

mab
多臂tiger機,又稱為mab。
同一個環境,動作,狀態下有可能返回1,有可能返回0。
也就是説環境反饋它不是一個固定的值。
可以假設為有五個函數,也就是相當於五種反饋,第一個函數返回1的概率是20%,返回0的概率是80%。
代碼實現:
import numpy as np
import pandas as pd
class MultiArmedBandit:
def __init__(self, n_arms, true_rewards):
self.n_arms = n_arms
self.true_rewards = true_rewards
self.estimates = np.zeros(n_arms) # 每個臂的獎勵估計
self.action_counts = np.zeros(n_arms) # 每個臂被選擇的次數
def select_arm(self, epsilon):
if np.random.rand() < epsilon:
return np.random.randint(self.n_arms) # 探索
else:
return np.argmax(self.estimates) # 開發
def update_estimates(self, chosen_arm, reward):
self.action_counts[chosen_arm] += 1
# 更新獎勵估計
self.estimates[chosen_arm] += (reward - self.estimates[chosen_arm]) / self.action_counts[chosen_arm]
def simulate_bandit(n_arms, true_rewards, n_rounds, epsilon):
bandit = MultiArmedBandit(n_arms, true_rewards)
rewards = np.zeros(n_rounds)
cumulative_rewards = np.zeros(n_rounds)
for round in range(n_rounds):
chosen_arm = bandit.select_arm(epsilon)
reward = np.random.normal(true_rewards[chosen_arm], 1) # 獎勵是正態分佈
bandit.update_estimates(chosen_arm, reward)
rewards[round] = reward
cumulative_rewards[round] = np.sum(rewards)
return cumulative_rewards
# 參數設置
n_arms = 5
true_rewards = [1.0, 1.5, 2.0, 0.5, 1.2] # 每個臂的真實獎勵均值
n_rounds = 1000
epsilon = 0.1
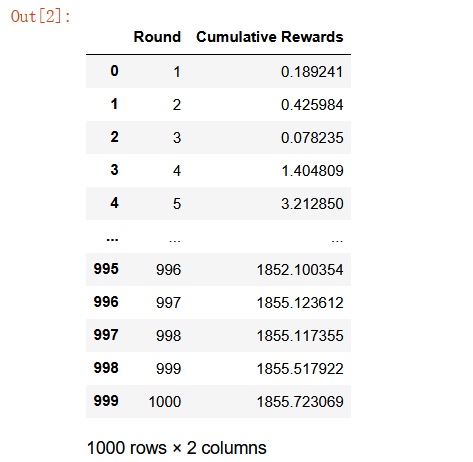
cumulative_rewards = simulate_bandit(n_arms, true_rewards, n_rounds, epsilon)
results_df = pd.DataFrame({
'Round': np.arange(1, n_rounds + 1),
'Cumulative Rewards': cumulative_rewards
})
results_df類定義:MultiArmedBandit
n_arms tiger機的數量
true_rewards 每個臂的真實平均獎勵
estimates 目前認為每個臂的平均回報是多少,初始全為0。
action_counts 記錄每個臂被拉了多少次,用於更新均值。
選擇臂:select_arm(self, epsilon)
然後定義一個隨機數。
以概率 ε 進行探索,也就是隨機選一個臂,以概率 1 - ε 進行開發(選當前估計獎勵最高的臂)。
比如説當 epsilon = 0.1:
-
10% 概率隨機探索
-
90% 概率選估計最好的那一個
更新估計值:update_estimates()
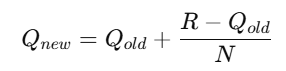
R 是這次的實際獎勵;N 是該臂被選過的次數;Q 是對該臂期望獎勵的估計。
模擬函數:simulate_bandit()
-
初始化一個
MultiArmedBandit實例; -
進行多輪(
n_rounds)實驗; -
每一輪:
-
用
select_arm()決定拉哪一台機器; -
根據真實均值
true_rewards[chosen_arm]生成一個服從正態分佈的獎勵; -
用
update_estimates()更新估計; -
記錄當前的獎勵和累計獎勵
-
效果如圖所示:
ucb
UCB算法是一種用於解決探索與利用問題的策略選擇方法,廣泛應用於多臂tiger機問題。
其核心思想是通過估計每個選項的潛在收益來平衡探索新選項和利用已知最佳選項 之間的權衡。
基本原理
-
探索與利用:
探索:嘗試新的選項以獲取更多的信息。
利用:選擇當前已知的最佳選項以最大化收益。
-
UCB值計算: 對於每個選項,UCB算法計算一個上置信界值也就是UCB值,該值結合了成功率和探索因子。
計算公式:
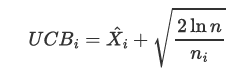
X_i 是選項 i 的成功率,即平均收益; n 是當前總的嘗試次數; n_i 是選項 i 的嘗試次數。
第一項是指當前已知的平均成功率;第二項是指置信區間,也就是越沒試過的策略,這項越大;比如説你去飯堂吃飯,吃過 10 次的店你知道它一般,但沒吃過的店你可能會想試一試,這就是 UCB 的探索機制。
應用場景 UCB算法廣泛應用於在線廣告推薦、A/B測試、動態定價、機器學習模型選擇等領域,尤其是在需要實時決策和反饋的環境中。
【----幫助網安學習,以下所有學習資料免費領!加vx:YJ-2021-1,備註 “博客園” 獲取!】
① 網安學習成長路徑思維導圖
② 60+網安經典常用工具包
③ 100+SRC漏洞分析報告
④ 150+網安攻防實戰技術電子書
⑤ 最權威CISSP 認證考試指南+題庫
⑥ 超1800頁CTF實戰技巧手冊
⑦ 最新網安大廠面試題合集(含答案)
⑧ APP客户端安全檢測指南(安卓+IOS)
ucb的通俗解釋:一個左撇子,用手拿東西的時候,用右手的概率是20% ,用左手的概率是80%由於第一次選擇的時候左右都會選,但是概率不同,選擇不同手的頻率就會影響兩邊ubc(可以理解為Q表)的值 那麼我們就可以根據兩邊受頻率影響的值動態調整我們是否選擇高的那邊的概率。
防火牆策略
假設有五個防火牆策略,並且攔截攻擊的成功率都不一致。
但是在實際項目中,不用都寫出成功率出來,畢竟只要知道哪個防火牆攔截的成功率高,那肯定優先選擇那個防火牆。
現在是不知道概率多少。
import numpy as np
import pandas as pd
def check1(payload):
return np.random.rand() < 0.5 # 50%成功率
def check2(payload):
return np.random.rand() < 0.7 # 70%成功率
def check3(payload):
return np.random.rand() < 0.4 # 40%成功率
def check4(payload):
return np.random.rand() < 0.3 # 30%成功率
def check5(payload):
return np.random.rand() < 0.6 # 60%成功率
# 將所有檢查函數放入列表中
check_functions = [check1, check2, check3, check4, check5]
# 定義防火牆策略選擇器類
class FirewallPolicySelector:
def __init__(self, n_policies):
self.n_policies = n_policies
self.successes = np.zeros(n_policies)
self.attempts = np.zeros(n_policies)
def select_policy(self):
total_attempts = np.sum(self.attempts)
if total_attempts == 0:
return np.random.randint(self.n_policies) # 如果沒有嘗試過,隨機選擇
ucb_values = self.successes / (self.attempts + 1e-5) + np.sqrt(2 * np.log(total_attempts) / (self.attempts + 1e-5))
return np.argmax(ucb_values) # 選擇UCB值最高的策略
def update(self, chosen_policy, success):
self.attempts[chosen_policy] += 1
self.successes[chosen_policy] += success
# 模擬防火牆策略優化過程
def simulate_firewall(n_policies, n_rounds):
policy_selector = FirewallPolicySelector(n_policies)
results = []
for round in range(n_rounds):
chosen_policy = policy_selector.select_policy()
payload = np.random.randint(0, 100) # 生成隨機攻擊樣本
success = check_functions[chosen_policy](payload) # 使用選定的check函數
policy_selector.update(chosen_policy, success)
results.append((round + 1, chosen_policy, success))
results_df = pd.DataFrame(results, columns=['輪次', '選擇的策略', '成功攔截'])
return results_df
# 參數設置
n_policies = len(check_functions) # 策略數量
n_rounds = 1000
# 運行模擬
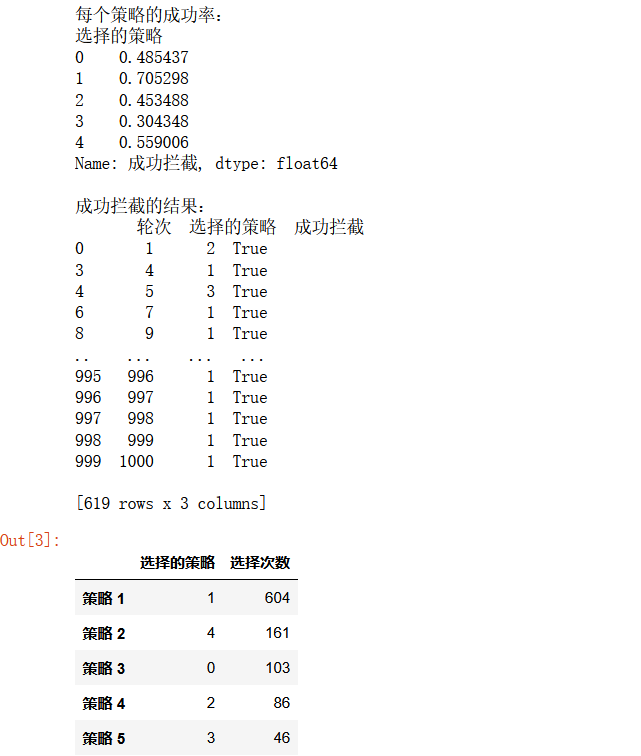
results_df = simulate_firewall(n_policies, n_rounds)
# 篩選出成功攔截的部分
successful_results = results_df[results_df['成功攔截'] == 1]
# 輸出每個策略的成功率
print("\n每個策略的成功率:")
print(results_df.groupby('選擇的策略')['成功攔截'].mean())
# 顯示成功攔截的結果
print("\n成功攔截的結果:")
print(successful_results)
# 統計每個策略的選擇次數
policy_counts = results_df['選擇的策略'].value_counts()
# 創建 DataFrame 顯示所有策略及其選擇次數
result_df = pd.DataFrame({
'選擇次數': policy_counts
}).reset_index()
# 重命名列
result_df.columns = ['選擇的策略', '選擇次數']
# 設置行標題
result_df.index = [f'策略 {i+1}' for i in range(len(result_df))]
result_df防火牆策略選擇器類 FirewallPolicySelector
n_policies: 策略數量;successes[i]: 第 i 個策略成功的次數;attempts[i]: 第 i 個策略被嘗試的次數
策略選擇核心 select_policy()
這裏用的ucb計算公式,在上述已貼出。
模擬防火牆運行:simulate_firewall()
循環共執行 n_rounds,比如 1000 輪:
選擇一個策略,然後模擬生成攻擊,接着判斷是否成功攔截,最後更新策略統計。
簡單來説,這份代碼就是模擬了一個基於UCB算法的自適應防火牆策略選擇系統,它通過統計每個檢測策略的歷史成功率和嘗試次數,自動在多輪攻擊中選擇最有效的策略,在“探索新方法”和“利用已知最優”之間取得平衡,最終趨向於選擇攔截率最高的策略。
效果如圖:
其實還有其他場景也適合,比如説什麼惡意代碼識別,郵箱識別,畢竟是策略選擇。
郵件攻防
假設現在有個角色A 通過mba模型實現強化學習下的優化釣魚郵件內容。
還有一個角色B 通過Q-learning的方式實現強化學習下的釣魚郵件內容識別。
當然也可以換成一邊是惡意軟件,一邊殺毒軟件,做一個養蠱哈哈。
整個流程就是攻擊方不斷髮送不同類型的釣魚郵件,防禦方在識別的過程中逐漸學習,而攻擊方也會記錄哪些內容更容易成功,從而傾向選擇這些高成功率內容。
import numpy as np
import pandas as pd
class PhishingContentOptimizer:
def __init__(self, contents, phishing_probabilities, epsilon=0.1):
self.contents = contents # 釣魚郵件內容列表
self.phishing_probabilities = phishing_probabilities # 各內容被識別為釣魚郵件的概率
self.epsilon = epsilon # 探索率
self.success_counts = np.zeros(len(contents)) # 各內容成功次數
self.total_counts = np.zeros(len(contents)) # 各內容嘗試次數
def select_content(self):
if np.random.rand() < self.epsilon:
return np.random.choice(self.contents) # 隨機選擇
else:
success_rates = self.success_counts / (self.total_counts + 1e-5) # 避免除零
return self.contents[np.argmax(success_rates)] # 選擇成功率最高的內容
def update(self, chosen_content, success):
index = self.contents.index(chosen_content)
self.total_counts[index] += 1
if success:
self.success_counts[index] += 1
class QLearningPhishingDetector:
def __init__(self, actions, learning_rate=0.1, discount_factor=0.9, exploration_rate=1.0):
self.q_table = {} # Q值表
self.actions = actions # 可採取的動作
self.learning_rate = learning_rate # 學習率
self.discount_factor = discount_factor # 折扣因子
self.exploration_rate = exploration_rate # 探索率
self.exploration_decay = 0.99 # 探索率衰減
def get_action(self, state):
if state not in self.q_table:
self.q_table[state] = [0] * len(self.actions)
if np.random.rand() < self.exploration_rate:
return np.random.choice(self.actions) # 探索
else:
return self.actions[np.argmax(self.q_table[state])] # 利用
def update_q_value(self, state, action, reward, next_state):
current_q = self.q_table[state]
max_future_q = max(self.q_table.get(next_state, [0] * len(self.actions)))
current_q[action] += self.learning_rate * (reward + self.discount_factor * max_future_q - current_q[action]) # 更新Q值
def decay_exploration(self):
self.exploration_rate *= self.exploration_decay
# 示例釣魚郵件內容及其被識別為釣魚郵件的概率
contents = [
"您的賬户存在異常,請立即驗證。",
"恭喜您獲得獎品,請點擊鏈接領取。",
"重要通知:請更新您的賬户信息。",
"您有新的消息,請查看。",
"系統升級,請確認您的信息。",
]
# 各內容被識別為釣魚郵件的概率
phishing_probabilities = {
contents[0]: 0.1,
contents[1]: 0.3,
contents[2]: 0.6,
contents[3]: 0.5,
contents[4]: 0.4,
}
# 初始化角色A(內容優化器)
optimizer = PhishingContentOptimizer(contents, phishing_probabilities)
# 初始化角色B(釣魚郵件識別器)
actions = [0, 1] # 0: 正常郵件, 1: 釣魚郵件
detector = QLearningPhishingDetector(actions)
# 預訓練階段
pretrain_steps = 50 # 預訓練步驟數
for _ in range(pretrain_steps):
chosen_content = np.random.choice(contents) # 隨機選擇內容
action = detector.get_action(chosen_content) # 識別郵件
# 根據內容的釣魚概率判斷
success = np.random.rand() < phishing_probabilities[chosen_content] if action == 1 else False
reward = 1 if action == 1 and success else -1 # 獎勵機制
detector.update_q_value(chosen_content, action, reward, chosen_content) # 更新Q值
detector.decay_exploration() # 衰減探索率
# 模擬釣魚攻擊過程
results = []
for _ in range(100): # 模擬100次釣魚攻擊
chosen_content = optimizer.select_content()
# 角色B識別郵件
action = detector.get_action(chosen_content) # 識別郵件
results.append({
'選擇的內容': chosen_content,
'識別結果': '釣魚郵件' if action == 1 else '正常郵件'
})
# 統計識別結果的成功率
for result in results:
if result['識別結果'] == '釣魚郵件':
# 根據內容的釣魚概率判斷
success = np.random.rand() < phishing_probabilities[result['選擇的內容']]
else:
success = False # 正常郵件識別為釣魚郵件的成功率為0
# 更新角色A的成功與否
optimizer.update(result['選擇的內容'], success)
# 更新角色B的Q值
reward = 1 if action == 1 and success else -1 # 獎勵機制
detector.update_q_value(result['選擇的內容'], action, reward, result['選擇的內容']) # 更新Q值
detector.decay_exploration() # 衰減探索率
# 轉換為DataFrame
results_df = pd.DataFrame(results)
# 輸出結果
print(results_df)
# 統計每個內容的使用頻率
content_counts = results_df['選擇的內容'].value_counts()
most_used_content = content_counts.idxmax()
most_used_count = content_counts.max()
# 篩選出使用最多的內容的結果
most_used_results = results_df[results_df['選擇的內容'] == most_used_content]
# 輸出使用最多的內容
print(f"\n使用最多的內容: {most_used_content}, 使用次數: {most_used_count}")
print("\n使用最多內容的結果:")
print(most_used_results)
# 統計識別結果為正常郵件的百分比
normal_email_count = results_df[results_df['識別結果'] == '正常郵件'].shape[0]
total_count = results_df.shape[0]
normal_email_percentage = (normal_email_count / total_count) * 100
print(f"\n識別結果為正常郵件的百分比: {normal_email_percentage:.2f}%")釣魚內容優化器 PhishingContentOptimizer
contents: 所有釣魚郵件的模板內容
phishing_probabilities: 每種內容被識別為釣魚的概率,也就是被識破的難度
epsilon: ε-貪婪算法中的“探索率”,比如 0.1 意味着 10% 概率隨機探索
success_counts: 各郵件“成功騙過檢測”的次數
total_counts: 每個內容被使用的次數
選擇內容 select_content
每輪發送郵件前,優化器根據歷史成功率決定發哪種內容:
-
90% 概率選擇成功率最高的郵件
-
10% 概率隨機選一個探索新的可能
這樣攻擊方會逐漸聚焦在最有效的郵件內容上。
釣魚郵件檢測器 QLearningPhishingDetector

更新 Q 值
update_q_value
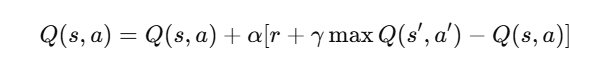
在狀態 s 採取動作 a 後,得到獎勵 r,下一狀態 s' 的最大潛在價值是 max_future_q,於是把當前的 Q 值往新的期望值方向更新一點。
預訓練階段,讓檢測器先學習
模擬 50 封訓練郵件,讓檢測器初步學會識別釣魚概率高的郵件。
獎勵邏輯:
-
檢測為釣魚且確實釣魚 → 獎勵 +1
-
否則 → 懲罰 -1
如果檢測器判斷為“釣魚郵件”,就按對應概率看它是否真識別成功, 否則認為識別失敗。
然後,攻擊方更新該郵件的成功率,防禦方更新Q值,探索率繼續衰減。
這裏其實還有個預訓練,先讓釣魚郵件識別器跑起來,學習裏面一些東西,分辨出哪個是釣魚郵件,哪個是正常郵件。
然後再去模擬釣魚郵件攻擊的過程,結果如下圖所示:

結果看起來比較發散,沒有那麼真實,其實可以把Q-Learing算法那一部分改為神經網絡。
GAN網絡其實就是Ai和Ai之間對打的過程。
更多網安技能的在線實操練習,請點擊這裏>>