

使用 JYPPX.DeploySharp 高效部署 PaddleOCR,解鎖多種高性能 OCR 文字識別方案
本文介紹如何通過 DeploySharp 框架在 .NET 環境下部署 PaddleOCR 模型,支持 OpenVINO、TensorRT、ONNX Runtime 等多種推理引擎,實現百毫秒級文字識別。
目錄
- 一、前言
- 二、核心技術原理解析
- 三、DeploySharp 架構優勢
- 四、支持的推理設備
- 五、快速開始指南
- 六、性能測試與分析
- 七、常見問題解答
- 八、軟件獲取
- 九、技術支持
一、前言
OCR(光學字符識別)技術在數字化辦公、文檔管理、票據識別等場景中發揮着重要作用。百度飛槳開源的 PaddleOCR 作為業界領先的 OCR 框架,以其優異的識別精度和豐富的功能特性深受開發者喜愛。
一年前,我基於自己開發的 OpenVINO C# API 項目,在 .NET 框架下使用 OpenVINO 部署工具部署 PaddleOCR 系列模型,推出了 PaddleOCR-OpenVINO-CSharp 項目。藉助 OpenVINO 在 CPU 上的強大推理優化能力,該項目成功實現了在純 CPU 環境下完成圖片文字識別、版面分析及表格識別等功能,推理速度可控制在 300 毫秒以內。
隨着項目的發展和應用場景的多樣化,單一推理引擎已無法滿足所有需求。近期,我將 OpenVINO、TensorRT、ONNX Runtime 等主流推理工具進行了統一封裝,推出了 DeploySharp 開源項目。該項目的核心優勢在於:
- 統一接口:通過底層接口抽象,實現一套代碼適配多種推理引擎
- 靈活部署:開發者可根據實際硬件環境選擇最優推理方案
- 性能優化:充分發揮各推理引擎的硬件加速能力
得益於 DeploySharp 底層接口統一的優勢,開發者現在可以用同一段代碼在 OpenVINO、TensorRT、ONNX Runtime 等多種推理引擎間自由切換。近期,我們完成了 PaddleOCR 模型的支持更新,為 .NET 開發者提供了一套完整的 OCR 解決方案。
目前,PaddleOCR 功能已集成至 DeploySharp 開源項目中(代碼已上傳至倉庫,NuGet 包正在籌備中)。為了讓大家快速體驗新版 PaddleOCR 的極致性能,我們特別準備了 JYPPX.DeploySharp.OpenCvSharp.PaddleOcr.TestDemo 演示程序,支持即開即用,無需複雜配置。
二、核心技術原理解析
2.1 PaddleOCR 工作流程
PaddleOCR 採用經典的「檢測-分類-識別」三階段流水線架構:
輸入圖片
│
▼
┌─────────────┐
│ 文本檢測 │ → 檢測圖片中的文本區域位置
│ (Detection) │
└─────────────┘
│
▼
┌─────────────┐
│ 文本方向分類 │ → 判斷文本方向(180度翻轉等)
│ (Classifier)│
└─────────────┘
│
▼
┌─────────────┐
│ 文本識別 │ → 識別文本區域的具體內容
│ (Recognition)│
└─────────────┘
│
▼
輸出識別結果
2.2 三階段模型詳解
| 階段 | 模型名稱 | 輸入 | 輸出 | 作用 |
|---|---|---|---|---|
| 檢測 | PP-OCRv5_det | 原始圖片 (3xHxW) | 文本框座標 | 定位文本區域 |
| 分類 | PP-OCRv5_cls | 裁剪文本框 (3x80x160) | 方向標籤 | 糾正文本方向 |
| 識別 | PP-OCRv5_rec | 裁剪文本框 (3x48xL) | 文本內容 | 識別字符序列 |
2.3 性能優化策略
- 模型量化:使用 int8 量化減小模型體積,提升推理速度
- 動態批處理:支持 Batch Size > 1,提高 GPU 利用率
- 併發推理:支持多線程併發處理,充分利用多核性能
- 硬件加速:針對不同硬件選擇最優計算後端
三、DeploySharp 架構優勢
DeploySharp 的核心設計理念是「統一接口,靈活部署」,其架構如下圖所示:
┌─────────────────────────────────────────────────────────┐
│ 應用層 (Application) │
│ PaddleOCR 文字識別 / 其他模型應用 │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ DeploySharp 抽象接口層 │
│ 統一的模型加載 / 推理執行 / 資源管理接口 │
└─────────────────────────────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ OpenVINO │ │ TensorRT │ │ ONNX Runtime │
│ Engine │ │ Engine │ │ Engine │
│ (CPU 優化) │ │ (GPU 加速) │ │ (跨平台支持) │
└───────────────┘ └───────────────┘ └───────────────┘
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Intel CPU │ │ NVIDIA GPU │ │ 多種硬件設備 │
│ │ │ │ │ (CPU/GPU/DML) │
└───────────────┘ └───────────────┘ └───────────────┘
主要優勢:
- 零代碼切換:更換推理引擎無需修改業務代碼
- 資源高效利用:自動管理模型生命週期和計算資源
- 擴展性強:易於添加新的推理引擎支持
- 生產就緒:經過充分測試,可直接用於生產環境
四、支持的推理設備
本演示程序支持多種主流推理後端,覆蓋從入門級設備到高性能服務器的各種場景:
| 推理引擎 | 支持設備 | 適用場景 | 性能特點 |
|---|---|---|---|
| OpenVINO | CPU | 無 GPU 環境、Intel 處理器 | CPU 優化,啓動快,穩定 |
| TensorRT | CUDA 11/12 | NVIDIA GPU 高性能場景 | GPU 加速,極致性能,需模型轉換 |
| ONNX Runtime CPU | CPU | 跨平台部署 | 通用性強,性能中等 |
| ONNX Runtime CUDA | CUDA 12 | NVIDIA GPU 環境部署 | GPU 加速,開箱即用 |
| ONNX Runtime TensorRT | CUDA 12 | NVIDIA GPU 高性能場景 | GPU 加速 + TensorRT 優化 |
| ONNX Runtime DML | DML GPU | Windows 平台多廠商 GPU | 支持 AMD/NVIDIA/Intel GPU |
性能提示:首次加載模型和推理時會較慢,這是正常現象(模型初始化和 JIT 編譯)。首次運行時請避免頻繁操作,待模型預熱完成後性能將顯著提升。
五、快速開始指南
5.1 程序界面概覽
運行程序後,主界面如下圖所示:
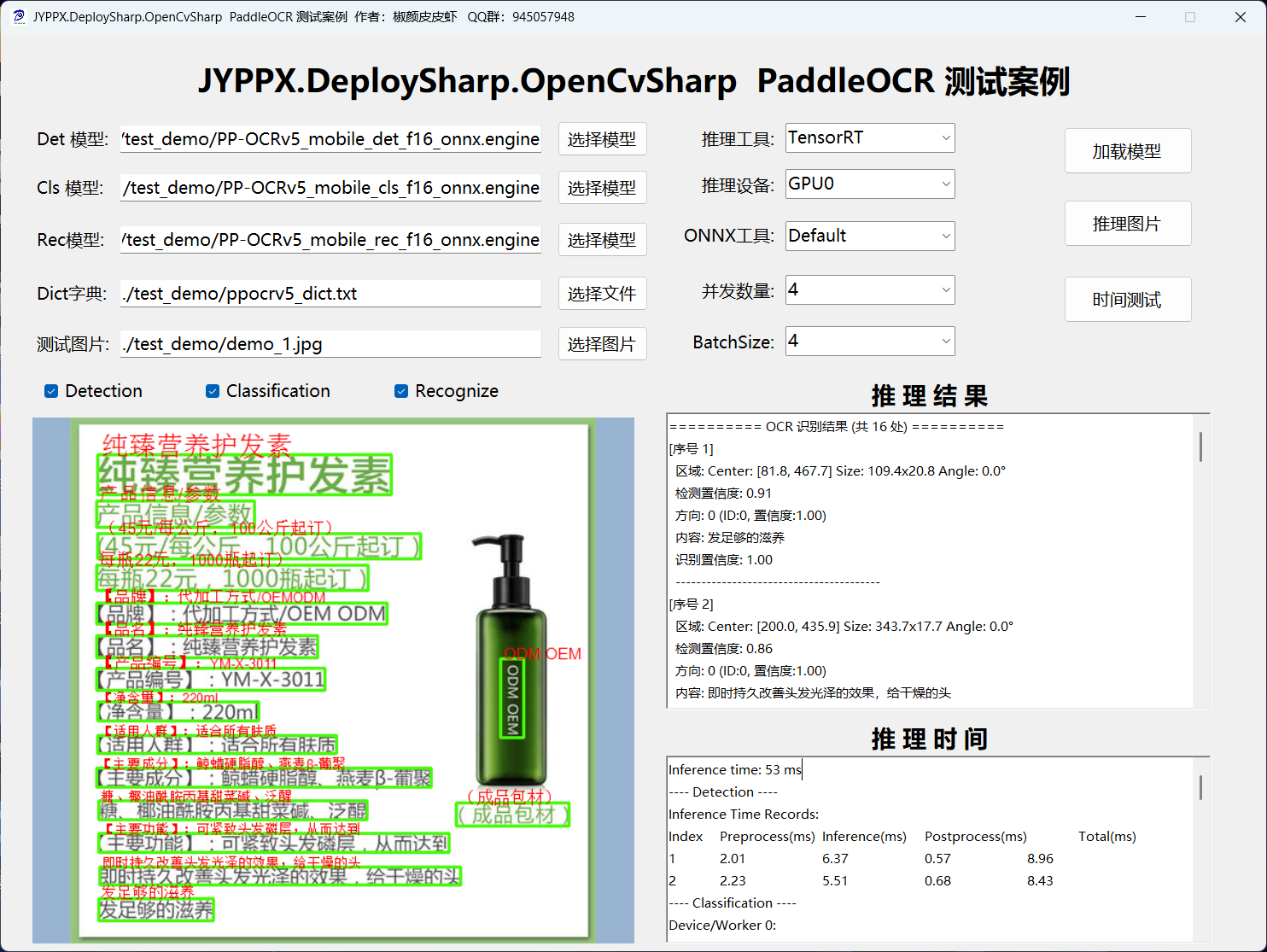
核心操作説明:
| 操作項 | 説明 | 注意事項 |
|---|---|---|
| 推理後端 | 選擇使用的推理引擎 | 切換後需重新加載模型 |
| 模型路徑 | 預置模型路徑,一般無需修改 | 支持自定義模型路徑 |
| 圖像路徑 | 選擇待識別的圖片 | 支持 JPG/PNG/BMP 等格式 |
| 加載模型 | 加載指定模型到內存 | 首次使用必須執行 |
| 推理圖片 | 執行單次圖片識別 | 首次需預熱 |
| 時間測試 | 連續推理十次並統計平均耗時 | 用於性能評估 |
| 併發數量 | 調整推理併發線程數 | 修改後需重新加載模型 |
| BatchSize | 批量處理大小 | 可動態調整 |
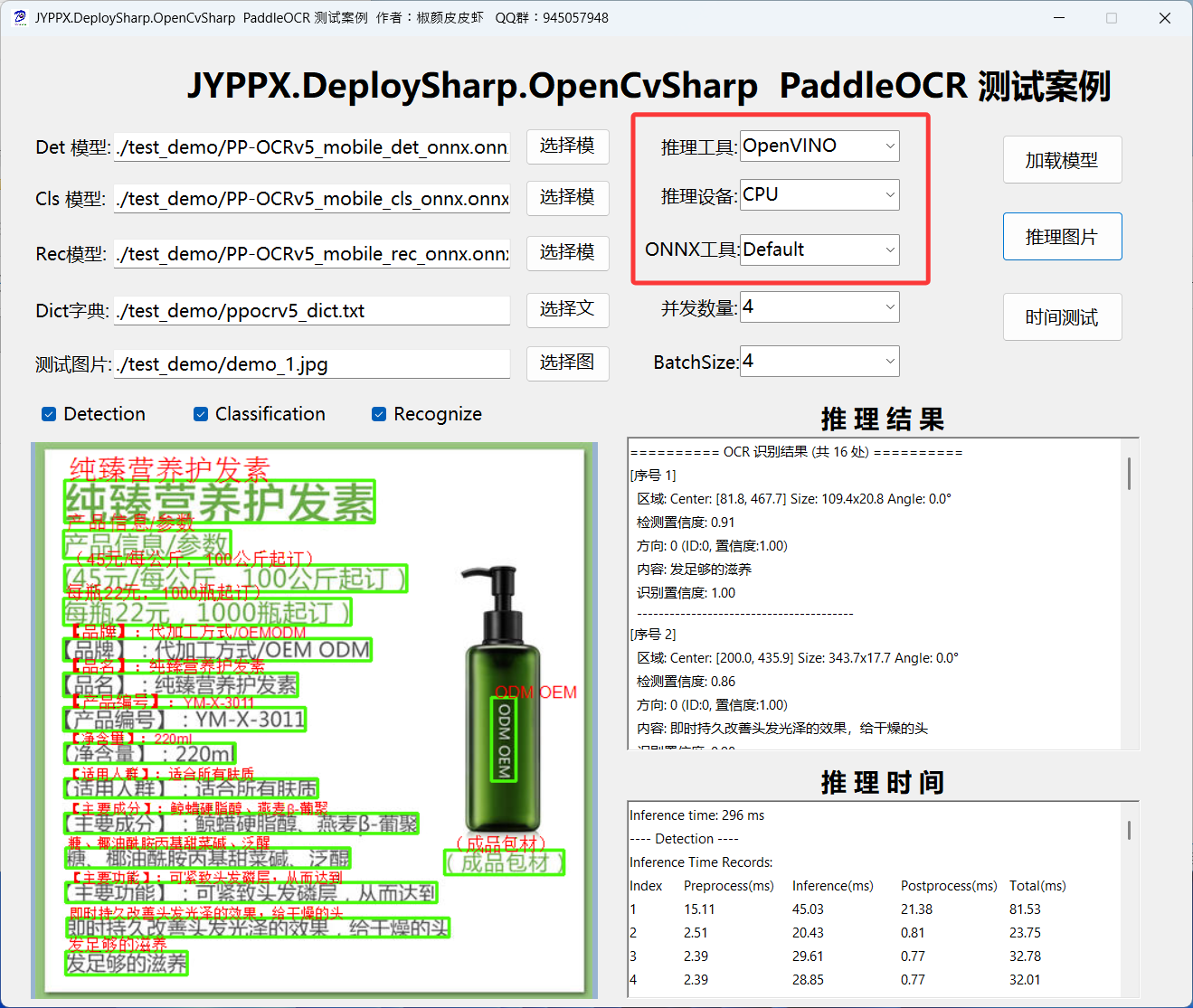
5.2 OpenVINO 推理
OpenVINO 是 Intel 推出的開源工具套件,針對 CPU 和Intel IGPU進行了深度優化,特別適合無 GPU 環境下的高性能推理。
CPU使用步驟:
1.運行程序
2.在「推理後端」下拉框中選擇 OpenVINO
3.點擊「加載模型」
4.點擊「推理圖片」開始識別
IGPU使用步驟:
英特爾集顯使用流程與上述一致,主要是設備要選擇GPU0:
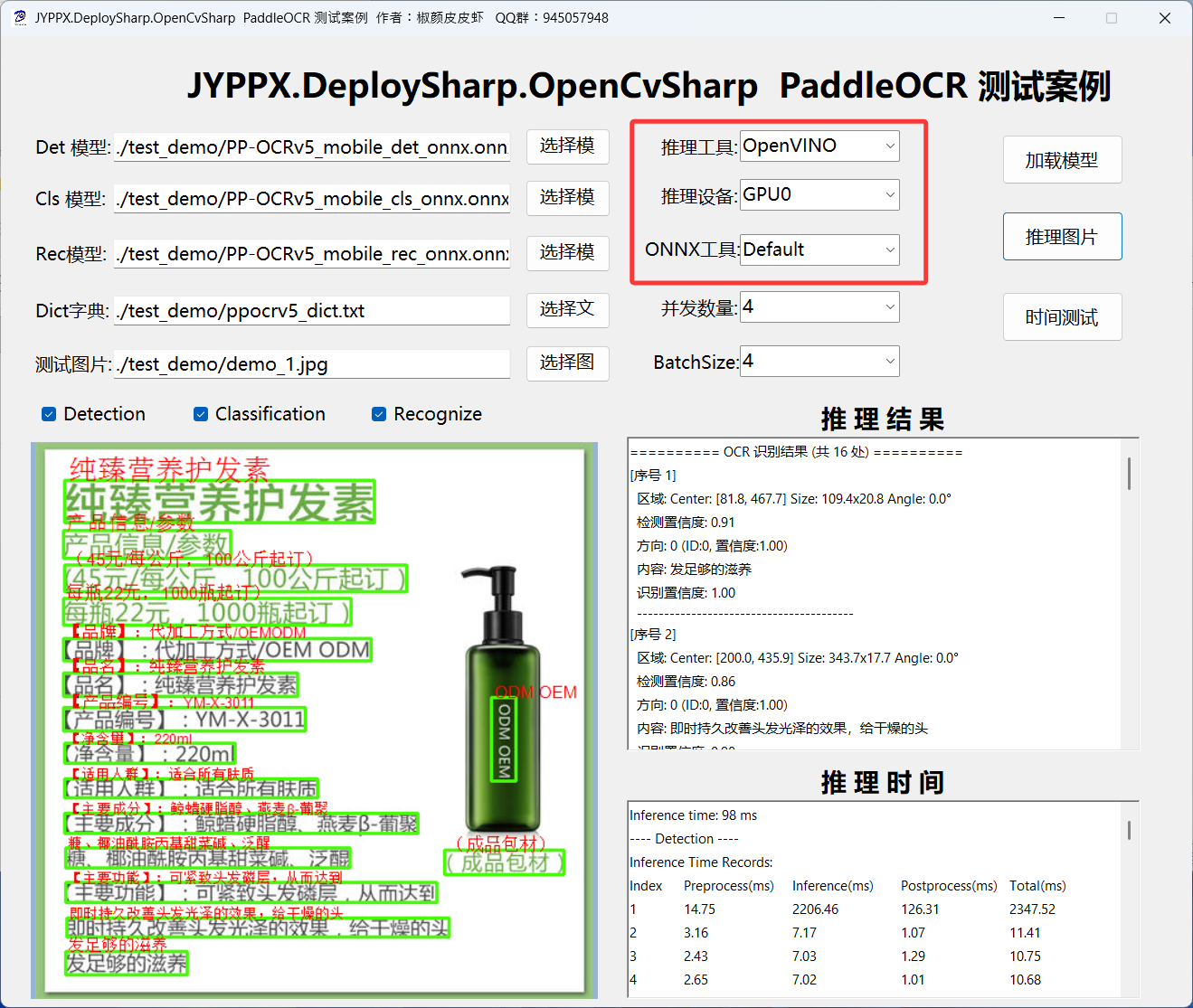
混合設備使用步驟:
英特爾OpenVINO支持CPU+IGPU混合設備推理,即AUTO模式,OpenVINO會根據設備情況自主選擇,使用方式與上述一致,主要是設備要選擇AUTO:
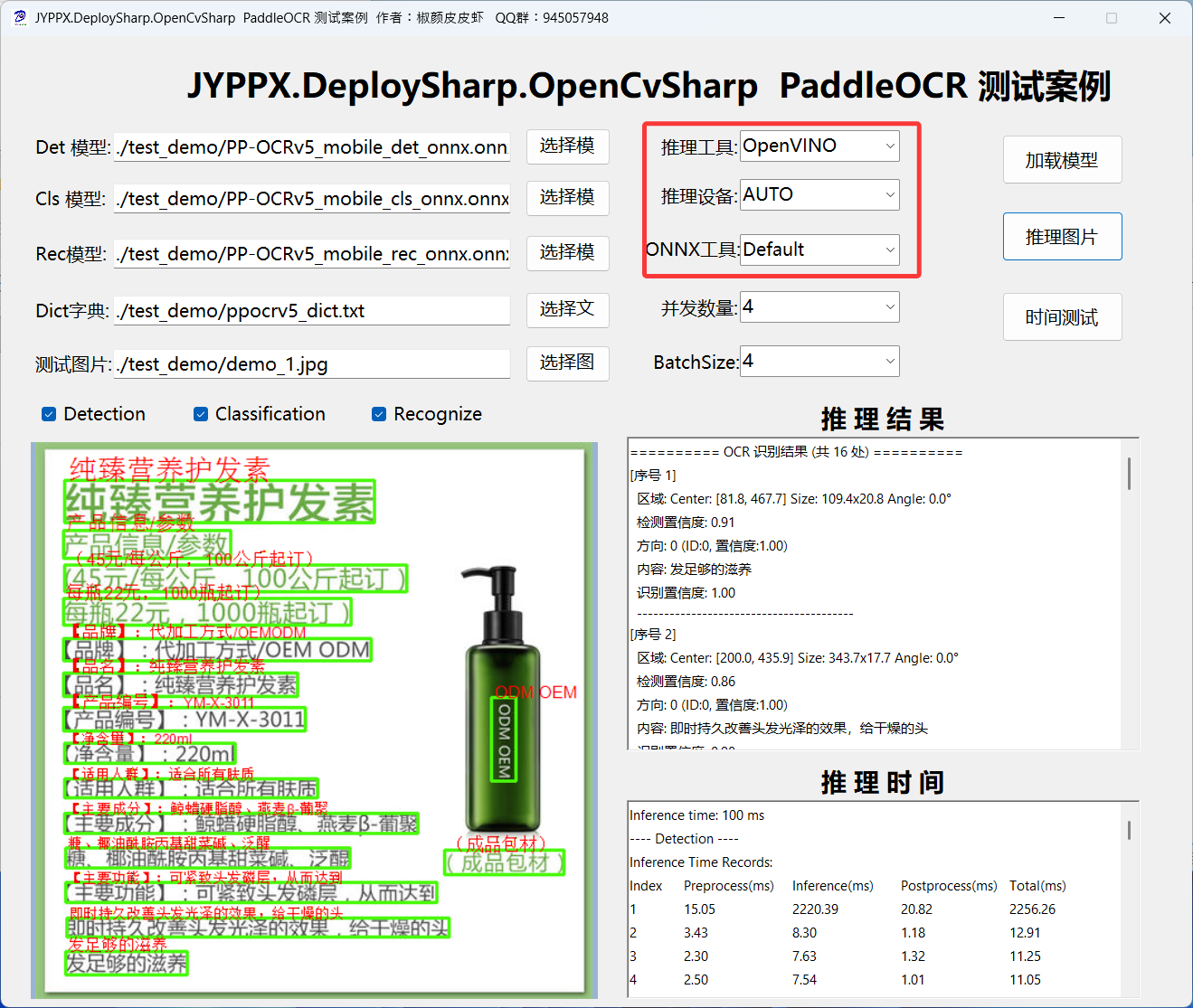
適用場景:
- 服務器環境部署
- 低功耗設備
- Intel CPU 用户
- 對啓動速度要求高的場景
5.3 ONNX Runtime CPU 推理
ONNX Runtime 是微軟推出的跨平台推理引擎,支持多種硬件加速後端,CPU 模式無需任何依賴即可使用。
使用步驟:
- 運行程序
- 在「推理後端」下拉框中選擇 ONNX Runtime CPU
- 點擊「加載模型」
- 點擊「推理圖片」開始識別
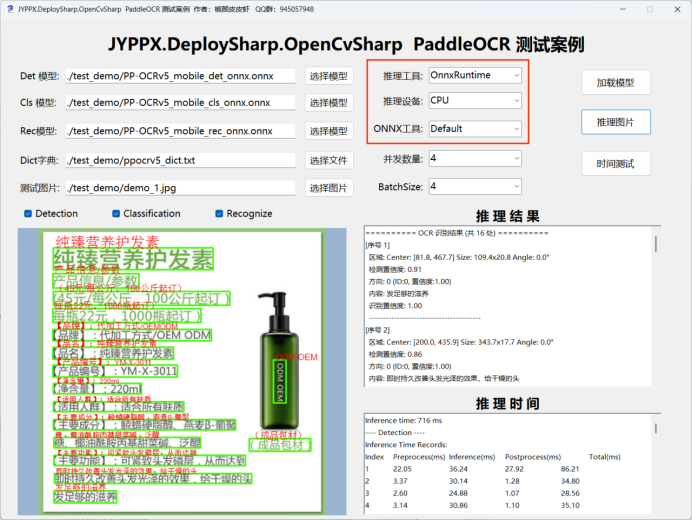
適用場景:
- 跨平台部署需求
- 無 GPU 加速環境
- 需要快速原型驗證
5.4 ONNX Runtime CUDA 推理
CUDA 是 NVIDIA 提供的並行計算平台,可充分利用 GPU 的並行計算能力實現顯著加速。
配置步驟
-
安裝 CUDA 驅動
- 訪問 NVIDIA CUDA 官網
- 下載並安裝 CUDA 12.x 版本(測試環境:CUDA 12.3)
-
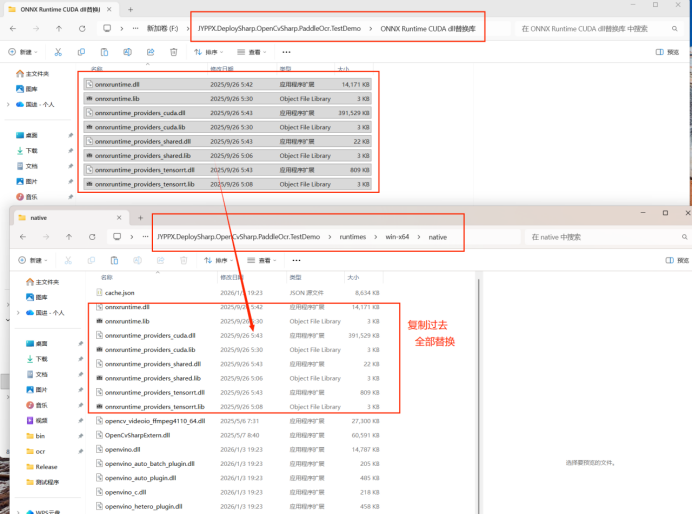
複製依賴文件
將以下 CUDA 相關 DLL 文件複製到程序運行目錄:
![CUDA 依賴文件]()
-
啓動推理
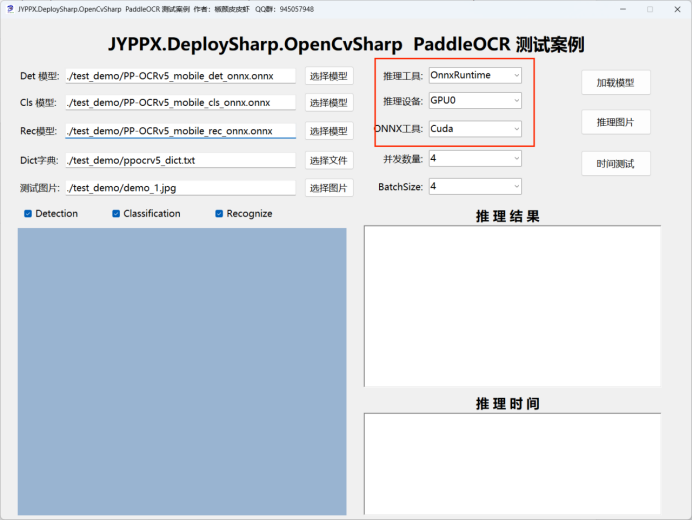
運行程序,在「推理後端」下拉框中選擇 ONNX Runtime CUDA
![ONNX Runtime CUDA 選擇界面]()
依賴説明:
| NuGet 包名 | 版本 |
|---|---|
| Microsoft.ML.OnnxRuntime.Gpu.Windows | 1.23.0 |
| Microsoft.ML.OnnxRuntime.Managed | 1.23.0 |
適用場景:
- 擁有 NVIDIA 顯卡的設備
- 對推理速度有較高要求
- 需要快速部署無需模型轉換
5.5 ONNX Runtime TensorRT 推理
TensorRT 是 NVIDIA 推出的高性能深度學習推理優化器,結合 CUDA 加速可達到極致性能。
配置步驟
依賴文件複製方式與 CUDA 模式一致。
使用步驟
- 運行程序
- 在「推理後端」下拉框中選擇 ONNX Runtime TensorRT
- 點擊「加載模型」
- 點擊「推理圖片」開始識別
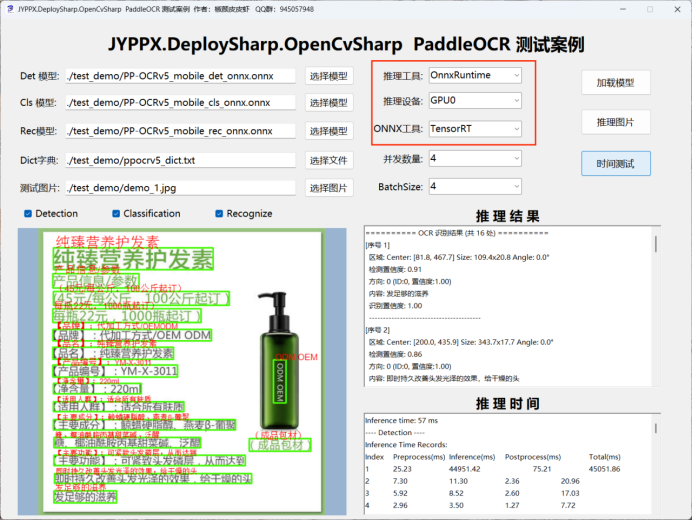
重要提示:首次運行推理時,TensorRT 會自動對 ONNX 模型進行優化編譯,此過程可能需要數分鐘,請耐心等待。編譯後的引擎文件會被緩存,後續推理速度將大幅提升。
依賴説明:
| NuGet 包名 | 版本 |
|---|---|
| Microsoft.ML.OnnxRuntime.Gpu.Windows | 1.23.2 |
| Microsoft.ML.OnnxRuntime.Managed | 1.23.2 |
適用場景:
- 對推理速度要求極高的生產環境
- NVIDIA GPU 設備
- 可接受首次運行較長的編譯時間
5.6 ONNX Runtime DML 推理
DirectML(DML)是 Windows 平台的高性能硬件加速接口,支持 AMD、NVIDIA 和 Intel 多廠商顯卡。
配置步驟
將 DML 相關 DLL 文件複製到程序運行目錄:
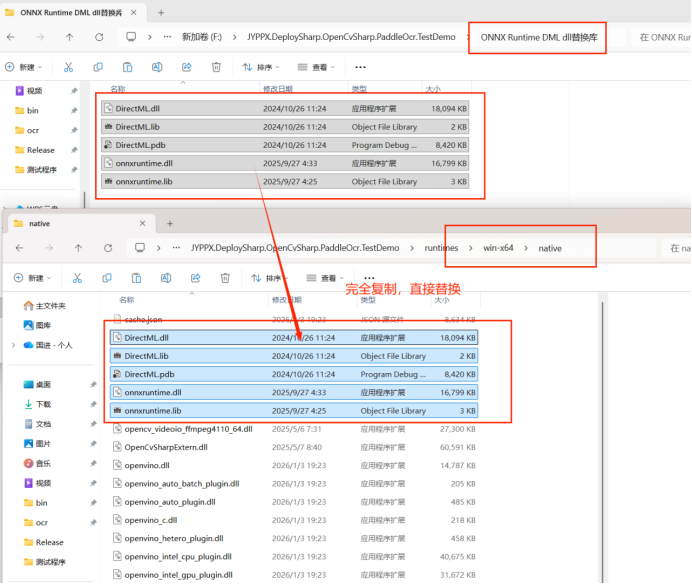
使用步驟
- 運行程序
- 在「推理後端」下拉框中選擇 ONNX Runtime DML
- 點擊「加載模型」
- 點擊「推理圖片」開始識別
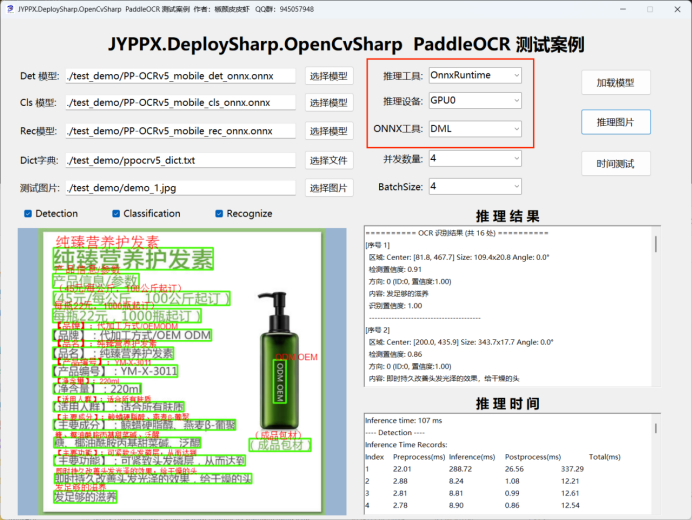
適用場景:
- Windows 平台用户
- AMD 顯卡用户
- 需要統一接口支持多品牌顯卡
5.7 TensorRTSharp 推理
TensorRTSharp 是對 NVIDIA TensorRT 的 C# 封裝,提供原生的 TensorRT 引擎加載和推理能力,支持 FP16 精度進一步提升性能。
環境準備
詳細的安裝和配置指南請參考:
https://mp.weixin.qq.com/s/D0c6j5MmraJO4Eza7tWm1A
TensorRTSharp 支持 CUDA 11 和 CUDA 12 兩個系列,請根據系統安裝的 CUDA 版本選擇對應的 DLL 文件。
配置步驟
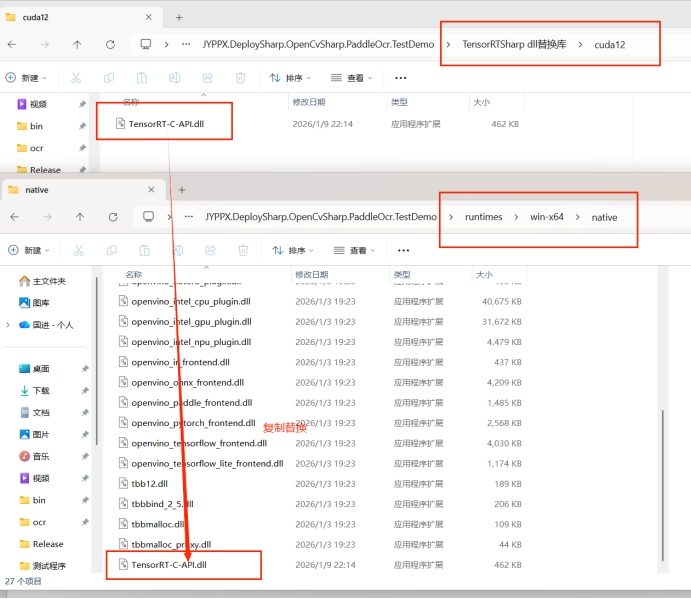
-
替換 DLL 文件
根據安裝的 CUDA 版本,將對應的 TensorRT DLL 文件複製到程序目錄:
![TensorRT DLL 文件]()
-
模型轉換
使用
trtexec工具將 ONNX 模型轉換為 TensorRT 引擎文件:![trtexec 轉換工具]()
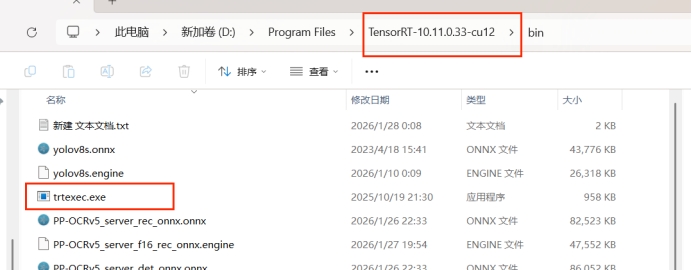
模型轉換指令
文本檢測模型(Det):
trtexec.exe --onnx=PP-OCRv5_mobile_det_onnx.onnx \
--minShapes=x:1x3x32x32 \
--optShapes=x:4x3x640x640 \
--maxShapes=x:8x3x960x960 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_det_f16_onnx.engine
文本分類模型(Cls):
trtexec.exe --onnx=PP-OCRv5_mobile_cls_onnx.onnx \
--minShapes=x:1x3x80x160 \
--optShapes=x:8x3x80x160 \
--maxShapes=x:64x3x80x160 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_cls_f16_onnx.engine
文本識別模型(Rec):
trtexec.exe --onnx=PP-OCRv5_mobile_rec_onnx.onnx \
--minShapes=x:1x3x48x48 \
--optShapes=x:8x3x48x1024 \
--maxShapes=x:64x3x48x1024 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_rec_f16_onnx.engine
開始推理
模型轉換完成後,在程序中選擇對應的 .engine 文件即可開始推理:
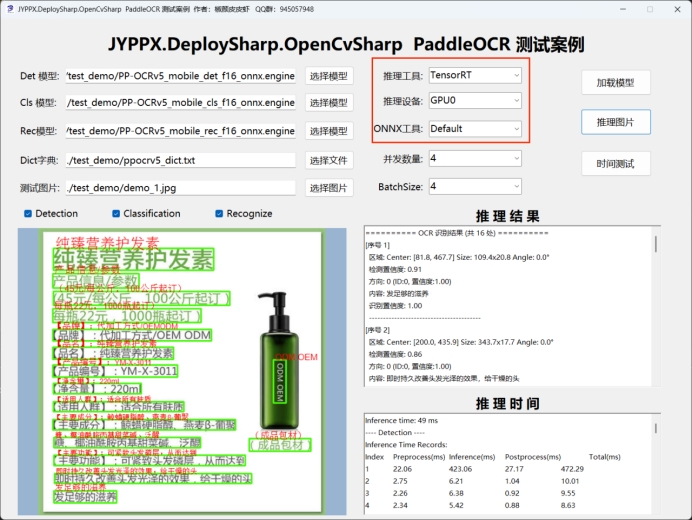
適用場景:
- 追求極致推理性能
- NVIDIA GPU 環境
- 允許離線模型轉換
六、性能測試與分析
6.1 性能測試工具
演示程序內置了完整的性能測試工具,支持兩種測試模式:
- 整體耗時統計:計算從圖片輸入到結果輸出的完整端到端耗時
- 詳細階段分析:記錄預處理、推理、後處理各階段的具體耗時
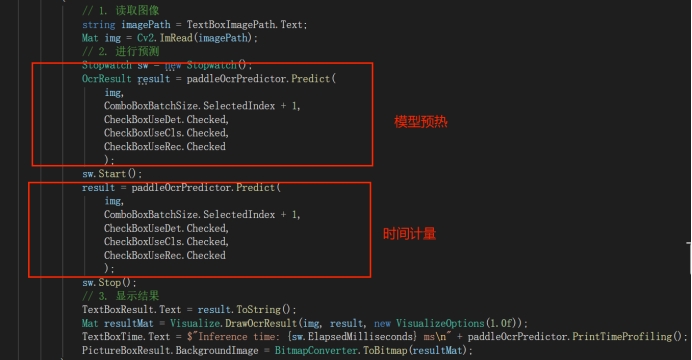
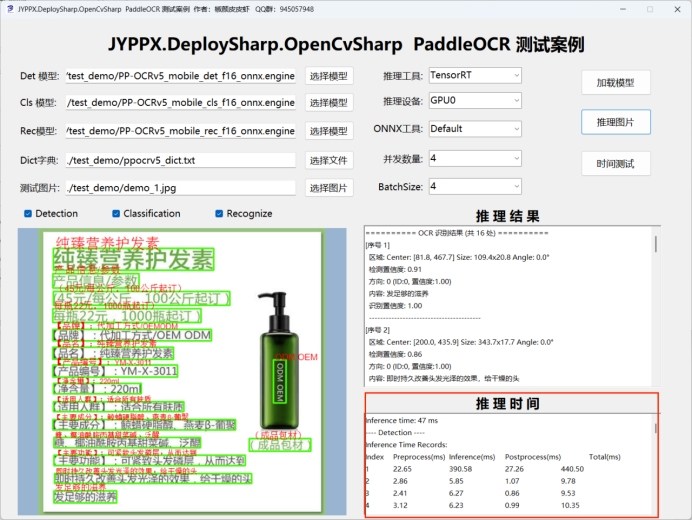
6.2 TensorRTSharp 性能示例
以下為使用 TensorRTSharp 在 4 併發配置下的性能測試數據:
Inference time: 53 ms
---- Detection ----
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 2.01 6.37 0.57 8.96
2 2.23 5.51 0.68 8.43
---- Classification ----
Device/Worker 0:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.84 6.89 0.00 8.73
2 1.99 6.97 0.01 8.96
Device/Worker 1:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.79 6.66 0.00 8.46
2 1.66 7.60 0.00 9.26
Device/Worker 2:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.61 5.31 0.00 6.92
2 1.51 8.01 0.00 9.53
Device/Worker 3:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.24 7.73 0.00 8.98
2 1.82 8.35 0.00 10.17
---- Recognition ----
Device/Worker 0:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 41.97 1.42 43.39
2 0.00 14.50 2.30 16.81
Device/Worker 1:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 47.40 6.81 54.21
2 0.00 19.42 2.76 22.18
Device/Worker 2:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 38.10 3.42 41.52
2 0.00 22.36 3.37 25.73
Device/Worker 3:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 109.94 4.58 114.52
2 0.00 26.59 4.55 31.14
6.3 性能對比總結
下表為使用洗髮水圖片,跑10次的平均時間測試:
| 推理引擎 | 設備 | 平均耗時 | 設備類型 |
|---|---|---|---|
| OpenVINO | CPU | 288ms | Intel(R) Core(TM) Ultra 9 288V 8核 |
| OpenVINO | IGPU | 99ms | Intel(R) Arc(TM) 140V GPU (16GB) |
| OpenVINO | 混合 AUTO:IGPU+CPU | 100ms | Intel(R) Core(TM) Ultra 9 288V 8核
Intel(R) Arc(TM) 140V GPU (16GB) |
| ONNX Runtime | CPU | 656ms | AMD Ryzen 7 5800H with Radeon Graphics 8核 |
| ONNX Runtime DML | GPU | 114ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| ONNX Runtime DML | IGPU | 331ms | Intel(R) Arc(TM) 140V GPU (16GB) |
| ONNX Runtime CUDA | GPU | 93ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| ONNX Runtime TensorRT | GPU | 52ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| TensorRTSharp | GPU | 51ms | NVIDIA GeForce RTX 3060 Laptop GPU |
性能測試徵集:我們歡迎廣大開發者分享各自的測試數據。請在評論區提供您的測試配置(硬件型號、併發數、Batch Size)和實測耗時,後續我們將整理成性能基準對比表。
七、常見問題解答
Q1: 首次推理為什麼特別慢?
A: 首次推理時需要進行以下操作:
- 模型加載到內存
- 推理引擎初始化
- JIT 編譯(部分引擎)
這是正常現象,後續推理速度會顯著提升。
Q2: 如何選擇合適的推理引擎?
A: 根據硬件環境和需求選擇:
| 場景 | 推薦引擎 |
|---|---|
| 無 GPU,有Intel CPU,追求穩定性 | OpenVINO |
| 有Intel GPU,需要跨平台 | OpenVINO |
| 無 GPU,需要跨平台 | ONNX Runtime CPU |
| 有 NVIDIA 顯卡,快速部署 | ONNX Runtime CUDA |
| 有 NVIDIA 顯卡,追求性能 | ONNX Runtime TensorRT / TensorRTSharp |
| Windows 平台,AMD 顯卡 | ONNX Runtime DML |
Q3: 切換推理引擎時為什麼需要重新加載模型?
A: 不同推理引擎對模型格式的內部表示和優化策略不同,因此需要重新解析和加載模型。點擊「加載模型」即可完成切換。
Q4: BatchSize 和併發數量有什麼區別?
A: 兩個參數的作用不同:
- BatchSize:單次推理處理的圖片數量,提升 GPU 利用率
- 併發數量:同時運行的推理引擎數量,設置幾個就會生成幾個推理引擎進行同時推理,提升多核/CPU 利用率
調整 BatchSize 不需要重新加載模型,但調整併發數量後需要重新加載。
Q5: TensorRT 模型轉換失敗怎麼辦?
A: 檢查以下幾點:
- 確保 CUDA 版本與 TensorRT 版本匹配
- 檢查 ONNX 模型文件是否完整
- 確認
trtexec參數中輸入尺寸範圍合理 - 如顯存不足,減小
--memPoolSize參數
Q6: 推理結果為空或識別不準確怎麼辦?
A: 常見原因和解決方法:
- 圖片質量:檢查圖片是否模糊、傾斜或光照不足
- 輸入尺寸:確保圖片尺寸符合模型輸入要求
- 語言支持:確認模型是否支持目標語言
- 模型版本:嘗試使用不同版本的 PaddleOCR 模型
八、軟件獲取
8.1 源碼下載
DeploySharp 項目已完全開源,可通過以下方式獲取:
主倉庫:
https://github.com/guojin-yan/DeploySharp.git
PaddleOCR 演示程序:
https://github.com/guojin-yan/DeploySharp/tree/DeploySharpV1.0/applications/JYPPX.DeploySharp.OpenCvSharp.PaddleOcr
8.2 可執行程序
如需直接獲取編譯好的可執行程序,請加入技術交流羣,從羣文件下載最新版本。
九、技術支持
9.1 反饋與交流
- GitHub Issues:在項目倉庫提交 Issue 或 Pull Request
- QQ 交流羣:加入 945057948,獲取實時技術支持

9.2 相關資源
- PaddleOCR 官方項目:https://github.com/PaddlePaddle/PaddleOCR
- OpenVINO 官方文檔:https://docs.openvino.ai/
- TensorRT 官方文檔:https://docs.nvidia.com/deeplearning/tensorrt/
- ONNX Runtime 官方文檔:https://onnxruntime.ai/docs/
結語
通過 DeploySharp 框架,我們成功實現了 PaddleOCR 在 .NET 環境下的高效部署。無論是純 CPU 環境下的穩定運行,還是 GPU 加速下的極致性能,開發者都可以根據實際需求靈活選擇。
未來,我們將持續優化框架性能,支持更多模型類型和推理引擎,為 .NET 開發者提供更完善的 AI 模型部署解決方案。
作者:Guojin Yan
最後更新:2026年1月
【文章聲明】
本文主要內容基於作者的研究與實踐,部分表述藉助 AI 工具進行了輔助優化。由於技術侷限性,文中可能存在錯誤或疏漏之處,懇請各位讀者批評指正。如果內容無意中侵犯了您的權益,請及時通過公眾號後台與我們聯繫,我們將第一時間核實並妥善處理。感謝您的理解與支持!