

在分析一段字符串的時候,可以藉助字符串的indexOf等方法,或者是正則表達式,可是,如果需要解析的是下面這段字符串:
<group>
<arc c-bind:cx='_width*0.5' c-bind:cy='_height*0.5' c-bind:radius1='_min*0.5' radius2='100' deg='120deg'>
</arc>
<group c-for='value in dataList'>
<circle c-bind:cx='value' c-on:click='doit0' c-bind:cy='value' radius='10'></circle>
<text c-bind:x='value+20' c-bind:y='value' c-bind:content='value' fill-color='red'></text>
</group>
<path>
<move-to x='10' y='10'></move-to>
<line-to x='100' y='100'></line-to>
</path>
<text c-bind:x='_width*0.5' c-bind:y='_height*0.5'>文字</text>
</group>什麼時候可能會需要解析類似這樣的字符串?比如你可能希望的nodejs環境開發一個爬蟲,分析爬到的頁面內容,或者是像上面的設計,用html來表達希望繪製什麼樣的圖形後通過js在canvas畫布上繪製出用户的意圖等。
下面,我們來一起看看,具體的怎麼一步步分析處理上面的字符串包含的信息的。
我們把分析分為這幾個步驟: 分析出符號 → 分析出單詞 → 單詞信息分析 → 獲取整體信息
## 分析出符號
我們把一個最小的類似"語句"的稱為單詞(和編譯原理中的單詞加以區分),比如這裏的一個標籤,而為了得到單詞,首先需要分析的稱為符號。比如對 "<div>你好</div>"而言,就存在三個符號: "<div>"、"你好"和"</div>"。
因此,符號就是容易分析出且在此基礎上很容易分析出單詞的存在,具體什麼是符號,取決於分析的內容和目標。
上面的內容,分析出符號的最終結果就是:
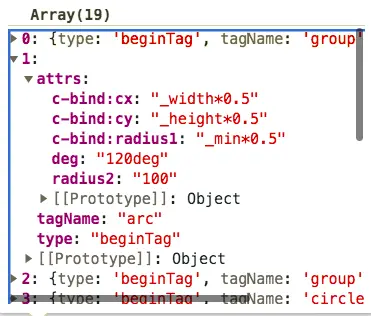
比如第二個符號,原始代碼是"<arc c-bind:cx='_width*0.5' c-bind:cy='_height*0.5' c-bind:radius1='_min*0.5' radius2='100' deg='120deg'>",經過分析得到,他是一個標籤的開始部分,名稱叫arc,有一些屬性等。
那麼,這樣的符號是如何分析出來的?很簡單,通過while循環即可。
在分析一個符號開始前,如果遇到的第一個非空白字符是"<",説明這是一個標籤(可能是開始、結束或自閉合的),直到遇到">"的時候,分析結束,也就是獲取了一個符號。
而如果在分析一個符號開始前,遇到的第一個非空白字符不是"<",説明這是一段文本,等遇到"<"的時候,回退一步即可獲得一段文本符號。
而對於標籤符號,只要在分析的時候額外加些判斷,就可以獲取更豐富的信息並獲取屬性值等。從而,就得到了上面的符號列表。
## 分析出單詞
在上面符號列表的基礎上,我們接下來將分析出下面的單詞列表:
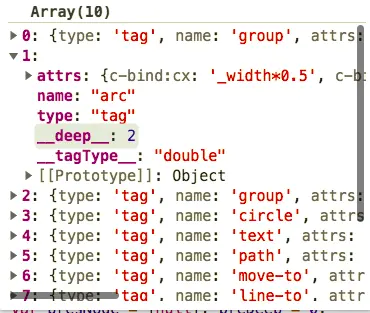
很明顯,單詞明顯比符號要少。那麼,如何通過符號列表獲取單詞列表?這會比上一步容易的多。
首先,你讀取了符號列表的第一個符號,如果是文本或者自閉合標籤,就已經獲取了第一個單詞,否則,一定是開始標籤。
現在,你把這個開始標籤存放到棧(先進後出)中去,並佔據單詞列表的一個位置,接着觀察下一個符號,如果是文本或者自閉合標籤,就是一個新的單詞,否則查看是否是開始標籤,如果是,同樣的處理,否則,判斷是否和當前棧頂的元素匹配,如果匹配,出棧並完成了一個單詞的匹配,不然就拋出錯誤。
如此反覆下去,直到符號列表遍歷完畢,觀察此時的棧,如果還有元素,可以默認自閉合即可。
## 單詞信息分析
在上一步,除了分析出單詞外,還需要額外給每個單詞標記層次(例如:根group是第一層,根的孩子是第二層,以此類推)。
層次是如何獲取的?比如,你當前的層次是deep,如果遇到的下一個符號是開始符號,那麼,下一個單詞(或文本,下同)的層次就一個是deep+1,如果遇到的是結束符號,下一個單詞就應該是deep-1,否則就依舊是deep。
獲取整體信息
對於一個字符串表達式而言,就是求值,對於json字符串而言,就是獲取json對象,而在此處,就是要獲取一個帶有關係的DOM樹。
先看看最終的結果:

我們拿節點"<circle c-bind:cx='value' c-on:click='doit0' c-bind:cy='value' radius='10'></circle>"舉例子。
通過parentNode和childNodes指明瞭它的父節點是第二個節點group,沒有孩子,前一個兄弟preNode為null沒有,後一個兄弟nextNode為4,也就是text標籤。
同樣的,我們來説説思路。
在單詞列表中,拿出一個單詞(其實也就是節點或文本節點),如果下一個單詞的deep和當前的一樣,就是兄弟關係,如果小一級,就是當前結點的孩子,這都比較容易。
如果比當前結點的deep大,怎麼辦?説明當前這個節點是葉子,需要回溯,回溯到deep和新的節點deep一樣的即可,那麼新的節點就是此節點的下一個兄弟,以此類推即可。
小結
上述關於解析字符串html的算法,已經封裝並對外開源: 解析xhtml為json對象











