
2025 年是大模型推理技術發展的關鍵之年。自年初 DeepSeek R1 發佈引發全民關注以來,推理框架加速需求暴漲,推理優化的戰場驟然升温。以 vLLM、SGLang、MindIE 為代表的高性能推理引擎,以及 FlashInfer、FlashAttention、ATB 等底層加速庫不斷突破性能瓶頸,相比年初,部分前沿框架的推理性能提升已達 3 到 4 倍以上。
隨着 Agent 應用的爆發和長上下文能力的普遍需求,端到端推理性能、大規模併發吞吐和低響應延遲已成為推理優化的三大主線,推動戰火轉向系統級的加速技術組合與工程優化。
在這一關鍵轉折點,我們需要一個平台級解決方案,將前沿的推理加速技術集大成,並將其普惠化,讓更多開發者和企業觸手可及。
GPUStack:連接前沿技術與生產力
自 2024 年 7 月正式開源以來,GPUStack 已在全球上百個國家和地區獲得廣泛使用與認可,以穩定可靠與出色的易用性贏得了用户羣體的普遍讚譽。我們始終堅信,開源生態的力量,是推動大模型普惠化的核心驅動力。
歷經數月的深入研發與打磨,我們隆重發布 GPUStack v2 —— 一個面向未來的高性能模型推理 MaaS 平台,旨在充分釋放異構硬件的算力潛能,並極大簡化異構環境下模型部署的複雜度。
在大模型推理的下半場,GPUStack v2 不再是簡單的模型服務平台,而是高性能推理生態的協調者與賦能者。
深度優化:集成生態之力,釋放硬件潛能
當前,推理引擎如 vLLM、SGLang、MindIE 等在算子融合、KV Cache 管理和調度優化方面已達到較高性能水平。然而,在不同硬件和應用場景下,要釋放這些引擎的全部潛力,需要大量的專業知識和手動調優。
GPUStack v2 解決了這一複雜性:
專家經驗調優
過去數千個小時的投入,我們在無數測試與驗證中不斷打磨 GPUStack,針對不同性能場景構建了完善的優化數據庫,並形成一套持續進化的推理性能最佳實踐。
內部測試數據顯示,通過最佳引擎選型和配置調優組合,H200 GPU 上運行 GLM 4.6 的吞吐量最高可提升 135%;H100 GPU 上運行 Qwen3-8B 的**響應延遲最高可降低 63%**。
我們會持續探索和投入,並將這些實踐沉澱進 GPUStack v2。各類優化和測試方法也會開放到我們的推理性能實驗室,讓每一位用户都能開箱即用地獲得卓越性能。
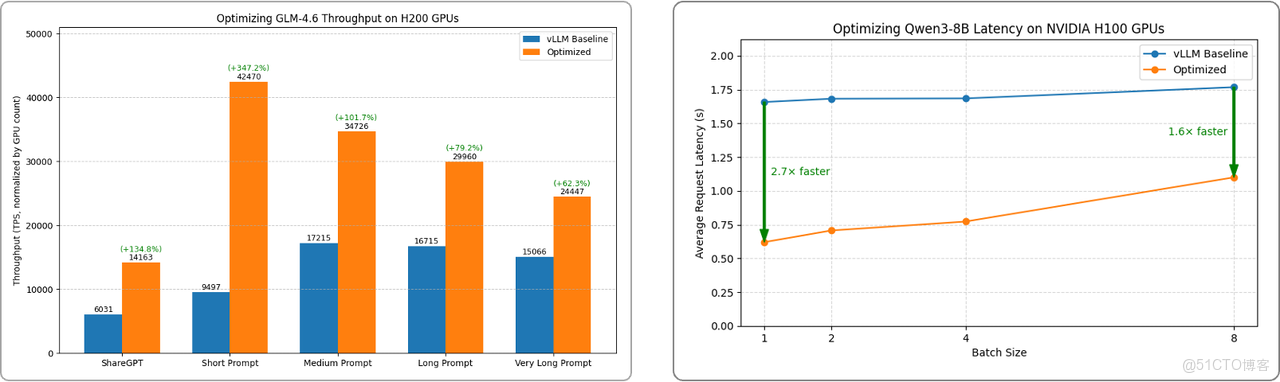
長序列與低時延優化
GPUStack v2 在專家調優基礎上,將多項前沿推理優化方法進行工程化整合,使用户無需修改模型或複雜配置,即可獲得穩定而顯著的性能提升。
- 解碼加速
GPUStack v2 原生集成 Eagle3、MTP、Ngram 等多種領先的解碼加速算法,通過縮短 Token 生成路徑、提升解碼並行度,顯著降低生成延遲(TPOT)。所有加速能力均通過統一接口封裝,開箱即用。
未來,我們將進一步推出針對主流模型優化後的 Eagle 解碼頭,同時提供個性化模型訓練服務,讓企業能夠構建適配自身業務的高性能解碼方案,實現更極致的推理速度。
- KV Cache 擴展
針對不斷增長的長上下文需求,GPUStack v2 提供多種開箱即用的 KV Cache 擴展方案(如 LMCache、HiCache),進一步增強 KV Cache 的靈活性與伸縮能力。
平台支持利用 GPU 主機內存擴容 KV Cache 池,並可通過高速外部共享存儲實現跨設備緩存擴展,從而大幅降低長序列場景下的首 Token 延遲(TTFT),顯著改善長文本處理、Agent 推理、多輪對話等場景的實際體驗。

兼容性與可插拔
當前,推理引擎領域呈現多元化的競爭格局。不同推理引擎各自在算力調度、KV Cache 管理或長上下文優化等維度深度發力,性能各有千秋。然而,尚無一個方案能在所有場景中全面領先,用户在選擇與切換時仍面臨巨大挑戰。
為此,GPUStack v2 以靈活開放為核心,提供可插拔後端架構與通用 API 代理支持,讓用户能夠以最高自由度選擇最適合的推理引擎。
無論是 vLLM、SGLang,還是其他新興或傳統 AI 推理引擎,GPUStack 都能輕鬆兼容,並支持任意引擎版本的靈活切換與異構環境下的智能調度,確保用户始終能在第一時間使用最新的開源模型與推理優化成果。
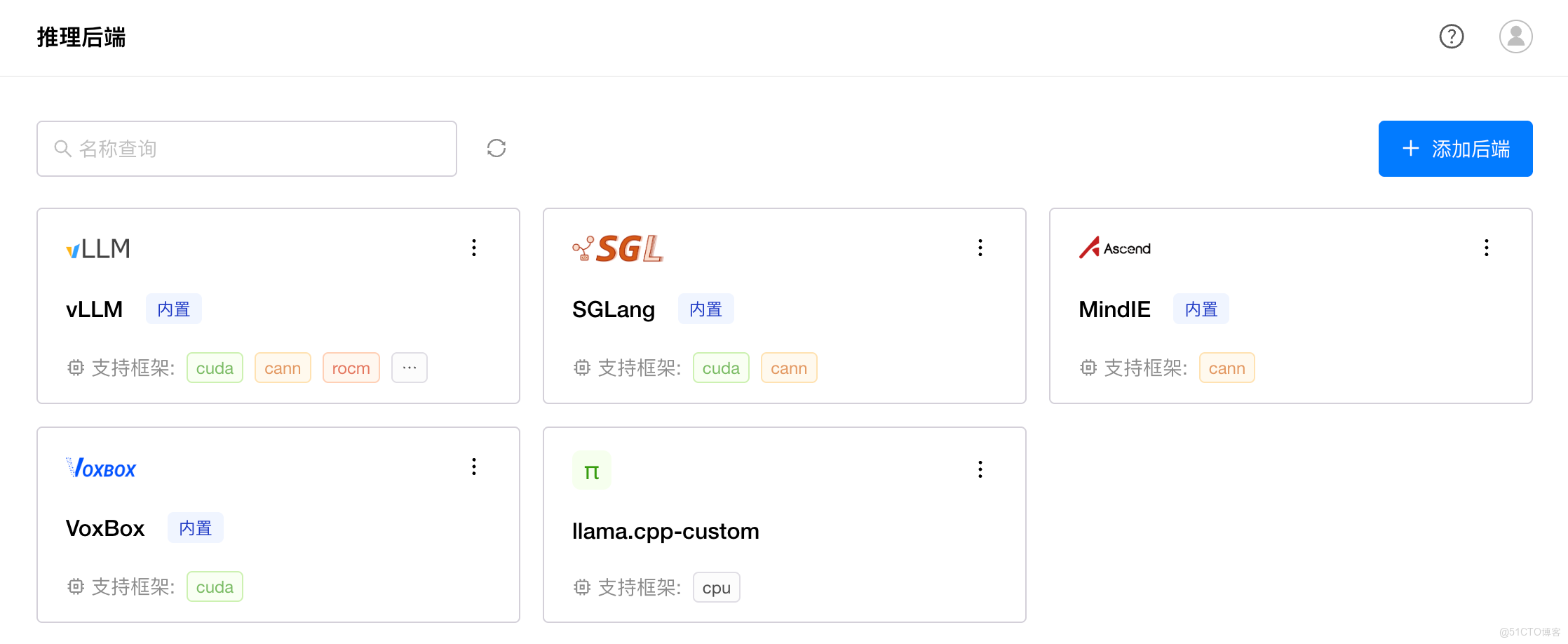
國產算力賦能
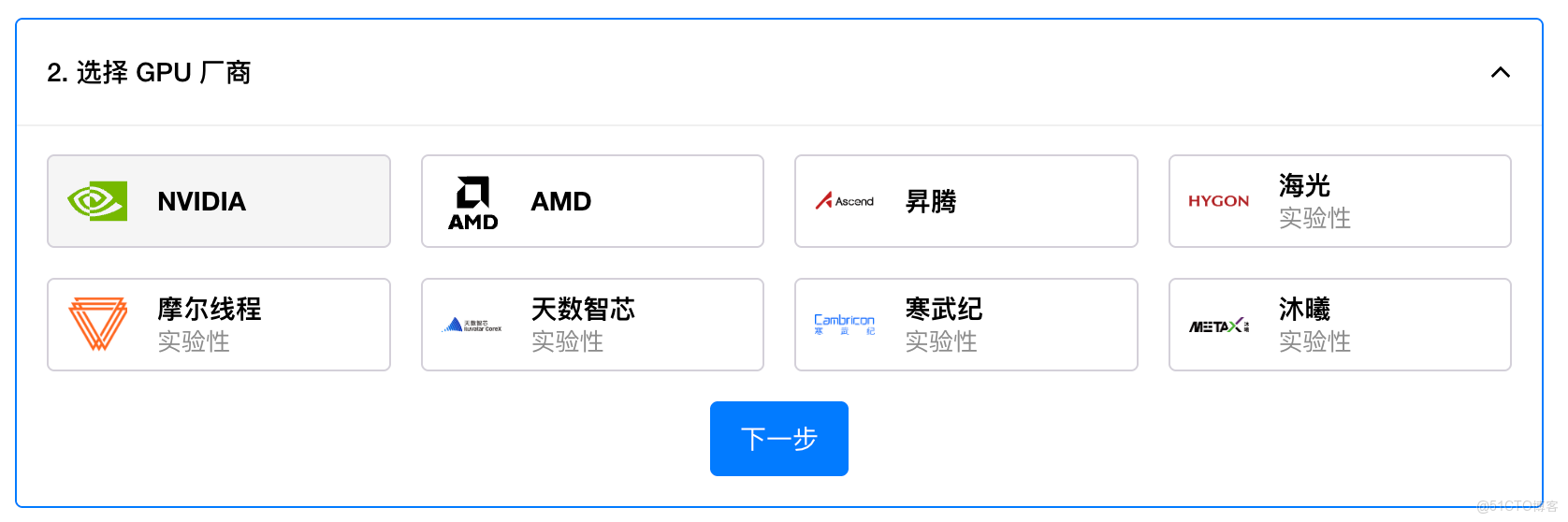
在大模型推理進入規模化落地階段的今天,異構算力的應用趨勢日益顯著。GPUStack v2 原生支持 NVIDIA、AMD 以及昇騰、海光、摩爾線程、天數智芯、寒武紀、沐曦等國內外主流異構算力,為用户提供跨硬件環境的一致、高效推理體驗。
針對國產算力平台,GPUStack 團隊進行了全面適配與探索優化。例如,在華為昇騰 910B NPU 上運行 Qwen3-30B-A3B 模型時,不同測試組合的性能差異顯著;通過最佳引擎選型和配置調優組合,可實現最高 284% 的吞吐量提升。
這充分展現出國產算力在大模型推理領域的強大潛力。未來,我們將繼續與國內外硬件生態夥伴深度協作,推動更多國產加速器在主流模型推理場景中實現最佳性能,助力算力自主可控與生態繁榮。
平台價值:從推理加速到高性能 MaaS 平台
隨着大模型推理進入下半場,單卡或單節點優化已無法滿足大規模部署需求。長上下文、多模型併發、異構算力環境以及複雜 Agent 任務,使平台層的算力調度、資源管理和運維治理成為核心競爭力。GPUStack v2 的目標,是提供一個高性能、可管理、可擴展、可觀測的 MaaS 平台,幫助企業在多樣化硬件與業務場景下,穩定、高效地運行大模型推理服務。
彈性算力:多 GPU 集羣與雲端資源統一管理
大模型推理的算力需求具有高負載與強波動特性。GPUStack v2 提供統一的算力管理與彈性擴縮容能力,使資源利用更加高效、可控與具成本優勢。
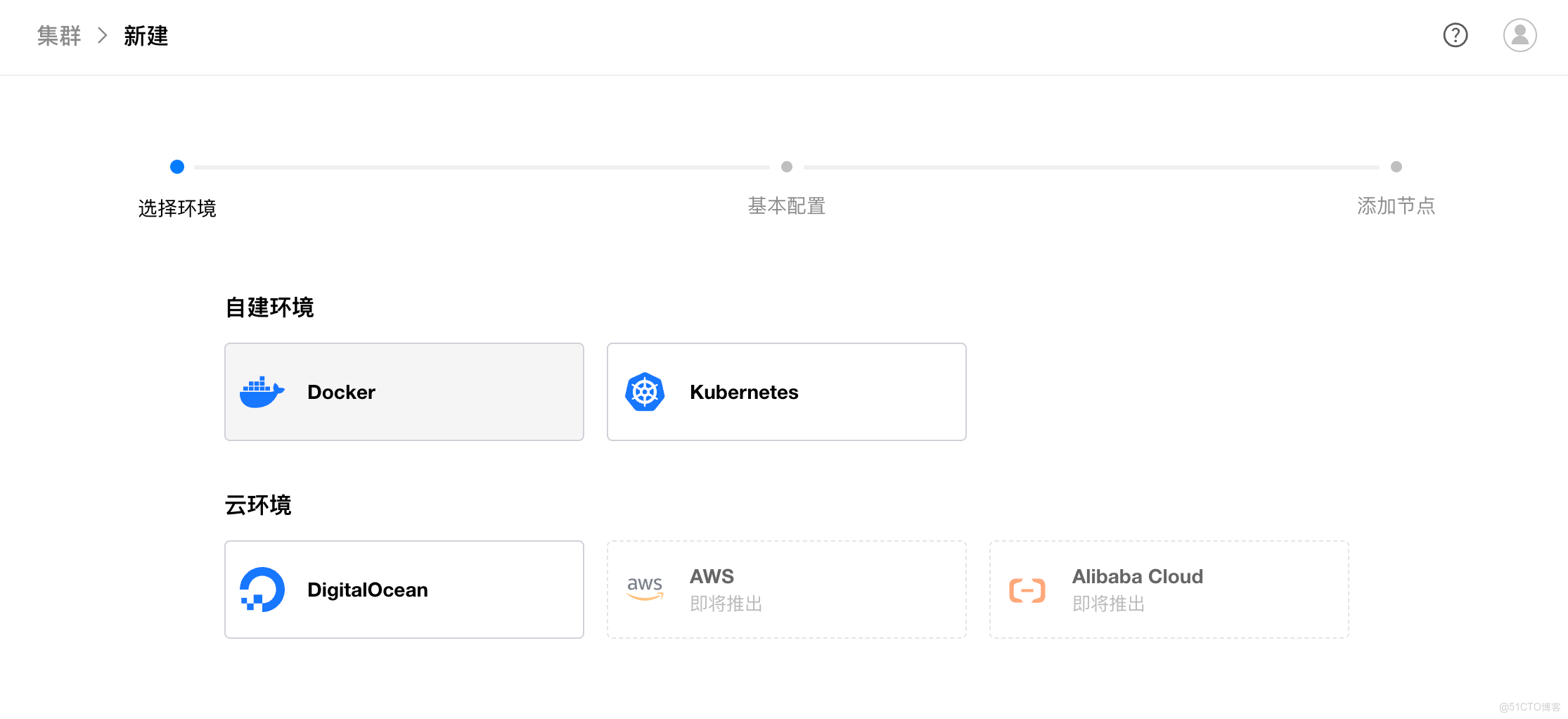
- 異構集羣統一管理
GPUStack v2 可以統一管理本地 GPU 集羣、Kubernetes GPU 資源以及多種異構雲 GPU,實現跨平台、高性能的推理資源池。平台在不同硬件架構間提供一致的調度與監控能力,讓用户充分釋放現有算力,保障高可用性與無限擴展潛力。
- 公有云 GPU 彈性擴縮容
通過與 AWS、阿里雲、DigitalOcean 等雲平台的深度集成,GPUStack v2 能根據業務負載自動擴容雲端 GPU 實例。高峯期快速拉起 GPU,保證吞吐與延遲滿足 SLA;低負載時可回收 GPU 資源,優化成本支出,實現算力的高效利用。
安全與訪問治理:Higress AI Gateway 集成
在企業級場景中,模型服務必須具備可控性、可治理性和穩定性。GPUStack v2 深度集成 Higress AI Gateway,將訪問管理、流量治理與服務穩定性統一納入平台管理,打造企業級高可靠的大模型服務入口。
- 統一 API 接入與協議轉換
藉助 Higress 高性能 AI 網關,GPUStack v2 將所有模型服務,包括非 OpenAI API 接口以統一方式對外暴露,屏蔽底層推理引擎的差異。平台提供協議轉換與通用 API 代理,支持跨語言、跨框架及非標準 API 調用,顯著降低上層應用的接入成本,讓開發者“開箱即可接入”。
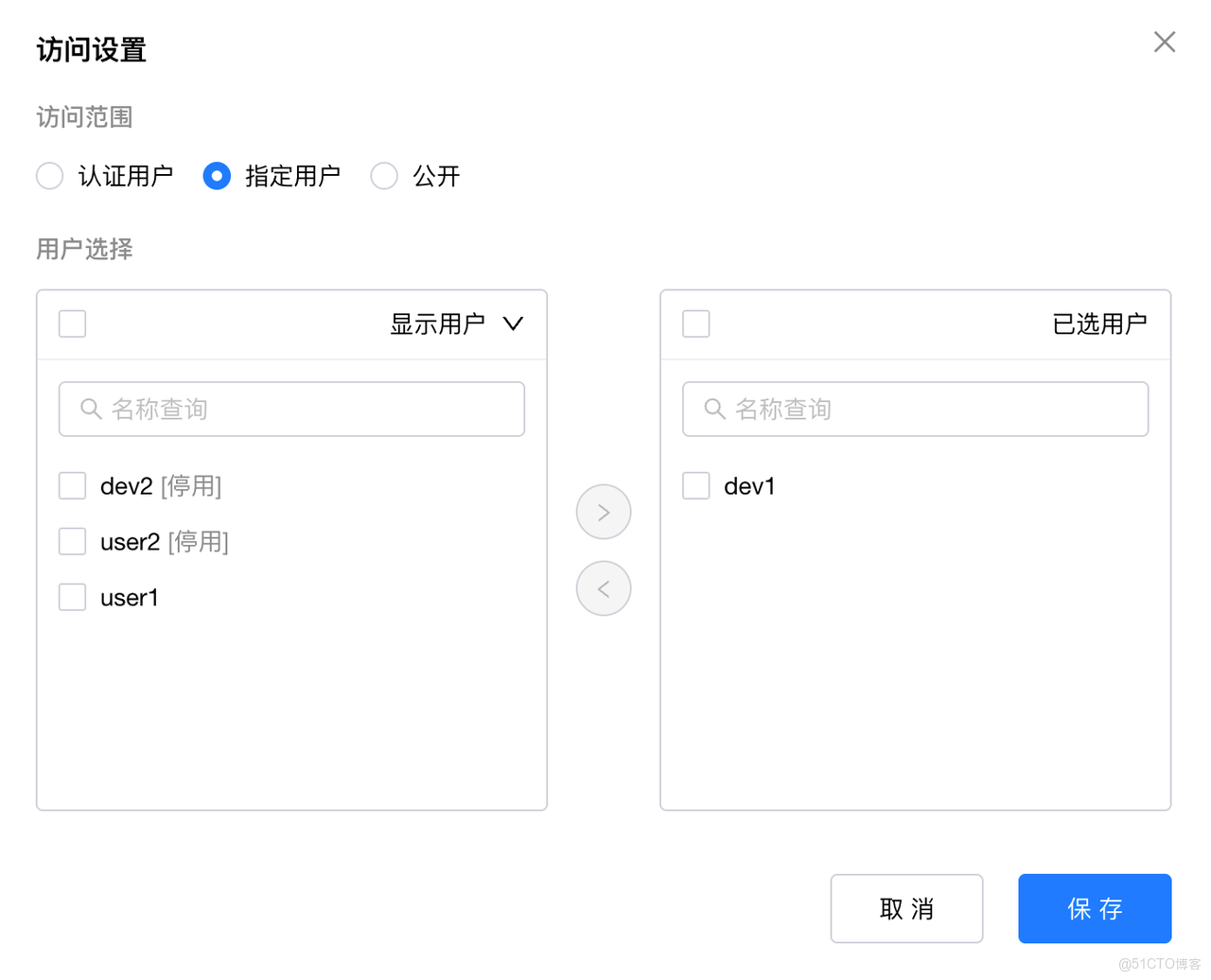
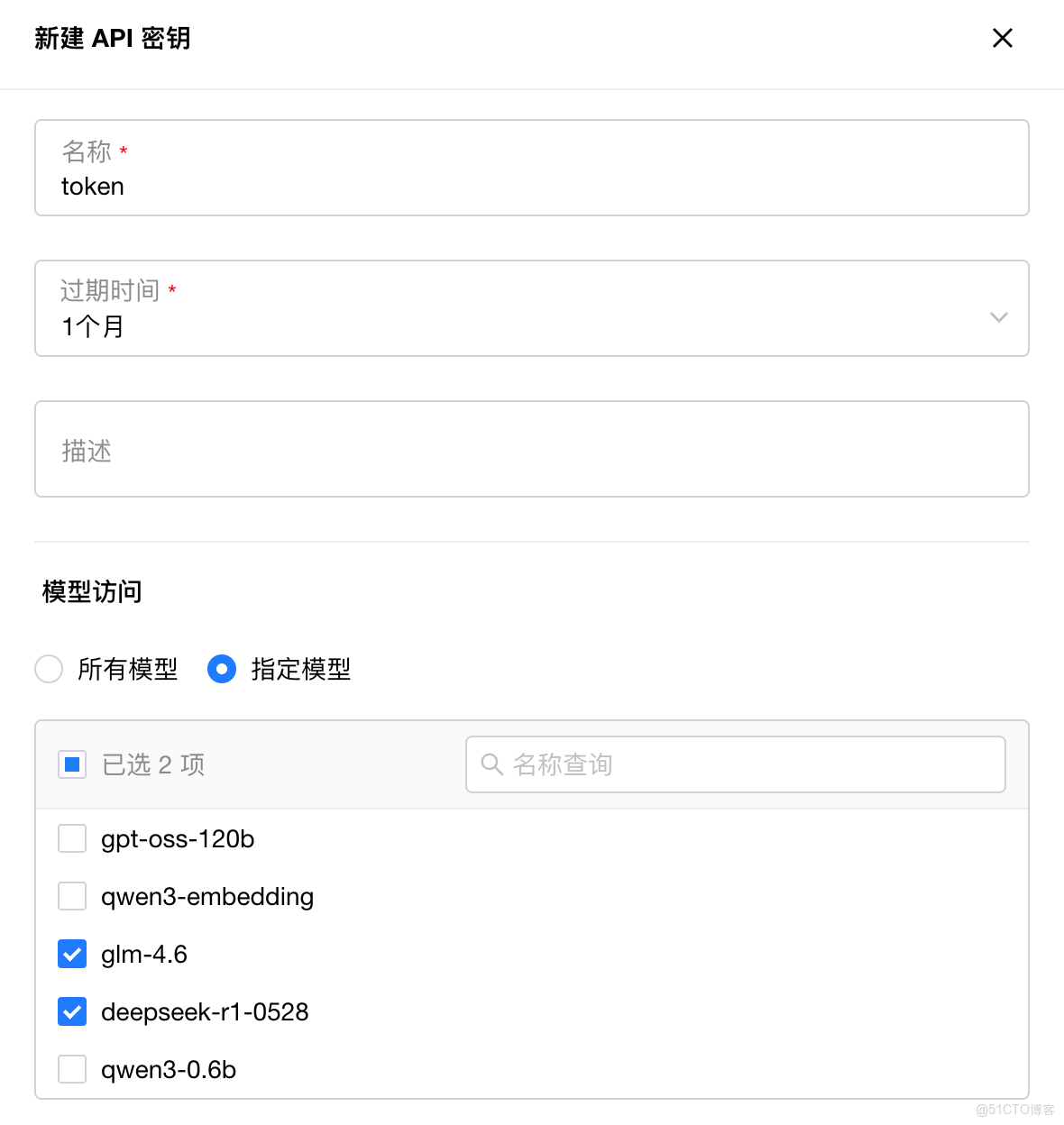
- 模型與 API Key 級訪問控制
GPUStack v2 提供 API Key 生命週期管理、模型級與 API Key 級的精細化訪問控制、權限分層以及企業級 SSO 集成,確保不同用户和團隊僅能訪問被授權的模型,實現平台級隔離與安全治理。
- 服務治理與可靠性保障
GPUStack v2 支持 Token 配額管理、速率限制、Fallback 故障切換等機制,通過流量控制與服務降級策略確保模型服務在高負載、異常或多業務競爭場景下依然保持穩定、可控與高可用。
全鏈路可觀測性與調用計量
在企業級大模型部署中,服務的穩定性、使用透明度和資源可控性至關重要。GPUStack v2 提供端到端可觀測能力,將模型運行狀態、調用情況與底層算力資源統一管理,實現可量化、可追蹤的推理服務。
- 模型健康監控
GPUStack v2 實時跟蹤模型運行狀態,包括推理錯誤、響應延遲和關鍵性能指標,通過可視化數據和報警機制,確保服務穩定可靠,併為異常排查提供強有力的數據支撐。
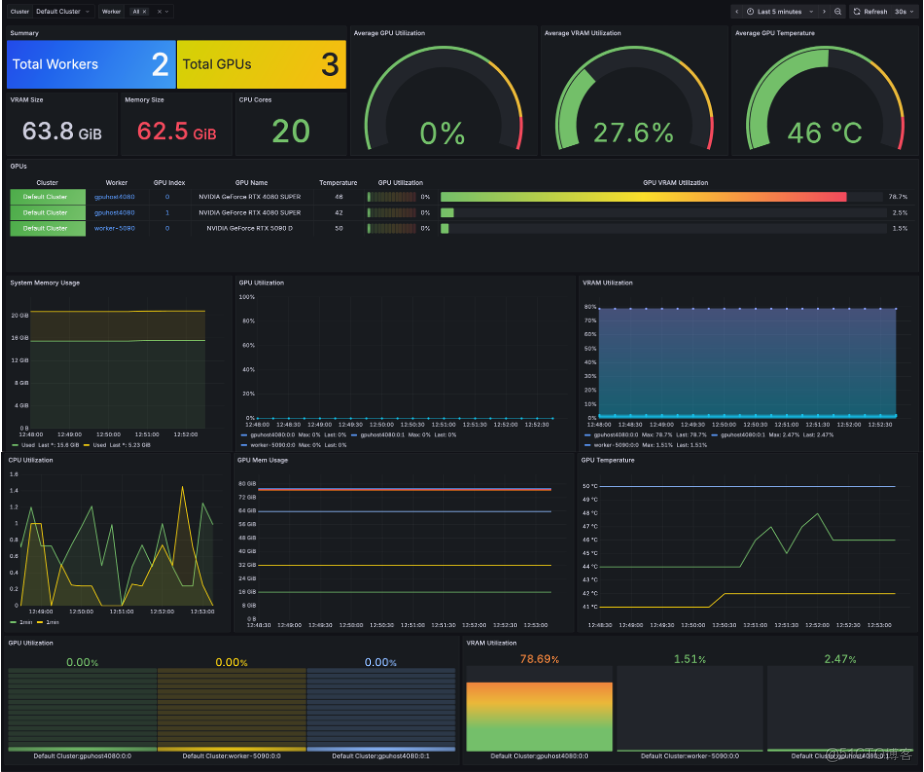
- 資源使用可視化
對每張 GPU、每個節點的計算利用率、顯存佔用、負載狀態等關鍵指標進行可視化監控,讓算力分配與集羣調度一目瞭然。幫助運維團隊快速發現瓶頸,優化資源使用,提高整體系統效率。
- 調用監控與計量統計
對每個 API 請求和 Token 使用量進行精細跟蹤和統計,支持按模型、團隊等維度分析,為計費、成本管理和容量規劃提供精確數據,使服務使用更加透明和可控,助力企業決策。

總結
GPUStack v2 不僅在推理層面提供端到端性能加速,更進一步將算力管理、智能調度、安全訪問與可觀測性收斂到統一的平台架構中。
它將高性能推理從單機調優擴展到異構集羣、跨雲、多模型的可管理基礎設施,使複雜生產場景中的資源利用、調度效率與服務穩定性都具備工程化保障。
在長上下文、高併發、低延遲正逐漸成為主流需求的背景下,GPUStack v2 正成為企業級大模型部署與持續運維的可靠、可擴展技術底座。
歡迎通過以下文檔快速安裝與體驗 GPUStack v2,也期待你探索更多用法,或向我們反饋真實場景中的問題與建議:
GitHub 倉庫: https://github.com/gpustack/gpustack
GPUStack 用户文檔: https://docs.gpustack.ai
Meetup 直播預告
為了讓更多開發者和 AI 愛好者深入瞭解 GPUStack v2 的架構設計與快速上手方法,同時解答大家在使用過程中遇到的問題,我們將在未來幾周陸續舉辦一系列在線 Meetup 直播。
在 Meetup 中,你將可以:
- 深入瞭解 GPUStack v2 的核心功能與最佳實踐
- 獲取專家調優經驗與性能優化技巧
- 現場提問,與社區和開發團隊直接交流
關注 GPUStack 官方公眾號或加入社區交流羣,第一時間獲取最新的 Meetup 時間、報名方式及直播主題推送。期待與你在線相聚,一起探索 GPUStack v2 的無限可能!