

前言
GreptimeDB 支持以單機和分佈式的形式進行部署,但緊隨而來一個尖鋭的問題:我們對投入生產的這套複雜系統有多少信心?
在 0.3 到 0.4 的迭代過程中,我們引入了混沌工程(Chaos engineering)來提高系統的健壯性。
混沌工程是怎麼實施的
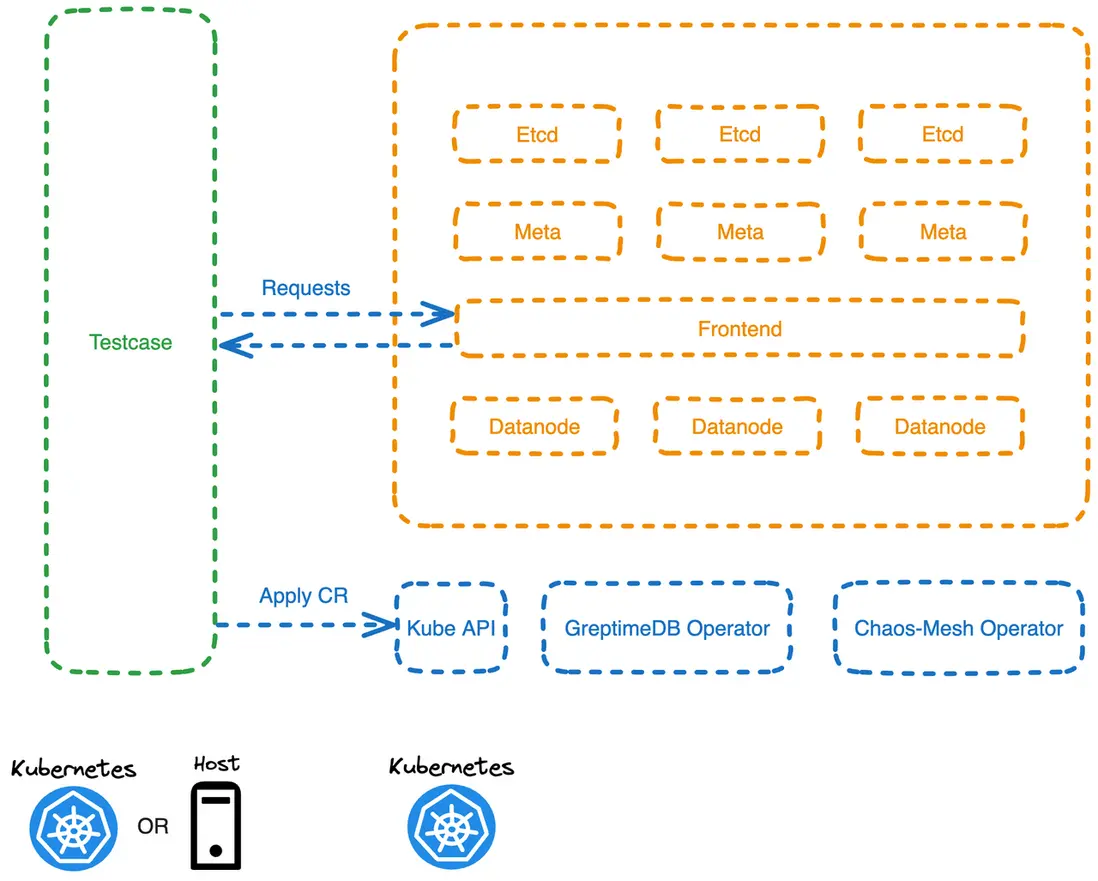
我們選擇了 Chaos Mesh 作為故障注入工具。我們在 Pod 中運行一個測試程序(Testcase),該程序通過定義 CR(Custom Resource)為 DB 集羣中特定的 Pod 注入故障;並在轉移故障後,對 DB 集羣的可用性和數據完整性進行驗證。
下面是一個示例,向 greptimedb-cluster 命名空間中名為 greptimedb-datanode-1 的 Pod 注入一個 Pod Kill 的故障。
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
namespace: greptimedb-cluster
spec:
action: pod-kill
mode: one
selector:
filedSelectors:
'metadata.name': 'greptimedb-datanode-1'為了便於調試測試程序,測試程序在開發環境中,可以直接運行在主機上,並通過 Kubectl 的端口轉發訪問 K8s 中的 DB 服務。
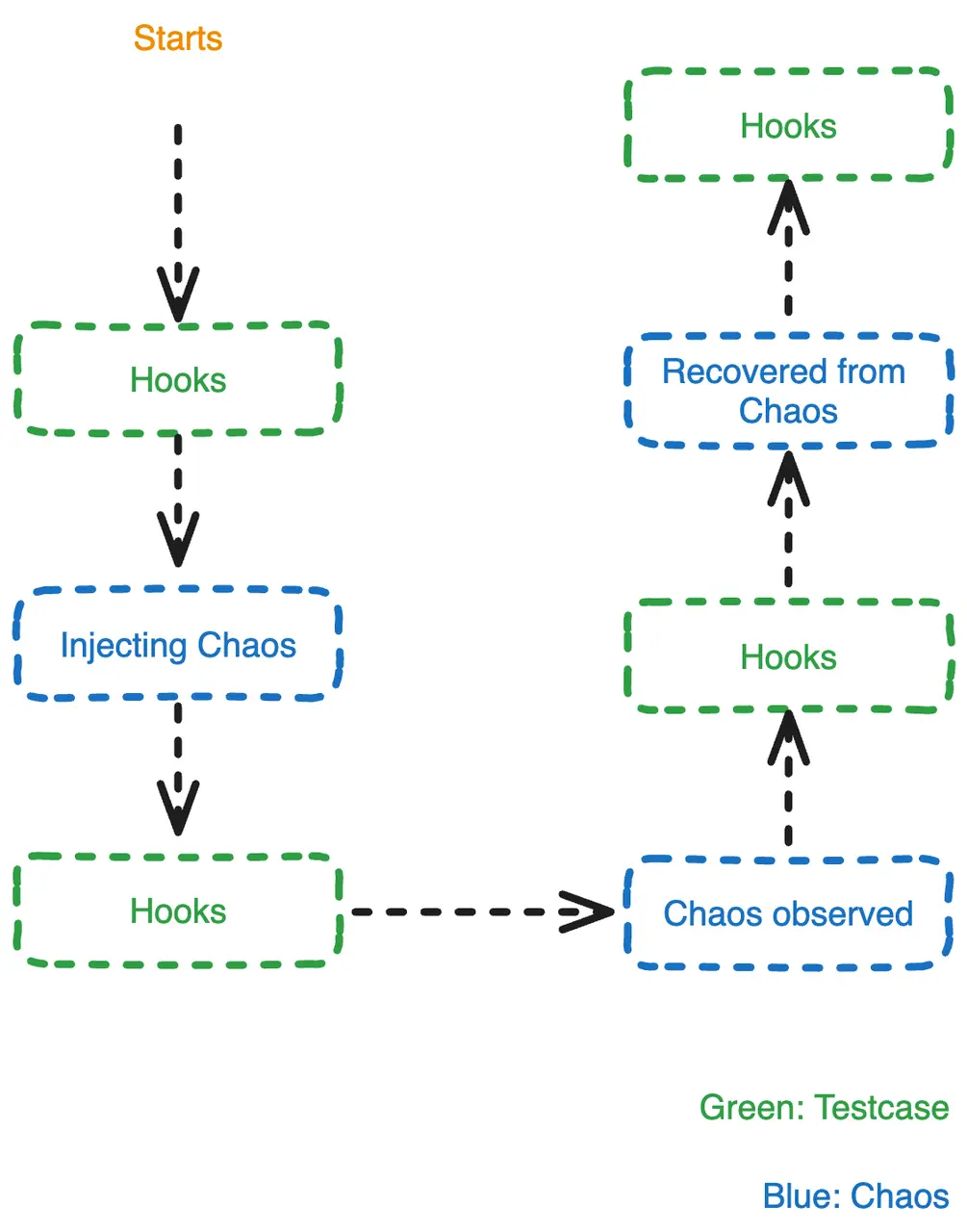
一些探索和經驗
1. 從最小場景開始
測試覆蓋不高時,可能會有一些“負負得正”的情況,讓整套系統看起來“正常”運行(實際上即使覆蓋率較高,也依然可能存在這些問題)。所以我們可以從最小場景開始測試,這個階段你需要非常清晰地知道系統的預期行為,並通過查看系統日誌,判斷系統的行為是否真的符合預期,以便發現問題後及時補相應的集成測試。
例如,我們需要驗證系統是否能容忍 Datanode 節點被 Kill,並觸發 Region Failover 流程(即將 Region 遷移到其他可用節點)。我們可以通過構建一個最小場景(少量表,少量數據)來進行驗證,通常當故障被注入到故障真正發生會有一定的時間間隔,此時我們需要一些方法去判斷系統是否真實發生故障了。
通常有幾種做法:通過調用 Kube API 觀察 ReplicatSet 的 Pod 副本數量少於預期;亦或是通過對目標節點進行讀寫來感知——在觀測到故障前不間斷的發起一些(少量的)將會路由到目標節點的讀寫操作,當客户端會返回故障時,即可視為目標節點不可用。隨後等待集羣恢復(例如調用 Kube API 等待 ReplicatSet 的 Pod 副本數量回到預期),我們就可以開始驗證服務可用性和數據的完整性。
2. 儘可能貼近真實的場景
GreptimeDB 可以將數據保存在 AWS S3 或者阿里雲 OSS 等等這樣的廉價對象存儲上。S3 這類存儲相比本地存儲來説,在測試中還是有不少差異的,主要體現在對 S3 訪問的延遲上。應儘早地貼近真實場景,即測試使用 S3 存儲的 DB 集羣。我們在開發測試程序的時候,也要將被測試 DB 集羣的數據存儲在靠近開發環境的 S3 中。
3. 梳理思路 + 補充集成測試
在開始混沌測試前,儘可能地把思路梳理清晰,在集成測試中把將要測試到鏈路進行覆蓋。混沌測試還是有不少額外工作量的,前期把測試做到位能節省不少時間。當然混沌測試和集成測試也可以説是相輔相成的,有些問題只有你真的在混沌測試中遇到了,才會打破你之前的一些判斷:“哇*,原來這個不是我想的小概率事件🤣”。
4. 關注偶發的問題
任何偶然發生的問題都要深究,對於小概率發生的問題其實需要大量的重試,並通過日誌精準地定位問題。
5. 構建可複用故障
構建一個混沌測試需要投入不少精力:通常注入一個故障,其中會涉及到多個步驟,例如注入故障,觀察到故障發生,等待服務完全恢復等。通過對這些步驟進行抽象,我們可以做到實現注入一個故障,測試多個不同的場景。
在混沌工程中發現的 Bugs
我們在混沌工程中發現的 Bugs 主要集中在以下幾類:
- Trait 的不同實現,行為不一致;
- 字段或接口冗餘;
- 多個 Bug 疊加,負負得正;
- 未使用別名造成的歧義;
- Corner Case 中數據與緩存不一致;
- 迭代過程中多人協作造成的一些遺漏。
我們還很意外地發現了一個上游的 Bug,OpenDAL FsBackend 的異步寫入在 sync_all 之前未調用 flush,導致其有潛在丟失數據的風險。我們在 0.4 版本中及時反饋並修復了這個 Bug,可以通過下面鏈接詳細瞭解:
- https://github.com/GreptimeTeam/greptimedb/issues/2382
- https://github.com/apache/incubator-opendal/issues/3052
- https://github.com/tokio-rs/tokio/issues/6005
關於 Greptime:
Greptime 格睿科技致力於為智能汽車、物聯網及可觀測等產生大量時序數據的領域提供實時、高效的數據存儲和分析服務,幫助客户挖掘數據的深層價值。目前主要有以下三款產品:
- GreptimeDB 是一款用 Rust 語言編寫的時序數據庫,具有分佈式、開源、雲原生和兼容性強等特點,幫助企業實時讀寫、處理和分析時序數據的同時降低長期存儲成本。
- GreptimeCloud 可以為用户提供全託管的 DBaaS 服務,能夠與可觀測性、物聯網等領域高度結合。
- GreptimeAI 是為 LLM 應用量身定製的可觀測性解決方案。
- 車雲一體解決方案是一款深入車企實際業務場景的時序數據庫解決方案,解決了企業車輛數據呈幾何倍數增長後的實際業務痛點。
GreptimeCloud 和 GreptimeAI 已正式公測,歡迎關注公眾號或官網瞭解最新動態!對企業版 GreptimDB 感興趣也歡迎聯繫小助手(微信搜索 greptime 添加小助手)。
官網:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文檔:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
