文章來源 | 恆源雲社區
原文地址 | Restormer
原文作者 | 咚咚
摘要
- 引入主題: 由於卷積神經網絡(CNNs)能夠從大規模數據中學習到圖像的generalizable特徵,所以被廣泛應用於圖像重建和相關任務。最近,另一類神經結構,Transformer,在自然語言和高水平的視覺任務已經顯示出顯著性能增益。
- 現存問題: 雖然 Transformer 模型彌補了 CNNs 的不足(即感受域有限和inadaptability to input content) ,但其計算複雜度隨着空間分辨率的增加而二次增長,因此不適用於大多數涉及高分辨率圖像的圖像重建任務。
- 解決方法: 論文提出了一個有效的Transformer模型,Restoration Transformer,Restormer,通過對基礎模塊(多頭前饋網絡)的幾個關鍵設計,使它能夠捕捉遠距離像素間的相互作用,同時仍然適用於大圖像。
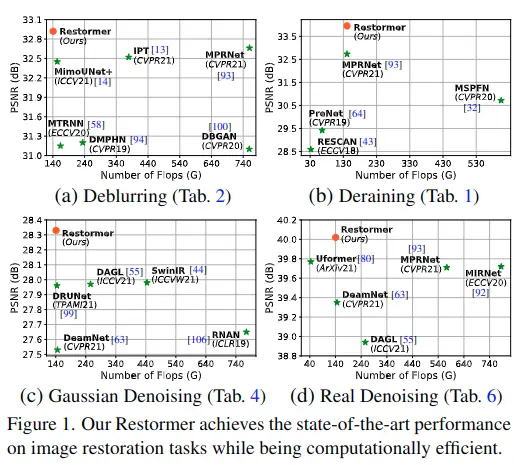
- 實驗結果: 在多個圖像重建任務上實現最先進的結果,包括圖像去噪、單圖像運動去模糊、散焦去模糊(單圖像和雙像素數據)和圖像去噪(高斯灰度/顏色去噪和真實圖像去噪)
算法
Overall Pipline
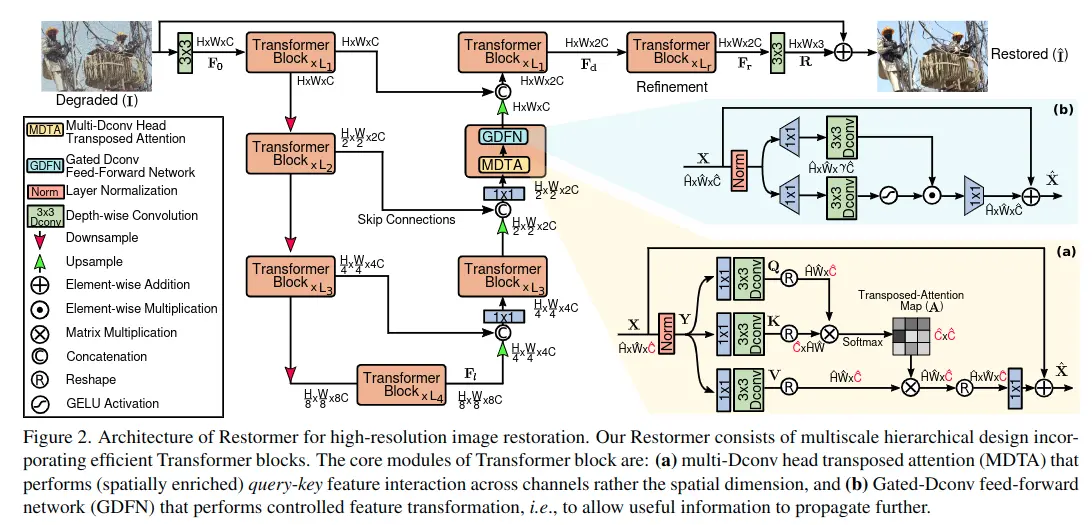
- 輸入圖像大小為\( I \in R^{H×W×3} \),首先利用一個卷積操作獲得特徵嵌入\( F_0 \in R^{H×W×C} \)
- \( F_0 \)通過一個對稱的4層編碼-解碼結構,得到高維特徵\( F_d \in R^{H×W×2C} \),每一層編碼/解碼都包括多個Transformer 模塊,從上到下,每一層中的Transformer模塊數量逐漸遞增,分辨率逐漸遞減。
- 編碼-解碼器之間使用跳躍連接來傳遞低維特徵信息。
- \( F_d \)進一步經過Refinement模塊來提取細節特徵
- 最後經過一個卷積層,並與輸入圖像進行疊加,得到最後的輸出圖像
如上圖所示,每個Transformer模塊中包括MDTA和GDFN模塊,接下來進行詳細介紹。
MDTA(MULTI-DCONV HEAD TRANSPOSED ATTENTION)

一般Transformer模塊中的多頭自注意力機制具有較大的計算量,在應用到高分辨率圖像上是不合適的,所以該論文提出了MDTA模塊。
有兩個與眾不同的方法:
- MDTA是計算通道上的自注意力而不是空間上,通過計算通道上的注意力來隱式編碼全局上下文信息。
- 在計算自注意力map之間,使用depth-wise卷積操作生成Q、K、V,這樣可以強調局部信息。
公式如下:
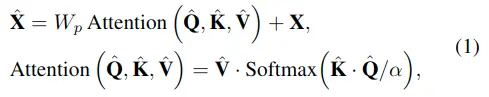
GDFN( GATED-DCONV FEED-FORWARD NETWORK)
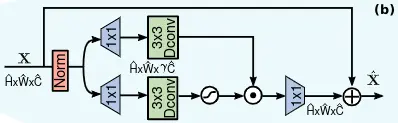
一般的Transformer模塊中使用FN進行逐像素特徵操作,擴展和減小通道數。
該論文與之不同,使用了(1)門控機制和(2)depthwise卷積
如上圖所示,下分支是一個門控單元,用於獲取每個像素點的激活狀態,使用1×1卷積層來擴展通道數,再使用3×3depthwise卷積層和GELU生成gate map。
並與上分支進行點乘,公式如下:
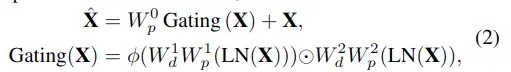
各層的GDFN通過控制信息流來允許每個層次關注與其他層次互補的細微細節。也就是説,與MDTA相比,GDFN提供了一個獨特的角色(專注於豐富上下文信息)。
PROGRESSIVE LEARNING
另外,論文還提出了一種漸進式訓練方法。
基於CNN的重建模型通常在固定大小的圖像patch上進行訓練。然而,在小裁剪patch上訓練Transformer模型可能不會編碼全局圖像統計信息,從而在測試時在全分辨率圖像上提供次優性能。
為此,論文采用漸進式學習的方式,在早期階段,網絡在較小的圖像塊上進行訓練,在後期的訓練階段,網絡在逐漸增大的圖像塊上進行訓練。
通過漸進學習在混合大小的patch上訓練的模型在測試時表現出更好的性能。
由於在大patch上進行訓練需要花費更長的時間,所以會隨着patch大小的增加而減少batch大小,以保持相同的訓練時間。
實驗
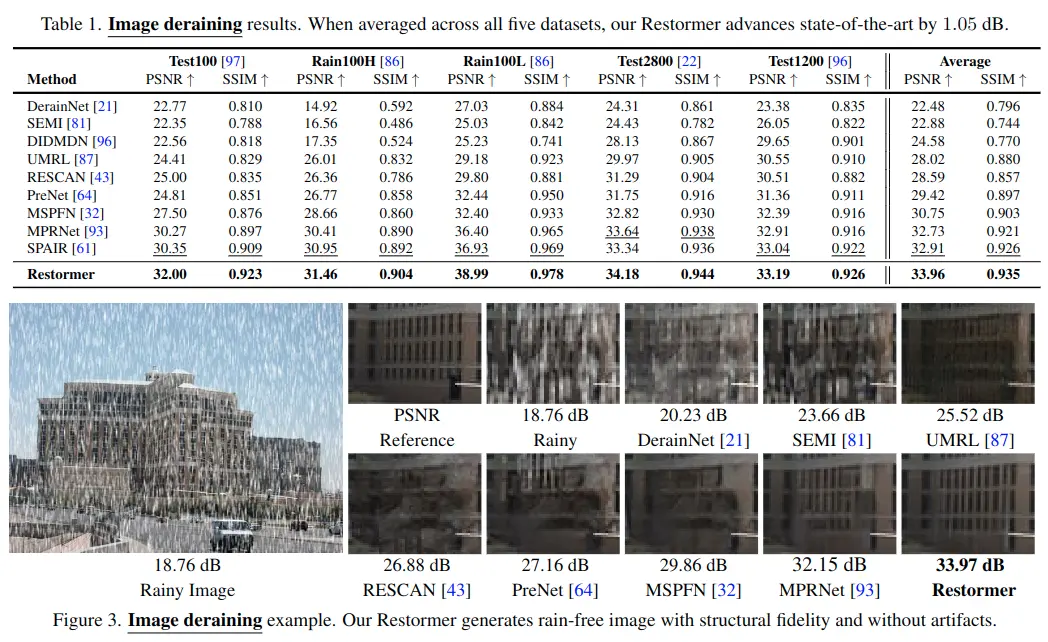
Image Deraining Results
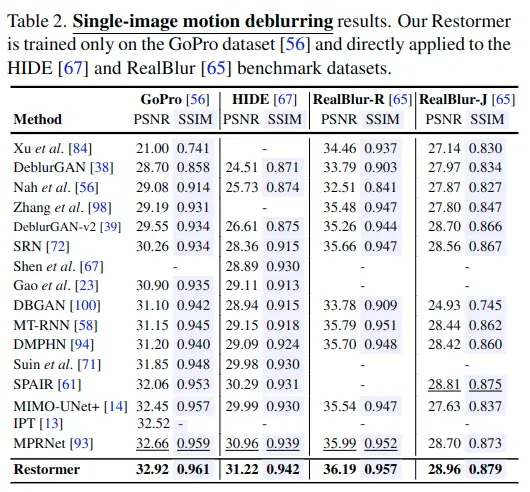
Single-image Motion Deblurring Results

Defocus Deblurring Results
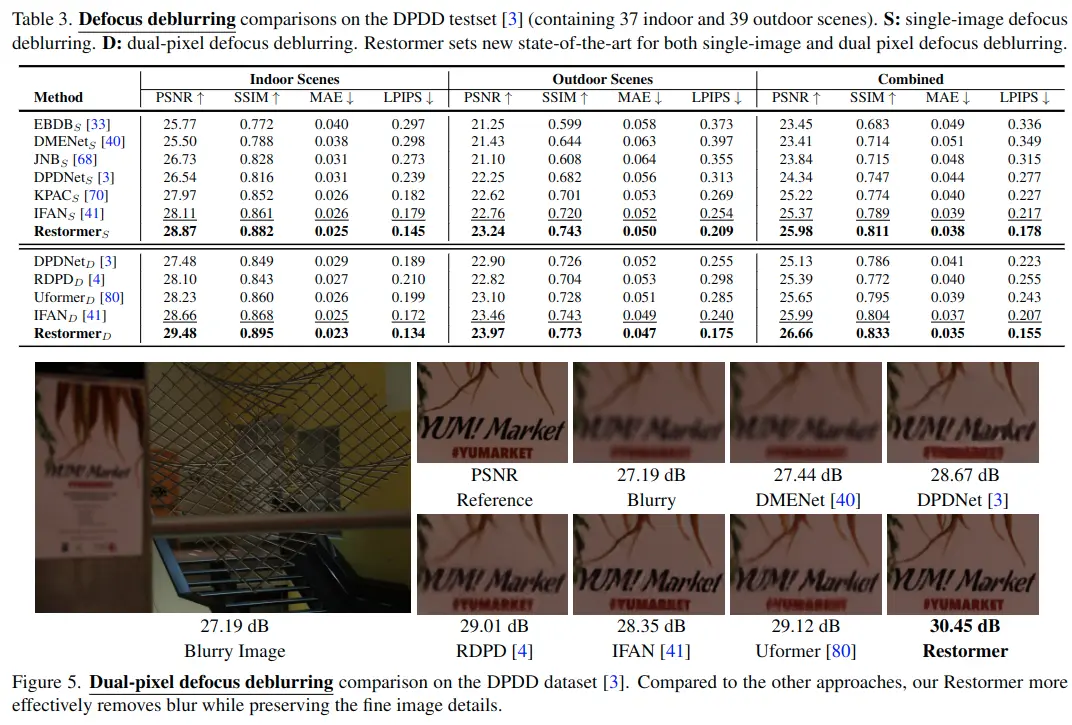
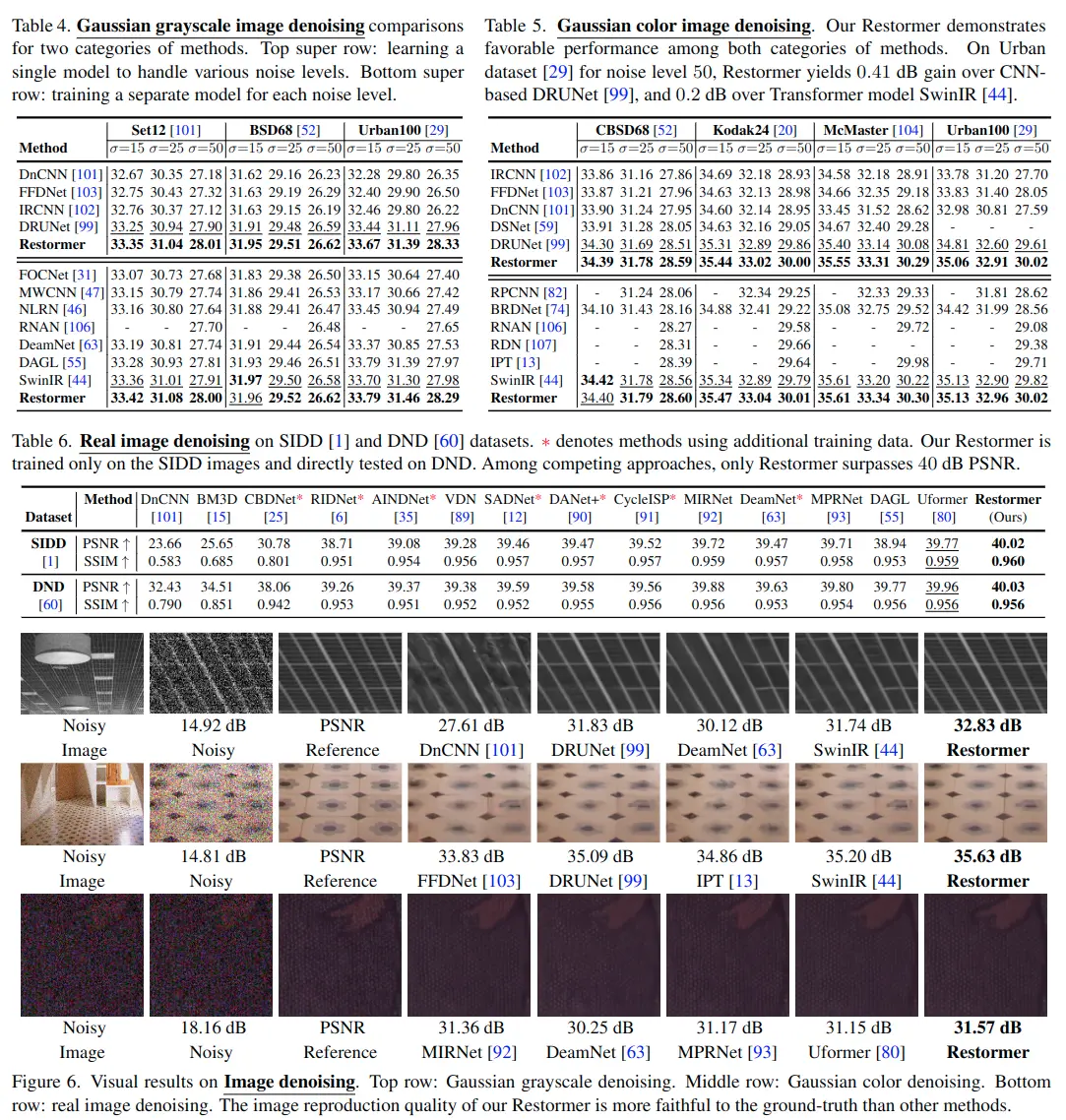
Image Denoising Results
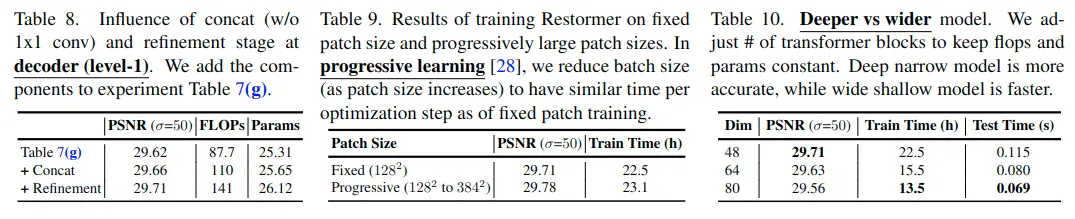
Ablation Studies