文章來源 | 恆源雲社區
原文地址 | 用於視頻的可變形Transformer
原文作者 | 咚咚
hi,大家好啊!窗外的樹🌲 綠了,樓下的桃花🌺 開了,春天,就這麼滴的過去了……
小編已經居家辦公(不能下樓)3個禮拜啦!敬請期待瘋掉的小編~
我的春遊徹底沒希望了!!!

説那麼多有啥用呢?還不是得乖乖搬運社區文章!畢竟社區夥伴們發帖是那麼的勤快!Respect!
正文開始
摘要
- 引入主題:在視頻分類領域,視頻Transformer最近作為一種有效的卷積網絡替代品出現。
- 現存問題:大多數以前的視頻Transformer採用全局時空注意或利用手動定義的策略來比較幀內和幀間的patch。這些固定注意力方案不僅計算成本高,而且通過比較預定位置的patch,忽略了視頻中的運動動力學。
- 解決方案:該論文介紹了可變形視頻Transformer(DVT),它根據運動信息動態預測每個查詢位置的一小部分視頻Patch,從而允許模型根據幀間的對應關係來決定在視頻中查看的位置。關鍵的是,這些基於運動的對應關係是從以壓縮格式存儲的視頻信息中以零成本獲得的。
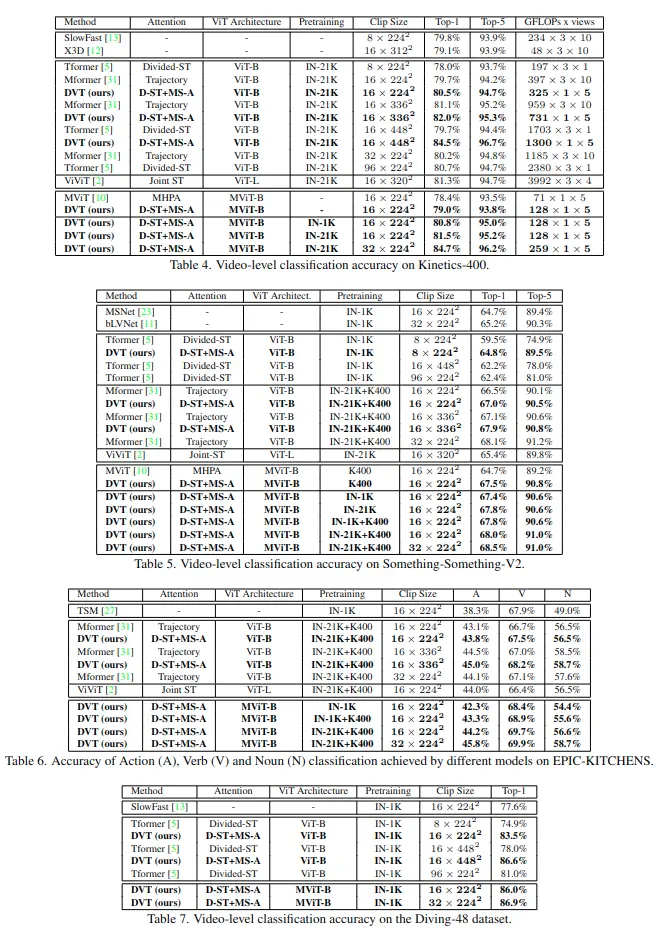
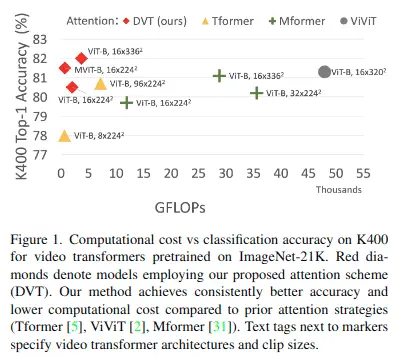
- 實驗結果:在四個大型視頻基準(Kinetics-400、Something-Something-V2、EPIC-KITCHENS和Diving-48)上的實驗表明,該論文模型在相同或更低的計算成本下實現了更高的精度,並在這四個數據集上獲得了最優結果。
算法
視頻TRANSFORMER
視頻數據的輸入大小一般可以表示為\( X\in R^{H×W×3×T} \) ,T表示幀數,3表示每一幀是RGB圖像
因為使用的是Transformer架構,所以首先需要將輸入數據轉換為一個\( S \cdot T \) tokens,S表示每一幀中的patch個數,每個token可以表示為\( x_s^t \in R^D \) 。整個過程可以表示如下:
- 將每一幀圖像進行非重疊分割,生成S個patch。
- 將每個patch投影到D個通道維度上。
- 添加空間位置編碼\( e_s \)和時間編碼\( e^t \)
最終得到\( z_s^t = x_s^t + e_s + e^t \)
然後通過多頭自注意力,layer norm(LN)和MLP計算,可以表示如下:
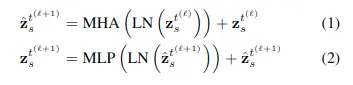
其中具體的自注意力可以表示如下(使用單頭進行簡化説明)

根據以往的視頻Transformer算法,自注意力機制可以分為Global space-time attention和Divided space-time attention
Global space-time attention
簡單來説就是將時空聯合起來進行注意力計算,公式如下:
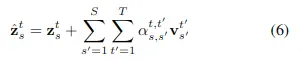
其中注意力權重計算公式如下:
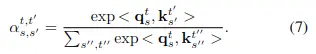
整個計算過程的計算複雜度為\( (S^2T^2) \),最大的問題就是計算量很大。
Divided space-time attention
顧名思義,就是將時間和空間的注意力進行分開計算,用來減少計算量
空間注意力計算公式如下:
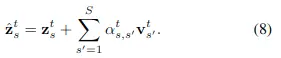
計算複雜度為\( O(S^2T) \)對應的時間注意力計算公式如下:
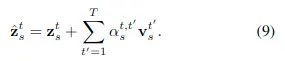
計算複雜度為\( O(ST^2) \)
需要注意的是,時間注意力只對不同時間幀上的同一個空間位置進行注意力計算!這就是其最大的問題,因為其沒有考慮到不同幀之間目標的運動。
可變形視頻TRANSFORMER
主要分為以下三個部分(創新點)
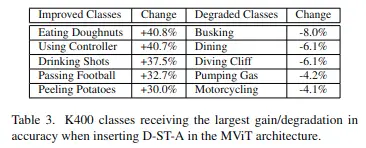
Deformable Space-time Attention(D-ST-A)
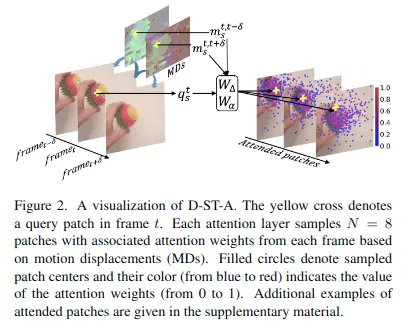
這個注意力機制和上文Divided space-time attention中的時間注意力機制很相似,但是有兩個主要不同點:
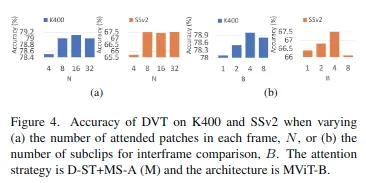
- 對於每個查詢\( q_s^t \) ,使用不同幀上的N個空間位置\( s(n)|n=1,… \)進行相似度計算,而不是一個固定位置,這雖然帶來相對較大的計算量,但會獲取更大空間上的特徵信息,性能會提高很多。文中使用N=8。
- 這N個位置是數據驅動的,而不是人為定義的,這在後面進行細説。
該注意力機制的數學表達式如下:

其中每一幀上的N個空間位置是如何計算的呢?
——是根據查詢點特徵和運動嵌入特徵經過投影生成的相對偏置計算的,公式如下:

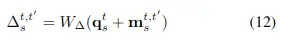
其中運動嵌入\( m_s^{t, t^\prime} \)是根據存儲在壓縮視頻中的運動位移和RGB residuals確定的,詳細步驟可以查看論文。
其中的相似度矩陣\( {\boldsymbol{\alpha}}_{s}^{t, t^{\prime}} \in R^N \)與之前的計算方式不同,而是根據查詢點特徵和運動嵌入特徵計算而來的,公式如下:

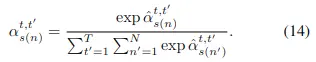
Deformable Multi-Scale Attention (D-MS-A)
上述D-ST-A是一個時間上的注意力機制,而D-MS-A是一個空間上的注意力機制,用於編碼同一幀上的注意力。
但對於每一幀圖像,這裏引入了多尺度注意力——計算F個不同分辨率下的空間信息,不同分辨率圖像中採樣\( N^\prime \)個patch進行注意力計算,多分辨率可以通過不同步長的3D卷積層來實現,數學表達式如下:
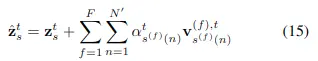
其中不同分辨率圖像中的patch採樣也是通過根據其中對應查詢點特徵計算偏置得到的,計算公式如下:
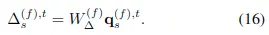
Attention Fusion
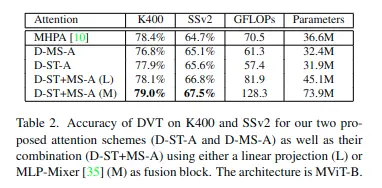
可以僅使用可變形時空注意(D-ST-A)、僅使用可變形多尺度注意(D-MS-A)以及兩者的組合(D-ST+MS-A)。
在最後一種情況下,將由這兩種注意策略獨立計算出的兩個token \( z_s^{ST^t} \)和\( z_s^{MS^t} \)饋送到一個注意力融合層u()進行信息融合,\( \mathbf{Z}_{s}^{t}=u\left(\mathbf{Z}_s^{S T^{t}}, \mathbf{Z}_s^{M S^{t}}\right) \)。
論文給出了兩種形式的注意力融合方式,一種基於簡單的線性投影,另一種基於MLP-Mixer模型。
實驗
在四個標準視頻分類基準上評估DVT:Kinetics-400(K400)、Something-Something-V2(SSv2)、EPIC-KITCHENS-100(EK100)和Diving-48(D48)
消融實驗
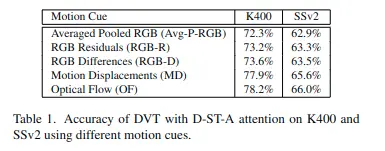
Choice of motion cues