
引言
在人工智能領域,將大型語言模型(LLM)從簡單的無狀態問答機器轉變為能夠進行連貫、有上下文感知對話的複雜智能體,其核心關鍵在於內存。LLM 本身是無狀態的,每次調用都是一次獨立的計算,它們不會天生記得之前的交互。為了構建能夠學習、適應和維護長期關係的智能體,開發者必須為其提供一個堅實的狀態管理框架。LangGraph 正是為此而生,它提供了一個強大而靈活的解決方案。
本指南旨在深入剖析 LangGraph 的內存架構,這是一個精心設計的雙系統,旨在模擬不同層次的人類記憶。我們將全面探討其兩大核心組件:
- 短期記憶(通過 Checkpointer 實現):負責捕捉單次對話中逐輪變化的上下文和狀態。這類似於人類的工作記憶,讓我們能夠流暢地進行一次對話,記住對方剛剛説了什麼。
- 長期記憶(通過 Store 實現):負責存儲跨越多次對話的持久化知識、用户偏好和核心事實。這好比人類的長期記憶,儲存着我們的身份、知識和經歷。
本教程將引導您從基本概念出發,逐步深入到生產級的內存管理策略。我們將通過詳盡的代碼示例和深入的架構分析,揭示如何利用 LangGraph 的內存機制來構建真正智能、有狀態的 AI 應用程序。無論您是希望構建一個簡單的聊天機器人,還是一個複雜的多智能體系統,對 LangGraph 內存的深刻理解都將是您成功的基石。
第一部分:LangGraph 內存的架構基礎
要精通 LangGraph 的內存管理,首先必須建立一個清晰的心理模型,理解其兩套內存系統的設計哲學。這兩個系統——Checkpointer 和 Store——並非相互替代,而是相輔相成,共同為智能體提供全面、多層次的記憶能力。
1.1 短期記憶:通過 Checkpointer 實現的對話線程
短期記憶在 LangGraph 中被定義為“線程級別的持久化”(thread-level persistence)。其核心目標是記錄和恢復在單次連續交互(即一個“線程”)中圖(Graph)的狀態演變。
核心機制:Checkpointer
Checkpointer 是 LangGraph 短期記憶的引擎。它的工作模式是自動化的:每當圖執行一步(例如,調用一個節點函數),checkpointer 就會自動將圖的當前完整狀態(State)保存為一個快照,即“檢查點”(Checkpoint)。
關鍵標識符:thread_id
thread_id 是激活和區分不同對話線程的唯一鑰匙。在調用圖的 invoke 或 stream 方法時,通過 configurable 字典傳入一個 thread_id,就等於告訴 LangGraph:“這次操作屬於這個特定的對話”。在執行前,LangGraph 會使用這個 thread_id 從後端加載最新的檢查點,恢復對話狀態;執行完畢後,它會再次使用同一個 thread_id 保存更新後的狀態。這種機制確保了對話的連續性 。
概念類比:瀏覽器會話 Cookie
可以將 checkpointer 和 thread_id 的關係類比為網站的會話(Session)Cookie。當您登錄一個網站後,瀏覽器會保存一個會話 Cookie。在您瀏覽不同頁面時,網站通過這個 Cookie 識別您的身份,從而保持您的登錄狀態。同樣,thread_id 就像這個會話 Cookie,讓 LangGraph 智能體在多輪對話中能夠“記住”您是誰以及你們正在聊什麼。
1.2 長期記憶:通過 Store 實現的持久化知識庫
與專注於單次對話的短期記憶不同,長期記憶旨在存儲“跨越不同對話或會話的用户特定或應用級別的數據”。這是智能體積累知識、形成對用户長期認知的地方。
核心機制:Store
Store 本質上是一個暴露給圖節點和工具(Tools)的鍵值數據庫。與 checkpointer 的自動化快照不同,對 Store 的操作是顯式和主動的。開發者需要在節點或工具的邏輯中,通過調用 store.put()、store.get() 或 store.search() 等方法來精確地讀寫信息 。
關鍵標識符:user_id 和 namespace
Store 中的數據通常通過更持久的標識符來組織。user_id 是最常見的例子,用於關聯特定用户的所有信息。此外,namespace(命名空間)提供了一種數據隔離機制,例如,使用 (“memories”, user_id) 這樣的元組作為命名空間,可以將用户的記憶與其他類型的數據(如用户偏好 (“preferences”, user_id))清晰地分離開來,避免數據衝突,保持知識庫的整潔有序 。
概念類比:用户數據庫中的個人檔案
可以將 Store 想象成一個應用數據庫中的用户個人檔案表。用户的姓名、聯繫方式、購買歷史等信息被永久存儲,並且在用户每次訪問時都可以被查詢和使用。同樣,LangGraph 的 Store 保存了那些不應隨單次對話結束而消失的持久化信息,智能體可以在任何時候、任何對話中訪問這些信息。
1.3 Checkpointer 與 Store 的協同作用
一個高級的智能體需要同時運用這兩種記憶。Checkpointer 提供了流暢的對話體驗,而 Store 則賦予了智能體深度和個性。
應用場景示例:AI 客户服務智能體
- Checkpointer (由 thread_id 標識) 記錄了當前對話的上下文:
- 用户:“你好,我的電腦開不了機了。”
- 智能體:“您好,請問您檢查過電源線是否插好了嗎?”
- Store (由 user_id 標識) 存儲了該用户的歷史信息:
- “用户 John Doe,於 YYYY-MM-DD 購買了 X 型號筆記本電腦,歷史支持記錄顯示曾有電源適配器故障。”
在這個場景中,checkpointer 確保了智能體能夠對用户當前的問題做出連貫的迴應。而 store 則提供了深層次的歷史背景,使智能體能夠提供更具個性化和洞察力的服務(例如,“我看到您之前遇到過電源問題,這次的情況是否類似?”)。
LangGraph 的這種雙內存架構,實際上是軟件工程中“關注點分離”(Separation of Concerns)原則的體現。它將易變的、與會話緊密相關的對話狀態(由 Checkpointer 管理)與穩定的、持久化的應用知識(由 Store 管理)分離開來。這種設計並非偶然,而是為了構建可擴展、可維護的複雜 AI 應用。它簡化了開發流程,降低了數據管理的複雜性,並允許這兩個系統根據應用需求獨立擴展。這表明 LangGraph 的設計目標遠不止於簡單的聊天機器人,而是面向需要精細化狀態管理的生產級企業應用。
為了更清晰地展示兩者的區別,下表進行了詳細對比:
第二部分:使用 Checkpointer 實現短期記憶
本部分將提供一個實踐指南,指導您如何為 LangGraph 應用添加對話記憶功能,從簡單的本地開發環境配置,到穩健的生產環境部署。
2.1 快速入門:用於開發的 InMemorySaver
對於開發、原型設計和測試階段,最簡單快捷的方式是使用 InMemorySaver。它將所有的對話狀態存儲在內存中的一個 Python 字典裏。
讓我們解構一下基礎的實現代碼 :
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
# 1. 實例化一個內存檢查點工具
checkpointer = InMemorySaver()
# 假設 builder 已經定義好了
builder = StateGraph(...)
#... 添加節點和邊...
# 2. 在編譯圖時傳入 checkpointer
graph = builder.compile(checkpointer=checkpointer)
# 3. 調用圖時,通過 configurable 傳入 thread_id
graph.invoke(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
{"configurable": {"thread_id": "1"}},
)
# 後續調用使用相同的 thread_id,圖將能“記住”之前的狀態
response = graph.invoke(
{"messages": [{"role": "user", "content": "我的名字是什麼?"}]},
{"configurable": {"thread_id": "1"}},
)
# response 將會包含模型回答 "你的名字是 Bob" 的信息代碼分析:
checkpointer = InMemorySaver(): 實例化過程非常簡單,無需任何配置。graph.compile(checkpointer=checkpointer): 這是將持久化能力“注入”圖的關鍵步驟。編譯後的 graph 對象現在具備了狀態管理的能力。{"configurable": {"thread_id": "1"}}: 這個字典是激活內存機制的核心。如果沒有提供 thread_id,每次 invoke 調用都將是無狀態的。而只要使用相同的 thread_id,LangGraph 就會在多次調用之間維持對話狀態。
重要提示:
InMemorySaver 僅適用於開發和測試。由於所有狀態都保存在內存中,一旦 Python 進程終止,所有對話歷史都將丟失。
2.2 生產級持久化:數據庫支持的 Checkpointer
當應用準備上線時,必須使用由數據庫支持的持久化 Checkpointer,以確保數據的可靠性和服務的連續性。LangGraph 為主流數據庫提供了開箱即用的支持,如 PostgreSQL、MongoDB 和 Redis。
以下是針對不同數據庫的配置和使用詳解。
2.2.1 PostgreSQL
PostgreSQL 是一個功能強大的開源對象關係數據庫,非常適合需要事務完整性和結構化數據的應用。
安裝:
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres連接與設置:
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://user:password@host:port/dbname?sslmode=disable"
# 使用 with 上下文管理器確保連接被正確關閉
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 首次運行時,需要執行 setup() 來創建數據庫表
# checkpointer.setup()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)checkpointer.setup() 是一個關鍵的一次性操作,它會在您的 PostgreSQL 數據庫中創建 LangGraph 所需的表結構,用於存儲檢查點數據 。
完整代碼示例(同步與異步):
下面的示例展示了一個完整的對話流程。用户首先介紹自己是 Bob,然後提問自己的名字。由於使用了 PostgresSaver 和相同的 thread_id,第二次調用能夠成功恢復狀態,讓模型正確回答。
同步 (Sync) 示例:
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
# 第一次調用
graph.invoke(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config
)
# 第二次調用
final_state = graph.invoke(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config
)
final_state["messages"][-1].pretty_print()異步 (Async) 示例:
異步版本結構類似,但使用了 async/await 語法和異步庫 AsyncPostgresSaver,適用於高併發場景。
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
#...
async with AsyncPostgresSaver.from_conn_string(DB_URI) as checkpointer:
# await checkpointer.setup()
async def call_model(state: MessagesState):
response = await model.ainvoke(state["messages"])
return {"messages": response}
#...
graph = builder.compile(checkpointer=checkpointer)
#...
await graph.ainvoke(...)無論是同步還是異步,核心的業務邏輯 call_model 保持不變。LangGraph 的架構將持久化邏輯與業務邏輯解耦,開發者只需在編譯時更換 checkpointer 即可切換持久化策略。
2.2.2 MongoDB 和 Redis
配置 MongoDB 和 Redis 的流程與 PostgreSQL 非常相似,只需替換為對應的 Saver 類即可。
- MongoDB:
- 安裝:
pip install -U pymongo langgraph langgraph-checkpoint-mongodb - 使用:
from langgraph.checkpoint.mongodb import MongoDBSaver
- Redis:
- 安裝:
pip install -U langgraph langgraph-checkpoint-redis - 使用:
from langgraph.checkpoint.redis import RedisSaver
選擇哪種數據庫取決於您的技術棧、性能需求和數據模型偏好。Redis 以其極高的讀寫速度著稱,適合作為高速緩存和檢查點存儲。MongoDB 則以其靈活的文檔模型見長,適合存儲半結構化的狀態數據。
2.3 高級模式:子圖與工具中的內存交互
2.3.1 子圖中的內存
當構建複雜的、由多個子圖嵌套而成的應用時,LangGraph 提供了靈活的內存管理策略。
- 內存繼承(默認行為):
默認情況下,子圖會繼承其父圖的 checkpointer。這意味着整個嵌套圖共享同一個對話狀態,數據可以在父子圖之間無縫流動。這對於將一個大型任務分解為多個模塊化子任務非常有用 。 - 內存隔離:
在某些場景下,例如構建多智能體系統,我們希望每個智能體(由一個子圖表示)擁有自己獨立的內存空間,互不干擾。此時,可以在編譯子圖時設置 checkpointer=True。
subgraph_builder = StateGraph(...)
#...
# 這會為子圖創建一個獨立的內存空間
subgraph = subgraph_builder.compile(checkpointer=True)這種模式賦予了每個智能體獨立的“記憶”,是實現複雜協作和自治行為的基礎 。
2.3.2 在工具中讀取狀態
工具(Tools)不再是無狀態的外部函數。LangGraph 允許工具直接訪問和讀取當前的圖狀態,使其具備上下文感知能力。
from typing import Annotated
from langgraph.prebuilt import InjectedState, create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
class CustomState(AgentState):
user_id: str
def get_user_info(
# 關鍵在於此:使用 Annotated 和 InjectedState
state: Annotated[CustomState, InjectedState]
) -> str:
"""根據狀態中的 user_id 查詢用户信息。"""
user_id = state["user_id"]
#... 查詢數據庫...
return f"用户信息查詢結果 for {user_id}"核心機制:state: Annotated[CustomState, InjectedState] 。
InjectedState 是一個特殊的標記,它告訴 LangGraph 運行時:“在調用這個工具時,請將當前的完整狀態對象作為第一個參數注入進來。” 這使得工具能夠基於圖的當前狀態(例如,從狀態中獲取 user_id)來執行更智能的操作。
2.3.3 從工具中寫入狀態
更進一步,工具甚至可以直接修改圖的狀態,這使得智能體能夠通過工具使用來“學習”和更新自己的內部“信念”。
from langgraph.types import Command
from langchain_core.messages import ToolMessage
def update_user_info(...) -> Command:
"""查找並更新用户信息到狀態中。"""
#... 業務邏輯...
user_name = "John Smith"
# 返回一個 Command 對象,而不是簡單的字符串
return Command(update={
"user_name": user_name,
"messages": [ToolMessage(content="Updated user info", tool_call_id="...")]
})核心機制:返回一個 Command 對象 。
當工具的返回類型被註解為 Command 時,LangGraph 會將其返回值解釋為對狀態的直接修改指令。Command(update={...}) 中的字典定義了要更新的狀態字段及其新值。這允許工具在完成其主要任務(例如,調用 API)的同時,將結果寫回智能體的短期記憶中,從而影響後續的決策。
InjectedState 和 Command 這兩種模式,將工具從被動的外部執行單元提升為狀態圖中的一等公民。它們能夠主動地感知和改變智能體的內部世界,這是構建能夠通過與環境交互來動態調整自身狀態的、更高級自主智能體的關鍵一步。
第三部分:使用 Store 構建長期記憶
如果説 Checkpointer 賦予了智能體流暢對話的能力,那麼 Store 則賦予了它沉澱知識、形成持久記憶的能力。本部分將深入探討如何使用 Store 為您的智能體構建一個跨越時間、跨越會話的知識庫。
3.1 基礎概念與 InMemoryStore
與 Checkpointer 類似,LangGraph 提供了一個 InMemoryStore 用於快速開發和原型驗證。它將所有數據存儲在內存中,API 與持久化 Store 保持一致。
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
# 1. 實例化一個內存 Store
store = InMemoryStore()
builder = StateGraph(...)
#...
# 2. 在編譯圖時傳入 store
graph = builder.compile(store=store)通過在 compile 方法中傳入 store 參數,該 store 實例就在整個圖的執行上下文中變得可用 。
3.2 用於生產應用的持久化 Store
為了讓記憶真正“長期”,生產環境必須使用數據庫支持的 Store。LangGraph 目前主要支持 PostgresStore 和 RedisStore。
3.2.1 使用 PostgresStore 和 RedisStore
配置過程與 Checkpointer 類似,但關鍵區別在於 Store 是如何在節點內部被訪問和使用的。
安裝:
- PostgreSQL:
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres - Redis:
pip install -U langgraph langgraph-checkpoint-redis
完整代碼示例(PostgreSQL):
下面的示例展示了 Store 的核心用法。智能體被要求記住用户的名字 “Bob”。這個信息通過 store.put() 被寫入數據庫。隨後,在一個全新的對話線程 (thread_id: “2”) 中,當被問及名字時,智能體通過 store.search() 從數據庫中檢索到了這個信息,併成功回答。這清晰地展示了 Store 跨會話記憶的能力。
同步 (Sync) 示例:
import uuid
from langchain_core.runnables import RunnableConfig
from langgraph.store.base import BaseStore
from langgraph.store.postgres import PostgresStore
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with (
PostgresStore.from_conn_string(DB_URI) as store,
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
):
# store.setup()
# checkpointer.setup()
# 1. 節點函數簽名中聲明 store 參數
def call_model(
state: MessagesState,
config: RunnableConfig,
*,
store: BaseStore,
):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
# 2. 從 Store 中讀取(搜索)記憶
memories = store.search(namespace, query=str(state["messages"][-1].content))
info = "\n".join([d.value["data"] for d in memories])
system_msg = f"用户信息: {info}"
# 3. 向 Store 中寫入記憶
last_message = state["messages"][-1]
if "remember" in last_message.content.lower():
memory_to_save = "User name is Bob"
# 使用 uuid 作為 key 確保唯一性
store.put(namespace, str(uuid.uuid4()), {"data": memory_to_save})
response = model.invoke(...)
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
# 4. 編譯時同時傳入 checkpointer 和 store
graph = builder.compile(
checkpointer=checkpointer,
store=store,
)
# 第一次對話,要求記住名字
config1 = {"configurable": {"thread_id": "1", "user_id": "user_001"}}
graph.invoke(
{"messages": [{"role": "user", "content": "remember my name is Bob"}]},
config1
)
# 第二次對話(新線程),詢問名字
config2 = {"configurable": {"thread_id": "2", "user_id": "user_001"}}
final_state = graph.invoke(
{"messages": [{"role": "user", "content": "what is my name?"}]},
config2
)
final_state["messages"][-1].pretty_print()代碼分析:
def call_model(..., *, store: BaseStore): 這是在節點中訪問 Store 的標準方式。通過在函數簽名中添加一個關鍵字參數store,LangGraph 運行時會自動將編譯時傳入的 store 實例注入進來。store.search(...): 用於從 Store 中檢索信息。store.put(...): 用於向 Store 中寫入信息。注意使用 namespace 和 user_id 來組織數據。graph.compile(checkpointer=checkpointer, store=store): 一個強大的智能體通常需要同時配置短期和長期記憶。
異步版本的邏輯完全相同,只需使用 AsyncPostgresStore 和 async/await 即可 。
3.3 用長期知識賦能工具
與短期記憶類似,工具也可以與長期記憶 Store 進行交互,從而執行依賴於持久化知識的複雜任務。
3.3.1 從 Store 中讀取
from langgraph.config import get_store
def get_user_info(config: RunnableConfig) -> str:
"""從 Store 中查找用户信息。"""
# 1. 獲取在上下文中可用的 store 實例
store = get_store()
user_id = config["configurable"].get("user_id")
# 2. 使用 store 實例進行查詢
user_info_doc = store.get(("users",), user_id)
return str(user_info_doc.value) if user_info_doc else "Unknown user"
# 創建 Agent 時傳入 store
agent = create_react_agent(..., store=store)核心機制:store = get_store() 。
這個函數是一個上下文感知(context-aware)的輔助函數。它能夠在工具執行時,自動獲取並返回在創建智能體時 compile 或 create_react_agent 中傳入的那個 store 實例。
3.3.2 向 Store 寫入
from typing_extensions import TypedDict
class UserInfo(TypedDict):
name: str
language: str
def save_user_info(user_info: UserInfo, config: RunnableConfig) -> str:
"""將用户信息保存到 Store。"""
store = get_store()
user_id = config["configurable"].get("user_id")
# 將結構化數據寫入 Store
store.put(("users",), user_id, user_info)
return "Successfully saved user info."最佳實踐:使用 TypedDict 或 Pydantic 模型來定義數據模式(schema)。這不僅能提供代碼級別的類型提示,更重要的是,它為 LLM 提供了一個清晰的結構化輸出格式。當 LLM 決定調用 save_user_info 工具時,它會知道需要生成一個包含 name 和 language 字段的字典,從而大大提高了工具調用的成功率和穩定性。
3.4 語義記憶:智能體知識的未來
LangGraph 的 Store 最強大的功能之一是支持語義搜索。這能將 Store 從一個簡單的鍵值數據庫,轉變為一個功能完備的向量數據庫。智能體不再只能通過精確的關鍵詞來檢索記憶,而是能夠根據概念的相似性來查找相關信息。這實際上是在智能體的記憶系統內部,原生集成了一套檢索增強生成(RAG)流程。
設置:
要啓用語義搜索,需要在實例化 Store 時配置一個 index。
from langchain.embeddings import init_embeddings
from langgraph.store.memory import InMemoryStore
# 1. 初始化一個嵌入模型
embeddings = init_embeddings("openai:text-embedding-3-small")
# 2. 在創建 Store 時配置 index
store = InMemoryStore(
index={
"embed": embeddings, # 指定用於向量化的模型
"dims": 1536, # 指定向量維度
}
)使用示例:
下面的示例中,我們向 Store 中存入了兩個事實:“我喜歡披薩”和“我是一個水管工”。當用户説“我餓了”時,store.search 會進行語義相似度搜索。儘管查詢中沒有“披薩”這個詞,但嵌入模型知道“餓”和“披薩”在語義上是高度相關的,因此成功地檢索出了“我喜歡披薩”這條記憶,並將其提供給 LLM 作為上下文。
# 存入記憶
store.put(("user_123", "memories"), "1", {"text": "I love pizza"})
store.put(("user_123", "memories"), "2", {"text": "I am a plumber"})
# 進行語義搜索
# "I'm hungry" 在語義上與 "I love pizza" 更接近
items = store.search(
("user_123", "memories"),
query="I'm hungry",
limit=1
)
# items.value 將會是 {"text": "I love pizza"}這種將 RAG 流程原生集成到記憶系統中的架構模式極其強大。智能體的“長期記憶”不再是一個被動存儲事實的倉庫,而是一個可以實時查詢、用以增強自身推理和生成能力的動態知識庫。這模糊了“記憶”和“知識庫”之間的界限,為構建能夠持續學習和成長的智能體鋪平了道路。隨着智能體與世界交互,它可以通過工具不斷地將新知識寫入其語義 Store,從而動態地擴展和優化其知識儲備,使其在未來的交互中變得越來越智能。
第四部分:主動內存管理策略
隨着對話的進行,短期記憶(即消息歷史)會不斷增長。如果不加以管理,很快就會超出 LLM 的上下文窗口限制(context window),導致 API 調用失敗或更糟——模型在無提示的情況下丟失早期上下文。因此,主動的內存管理不是一個可選項,而是構建任何非平凡、可長期運行智能體的必需品。
LangGraph 提供了多種策略來應對這一挑戰。
4.1 上下文窗口挑戰
所有 LLM 都有一個輸入token數量的上限。例如,一個模型的上下文窗口可能是 4096 或 32768 個token。一次對話,包括歷史消息、系統提示、工具定義等,其總長度不能超過這個限制。本節將介紹三種核心策略來解決這個問題:修剪、刪除和總結。
4.2 策略一:修剪消息 (Trimming)
這是最簡單直接的策略:當消息歷史過長時,從開頭或結尾丟棄一部分消息,以確保總長度符合限制。
在智能體 (Agent) 中實現:
使用 create_react_agent 等預構建的智能體時,可以通過 pre_model_hook 參數輕鬆實現。這個鈎子函數會在每次調用 LLM 之前執行,是修改輸入的理想位置。
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
def pre_model_hook(state):
trimmed_messages = trim_messages(
state["messages"],
strategy="last", # 保留最新的消息
token_counter=count_tokens_approximately,
max_tokens=4096,
start_on="human", # 確保修剪後以人類消息開始
)
# 將修剪後的消息放入一個新鍵,供 LLM 使用
return {"llm_input_messages": trimmed_messages}
agent = create_react_agent(
model,
tools,
pre_model_hook=pre_model_hook,
checkpointer=checkpointer,
)trim_messages 是一個非常方便的工具函數,strategy="last" 表示保留最近的消息,丟棄最老的消息,這是最常見的修剪策略 。
在工作流 (Workflow) 中實現:
如果想獲得更精細的控制,可以直接在調用模型的節點內部實現修剪邏輯。
def call_model(state: MessagesState):
messages = trim_messages(
state["messages"],
strategy="last",
max_tokens=4096,
)
response = model.invoke(messages)
return {"messages": [response]}4.3 策略二:刪除消息 (Deleting)
這是一種更具針對性的方法,允許從狀態中永久移除特定的消息。這對於清理不再需要的系統指令、冗餘的工具輸出或錯誤信息非常有用。
實現方式:
要刪除消息,不能直接從狀態的 messages 列表中移除。正確的做法是,在節點中返回一個包含 RemoveMessage 對象的列表。LangGraph 的狀態更新機制會識別這些對象,並執行刪除操作。
刪除特定消息:
from langchain_core.messages import RemoveMessage
def delete_messages_node(state):
messages = state["messages"]
if len(messages) > 10:
# 假設我們要刪除最早的兩條消息
messages_to_delete = messages[:2]
return {
"messages": [RemoveMessage(id=m.id) for m in messages_to_delete]
}
return {}刪除所有消息:
LangGraph 提供了一個特殊的常量 REMOVE_ALL_MESSAGES 來清空整個消息歷史。
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def clear_history_node(state):
return {"messages": REMOVE_ALL_MESSAGES}4.4 策略三:總結對話 (Summarizing)
這是最智能但也是最複雜的策略。它不是簡單地丟棄舊消息,而是使用一個 LLM 將對話的早期部分壓縮成一個摘要。這樣既減小了token佔用,又最大限度地保留了核心信息。
在智能體 (Agent) 中實現(推薦):
langmem 庫提供了一個預構建的 SummarizationNode,可以極大地簡化實現過程。
from langmem.short_term import SummarizationNode, RunningSummary
# 1. 配置總結節點
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=summarization_model, # 用於生成摘要的模型
max_tokens=4096, # 輸入給主模型的最大 token 數
max_summary_tokens=512, # 摘要本身的最大 token 數
output_messages_key="llm_input_messages",
)
# 2. 擴展狀態以包含總結上下文
class State(AgentState):
context: dict
# 3. 將總結節點用作 pre_model_hook
agent = create_react_agent(
...,
pre_model_hook=summarization_node,
state_schema=State,
checkpointer=checkpointer,
)這裏,SummarizationNode 被用作 pre_model_hook。它會自動檢查消息歷史的長度,當超過閾值時,觸發一次總結,然後將“摘要 + 最近消息”的組合傳遞給主模型。State 中的 context 字段用於存儲運行中的摘要信息,避免在每次調用時都重複總結 。
在工作流 (Workflow) 中自定義實現:
開發者也可以從零開始構建自己的總結邏輯,這提供了最大的靈活性。
class StateWithSummary(MessagesState):
summary: str
def summarize_conversation_node(state: StateWithSummary):
# 獲取已有的摘要
current_summary = state.get("summary", "")
# 構建用於生成新摘要的提示
prompt = f"當前摘要: {current_summary}\n\n請結合以下新消息擴展摘要:..."
# 調用 LLM 生成新摘要
new_summary = model.invoke(prompt).content
# 找出已經被總結的消息並準備刪除它們
messages_to_delete = [...]
return {
"summary": new_summary,
"messages": [RemoveMessage(id=m.id) for m in messages_to_delete]
}這個自定義節點負責維護狀態中的 summary 字段,並定期清理已被總結的舊消息。
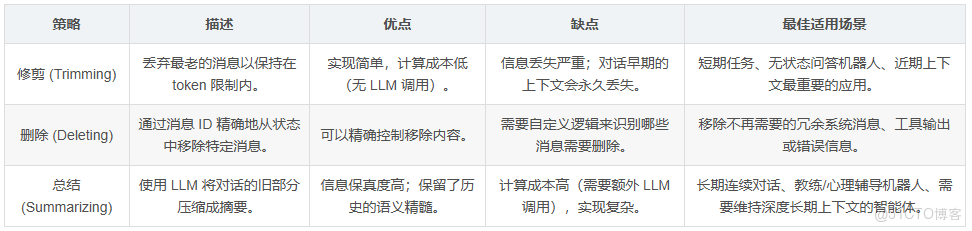
選擇哪種內存管理策略,本質上是在計算成本、信息保真度和實現複雜度之間做出權衡。
- 修剪:成本最低,實現最簡單,但信息丟失最嚴重。它像一把鈍刀,粗暴地切掉歷史。
- 刪除:成本低,複雜度中等,可以精確控制信息移除,但需要自定義邏輯。
- 總結:成本最高(需要額外的 LLM 調用),實現最複雜,但信息保真度最高。它保留了對話的語義精髓。
沒有一種策略是普適的“最佳”選擇。開發者應根據應用的具體需求來決定。一個簡單的問答機器人可能用修剪就足夠了,而一個需要建立長期關係的心理輔導或私人教練智能體,則必須使用總結策略來維持對用户歷史的深刻理解。
第五部分:管理控制與調試
構建和部署了有狀態的智能體後,對其內存進行檢查、管理和重置的能力變得至關重要,這對於調試、監控和用户體驗管理都必不可少。
5.1 檢查智能體狀態
LangGraph 提供了簡單的 API 來查看任何給定對話線程的當前狀態和歷史狀態。
查看線程的當前狀態(最新的檢查點):
使用 graph.get_state(config) 方法可以獲取指定 thread_id 的最新狀態快照。
config = {"configurable": {"thread_id": "1"}}
latest_state = graph.get_state(config)
print(latest_state.values)也可以通過 checkpointer 的底層 API 實現:checkpointer.get_tuple(config) 。
查看線程的狀態歷史:
使用 graph.get_state_history(config) 可以獲取一個迭代器,它會按時間順序返回該線程的所有歷史檢查點。這對於追溯狀態是如何一步步演變的、排查問題非常有幫助。
config = {"configurable": {"thread_id": "1"}}
for state_snapshot in graph.get_state_history(config):
print(f"Checkpoint ID: {state_snapshot.checkpoint_id}")
print(state_snapshot.values)對應的底層 API 是 checkpointer.list(config) 。
5.2 重置對話
在很多應用中,用户需要能夠“開始新的聊天”,這在後端就對應着重置或刪除當前的對話歷史。此外,出於數據隱私合規(如 GDPR)的考慮,也需要有能力永久刪除用户數據。
刪除線程的所有檢查點:
checkpointer 對象提供了一個直接的方法 delete_thread 來完成這個任務。
thread_id_to_delete = "1"
checkpointer.delete_thread(thread_id_to_delete)執行此命令後,與 thread_id="1" 相關的所有短期記憶(檢查點)都將被從後端數據庫中永久刪除 。
結論:構建一致的內存策略
本指南全面探討了 LangGraph 的雙軌內存架構,從基礎概念到高級應用,再到生產環境中的管理策略。我們看到,LangGraph 不僅僅提供了一個簡單的記憶功能,而是提供了一套完整、強大且靈活的狀態管理工具集,讓開發者能夠構建出真正具有深度和持久性的智能體。
為了成功地構建您自己的有狀態應用,以下是一些關鍵的架構性建議:
- 從規劃開始:在編寫代碼之前,清晰地規劃您的內存策略。明確哪些信息屬於短暫的對話上下文(應由 Checkpointer 管理),哪些是需要永久保存的核心知識(應存入 Store)。
- 選擇合適的後端:在開發階段使用 InMemory 版本進行快速迭代,但在部署生產環境時,根據團隊的技術棧、性能需求和數據一致性要求,謹慎選擇一個持久化的數據庫(如 PostgreSQL, Redis)。
- 讓工具具備狀態感知能力:充分利用
InjectedState和get_store(),將您的工具從無狀態的函數轉變為能夠感知和利用智能體內部狀態的強大組件。 - 主動管理上下文:不要等到上下文窗口溢出時才去補救。在開發初期就實施一種內存管理策略(修剪、刪除或總結),確保您的智能體能夠穩健地處理長時間的交互。
最後,LangGraph 的生態系統還在不斷髮展。LangMem 庫 提供了更多預構建的高級內存工具和策略,值得進一步探索。通過結合 LangGraph 強大的核心框架和社區貢獻的工具,您將能夠構建出下一代的人工智能應用,它們不僅能言善辯,更能記憶、學習和成長。