sensitive_ops.pt")
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1.基本配置
#全局 feat fp16
ModuleNameTemplate({"": torch.float16}),
#將conv和matmul類算子配置為全int8輸入
ConvDtypeTemplate(
input_dtype=qint8,
weight_dtype=qint8,
),
MatmulDtypeTemplate(
input_dtypes=[qint8, qint8],
),
#2.配置output1輸出敏感度Top10的算子為int16(按需配置)
SensitivityTemplate(
sensitive_table=table1,
topk_or_ratio=10,
),
#3.配置output2輸出敏感度10%的算子為int16(按需配置)
SensitivityTemplate(
sensitive_table=table2,
topk_or_ratio=0.1,
),
],
save_dir=args.save_path,)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path)3.5.3 配置算子為 float32 計算
在做精度調優的時候,有時候想要快速定位引起量化誤差的瓶頸,此時會將模型片段或者算子配置為 float32 計算,如下為將指定模型片段和算子配置為 float32 計算的示例:
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
#1. 基礎配置全局激活&weight int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
ModuleNameTemplate(
{
#2.批量配置"encoder.encoder.0.layers.0"為float32計算
"encoder.encoder.0.layers.0": torch.float32,
#3.配置"backbone.conv1.conv1_2.conv.act"算子為float32計算
"backbone.conv1.conv1_2.conv.act": torch.float32,}
),
],
save_dir=args.save_path,
)3.5.4 QAT 訓練時固定激活 scale
在 QAT 精度調優實踐中發現(主要是圖像分類任務實驗),做完 calibration 後,把 activation 的 scale 固定住,不進行更新,即設置 activation 的 averaging_constant=0 ,QAT 訓練精度相比於不固定 activation 的 scale 的量化精度會更好。相關配置示例如下所示:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization.fake_quantize import FakeQuantize
from horizon_plugin_pytorch.quantization.qconfig import QConfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import get_qconfig
my_qconfig_setter=QconfigSetter(
#將激活的averaging_constant參數配置為0
reference_qconfig= QConfig(
output=FakeQuantize.with_args(
observer=MinMaxObserver,
averaging_constant=0,#averaging_constant配置為0
), ),
templates=[
#配置weight和激活全局int8
ModuleNameTemplate({"":qint8}),
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8),
MatmulDtypeTemplate(input_dtypes=qint8),
],
save_dir=args.save_path,
)
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.save_path
)4. 新版 qconfig 模板遷移
用户在遷移到新版 qconfig 模板時,建議根據以下情況進行不同的操作:
- 如果用户部署平台為征程 6B、征程 6H 和征程 6P,為了更方便地利用浮點算力,建議使用新版 qconfig 模板。
- 如果用户模型從未適配過 QAT 鏈路,建議用户直接參考第 3 章使用新版 qconfig 模板進行配置。
- 如果用户模型已經適配過老版本 qconfig 模板,且在模型迭代中還需要修改 qconfig 配置,比如增加 int16 算子等,那麼建議用户參考第 3 章重新進行新版 qconfig 模板的適配。
- 如果用户模型已經適配過老版本 qconfig 模板,且確認在模型迭代中不再需要修改 qconfig 配置,那麼則建議用户按照下面的流程進行遷移工作。
若用户已經穩定使用老版本 qconfig 模板,而且模型迭代中不需要再修改量化配置,那麼建議按照以下流程進行適配:
- 首先,使用
SaveToFileTemplate接口保存舊模板下的量化配置文件qconfig_dtypes.pt,其中涵蓋每個算子的 dtype; - 其次,需檢查模型中是否存在採用 fix\_scale 的算子。鑑於 qconfig\_dtypes.pt 目前尚不支持保存 fix\_scale 的算子信息,並且新舊模板在 fix\_scale 的配置方面存在差異,若存在 fix\_scale 的算子,那麼就必須對新模板下 fix\_scale 的配置進行適配;
- 最後,運用
LoadFromFileTemplate接口加載已保存的qconfig_dtypes.pt
這裏要特別注意,加載已保存的 qconfig_dtypes.pt 文件後不支持再對模型中的算子 dtype 做修改。
下面將詳細介紹遷移的具體步驟和操作要點。
4.1 保存舊版本的 qconfig\_dtypes 文件
horizon_plugin_pytorch 提供了 SaveToFileTemplate 接口用於將量化配置文件保存為 qconfig_dtypes.pt。其路徑和使用方式如下:
from horizon_plugin_pytorch.quantization.qconfig_setter.templates import *
...
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(...),
calibration_8bit_weight_16bit_act_qconfig_setter,
),
check_result_dir=args.save_path,
)
#prepare後保存
#args.save_path為qconfig_dtypes.pt保存路徑
save_api=SaveToFileTemplate(args.save_path)
save_api(None, qat_model, None, None, None)在完成修改並運行後,於 args.save\_path 目錄下將會生成包含量化 dtype 的 qconfig\_dtypes.pt 與 qconfig\_dtypes.pt.py 文件。
4.2 適配 fix\_scale 的配置
目前,qconfig_dtypes.pt 文件在保存量化配置信息時,存在一定的功能限制,即尚不支持對配置了 fix\_scale 的算子信息進行保存。這意味着當用户在舊版本 qconfig 中對部分算子設置了 fix\_scale 時,相關的配置無法通過 qconfig_dtypes.pt 文件完整遷移至新模板。
因此,若用户的模型中存在配置 fix\_scale 的算子,fix\_scale 的算子和相應配置可以通過 model_check_result.txt 獲取,為確保量化配置能夠對齊舊版本,必需按照上文 3.2 章節所闡述的適配規則和操作步驟,手動對 fix\_scale 的配置進行調整與適配,以使其符合新模板的要求。
4.3 加載 qconfig_dtypes.pt 文件
使用 LoadFromFileTemplate 加載舊版本模板 qconfig\_dtypes.pt 時,為確保與舊版本行為相適配,必須對特定參數予以配置。否則,可能會面臨加載 calib/qat 權重失敗的問題。以下為相關參數的詳細闡述:
- 對於
QconfigSetter(),應將“enable\_optimize”參數配置為“False”,以此避免啓用任何新版本中的默認優化。 - 針對
LoadFromFileTemplate(),務必將“only\_set\_mod\_in\_graph”參數配置為“False”。原因在於,在老版本配置中,存在對非 graph 中的操作進行 qconfig 設置的情形。 - 在執行
prepare操作時,需將“fuse\_mode”參數配置為“FuseMode.BNAddReLU”,進而實現與老版本行為的對齊。
以下為完整的使用示例:
import torch
from horizon_plugin_pytorch.quantization import prepare,set_fake_quantize,FakeQuantState
from horizon_plugin_pytorch.quantization import get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
my_qconfig_setter=QconfigSetter(
reference_qconfig=get_qconfig(observer=MSEObserver),
templates=[
ModuleNameTemplate(
{ #1.適配fix_scale的配置
"backbone.quant":{"dtype":qint8,"threshold":1.0},
}
#2.Load舊模板下保存的qconfig_dtypes.pt
LoadFromFileTemplate(
"./qconfig_old/qconfig_dtypes.pt",
#3.該參數需要設置 False,原來配置中有對非 graph 中的 op 設置 qconfig
only_set_mod_in_graph=False,
),],
save_dir=args.output_dir,
#4.無需開啓任何優化,關閉enable_optimize
enable_optimize=False,
)
from horizon_plugin_pytorch.quantization.fx.fusion_patterns import FuseMode
qat_model = prepare(
float_model,
example_inputs=example_input,
qconfig_setter=my_qconfig_setter,
check_result_dir=args.output_dir,
#5.對齊老版本的融合行為
fuse_mode=FuseMode.BNAddReLU,
)