

引言
本文記錄一次線上 GC 問題的排查過程與思路,希望對各位讀者有所幫助。過程中也走了一些彎路,現在有時間沉澱下來思考並總結出來分享給大家,希望對大家今後排查線上 GC 問題有幫助。
背景
服務新功能發版一週後下午,突然收到 CMS GC 告警,導致單台節點被拉出,隨後集羣內每個節點先後都發生了一次 CMS GC,拉出後的節點垃圾回收後接入流量恢復正常(事後排查發現被重啓了)。
告警信息如下(已脱敏):
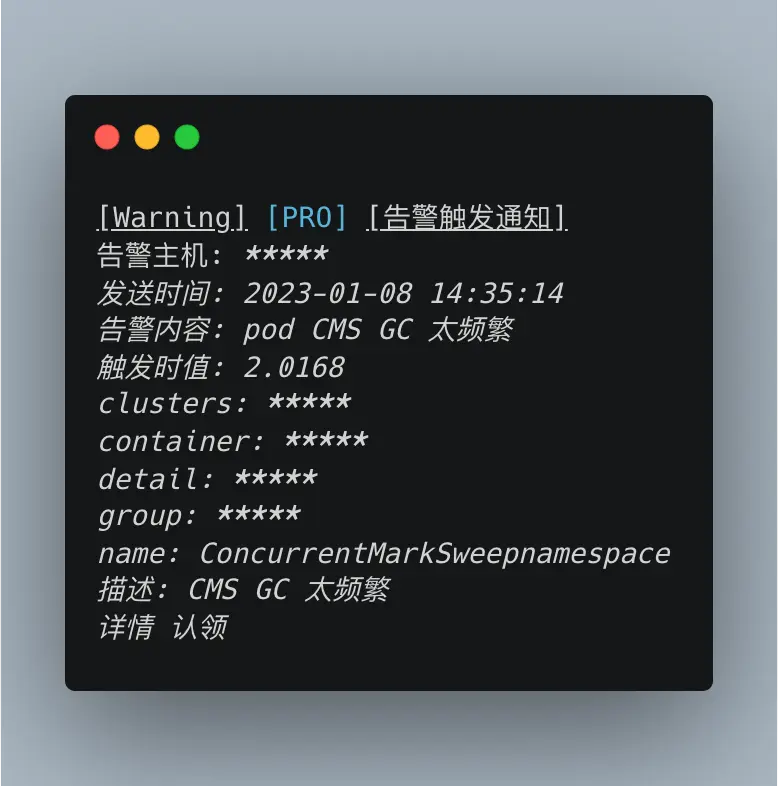
多個節點幾乎同時發生 GC 問題,且排查自然流量監控後發現並未有明顯增高,基本可以確定是有 GC 問題的,需要解決。
排查過程
GC 日誌排查
GC 問題首先排查的應該是 GC 日誌,日誌能能夠清晰的判定發生 GC 的那一刻是什麼導致的 GC,通過分析 GC 日誌,能夠清晰的得出 GC 哪一部分在出問題,如下是 GC 日誌示例:
0.514: [GC (Allocation Failure) [PSYoungGen: 4445K->1386K(28672K)] 168285K->165234K(200704K), 0.0036830 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.518: [Full GC (Ergonomics) [PSYoungGen: 1386K->0K(28672K)] [ParOldGen: 163848K->165101K(172032K)] 165234K->165101K(200704K), [Metaspace: 3509K->3509K(1056768K)], 0.0103061 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
0.528: [GC (Allocation Failure) [PSYoungGen: 0K->0K(28672K)] 165101K->165101K(200704K), 0.0019968 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.530: [Full GC (Allocation Failure) [PSYoungGen: 0K->0K(28672K)] [ParOldGen: 165101K->165082K(172032K)] 165101K->165082K(200704K), [Metaspace: 3509K->3509K(1056768K)], 0.0108352 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]如上 GC 日誌能很明顯發現導致 Full GC 的問題是:Full GC 之後,新生代內存沒有變化,老年代內存使用從 165101K 降低到 165082K (幾乎沒有變化)。這個程序最後內存溢出了,因為沒有可用的堆內存創建 70m 的大對象。
但是,生產環境總是有奇奇怪怪的問題,由於服務部署在 K8s 容器,且運維有對服務心跳檢測,當程序觸發 Full GC 時,整個系統 Stop World,連續多次心跳檢測失敗,則判定為當前節點可能出故障(硬件、網絡、BUG 等等問題),則直接拉出當前節點,並立即重建,此時之前打印的 GC 日誌都是在當前容器卷內,一旦重建,所有日誌全部丟失,也就無法通過 GC 日誌排查問題了。
JVM 監控埋點排查
上述 GC 日誌丟失問題基本無解,發生 GC 則立即重建,除非人為干預,否則很難拿到當時的 GC 日誌,且很難預知下次發生 GC 問題時間(如果能上報 GC 日子就不會有這樣的問題,事後發現有,但是我沒找到。。)。
此時,另一種辦法就是通過 JVM 埋點監控來排查問題。企業應用都會配備完備的 JVM 監控看板,就是為了能清晰明瞭的看到“事故現場”,通過監控,可以清楚的看到 JVM 內部在時間線上是如何分配內存及回收內存的。
JVM 監控用於監控重要的 JVM 指標,包括堆內存、非堆內存、直接緩衝區、內存映射緩衝區、GC 累計信息、線程數等。
主要關注的核心指標如下:
-
GC(垃圾收集)瞬時和累計詳情
- FullGC 次數
- YoungGC 次數
- FullGC 耗時
- YoungGC 耗時
-
堆內存詳情
- 堆內存總和
- 堆內存老年代字節數
- 堆內存年輕代 Survivor 區字節數
- 堆內存年輕代 Eden 區字節數
- 已提交內存字節數
- 元空間元空間字節數
-
非堆內存
- 非堆內存提交字節數
- 非堆內存初始字節數
- 非堆內存最大字節數
-
直接緩衝區
- DirectBuffer 總大小(字節)
- DirectBuffer 使用大小(字節)
-
JVM 線程數
- 線程總數量
- 死鎖線程數量
- 新建線程數量
- 阻塞線程數量
- 可運行線程數量
- 終結線程數量
- 限時等待線程數量
- 等待中線程數量
發生 GC 問題,重點關注的就是這幾個指標,大致就能圈定 GC 問題了。
堆內存排查
首先查看堆內存,確認是否有內存溢出(指無法申請足夠的內存導致),對內監控如下:
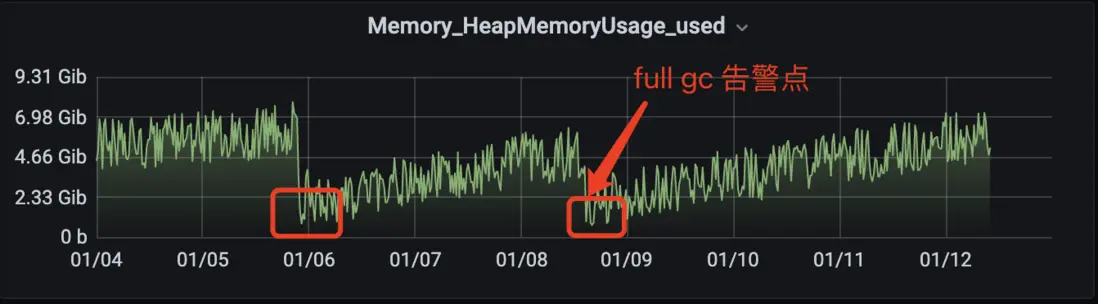
可以看到發生 Full GC 後,堆內存明顯降低了很多,但是在未發生大量 Full GC 後也有內存回收到和全量 GC 同等位置,所以可以斷定堆內存是可以正常回收的,不是導致大量 Full GC 的元兇。
非堆內存排查
非堆內存指 Metaspace 區域,監控埋點如下:
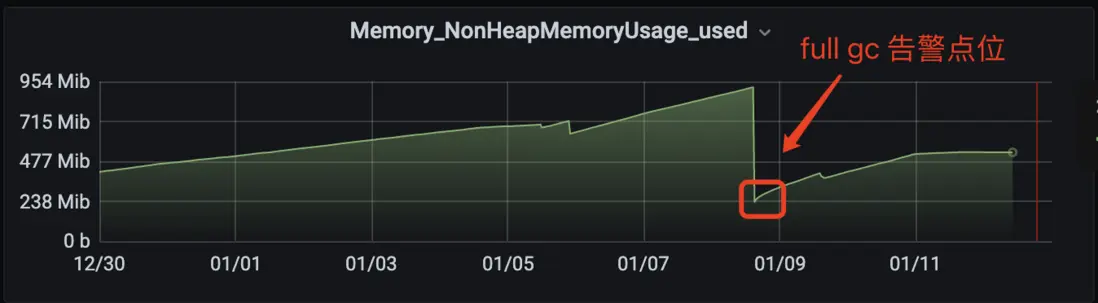
可以看到發生告警後,非堆內存瞬間回收很多(因為服務器被健康檢查判定失效後重建,相當於重新啓動,JVM 重新初始化),此處如果有 GC 排查經驗的人一定能立即篤定,metaspace 是有問題的。
Metaspace 是用來幹嘛的?JDK8 的到來,JVM 不再有 PermGen(永久代),但類的元數據信息(metadata)還在,只不過不再是存儲在連續的堆空間上,而是移動到叫做 “Metaspace” 的本地內存(Native memory)中。
那麼何時會加載類信息呢?
- 程序運行時:當運行 Java 程序時,該程序所需的類和方法。
- 類被引用時:當程序首次引用某個類時,加載該類。
- 反射:當使用反射 API 訪問某個類時,加載該類。
- 動態代理:當使用動態代理創建代理對象時,加載該對象所需的類。
由上得出結論,如果一個服務內沒有大量的反射或者動態代理等類加載需求時,講道理,程序啓動後,類的加載數量應該是波動很小的(不排除一些異常堆棧反射時也會加載類導致增加),但是如上監控顯示,GC 後,metaspace 的內存使用量一直緩步增長,即程序內不停地製造“類”。
查看 JVM 加載類監控如下:
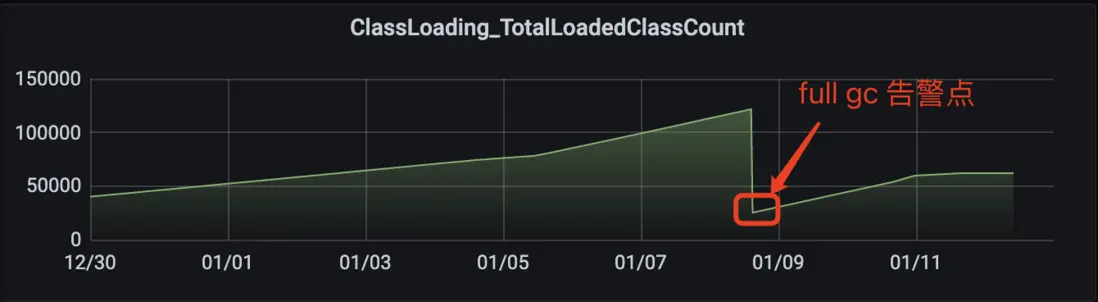
由上監控,確實是加載了大量的類,數量趨勢和非堆使用量趨勢吻合。
查看當前 JVM 設置的非堆內存大小如下:
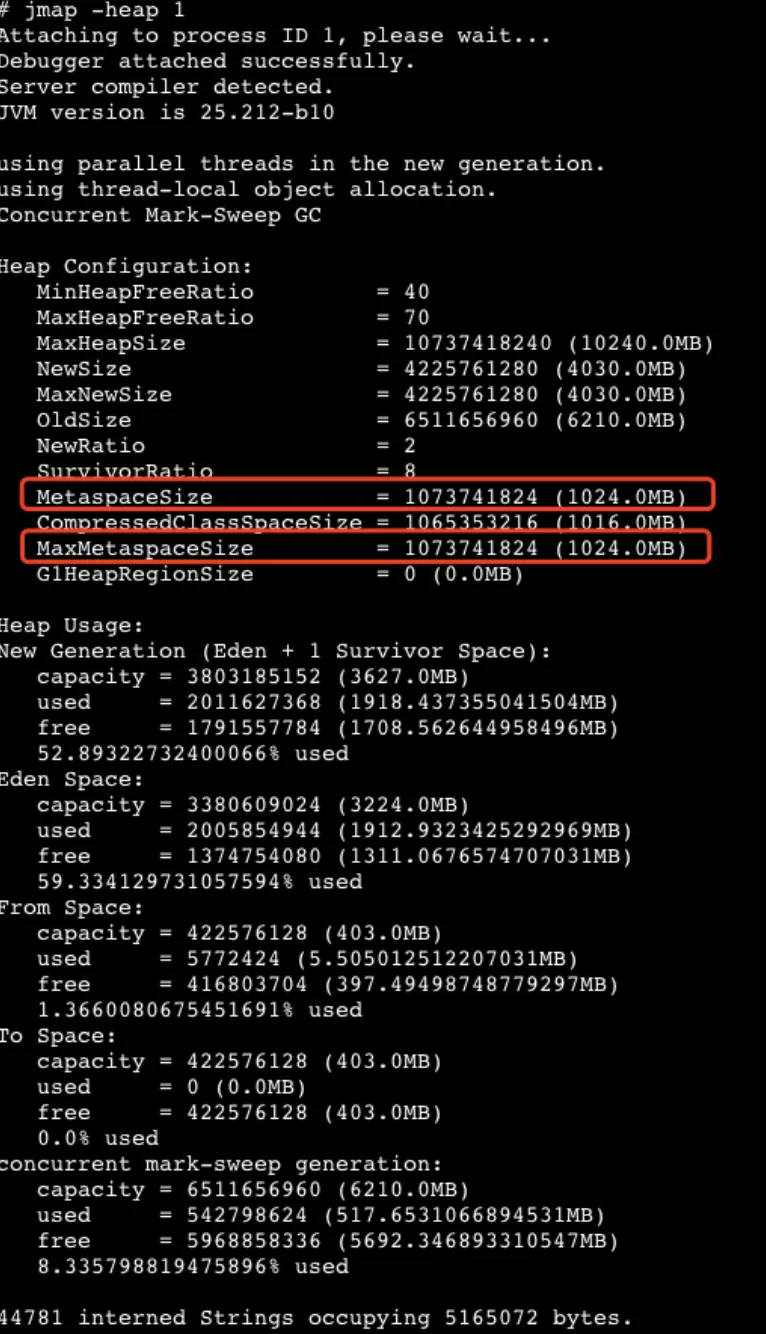
MetaspaceSize & MaxMetaspaceSize = 1024 M,由上面非堆內存使用監控得出,使用量已接近 1000 M,無法在分配足夠的內存來加載類,最終導致發生 Full GC 問題。
程序代碼排查
由上面排查得出的結論:程序內在大量的創建類導致非堆內存被打爆。結合當前服務內存在大量使用 Groovy 動態腳本功能,大概率應該是創建腳本出了問題,腳本創建動態類代碼如下:
public static GroovyObject buildGroovyObject(String script) {
GroovyClassLoader classLoader = new GroovyClassLoader();
try {
Class<?> groovyClass = classLoader.parseClass(script);
GroovyObject groovyObject = (GroovyObject) groovyClass.newInstance();
classLoader.clearCache();
log.info("groovy buildScript success: {}", groovyObject);
return groovyObject;
} catch (Exception e) {
throw new RuntimeException("buildScript error", e);
} finally {
try {
classLoader.close();
} catch (IOException e) {
log.error("close GroovyClassLoader error", e);
}
}
}線上打開日誌,確實證明了在不停的創建類。
腳本創建類導致堆內存被打爆,之間也是踩過坑的,針對同一個腳本(MD5 值相同),則會直接拿緩存,不會重複創建類,緩存 check 邏輯如下:
public static GroovyObject buildScript(String scriptId, String script) {
Validate.notEmpty(scriptId, "scriptId is empty");
Validate.notEmpty(scriptId, "script is empty");
// 嘗試緩存獲取
String currScriptMD5 = DigestUtils.md5DigestAsHex(script.getBytes());
if (GROOVY_OBJECT_CACHE_MAP.containsKey(scriptId)
&& currScriptMD5.equals(GROOVY_OBJECT_CACHE_MAP.get(scriptId).getScriptMD5())) {
log.info("groovyObjectCache hit, scriptId: {}", scriptId);
return GROOVY_OBJECT_CACHE_MAP.get(scriptId).getGroovyObject();
}
// 創建
try {
GroovyObject groovyObject = buildGroovyObject(script);
// 塞入緩存
GROOVY_OBJECT_CACHE_MAP.put(scriptId, GroovyCacheData.builder()
.scriptMD5(currScriptMD5)
.groovyObject(groovyObject)
.build());
} catch (Exception e) {
throw new RuntimeException(String.format("scriptId: %s buildGroovyObject error", scriptId), e);
}
return GROOVY_OBJECT_CACHE_MAP.get(scriptId).getGroovyObject();
}此處代碼邏輯在之前的測試中都是反覆驗證過的,不會存在問題,即只有緩存 Key 出問題導致了類的重複加載。結合最近修改上線的邏輯,排查後發現,scriptId 存在重複的可能,導致不同腳本,相同 scriptId 不停重複加載(加載的頻次 10 分鐘更新一次,所以非堆使用緩慢上升)。
此處埋了一個小坑:加載的類使用 Map 存儲的,即同一個 cacheKey 調用 Map.put() 方法,重複加載的類會被後面加載的類給替換掉,即之前加載的類已經不在被 Map 所“持有”,會被垃圾回收器回收掉,按理來説 Metaspace 不應該一直增長下去!?
提示:類加載與 Groovy 類加載、Metaspace 何時會被回收。
由於篇幅原因,本文就不在此處細究原因了,感興趣的朋友自行 Google 或者關注一下我,後續我再專門開一章詳解下原因。
總結
知其然知其所以然。
想要系統性地掌握 GC 問題處理方法,還是得了解 GC 的基礎:基礎概念、內存劃分、分配對象、收集對象、收集器等。掌握常用的分析 GC 問題的工具,如 gceasy.io 在線 GC 日誌分析工具,此處筆者參照了美團技術團隊文章 Java 中 9 種常見的 CMS GC 問題分析與解決 收益匪淺,推薦大家閲讀。
往期精彩
- 性能調優——小小的 log 大大的坑
- 性能優化必備——火焰圖
- Flink 在風控場景實時特徵落地實戰
歡迎關注公眾號:咕咕雞技術專欄
個人技術博客:https://jifuwei.github.io/ >