

推薦:使用NSDT場景編輯器助你快速搭建可編輯的3D應用場景
什麼是 SQL 中的連接?
SQL 聯接允許您基於公共列合併來自多個數據庫表的數據。這樣,您就可以將信息合併在一起,並在相關數據集之間創建有意義的連接。
SQL 中的連接類型
有幾種類型的 SQL 聯接:
- 內聯接
- 左外連接
- 右外連接
- 完全外部聯接
- 交叉連接
讓我們解釋每種類型。
SQL 內部聯接
內部聯接僅返回在要聯接的兩個表中存在匹配項的行。它基於共享鍵或列合併兩個表中的行,丟棄不匹配的行。我們通過以下方式對此進行可視化。

在 SQL 中,這種類型的連接是使用關鍵字 JOIN 或 INNER JOIN 執行的。
SQL 左外部聯接
左外連接返回左側(或第一個)表中的所有行和右側(或第二個)表中的匹配行。如果沒有匹配項,則返回右側表中列的 NULL 值。我們可以這樣想象它。

如果要在 SQL 中使用此聯接,可以使用 LEFT OUTER JOIN 或 LEFT JOIN 關鍵字來實現。這是一篇討論左聯接與左外聯接的文章。
SQL 右外聯接
右聯接與左聯接相反。它返回右側表中的所有行和左側表中的匹配行。如果沒有匹配項,則返回左側表中列的 NULL 值。

在 SQL 中,此連接類型是使用關鍵字 RIGHT OUTER JOIN 或 RIGHT JOIN 執行的。
SQL 完全外部聯接
完全外部聯接返回兩個表中的所有行,儘可能匹配行,併為不匹配的行填充 NULL 值。

SQL 中此聯接的關鍵字是“完全外部聯接”或“完全聯接”。
SQL 交叉聯接
這種類型的聯接將一個表中的所有行與第二個表中的所有行合併在一起。換句話説,它返回笛卡爾積,即兩個錶行的所有可能組合。這是可視化效果,使其更容易理解。

在 SQL 中交叉聯接時,關鍵字是 CROSS JOIN。
瞭解 SQL 聯接語法
要在 SQL 中執行聯接,您需要指定要聯接的表、用於匹配的列以及要執行的聯接類型。在 SQL 中聯接表的基本語法如下:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;此示例演示如何使用 JOIN。
引用 FROM 子句中的第一個(或左側)表。然後,使用 JOIN 跟隨它並引用第二個(或右側)表。
然後是 ON 子句中的連接條件。您可以在此處指定將用於聯接兩個表的列。通常,它是一個共享列,它是一個表中的主鍵和第二個表中的外鍵。
注意:主鍵是表中每條記錄的唯一標識符。外鍵在兩個表之間建立鏈接,即它是第二個表中引用第一個表的列。我們將在示例中向您展示這意味着什麼。
如果你想使用左聯接、右聯接或完全聯接,你只需使用這些關鍵字而不是 JOIN ——代碼中的其他一切都完全相同!交叉連接的情況略有不同。
其性質是聯接兩個表中的所有行組合。這就是為什麼不需要 ON 子句,語法如下所示。
SELECT columns
FROM table1
CROSS JOIN table2;換句話説,您只需在 FROM 中引用一個表,在 CROSS JOIN 中引用第二個表。
或者,您可以在 FROM 中引用這兩個表並用逗號分隔它們 - 這是 CROSS JOIN 的簡寫。
`SELECT columns
FROM table1, table2;`
自連接:SQL 中一種特殊類型的連接
還有一種連接表的特定方法 - 將表與自身連接。這也稱為自聯表。它不完全是一種獨特的聯接類型,因為前面提到的任何聯接類型也可用於自聯接。自聯接的語法與我之前向您展示的語法類似。主要區別在於 FROM 和 JOIN 中引用了相同的表。
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;此外,您需要為表提供兩個別名以區分它們。您正在做的是將表與自身聯接,並將其視為兩個表。
我只是想在這裏提到這一點,但我不會進一步詳細介紹。如果您對自加入感興趣,請參閲這本關於 SQL 中自加入的圖解指南。
SQL 聯接示例
是時候向您展示我提到的所有內容在實踐中是如何工作的了。我將使用 StrataScratch 中的 SQL JOIN 面試問題來展示 SQL 中每種不同類型的連接。
- 連接示例Microsoft的這個問題希望您列出每個項目並按員工計算項目的預算。昂貴的項目“給定映射到每個項目的項目和員工列表,按分配給每個員工的項目預算金額計算。輸出應包括項目標題和項目預算,四捨五入到最接近的整數。首先按每位員工預算最高的項目對列表進行排序。數據這個問題給出了兩個表格。
ms_projects編號:國際
標題:瓦爾查爾
預算:國際
ms_emp_projects
emp_id:國際
project_id:國際現在,表 ms_projects 中的列 id 是表的主鍵。可以在表ms_emp_projects中找到相同的列,儘管名稱不同:project_id。這是表的外鍵,引用第一個表。我將使用這兩列來聯接解決方案中的表。
法典
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b
ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;我使用 JOIN 連接了兩個表。表 ms_projects 在 FROM 中引用,而ms_emp_projects在 JOIN 之後引用。我為兩個表提供了一個別名,這樣我以後就不會使用該表的長名稱。
現在,我需要指定要聯接表的列。我已經提到哪些列是一個表中的主鍵,哪些列是另一個表中的外鍵,所以我將在這裏使用它們。
我相等這兩列,因為我想獲取項目 ID 相同的所有數據。我還在每列前面使用了表的別名。
現在我可以訪問兩個表中的數據,我可以在 SELECT 中列出列。第一列是項目名稱,第二列是計算的。
此計算使用 COUNT() 函數來計算每個項目的員工人數。然後,我將每個項目的預算除以員工人數。我還將結果轉換為十進制值並將其四捨五入到零小數位。
輸出下面是查詢返回的內容。

2. 左連接示例
讓我們在Airbnb面試問題上練習這個加入。它希望您找到每個城市的訂單數量、客户數量和訂單總成本。
客户訂單和詳細信息
“查找每個城市的訂單數量、客户數量和訂單總成本。僅包括至少下了 5 個訂單的城市,並計算每個城市的所有客户,即使他們沒有下訂單。輸出每個計算以及相應的城市名稱。
數據您將獲得客户和訂單的表格。
客户
編號:國際
first_name:瓦爾查爾
last_name:瓦爾查爾
城市:瓦爾查爾
地址:瓦爾查爾
phone_number:瓦爾查爾
訂單
編號:國際
cust_id:國際
order_date:日期時間
order_details:瓦爾查爾
total_order_cost:國際共享列是來自表客户的 id,cust_id來自表訂單。我將使用這些列來聯接表。
法典
以下是使用左聯接解決此問題的方法。
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;我在 FROM(這是我們的左表)中引用表客户,並在客户 ID 列上將其與訂單左連接。
現在我可以選擇城市,使用 COUNT() 按城市獲取訂單和客户數量,並使用 SUM() 按城市計算總訂單成本。
為了按城市獲得所有這些計算,我按城市對輸出進行分組。
問題中還有一個額外的要求:“僅包括至少下了 5 個訂單的城市......”我使用“必須”僅顯示具有五個或更多訂單的城市來實現此目的。
問題是,為什麼我使用了 LEFT JOIN 而不是 JOIN?線索在問題中:“...並計算每個城市的所有客户,即使他們沒有下訂單。可能並非所有客户都下了訂單。這意味着我想顯示錶客户中的所有客户,這完全符合左連接的定義。
如果我使用 JOIN,結果將是錯誤的,因為我會錯過沒有下任何訂單的客户。
注意:SQL 中連接的複雜性並不反映在它們的語法上,而是反映在它們的語義上! 如您所見,每個聯接的編寫方式相同,只是關鍵字發生了變化。但是,每個聯接的工作方式不同,因此可以根據數據輸出不同的結果。因此,您必須完全瞭解每個聯接的作用,並選擇能夠準確返回您想要的聯接!
輸出
現在,讓我們看一下輸出。

3. 右連接示例
右聯接是左聯接的鏡像。這就是為什麼我可以使用RIGHT JOIN輕鬆解決之前的問題。讓我告訴你怎麼做。數據表格保持不變;我將只使用不同類型的聯接。
法典
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id
GROUP BY c.city
HAVING COUNT(o.id) >=5;以下是更改的內容。當我使用 RIGHT JOIN 時,我切換了表的順序。現在,表訂單變為左訂單,表客户訂單變為右側訂單。連接條件保持不變。我只是切換了列的順序以反映表的順序,但沒有必要這樣做。
通過切換表的順序並使用 RIGHT JOIN,我將再次輸出所有客户,即使他們沒有下任何訂單。
查詢的其餘部分與上一示例中相同。輸出也是如此。
注意:在實踐中,右聯接相對較少使用。對於SQL用户來説,LEFT JOIN似乎更自然,因此他們更頻繁地使用它。任何可以用 RIGHT JOIN 完成的事情也可以用 LEFT JOIN 完成。因此,沒有特定情況可能首選 RIGHT JOIN。
輸出

4. 完全連接示例
Salesforce和特斯拉的問題希望你計算2020年推出的產品公司數量與前一年推出的產品公司數量之間的淨差異。
新產品“你會得到一個按公司按年份列出的產品發佈表。編寫一個查詢來計算 2020 年推出的產品公司數量與上一年推出的產品公司數量之間的淨差額。輸出公司名稱以及與上一年相比發佈的2020年淨產品淨差額。
數據
該問題提供了一個包含以下列的表。
car_launches
年:國際
company_name:瓦爾查爾
product_name:瓦爾查爾
當只有一個表時,我將如何連接表?嗯,讓我們也看看吧!法典這個查詢有點複雜,所以我會逐漸揭示它。
SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;第一個 SELECT 語句查找 2020 年的公司和產品名稱。此查詢稍後將轉換為子查詢。
這個問題希望你找到2020年和2019年之間的區別。因此,讓我們為2019年編寫相同的查詢。`
SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019;
現在,我將把這些查詢變成子查詢,並使用完全外部聯接來聯接它們。
SELECT *
FROM
(SELECT company_name,
product_name AS brand_2020FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name;
子查詢可以被視為表,因此可以連接。我給第一個子查詢一個別名,並將其放在 FROM 子句中。然後,我使用“完全外部聯接”將其與公司名稱列上的第二個子查詢聯接。
通過使用這種類型的 SQL 聯接,我將在 2020 年的所有公司和產品與 2019 年的所有公司和產品合併。
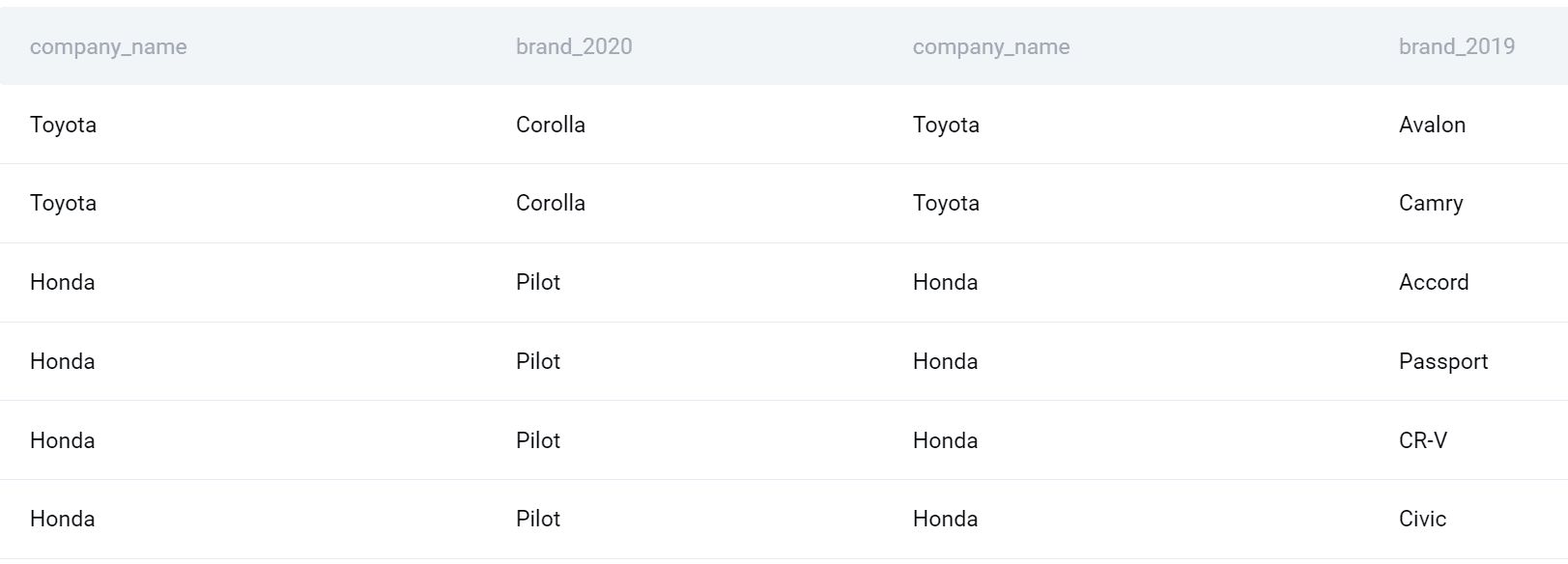
現在我可以完成我的查詢了。讓我們選擇公司名稱。此外,我將使用 COUNT() 函數查找每年推出的產品數量,然後減去它以獲得差額。最後,我將按公司對輸出進行分組,並按公司字母順序對其進行排序。
這是整個查詢。
SELECT a.company_name,
(COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_productsFROM
(SELECT company_name,
product_name AS brand_2020FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;
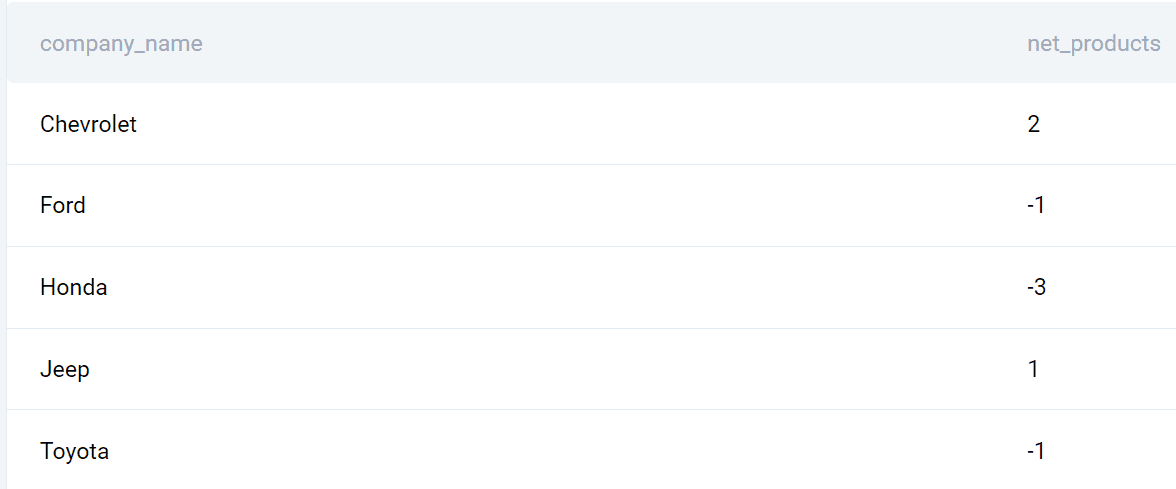
## 輸出
以下是 2020 年和 2019 年之間的公司列表和推出的產品差異。
## 5. 交叉連接示例
德勤的這個問題非常適合展示CROSS JOIN的工作原理。
最多兩個數字“給定一列數字,考慮兩個數字的所有可能排列,假設數字對(x,y)和(y,x)是兩個不同的排列。然後,對於每個排列,找到兩個數字中的最大值。
輸出三列:第一列、第二個數字和兩列中的最大值。
該問題希望您找到兩個數字的所有可能排列,假設數字對 (x,y) 和 (y,x) 是兩個不同的排列。然後,我們需要找到每個排列的最大值。
## 數據
這個問題給了我們一個帶有一列的表格。
deloitte_numbers
數:國際
## 法典
此代碼是 CROSS JOIN 的一個示例,也是自連接的示例。
SELECT dn1.number AS number1,
dn2.number AS number2,
CASE
WHEN dn1.number > dn2.number THEN dn1.number
ELSE dn2.number
END AS max_numberFROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
我在 FROM 中引用該表並給它一個別名。然後,我通過在交叉連接後引用它併為表提供另一個別名來將其與自身交叉連接。
現在可以使用一個表,因為它們是兩個。我從每個表中選擇列號。然後,我使用 CASE 語句設置一個條件,該條件將顯示兩個數字的最大數量。
為什麼在這裏使用交叉連接?請記住,它是一種 SQL 聯接類型,將顯示所有表中所有行的所有組合。這正是問題要問的!
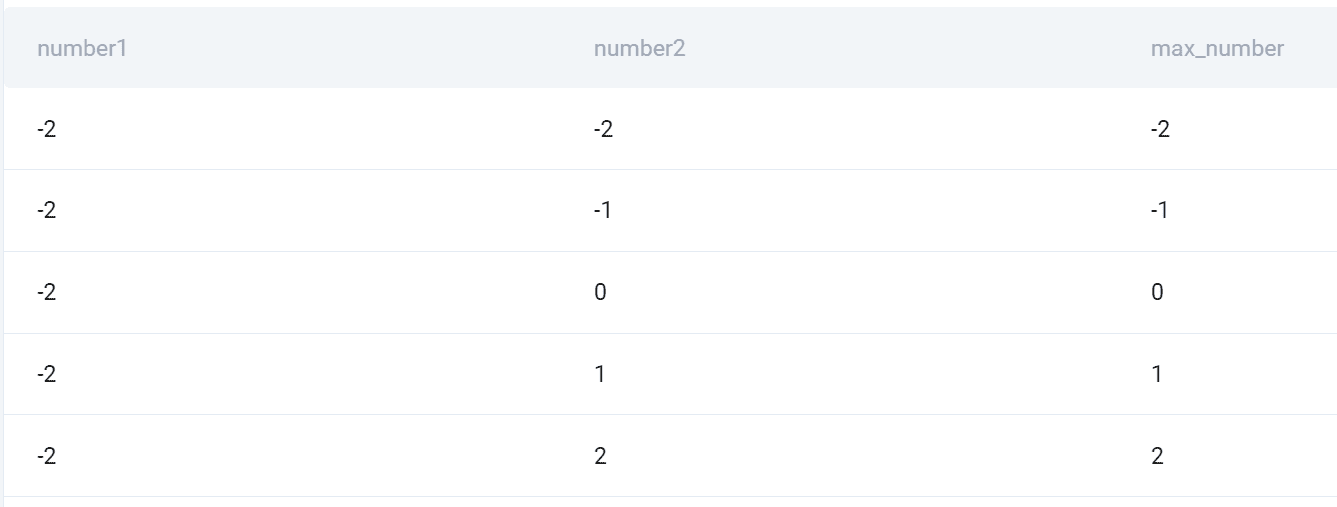
## 輸出
這是所有組合的快照以及兩者的較高數字。
## 將 SQL 聯接用於數據科學
現在您已經知道如何使用 SQL 聯接,問題是如何在數據科學中利用這些知識。
SQL 聯接在數據科學任務(如數據瀏覽、數據清理和特徵工程)中起着至關重要的作用。
下面是如何利用 SQL 聯接的幾個示例:合併數據:通過聯接表,可以將不同的數據源彙集在一起,從而分析多個數據集之間的關係和相關性。例如,將客户表與交易表聯接可以提供對客户行為和購買模式的見解。
數據驗證:聯接可用於驗證數據質量和完整性。通過比較來自不同表的數據,可以識別不一致、缺失值或異常值。這有助於您進行數據清理,並確保用於分析的數據準確可靠。
特徵工程:聯接有助於為機器學習模型創建新功能。通過合併相關表,您可以提取有意義的信息並生成捕獲數據中重要關係的特徵。這可以增強模型的預測能力。
聚合和分析:聯接使您能夠跨多個表執行復雜的聚合和分析。通過組合來自各種來源的數據,您可以全面瞭解數據並獲得有價值的見解。例如,將銷售表與產品表聯接可以幫助您按產品類別或區域分析銷售業績。
## SQL 聯接的最佳做法
正如我已經提到的,聯接的複雜性並沒有體現在它們的語法中。您看到語法相對簡單。
聯接的最佳實踐也反映了這一點,因為它們不關心編碼本身,而是聯接的作用和性能。
若要充分利用 SQL 中的聯接,請考慮以下最佳做法。
* 瞭解您的數據: 熟悉數據中的結構和關係。這將幫助您選擇適當的聯接類型,並選擇正確的列進行匹配。
*
* 使用索引:如果表很大或經常聯接,請考慮在用於聯接的列上添加索引。索引可以顯著提高查詢性能。
*
* 注意性能:聯接大型表或多個表的計算成本可能很高。通過篩選數據、使用適當的聯接類型並考慮使用臨時表或子查詢來優化查詢。
*
* 測試和驗證:始終驗證聯接結果以確保正確性。執行健全性檢查並驗證聯接的數據是否符合您的預期和業務邏輯。
結論
SQL 聯接是一個基本概念,使數據科學家能夠合併和分析來自多個源的數據。通過了解不同類型的 SQL 聯接、掌握其語法並有效利用它們,數據科學家可以解鎖有價值的見解、驗證數據質量並推動數據驅動的決策。
我用五個例子向您展示瞭如何做到這一點。現在,您可以利用 SQL 的強大功能並加入您的數據科學項目並取得更好的結果。
原文鏈接[SQL 數據科學:瞭解和利用連接](https://www.mvrlink.com/sql-data-science-understanding-and-utilizing-joins/)