

0.前言
給組裏的本科生講一講惡意軟件,以及如何識別惡意軟件。
1.CNN介紹
注:這裏寫得很簡陋,只挑筆者不熟悉的部分寫,具體學習還是得詳看官方文檔。
卷積神經網絡(CNN)是一種深度學習模型,特別適用於處理圖像和視頻等數據。
CNN包括:卷積層、激活層、池化層、全連接層。
CNN的工作流程:
1.輸入層:接收原始數據(如圖像)
-
卷積層:提取特徵,生成特徵圖
-
激活層:引入非線性
-
池化層:下采樣,減少維度
-
重複步驟 2-4:多次卷積和池化以提取更高層次的特徵.
-
全連接層:展平特徵圖並進行分類
-
輸出層:輸出預測結果
感受野是卷積神經網絡中一個重要的概念,指的是網絡中某一層的一個神經元所能“看到”的輸入區域。
換句話説,感受野描述了網絡中某個特徵圖位置的神經元對輸入圖像的哪些部分有響應。
單層感受野:對於卷積層,感受野的大小可以通過以下公式計算:
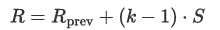
(R) 是當前層的感受野大小, R prev是前一層的感受野大小,(k) 是卷積核的大小,(S) 是步長。
説白了就是決定模型到底是看得宏觀一點,還是看得微觀一點,這主要還是取決於數據集,數據集提取出來的數學特徵,是細節上的能夠具體表明的數學特徵。
還是比較抽象的數學特徵。
比較抽象比較宏觀的話,就可以用大一點的感受野。
感受野的影響:
-
特徵提取能力: 較大的感受野可以捕捉到更大範圍的上下文信息,有助於提取全局特徵,但是準確度可能就會下降;較小的感受野則適合捕捉局部細節,判斷的準確度就會更高,但是就不能理解更高維度的內容。
-
模型性能: 在某些任務中,較大的感受野可能會提高模型的性能,尤其是在處理複雜場景時。
-
設計選擇: 在設計CNN時,可以通過選擇合適的卷積核大小、步長和層數來控制感受野的大小,以適應特 定任務的需求。
2.CNN識別惡意軟件
注意:這裏放出的代碼都不是完整的,只截取重要部分代碼。
這裏收集一些windows api的調用序列,觀察這個軟件中調用哪些api,來判斷這個軟件是不是惡意軟件。
windows_api_list = [
"CreateFileA", "CreateFileW", "ReadFile", "WriteFile", "CloseHandle",
"GetLastError", "SetLastError", "VirtualAlloc", "VirtualFree",
"CreateThread", "ExitThread", "WaitForSingleObject", "GetModuleHandleA",
"GetProcAddress", "LoadLibraryA", "LoadLibraryW", "FreeLibrary",
"GetModuleFileNameA", "GetModuleFileNameW", "MessageBoxA", "MessageBoxW",
"CreateEventA", "CreateEventW", "SetEvent", "ResetEvent", "WaitForMultipleObjects",
"OpenProcess", "TerminateProcess", "ReadProcessMemory", "WriteProcessMemory",
"CreateProcessA", "CreateProcessW", "GetExitCodeProcess", "ShellExecuteA",
"ShellExecuteW", "FindFirstFileA", "FindNextFileA", "FindClose",
"DeleteFileA", "DeleteFileW", "MoveFileA", "MoveFileW",
"CopyFileA", "CopyFileW", "CreateDirectoryA", "CreateDirectoryW",
"RemoveDirectoryA", "RemoveDirectoryW", "GetFileSize", "SetFilePointer",
"FlushFileBuffers", "GetFileInformationByHandle", "SetEndOfFile",
"GetFileTime", "SetFileTime", "CreateMutexA", "CreateMutexW",
"ReleaseMutex", "OpenMutexA", "OpenMutexW", "CreateSemaphoreA",
"CreateSemaphoreW", "ReleaseSemaphore", "OpenSemaphoreA", "OpenSemaphoreW",
"CreatePipe", "ReadFileEx", "WriteFileEx", "CancelIo",
"GetOverlappedResult", "CreateIoCompletionPort", "PostQueuedCompletionStatus",
"GetQueuedCompletionStatus", "SetEvent", "ResetEvent", "CreateFileMappingA",
"CreateFileMappingW", "MapViewOfFile", "UnmapViewOfFile", "VirtualQuery",
"VirtualQueryEx", "GetSystemInfo", "GetSystemTime", "SetSystemTime",
"GetTickCount", "Sleep", "GetCurrentProcessId", "GetCurrentThreadId",
"GetCommandLineA", "GetCommandLineW", "GetEnvironmentVariableA",
"GetEnvironmentVariableW", "SetEnvironmentVariableA", "SetEnvironmentVariableW",
"CreateProcessAsUserA", "CreateProcessAsUserW", "ImpersonateLoggedOnUser",
"RevertToSelf", "OpenThreadToken", "SetThreadToken", "DuplicateTokenEx",
"AdjustTokenPrivileges", "GetTokenInformation", "SetTokenInformation",
"CreateRemoteThread", "GetExitCodeThread", "WaitForInputIdle"
]收集完之後,把這些windows api變成numpy數組 類似[0,1],每一個位置代表一個獨特的windowsapi函數,位置上的值代表這個函數有沒有被調用。
然後我們要接收.exe軟件,使用pefile.PE這個python的第三方庫,從其導入表裏面把windows api提取出來,放入列表。
然後遍歷.exe軟件提取到的的windows api,是否在事先寫好的windows api列表中,如果找到,就找到對應的索引號,寫成1。
def extract_api_calls(exe_path):
pe = pefile.PE(exe_path)
api_calls = []
# 遍歷導入表
for entry in pe.DIRECTORY_ENTRY_IMPORT:
for imp in entry.imports:
api_calls.append(imp.name.decode('utf-8') if imp.name else None)
return api_calls
def create_api_vector(api_calls):
vector = np.zeros(len(windows_api_list), dtype=int)
for api in api_calls:
if api in windows_api_list:
index = windows_api_list.index(api)
vector[index] = 1
return vector這裏的惡意軟件的數據集可以利用微步的api,去爬取惡意樣本。
正常軟件也同理。
把正常軟件標籤貼為0,惡意的程序標籤為1。
def whitelist(whitedir):
labels = []
features = []
# 獲取文件夾中所有的 EXE 文件
for filename in os.listdir(whitedir):
if filename.endswith('.exe'):
one_feature = read_one_file(os.path.join(whitedir, filename))
features.append(one_feature)
labels.append(0) # 標籤為 0
# 將 features 轉換為 numpy 數組
features_array = np.array(features)
return features_array, np.array(labels)
def blacklist(whitedir):
labels = []
features = []
# 獲取文件夾中所有的 EXE 文件
for filename in os.listdir(whitedir):
if filename.endswith('.exe'):
one_feature = read_one_file(os.path.join(whitedir, filename))
features.append(one_feature)
labels.append(1) # 標籤為 1
# 將 features 轉換為 numpy 數組
features_array = np.array(features)
return features_array, np.array(labels)
# 讀取白名單和黑名單特徵
whitelist_features, whitelist_labels = whitelist("./data/normal_file")
blacklist_features, blacklist_labels = blacklist("./data/virus_file")數據處理好之後,開始創建模型。
import tensorflow as tf
import vec_data
# 創建 CNN 模型
model = tf.keras.Sequential([
tf.keras.layers.Conv1D(32, kernel_size=3, activation='relu', input_shape=(vec_data.features.shape[1], 1)),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Conv1D(64, kernel_size=3, activation='relu'),
tf.keras.layers.MaxPooling1D(pool_size=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax') # 二分類
])模型比較簡單,一個卷積,一個池化,再一個卷積,一個池化,然後就展平,全連接,全連接。
所有神經網絡的第一層一定都是數據輸入層,不管是什麼神經網絡算法,都得在第一層寫個input_shape表示輸入的數據。
【----幫助網安學習,以下所有學習資料免費領!加vx:YJ-2021-1,備註 “博客園” 獲取!】
① 網安學習成長路徑思維導圖
② 60+網安經典常用工具包
③ 100+SRC漏洞分析報告
④ 150+網安攻防實戰技術電子書
⑤ 最權威CISSP 認證考試指南+題庫
⑥ 超1800頁CTF實戰技巧手冊
⑦ 最新網安大廠面試題合集(含答案)
⑧ APP客户端安全檢測指南(安卓+IOS)
接下來是模型的參數:
train_param = {"epoch": 50, "batch_size": 32}
model_compile_param = {
"optimizer":'adam',
"loss":'sparse_categorical_crossentropy',
"metrics":['accuracy']
}第一個是訓練次數 50 和每一次訓練讀到的數據的最小量 32。
第二個是模型編譯的參數,adam編譯器,損失函數,評分機制。
然後是模型訓練:
import tensorflow as tf
import model_struct
import vec_data
import model_param
model_struct.model.compile(optimizer=model_param.model_compile_param["optimizer"],
loss=model_param.model_compile_param["loss"],
metrics=model_param.model_compile_param["metrics"])
print(model_struct.model.summary())
model_struct.model.fit(vec_data.features,
vec_data.labels,
epochs=model_param.train_param["epoch"],
batch_size=model_param.train_param["batch_size"])
model_struct.model.save("my_cnn.keras")先把模型編譯出來,然後就做訓練,最後把模型保存下來。
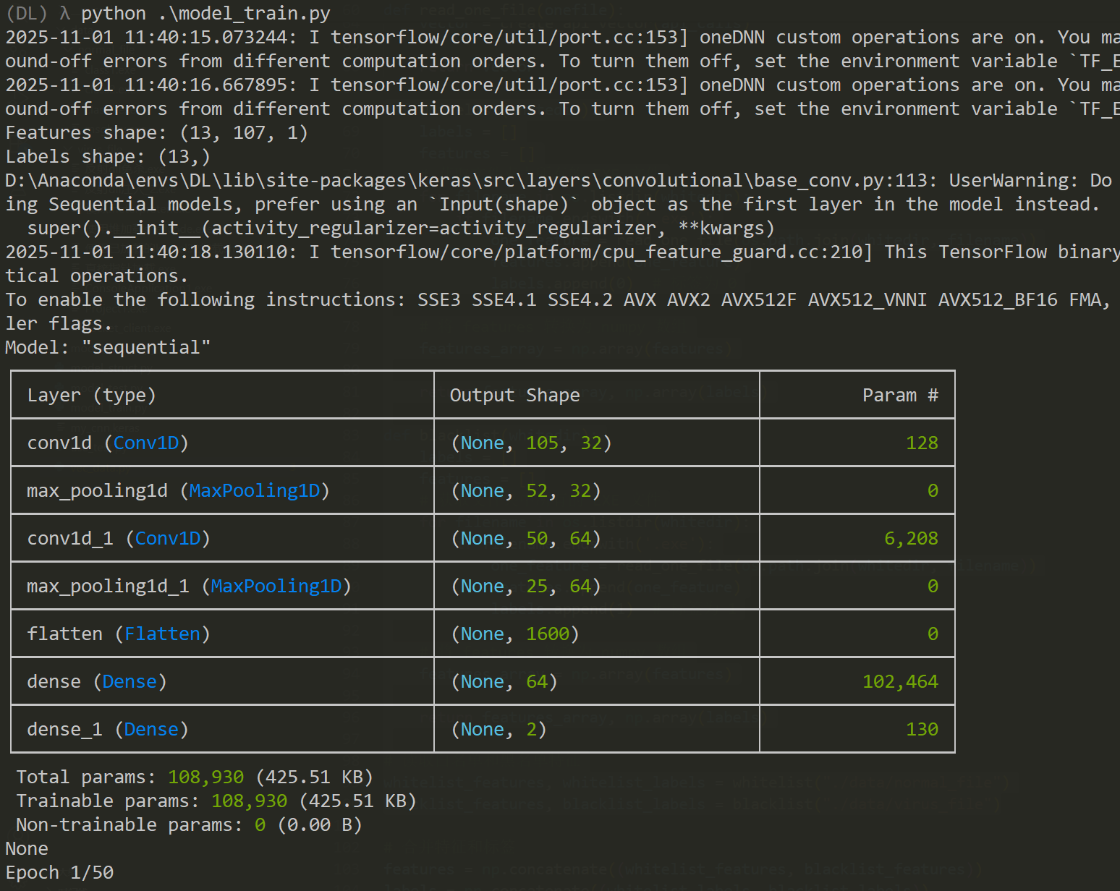
顯示的神經網絡的形狀,卷積層向下輸出32,到展平那裏輸出已經是1600了。
下面是訓練50次:
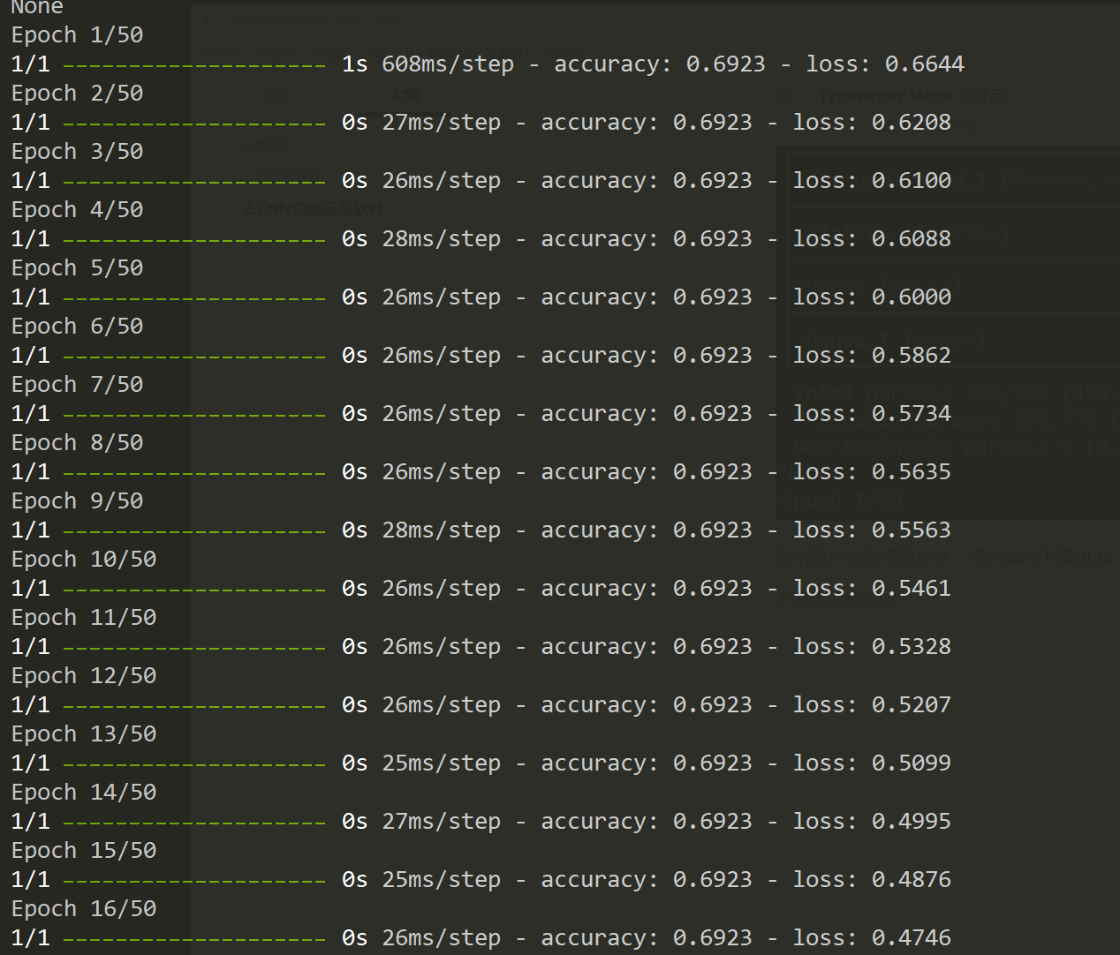
可以看到損失函數的大小和正確率。
雖然最後正確率顯示有92%,但是因為實際的樣本數量較少,訓練次數又較多,就會有過擬合的問題,實戰不行。
所以還得去多找一些樣本,VT和微步。
模型完成之後,就來用模型去測試了。
這裏寫個了簡單彈窗程序:
#include <windows.h>
void main() {
MessageBoxA(NULL,"aaaa","bbbb",MB_OK);
}編譯出.exe文件後丟給模型去測試:
import tensorflow as tf
import numpy as np
import vec_data
def predict_exe(exe_path, model):
# 提取 API 調用
api_calls = vec_data.extract_api_calls(exe_path)
# 創建特徵向量
feature_vector = vec_data.create_api_vector(api_calls)
# 調整輸入形狀
feature_vector = feature_vector.reshape(1, feature_vector.shape[0], 1) # (1, 特徵長度, 1)
# 進行預測
prediction = model.predict(feature_vector)
# 獲取預測結果
predicted_class = np.argmax(prediction, axis=1)
return predicted_class[0]
model = tf.keras.models.load_model('./my_cnn.keras')
# 示例用法
exe_path = "../Project1/x64/Release/Project1.exe"
predicted_label = predict_exe(exe_path, model)
print(f'Predicted label: {predicted_label}') # 0 表示白名單,1 表示黑名單將目標.exe文件導入,然後提取API,創建特徵向量,調整輸入形狀,進行預測結果會是個矩陣,所以最後用np.argmax這個參數最大的矩陣拿來做標籤預測。
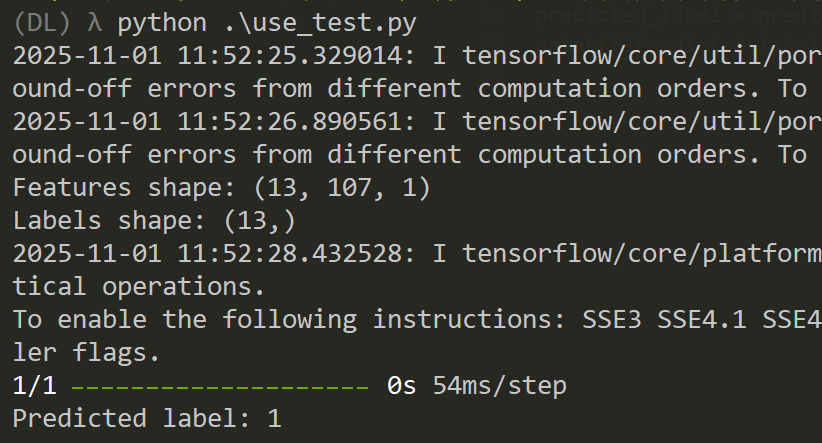
它顯示的是1,也就是個惡意軟件,但是這其實只是個正常的彈窗程序罷了。
所以這裏其實就存在問題,樣本數量太少了,導致實戰不行。
不過模型的構造和訓練方法是一樣的,只需要增加樣本數量和根據自己電腦性能調整訓練次數,就可以有令人滿意的結果。
補充:用windows api來做惡意軟件檢測其實算是比較取巧,因為在免殺中很多惡意軟件是可以隱藏的導入表函數的,然後還有很多函數可以替換達到同樣的效果。
還有就是現在很多惡意軟件都會把自己的api調用變成一個正常應用程序,也就是説正常程序會調用的windows api,惡意軟件也會用,所以拿windows api 來做惡意軟件檢測在實戰中效果應該是不太理想的。
像360,火絨之類的大廠 會用ast ,也就是控制流程,if-else這些東西,做成numpy數組;
或者是直接把shellcode這類16進制數放入模型中,比如説提取text段shellcode放入數組。
當然長度可能會不一樣,所以需要定義一下長度(1.1024*1024),把shellcode放入到每一個位置中去,如果小於定義長度就拿0去填充。
如果大於就切掉多餘的部分。
或者直接多個模型多個特徵來綜合判斷是不是惡意軟件。
更多網安技能的在線實操練習,請點擊這裏>>
