

導讀:2025年是智能體爆發的一年。然而,隨着模型能力的提升,工業界開始反思:盲目增加智能體、盲目增加工具調用次數真的能“大力出奇跡”嗎?本文串聯了兩篇Google論文,從宏觀的架構選擇到微觀的工具預算感知,探討如何科學地構建高效的Agent系統。
Part 1. 宏觀選型:多智能體的科學定律
- Towards a Science of Scaling Agent Systems
最近在很多分享交流上對於究竟使用單智能體vs多智能體有很多不同的聲音。24年其實以多智能體架構為主,但是隨着模型能力的提升,不少論文發現,多智能體帶來的邊際收益在遞減,同時多智能體之間的溝通成本和信息碎片化,導致在部分任務上甚至不如單智能體的效果。
而Google這篇論文沒有停留在理論爭辯,而是通過嚴謹的控制變量實驗,揭示了架構選擇與任務特徵之間的深層數學關係。論文試圖回答:
- 影響智能體系統表現的決定性變量是什麼?
- 智能體間的“溝通”何時是蜜糖,何時是砒霜?
- 是否存在一個通用的“最優架構”?
實驗設計:解耦與控制
為了得出上述結論,作者設計了一個非常嚴謹的控制變量實驗。以下是其具體的實驗步驟:
步驟一:明確的Agentic任務範圍
論文明確剔除了所有非智能體任務,畢竟多智能體隱式帶來的Ensenble等推理效果很容易在HumanEval等任務上帶來提升。這裏智能體任務包含三個特點
- 多步和環境交互
- 基於部分觀測的反覆信息收集
- 基於反饋的策略優化
缺少以上條件的任務,其實都是在測試模型自身的推理能力,而非智能體在動態非確定環境性下工具調用和多步動態規劃能力。基於以上條件論文選擇了下面四個測試實驗
- Finance-Agent: 高可分解性,需多視角數據聚合。
- BrowseComp-Plus: 動態網頁瀏覽,具有高熵搜索空間 。
- PlanCraft: 基於《我的世界》GUI界面的合成數據集,包含時空數據的規劃任務,具有嚴格的序列依賴性。
- Workbench: 評估業務流程自動化,涉及確定的代碼執行和工具使用,例如發郵件、安排會議。
步驟二:梳理智能體架構分類
為了解耦“多智能體”這個概念,作者將其拆解為 5 種標準架構進行對比:
- SAS:單智能體架構
- MAS:多智能體架構,論文按照信息流動方式和結構分成以下幾類
- Independent:所有智能體之間沒有溝通,各幹各個的,等同於Ensemble模型
- Centralized:中心化模式,Cluade稱之為Orchestrator,主智能體負責規劃分發任務給子智能體並彙總信息,整個信息流動中存在主導者和信息瓶頸。
- DeCentralized:去中心化,所有智能體All to All通信,論文使用的是辯論模式,其實也有也有像圓桌討論、多角色討論等其他模式,只不過是智能體的角色和所站論點的差異。
- Hybrid:兼顧中心規劃和子智能體的橫向溝通的混合模式
更具體的不同智能體架構的交互深度、溝通複雜度如下
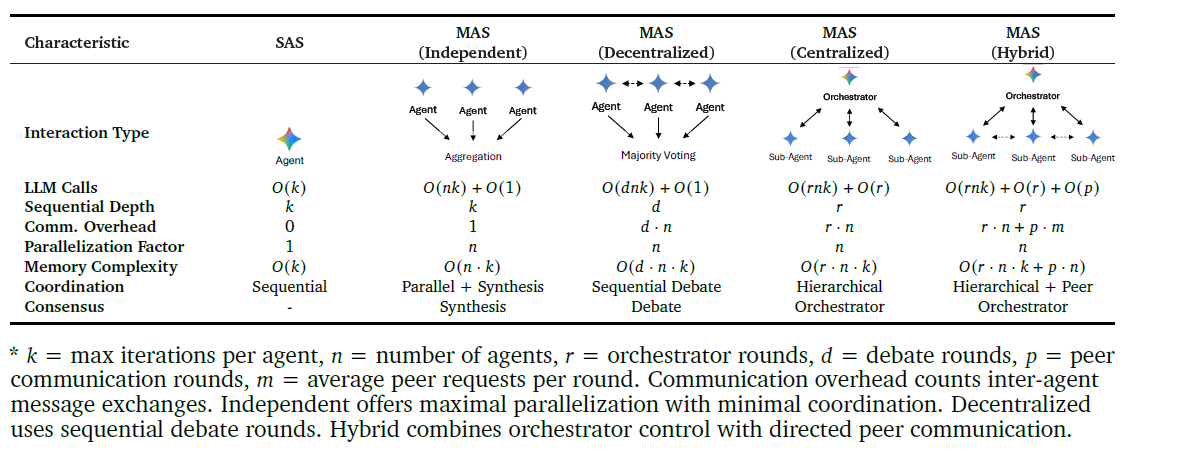
步驟三:變量控制
所有架構使用完全相同的工具、指令和任務描述,和相同的總推理Token預算。所以會存在MAS下子智能體越多,那每個子智能體分配到的輪次就更少。
實驗結論和分析
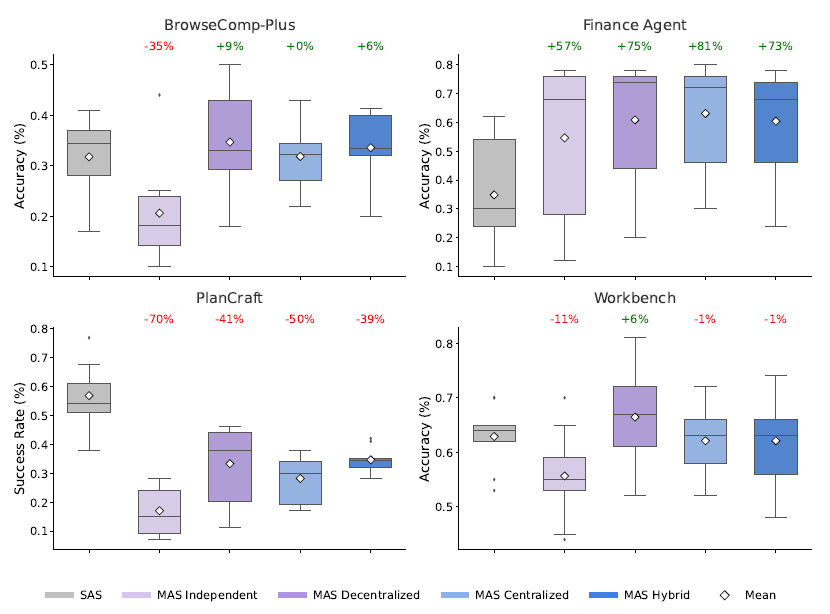
如上圖是不同智能體結構在不同任務上的實驗效果,實驗結果並未給出一個“萬能架構”,反而揭示了信息流結構(Information Flow Structure)才是決定架構優劣的根本。
多智能體收益高度依賴任務結構,不存在永遠最優的智能體架構
- 正收益: 在可分解、並行的任務上,例如需要多角度信息收集的Finance Agent任務上,MAS 表現出色,中心化架構(Centralized)比單體(SAS)提升了 80.9% 。
- 微收益: 在動態搜索任務(BrowseComp-Plus)上,去中心化架構僅帶來 9.2% 的提升 。
- 負收益: 在強序列依賴的規劃任務(PlanCraft)上,所有 MAS 架構都導致性能下降,降幅在 39% 到 70% 之間 。
為什麼多智能體在序列任務重失效?
作為算法工程師,我們需要透過現象看本質:這是Context Fragmentation(上下文碎片化)帶來的必然結果。
- 高可分解性任務:類比Finance Agent,以及單段落的大綱寫作等任務
這類任務的信息流特徵是正交且獨立,所以
\(P(task2|task1)\sim P(task2)\),也意味着子智能體之前幾乎無需溝通交流或者狀態同步,因此中心化結構能帶來併發效率提升,以及覆蓋更廣的搜索空間。
- 強序列依賴任務:類比PlanCraft,以及Coding等任務
這類任務的信息流特徵是馬爾科夫或者更長程的序列依賴,所以\(State_2=f(State_1, Action_1)\),意味着每個智能體都要能獲取前面智能體任務執行的全部輸出以及隱含假設,才能繼續執行。依賴全面完整的信息傳遞和大量的信息傳輸交流。而這正是SAS單智能體的模式
重要的Scaling法則
同時論文還嘗試進一步歸因除架構之外的其他影響因素,包括
-
工具-協作權衡(Tool-Coordination Trade-off): 這是一個強負相關因素 (\(\beta=-0.330\))。任務涉及的工具越多(Tool-heavy),多智能體的通信開銷(Overhead)就越嚴重,導致效率驟降。一個可能原因在於工具越多,複雜的tool schema會和複雜的協作指令搶奪模型有限的注意力空間(類似注意力搶佔在多輪對話vs工具調用中也能觀測到)。
-
能力飽和效應(Capability Saturation): 當單體 Agent 的基線準確率已經超過 45% 時,增加更多 Agent 反而會因為協調成本帶來負收益。因為高水平模型在同一任務上的一致性較高,而額外的溝通返回會引入語義漂移(類似傳話過程中的傳遞誤差)。除非是多智能體獨立查詢不同數據獨立完成任務,否則只是推理協作提升不大。(所以本質還是信息流動的問題)
-
架構相關的錯誤放大(Error Amplification): Independent架構會將錯誤放大 17.2倍(因為缺乏錯誤驗證機制),而中心化架構能顯著通過中心的規劃智能體作為verifier對所有子智能體的返回信息盡心驗證提升系統魯棒性。
所以整體上在智能體設計上幾個點很明確,第一明確你任務的信息流結構、再評估單智能體的效果、最後評估你工具的複雜度再考慮使用什麼類型的多智能體結構。
Part 2. 微觀執行:單智能體的預算感知
- Budget aware Tool-USE Effective Agent Scaling
聊完多智能體選型,接下來我們看下如何最大化單智能體在有限工具調用下的執行效果。論文揭示了實際應用中的一個現實問題,既我們不會無限等待模型去循環往復的調用工具,我們依舊是在追尋效率和效果的帕累托最優。
那Agent執行,本質就變成了一個條件優化問題,如何在有限的工具調用次數下,最大化智能體的執行效果。
2.1 核心痛點:盲目的Hard Stop
現有Agent框架通常設置 max_steps(iteration)=XX 作為兜底,來強制截斷模型超長的工具調用鏈路,但 Agent 本身不知道自己還剩多少次機會。這也導致簡單的增加 step 限制並不能線性提升效果,因為 Agent 不知道自己“錢(Budget)”還剩多少,在實際任務執行時我們往往觀測到兩種失敗模式
- Agent過早放棄沒有收集到完整信息
- Agent在錯誤,或者很難成功的道路上反覆嘗試導致資源耗盡
2.2 解決方案Level1 - 顯式感知
作者提出的 BATS (Budget Aware Test-time Scaling) 框架,本質上是在 Prompt Engineering 和控制流層面引入了模型可感知的預算條件約束。
指令如下,論文在Prompt中動態加入了工具調用Budget,在每輪模型進行工具調用時,顯式告知模型,當前可用的工具調用次數,以及針對不同的預算剩餘,模型應該如何動態調整自己的工具調用策略。
## Budget
You have two independent budgets:
- Query Budget (for search)
- URL Budget (for browse)
Each string in 'query' or 'url' consumes 1 unit respectively.
After each <tool_response>, a <budget> tag shows remaining units.
You must ADAPT your strategy dynamically to the current budget state.
### HIGH Budget (>=70% remaining)
- Search: 3-5 diverse queries in one batch.
- Browse: up to 2-3 high-value URLs.
- Goal: Broad exploration, build context fast.
### MEDIUM Budget (30%-70%)
- Search: 2-3 precise, refined queries per cycle.
- Browse: 1-2 URLs that close key knowledge gaps.
- Goal: Converge; eliminate uncertainty efficiently.
### LOW Budget (10%-30%)
- Search: 1 tightly focused query.
- Browse: at most 1 most promising URL.
- Goal: Verify a single critical fact or finalize answer.
### CRITICAL (<10% remaining or 0 in one budget)
- Avoid using the depleted tool.
- Only perform 1 minimal-cost query or browse if absolutely essential.
- If uncertainty remains and no tool use is possible, output <answer>None</answer>.
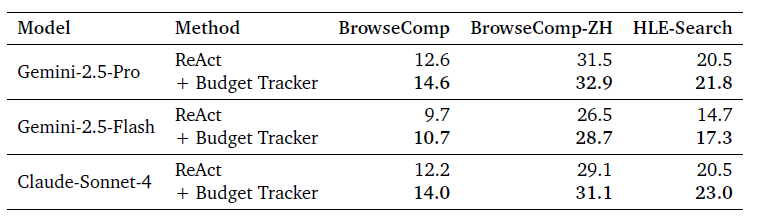
論文使用多個模型,在多個任務上對比了單純使用ReACT,和加入Budget的ReACT的效果。
-
相同預算下,Budget Tracker可以實現更高的任務完成準確率
![image]()
-
相同的準確率下,Budget Tracker的工具調用輪次更低
![image]()
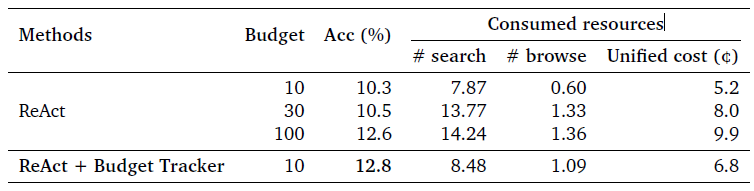
-
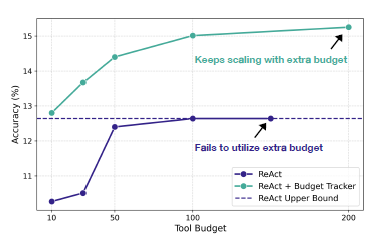
加入Budget Tracker後,提升工具調用次數可以更加持續地帶來效果提升。換言之引入Budget Tracker可以提升智能體在單任務的執行上限。
![image]()
解決方案Level2 - 策略使用
Budget Tracker只是第一步,它負責“報賬”讓模型瞭解自己還有多少次機會,剩餘全靠模型自己發揮,而再進一步我們可以系統告知模型如何利用這筆預算來規劃複雜路徑,包括如何優化Planning和Verification的效果。
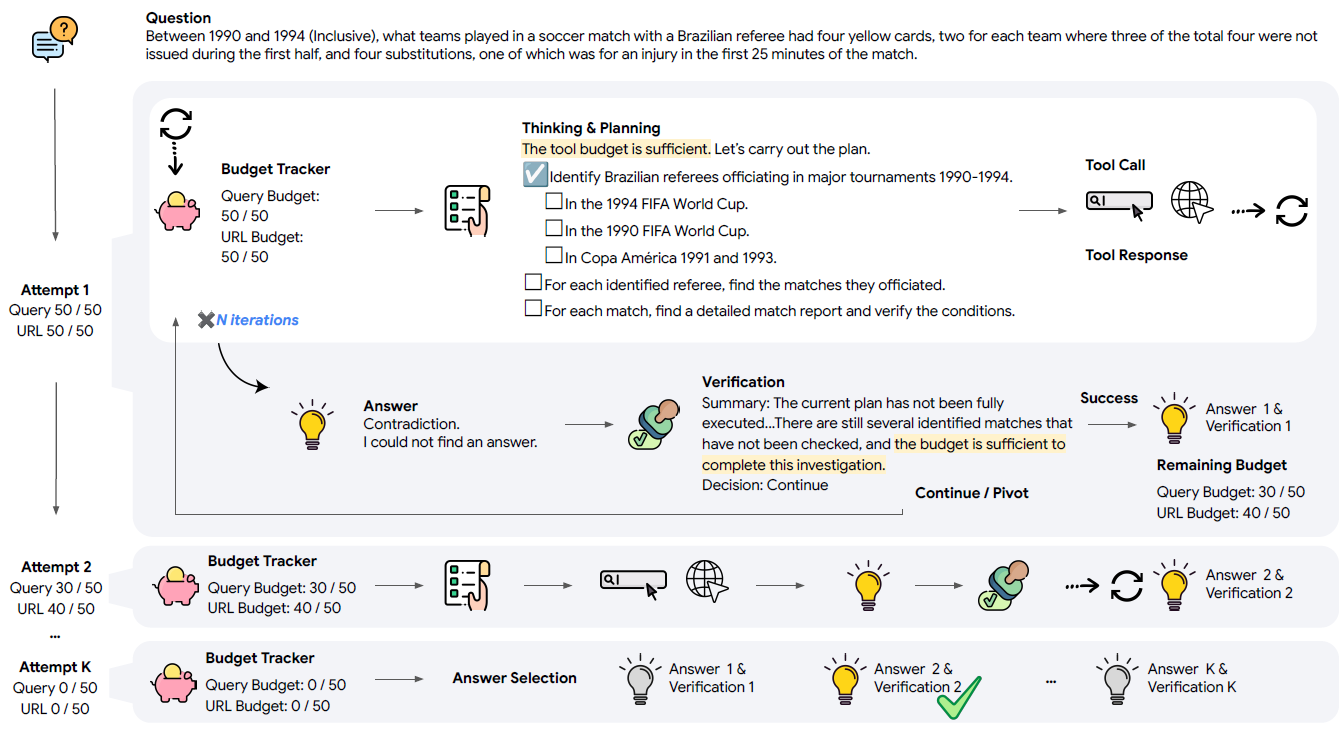
論文選用的智能體架構,是兩個單線程的智能體,第一個智能體Planner負責規劃,並根據規劃步驟逐步調用工具回答並給出答案, 第二個整體Verification負責對第一個智能體給出的答案進行校驗,並判斷是否需要答案已經合格,後者需要深入挖掘、或者更換搜索方向。
我們就單看下和Plan模塊的結合,Budget預算對這個模塊的影響包括
- Exploration: 預算決定了搜索樹的寬度。預算足 \(\rightarrow\) 制定多分支探索計劃;預算緊 \(\rightarrow\) 制定單點驗證計劃
- Verification:預算決定了回溯的深度。預算足 \(\rightarrow\) 深入挖掘;預算緊 \(\rightarrow\) 立刻轉換方向或者直接輸出答案
具體規劃相關的指令如下:
## About questions
Questions contain two types of constraints: exploration and verification.
* Exploration: Broad, core requirements (e.g., birthday, profession). Use these for initial
searches to surface candidates. You may combine 1-2 to form stronger queries.
* Verification: Narrow, specific details. Apply these only after you have candidates, to
confirm or filter them. Never begin with verification constraints.
Start with exploration queries, then use verification to validate the results.
## About planning
Maintain a tree-structured checklist of actionable steps (each may require several tool calls).
- Mark each step with its status: [ ] pending, [x] done, [!] failed, [~] partial.
- Use numbered branches (1.1, 1.2) to represent alternative paths or candidate leads.
- Log resource usage after execution: (Query=#, URL=#).
- Keep all executed steps, never delete them, retain history to avoid repeats.
- Update dynamically as you reason and gather info, adding or revising steps as needed.
- Always consider current and remaining budget when updating the plan.
引入以上指令和Budget Tracker後,會觀測到模型在不同預算前提下做出的如下行為改變。
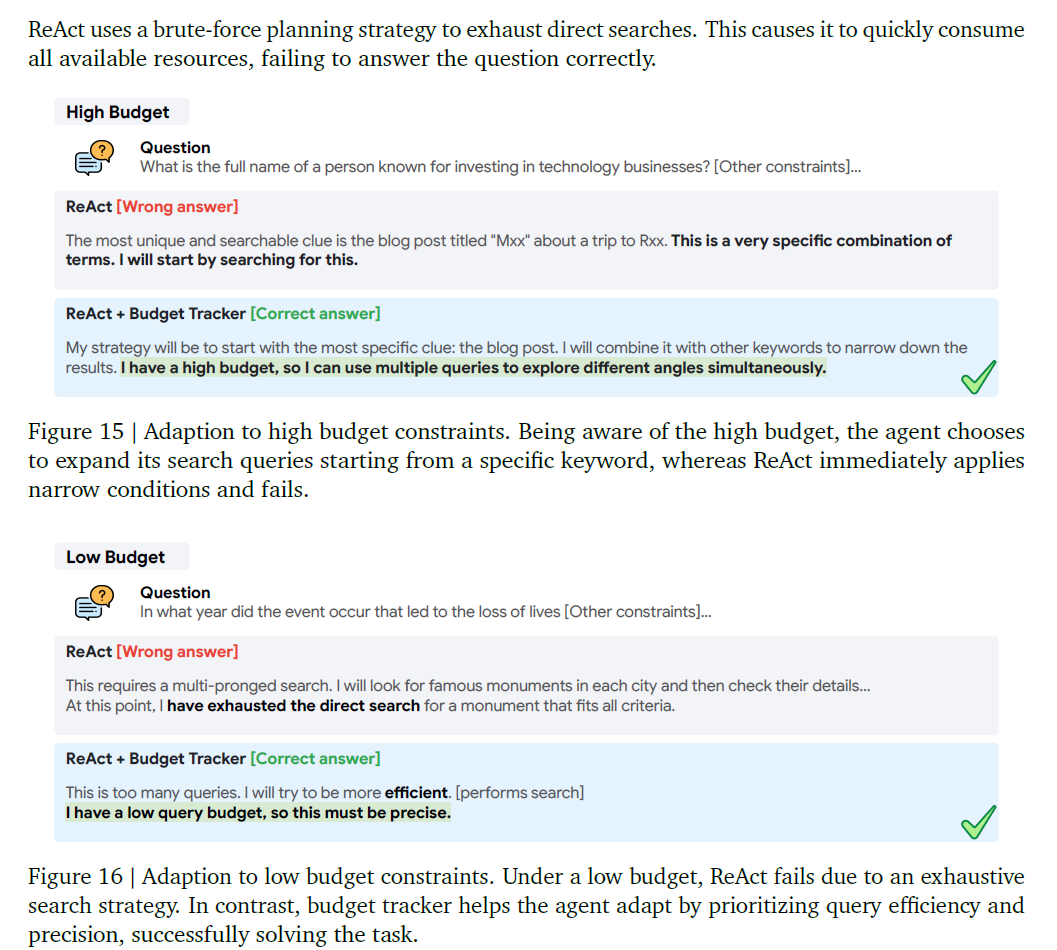
再進一步感覺可以把不同Latency要求場景中,對於模型儘量快執行完成、或者儘量更全收集信息等差異化約束條件,以及不同工具在不同場景的使用優先級打分等都作為模型可以動態感知信息注入到模型上文中,把當前RL Agent訓練的思路都顯式注入到推理上文中,是個值得嘗試的思路。
想看更全的大模型論文·微調預訓練數據·開源框架·AIGC應用 >> DecryPrompt
2025年最後一天了,嘮2塊錢的,高燒已經燒了三天燒的一時不知今夕是何夕,似乎每次項目一上線,人一泄勁免疫力就跟着出走,睜眼一看已經是31號了,趁着早上燒還沒起來抓緊把年底最後一篇博客傳了。
2026年祝自己和爸爸媽媽都身體賁棒,吃嘛嘛香,也祝大家明年都健健康康,無病無災,今年就許了這一個願望,希望會成真哦~