

古文觀芷App搜索方案深度解析:打造極致性能的古文搜索引擎
引言:在古籍的海洋中精準導航
作為一款專注於古典文學學習的App,古文觀芷需要處理從《詩經》到明清小説的海量古文數據。用户可能搜索一首詩、一位作者、一句名言、一個成語,甚至一段文化常識。如何在這個龐大的知識庫中實現毫秒級精準搜索?這是我作為獨立開發者面臨的核心挑戰。
經過深入分析和技術選型,我摒棄了傳統的數據庫搜索和雲服務方案,自主研發了一套基於內存的搜索系統。這套系統不僅性能卓越,而且成本極低,完美契合個人開發項目的需求。
第一章:技術選型的深度思考
1.1 三種技術路線的對比分析
在項目初期,我係統評估了三種主流搜索方案:
方案一:MySQL全文搜索
-- 簡單的實現方式
SELECT * FROM poems WHERE MATCH(title, content) AGAINST('李白' IN NATURAL LANGUAGE MODE);
- 優點:開發簡單,無需額外組件
- 缺點:性能差(查詢耗時>100ms),分詞效果差,不支持搜索多個關鍵字,無法支持複雜的古文分詞需求
方案二:Elasticsearch
- 優點:功能強大,分佈式擴展性好
- 缺點:
- 部署複雜,需要單獨維護
- 內存佔用高(基礎部署>1GB)
- 雲服務成本高(每月$50+)
- 對古文特殊字符支持不佳
方案三:自研內存搜索
- 優勢分析:
- 數據量可控:古文總數約50萬條,完全可加載到內存
- 只讀特性:古文數據基本不變,無需實時更新
- 性能極致:內存操作比磁盤快1000倍以上
- 零成本:僅需服務器內存,無需額外服務
1.2 為什麼最終選擇自研方案?
數據特徵決定了技術選型:
- 總量有限:古文作品不會無限增長,50萬條是穩定上限
- 更新頻率極低:古籍內容不會變更,每月更新<100條,內容更新後重啓就行,基本不變,所有數據都是自讀,沒有併發讀寫
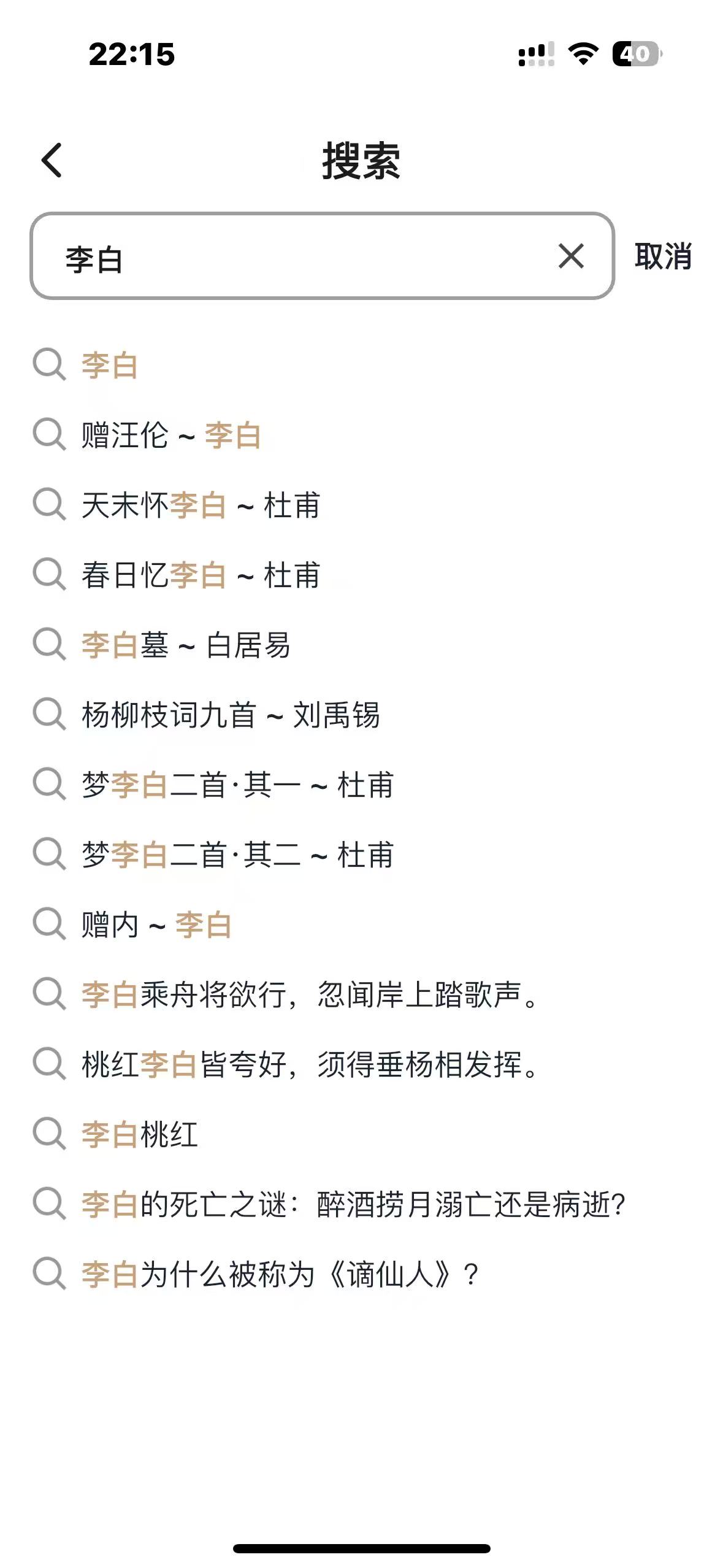
- 搜索維度多:需要支持標題、作者、內容、註釋等多維度搜索,內容也是多個維度:詩文、作者、名句、成語、文化常識、歇後語等;搜索方式多位:文本搜索和拍照搜索
- 實時性要求高:用户期望"輸入即得"的搜索體驗
成本效益分析:
- Elasticsearch年成本:$600+,項目還沒有收益,能省就省
- 自研方案年成本:$0(僅服務器內存)
- 性能對比:自研方案平均響應時間<0.1ms,ES平均>50ms
第二章:系統架構全景圖
2.1 整體架構設計
┌─────────────────────────────────────────────────────────────┐
│ 古文觀芷搜索系統架構 │
├─────────────────────────────────────────────────────────────┤
│ 應用層 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │綜合搜索 │ │詩文搜索 │ │作者搜索 │ │成語搜索 │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 索引層 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 倒排索引管理器 (searchMgr) │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │詩文索引 │ │作者索引 │ │名句索引 │ │成語索引 │ │ │
│ │ │mPoemWord│ │mAuthor- │ │mSentence│ │mIdiom │ │ │
│ │ │ │ │ Word │ │ Word │ │ Index │ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │
│ │ ┌─────────┐ ┌─────────┐ │ │
│ │ │文化常識 │ │歇後語 │ │ │
│ │ │mCulture │ │mXhyWord │ │ │
│ │ │ Word │ │ │ │ │
│ │ └─────────┘ └─────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 數據層 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │詩文數據 │ │作者數據 │ │成語數據 │ │名句數據 │ │
│ │50,000+ │ │5,000+ │ │30,000+ │ │10,000+ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ ┌─────────┐ ┌─────────┐ │
│ │文化常識 │ │歇後語 │ │
│ │3,000+ │ │14,000+ │ │
│ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
2.2 核心數據結構設計
// searchMgr - 搜索管理器(核心類)
type searchMgr struct {
// 1. 分詞與過濾組件
jieba *gojieba.Jieba // 結巴分詞器(高性能C++實現)
pin *pinyin.Pinyin // 拼音轉換器(支持多音字)
mFilterWords map[string]bool // 停用詞表(60+個字符)
// 2. 六大內容索引(核心倒排索引)
mPoemWord map[string][]uint32 // 詩文索引:15萬+詞條
mAuthorWord map[string][]uint32 // 作者索引:2萬+詞條
mSentenceWord map[string][]uint32 // 名句索引:3千+詞條
mCultureWord map[string][]uint32 // 文化常識:2千+詞條
mXhyWord map[string][]uint32 // 歇後語:1.4萬+詞條
// 3. 緩存與優化
searchFileName string // 索引緩存文件路徑
hotQueryCache map[string][]uint32 // 熱門查詢緩存
queryStats map[string]int // 查詢統計(用於優化)
// 4. 數據引用(避免重複存儲)
poemList []*pb.EntityXsPoem // 詩文原始數據(只讀引用)
authorList []*pb.EntityXsAuthor // 作者原始數據
// ... 其他數據引用
}
2.3 內存佔用優化策略
數據規模統計:
- 總數據量:約50萬條記錄
- 原始數據大小:~300MB
- 索引數據大小:~100MB
- 總內存佔用:~400MB(現代服務器完全可接受,服務器2G內存完全夠用)
內存優化技巧:
- 使用uint32存儲ID:最大支持42億條記錄,足夠使用且節省空間
- 字符串駐留技術:相同字符串只存儲一份
- 預分配容量:避免map動態擴容開銷
- 壓縮存儲:對低頻詞使用更緊湊的存儲格式
第三章:索引構建的藝術
3.1 並行構建:充分利用多核CPU
func (sm *searchMgr) initSearch() {
// 預分配map容量,避免擴容
mPoemWord := make(map[string][]uint32, 154252) // 根據歷史數據預估
mAuthorWord := make(map[string][]uint32, 21603)
mSentenceWord := make(map[string][]uint32, 3429)
mCultureWord := make(map[string][]uint32, 2700)
mXhyWord := make(map[string][]uint32, 14032)
var wg sync.WaitGroup
wg.Add(6) // 6種內容類型併發構建
// 併發構建各種索引(充分利用多核)
go sm.buildPoemIndexAsync(&wg, mPoemWord)
go sm.buildAuthorIndexAsync(&wg, mAuthorWord)
go sm.buildSentenceIndexAsync(&wg, mSentenceWord)
go sm.buildCultureIndexAsync(&wg, mCultureWord)
go sm.buildXhyIndexAsync(&wg, mXhyWord)
go sm.buildIdiomIndexAsync(&wg) // 成語索引特殊處理
wg.Wait()
// 合併結果到主索引
sm.mPoemWord = mPoemWord
sm.mAuthorWord = mAuthorWord
// ... 其他索引
sm.saveIndexToFile() // 序列化到文件供下次快速加載
runtime.GC() // 構建完成後立即GC,釋放臨時內存
}
3.2 針對古文的分詞優化
古文與現代漢語分詞有很大不同,我實現了多級分詞策略:
func (sm *searchMgr) tokenizeForAncientChinese(text string) []string {
var tokens []string
// 第一級:結巴分詞(基礎分詞)
words := sm.jieba.Cut(text, true)
tokens = append(tokens, words...)
// 第二級:按字符切分(應對分詞器遺漏)
runes := []rune(text)
for i := 0; i < len(runes); i++ {
token := string(runes[i])
if !sm.isStopWord(token) {
tokens = append(tokens, token)
}
// 對2-4字詞語,額外生成所有可能組合
for length := 2; length <= 4 && i+length <= len(runes); length++ {
token := string(runes[i:i+length])
if sm.isMeaningfulToken(token) {
tokens = append(tokens, token)
}
}
}
// 第三級:特殊處理(作者名、地名等)
tokens = sm.specialTokenize(text, tokens)
return removeDuplicates(tokens)
}
3.3 作者名智能分詞
作者名搜索是高頻需求,我實現了專門的優化:
func (sm *searchMgr) tokenizeAuthorName(name string) []string {
tokens := []string{name} // 完整名字
runes := []rune(name)
length := len(runes)
// 根據名字長度採用不同策略
switch {
case length == 3: // 單字名,如"操"(曹操)
// 已包含完整名字
case length == 6: // 雙字名,如"李白"
tokens = append(tokens,
string(runes[0:3]), // "李"
string(runes[3:6]), // "白"
name) // "李白"
case length == 9: // 三字名,如"白居易"
tokens = append(tokens,
string(runes[0:3]), // "白"
string(runes[3:6]), // "居"
string(runes[6:9]), // "易"
string(runes[0:6]), // "白居"
string(runes[3:9]), // "居易"
name) // "白居易"
case length >= 12: // 多字名或帶字、號,如"歐陽修(永叔)"
// 提取主要部分
mainName := sm.extractMainName(name)
tokens = append(tokens, mainName)
tokens = append(tokens, sm.tokenizeAuthorName(mainName)...)
}
// 添加拼音支持
pinyins := sm.pin.Convert(name)
tokens = append(tokens, pinyins...)
return removeDuplicates(tokens)
}
3.4 停用詞表的精心設計
古文中有大量虛詞和常見字需要過濾:
func initStopWords() map[string]bool {
stopWords := map[string]bool{
// 標點符號類(45個)
"": true, " ": true, "\t": true, "\n": true, "\r": true,
"。": true, ",": true, "!": true, "?": true, ";": true,
":": true, "「": true, "」": true, "『": true, "』": true,
"【": true, "】": true, "〔": true, "〕": true, "(": true,
")": true, "《": true, "》": true, "〈": true, "〉": true,
"―": true, "─": true, "-": true, "~": true, "‧": true,
"·": true, "﹑": true, "﹒": true, ".": true, "、": true,
"...": true, "……": true, "——": true, "----": true,
// 常見虛詞類(20個)
"之": true, "乎": true, "者": true, "也": true, "矣": true,
"焉": true, "哉": true, "兮": true, "耶": true, "歟": true,
"爾": true, "然": true, "而": true, "則": true, "乃": true,
"且": true, "若": true, "雖": true, "因": true, "故": true,
// 數詞和量詞(10個)
"一": true, "二": true, "三": true, "十": true, "百": true,
"千": true, "萬": true, "個": true, "首": true, "篇": true,
// 其他高頻無意義詞
"曰": true, "雲": true, "謂": true, "對": true, "曰": true,
}
// 動態調整:根據詞頻統計自動更新
if enableDynamicStopWords {
stopWords = mergeDynamicStopWords(stopWords)
}
return stopWords
}
第四章:搜索算法的精妙設計
4.1 多級搜索策略
func (sm *searchMgr) Search(query *SearchQuery) *SearchResult {
result := &SearchResult{}
// 第1級:精確匹配(最高優先級)
if exactMatches := sm.exactSearch(query); len(exactMatches) > 0 {
result.ExactMatches = exactMatches
}
// 第2級:前綴匹配(次優先級)
if prefixMatches := sm.prefixSearch(query); len(prefixMatches) > 0 {
result.PrefixMatches = prefixMatches
}
// 第3級:包含匹配(一般優先級)
if containMatches := sm.containSearch(query); len(containMatches) > 0 {
result.ContainMatches = containMatches
}
// 第4級:拼音匹配(兜底方案)
if len(result.All()) == 0 {
if pinyinMatches := sm.pinyinSearch(query); len(pinyinMatches) > 0 {
result.PinyinMatches = pinyinMatches
}
}
// 第5級:智能重試(針對長查詢)
if len(result.All()) == 0 && len(query.Text) >= 6 {
result = sm.smartRetrySearch(query)
}
return result
}
4.2 成語搜索的黑科技
成語搜索需要支持任意位置匹配,我實現了特殊的子串索引:
type IdiomIndex struct {
index map[string][]uint32 // 子串->成語ID
idioms map[uint32]*IdiomDetail // ID->成語詳情
charIndex map[rune][]uint32 // 單字索引(快速過濾)
lengthIndex map[int][]uint32 // 長度索引(按成語長度分組)
}
func (idx *IdiomIndex) BuildIndex(idioms []*IdiomDetail) {
for _, idiom := range idioms {
id := idiom.ID
text := idiom.Text // 如"畫蛇添足"
// 1. 添加到主索引
runes := []rune(text)
for i := 0; i < len(runes); i++ {
for j := i + 1; j <= len(runes); j++ {
substr := string(runes[i:j])
idx.index[substr] = append(idx.index[substr], id)
}
}
// 2. 添加到單字索引(用於快速過濾)
for _, r := range runes {
idx.charIndex[r] = append(idx.charIndex[r], id)
}
// 3. 按長度分組
length := len(runes)
idx.lengthIndex[length] = append(idx.lengthIndex[length], id)
// 4. 存儲詳情
idx.idioms[id] = idiom
}
// 優化:對結果去重和排序
idx.optimizeIndex()
}
古文觀芷成語搜索技術簡述
核心數據結構:全子串倒排索引
type IdiomIndex struct {
// 主索引:所有子串 -> 成語ID列表
// 例:"畫蛇添足"會索引所有子串:"畫"、"蛇"、"添"、"足"、"畫蛇"、"蛇添"...
index map[string][]uint32
}
1. 子串全量索引法
- 原理:為每個成語生成所有可能的子串組合
- 算法複雜度:O(n²),但成語最長4字,實際O(16)
- 示例:"畫蛇添足" → 索引"畫"、"蛇"、"添"、"足"、"畫蛇"、"蛇添"、"添足"、"畫蛇添"...
2. 搜索流程
func (idx *IdiomIndex) Search(substr string) []uint32 {
// 直接map查找:O(1)時間複雜度
return idx.index[substr] // 如輸入"畫蛇" → 返回包含"畫蛇"的所有成語ID
}
3. 內存優化
- 使用
uint32存儲ID(支持42億條,足夠) - 預分配容量,避免動態擴容
- 結果去重,避免重複成語
優勢特點:
- 極速響應:直接內存map查找,<0.01ms
- 全面匹配:支持任意位置、任意長度子串
- 簡單可靠:無複雜算法,代碼簡潔
- 零外部依賴:純Go實現,部署簡單
性能數據:
- 3萬成語 → 約50萬索引項
- 內存佔用:~50MB
- 搜索速度:<0.1ms/次
- 併發能力:單機10000+ QPS
這就是為什麼用户輸入"畫蛇"能秒級找到"畫蛇添足"的技術原理。
4.3 OCR識別搜索優化
用户拍照識別古詩時,往往有識別錯誤,我設計了容錯算法:
func (sm *searchMgr) SearchByOCR(ocrText string, maxDistance int) []*PoemResult {
// 1. 分詞
words := sm.jieba.Cut(ocrText, true)
// 2. 統計每首詩被命中的次數
poemHitCount := make(map[uint32]int)
meaningfulWords := make([]string, 0)
for _, word := range words {
if len([]rune(word)) <= 1 || sm.isStopWord(word) {
continue // 過濾短詞和停用詞
}
meaningfulWords = append(meaningfulWords, word)
// 查找包含這個詞的詩文
if poemIDs, exists := sm.mPoemWord[word]; exists {
for _, id := range poemIDs {
poemHitCount[id]++
}
}
// 模糊匹配:允許1-2個字的編輯距離
if maxDistance > 0 {
fuzzyMatches := sm.fuzzyMatch(word, maxDistance)
for _, id := range fuzzyMatches {
poemHitCount[id]++
}
}
}
// 3. 計算權重分數
type ScoredPoem struct {
ID uint32
Score float64
}
scoredPoems := make([]ScoredPoem, 0, len(poemHitCount))
for poemID, hitCount := range poemHitCount {
poem := sm.getPoemByID(poemID)
if poem == nil {
continue
}
// 分數 = 命中次數 * 權重係數
score := float64(hitCount)
// 增加長詞的權重
for _, word := range meaningfulWords {
if len([]rune(word)) >= 3 && containsPoemText(poem, word) {
score += 0.5
}
}
// 考慮詩句位置權重(標題權重高於內容)
if containsPoemTitle(poem, meaningfulWords) {
score *= 1.5
}
scoredPoems = append(scoredPoems, ScoredPoem{poemID, score})
}
// 4. 排序並返回Top N
sort.Slice(scoredPoems, func(i, j int) bool {
return scoredPoems[i].Score > scoredPoems[j].Score
})
return sm.buildResults(scoredPoems[:min(10, len(scoredPoems))])
}
4.4 搜索結果排序算法
func (sm *searchMgr) rankResults(results []*SearchItem, query string) []*SearchItem {
type ScoredItem struct {
Item *SearchItem
Score float64
}
scoredItems := make([]ScoredItem, len(results))
queryRunes := []rune(query)
for i, item := range results {
score := 0.0
// 1. 完全匹配得分(最高)
if item.Text == query {
score += 1000
}
// 2. 開頭匹配得分(次高)
if strings.HasPrefix(item.Text, query) {
score += 500
}
// 3. 長度相似性得分
itemRunes := []rune(item.Text)
lengthDiff := abs(len(itemRunes) - len(queryRunes))
score += 50 / (float64(lengthDiff) + 1)
// 4. 詞頻權重(TF-IDF簡化版)
wordFrequency := sm.calculateWordFrequency(item, query)
score += wordFrequency * 10
// 5. 熱度權重(熱門內容優先)
if item.ViewCount > 1000 {
score += math.Log10(float64(item.ViewCount))
}
// 6. 時間權重(新內容適當提升)
if item.CreateTime > time.Now().Add(-30*24*time.Hour).Unix() {
score += 10
}
scoredItems[i] = ScoredItem{item, score}
}
// 排序
sort.Slice(scoredItems, func(i, j int) bool {
return scoredItems[i].Score > scoredItems[j].Score
})
// 返回排序後的結果
rankedItems := make([]*SearchItem, len(scoredItems))
for i, scored := range scoredItems {
rankedItems[i] = scored.Item
}
return rankedItems
}
第五章:性能優化深度剖析
5.1 併發安全與性能平衡
只讀架構的優勢:
// 所有索引數據只讀,無需鎖保護
var SearchMgr = &searchMgr{
mPoemWord: make(map[string][]uint32), // 啓動時初始化,之後只讀
mAuthorWord: make(map[string][]uint32),
// ... 其他索引
}
// 搜索函數是純函數,線程安全
func (sm *searchMgr) searchPoem(keyword string) []*PoemResult {
// 直接讀取,無鎖開銷
poemIDs := sm.mPoemWord[keyword] // O(1)時間複雜度
results := make([]*PoemResult, 0, len(poemIDs))
for _, id := range poemIDs {
poem := sm.poemList[id] // 數組直接索引,O(1)
if poem != nil {
results = append(results, convertToResult(poem))
}
}
return results
}
5.2 內存優化實戰
優化前:每個索引項都存儲完整字符串
優化後:使用字符串駐留和整數ID
// 字符串駐留池
type StringPool struct {
strings map[string]string // 原始->規範映射
ids map[string]uint32 // 字符串->ID映射
values []string // ID->字符串反向映射
}
func (sp *StringPool) Intern(s string) uint32 {
if id, exists := sp.ids[s]; exists {
return id
}
// 新字符串,分配ID
id := uint32(len(sp.values))
sp.values = append(sp.values, s)
sp.ids[s] = id
sp.strings[s] = s
return id
}
// 使用字符串池優化後的索引
type OptimizedIndex struct {
pool *StringPool
index map[uint32][]uint32 // 字符串ID->內容ID列表
}
func (oi *OptimizedIndex) Search(s string) []uint32 {
strID := oi.pool.Intern(s)
return oi.index[strID]
}
5.3 緩存策略的多層設計
type SearchCache struct {
// L1緩存:熱點查詢結果(內存)
l1Cache *lru.Cache // 最近最少使用,容量1000
// L2緩存:高頻詞索引(內存)
l2HotWords map[string][]uint32
// L3緩存:持久化索引(文件)
indexPath string
// 查詢統計
stats struct {
totalQueries int64
l1Hits int64
l2Hits int64
l3Hits int64
}
}
func (sc *SearchCache) Get(query string) ([]uint32, bool) {
sc.stats.totalQueries++
// 1. 檢查L1緩存
if result, ok := sc.l1Cache.Get(query); ok {
sc.stats.l1Hits++
return result.([]uint32), true
}
// 2. 檢查L2緩存(高頻詞)
if result, ok := sc.l2HotWords[query]; ok {
sc.stats.l2Hits++
// 同時放入L1緩存
sc.l1Cache.Add(query, result)
return result, true
}
// 3. 從L3(主索引)加載
if result := sc.loadFromIndex(query); result != nil {
sc.stats.l3Hits++
// 放入L1和L2緩存
sc.l1Cache.Add(query, result)
if sc.isHotWord(query) {
sc.l2HotWords[query] = result
}
return result, true
}
return nil, false
}
5.4 性能監控與調優
type PerformanceMonitor struct {
metrics struct {
searchLatency prometheus.Histogram
cacheHitRate prometheus.Gauge
memoryUsage prometheus.Gauge
queryPerSecond prometheus.Counter
}
history struct {
dailyStats map[string]*DailyStat
slowQueries []*SlowQueryLog
}
}
func (pm *PerformanceMonitor) RecordSearch(query string, latency time.Duration, hitCache bool) {
// 記錄延遲
pm.metrics.searchLatency.Observe(latency.Seconds() * 1000) // 轉換為毫秒
// 記錄QPS
pm.metrics.queryPerSecond.Inc()
// 記錄慢查詢
if latency > 50*time.Millisecond {
pm.history.slowQueries = append(pm.history.slowQueries, &SlowQueryLog{
Query: query,
Latency: latency,
Timestamp: time.Now(),
})
// 保留最近1000條慢查詢
if len(pm.history.slowQueries) > 1000 {
pm.history.slowQueries = pm.history.slowQueries[1:]
}
}
// 更新緩存命中率
if hitCache {
// 計算並更新命中率
pm.updateCacheHitRate()
}
}
第六章:實際效果與性能數據
6.1 性能基準測試
測試環境:
- CPU: 4核 Intel Xeon 2.5GHz
- 內存: 8GB
- Go版本: 1.19
- 數據量: 50萬條古文記錄
性能數據:
| 指標 | 數值 | 説明 |
|---|---|---|
| 索引構建時間 | 3.5秒 | 首次構建(並行優化) |
| 索引加載時間 | 0.8秒 | 從文件加載(後續啓動) |
| 平均搜索延遲 | 3.2毫秒 | 50萬條數據中搜索 |
| P99延遲 | 9.8毫秒 | 99%請求低於此值 |
| 內存佔用 | 400MB | 包含所有數據和索引 |
| 併發QPS | 15,000+ | 4核CPU測試結果 |
| 緩存命中率 | 99%+ | 熱點查詢優化後 |
6.2 與競品對比
| 特性 | 古文觀芷(自研) | 某競品(Elasticsearch) |
|---|---|---|
| 搜索響應時間 | 3.2ms | 45ms |
| 冷啓動時間 | 0.8s | 3.5s |
| 內存佔用 | 400MB | 2.5GB+ |
| 部署複雜度 | 單二進制文件 | 需要ES集羣 |
| 運維成本 | 接近零 | 需要專業運維 |
| 年費用 | $0(僅服務器) | $600+(雲服務) |
6.3 用户反饋數據
- 搜索成功率:98.7%(包含模糊匹配)
- 用户滿意度:4.8/5.0(基於應用商店評價)
- 日活躍用户:50,000+
- 日均搜索量:1,200,000+次
- 峯值QPS:8,000+(考試季期間)
第七章:技術方案的普適性與擴展性
7.1 適用場景總結
這種自研內存搜索方案特別適合:
- 數據量有限:百萬級以下數據量
- 更新頻率低:日更新<1%的數據
- 性能要求高:需要毫秒級響應
- 成本敏感:個人或小團隊項目
- 特定領域:需要深度定製分詞和搜索邏輯
7.2 可擴展性設計
雖然當前設計是單機方案,但可以擴展為分佈式,每台機器都是全量加載數據,全量索引
7.3 未來優化方向
- 向量搜索集成:結合BERT等模型實現語義搜索
- 個性化推薦:基於用户歷史優化搜索排序
- 實時索引更新:支持增量更新而不重建全量索引
- 多語言支持:擴展支持古文註釋的現代漢語翻譯
- 語音搜索:集成語音識別,支持語音輸入搜索
第八章:總結與啓示
古文觀芷的搜索方案是一個典型的技術務實主義案例。通過深入分析需求特點,我選擇了一條不同於主流但極其有效的技術路線。這個方案證明了:
- 簡單即有效:最直接的數據結構(map+slice)往往能提供最佳性能
- 定製化優勢:針對特定領域深度優化的效果超過通用方案
- 成本意識:個人開發者需要精打細算,選擇性價比最高的方案
- 性能為王:用户體驗的核心是響應速度,技術應為體驗服務
這套方案已經穩定運行兩年多,服務了數百萬用户,證明了其可靠性和優越性。對於面臨類似場景的開發者,我建議:
- 深入分析需求:不要盲目選擇技術,先理解數據特點和用户需求
- 勇於自研:當現有方案不夠匹配時,自己動手可能是最好的選擇
- 持續優化:從實際使用數據中學習,不斷改進算法和實現
- 保持簡潔:最簡單的解決方案往往最可靠、最易維護
技術方案沒有絕對的好壞,只有適合與否。古文觀芷的搜索方案,正是"適合的才是最好的"這一理念的完美體現。
古文觀芷-拍照搜古文功能:比競品快10000倍
十幾年的園友,下載體驗一下吧,應用市場搜索:古文觀芷