

藉着 DeepSeek-OCR這篇論文,本章我們來回顧下多模態大模型(VLM)的核心技術演進。
很多人認為:圖像Token的信息密度和效率遠不如文本。但 DeepSeek-OCR的核心價值,就是用實踐證明了這是一個偽命題。它通過一套巧妙的串行視覺壓縮架構,實現1個視覺Token近乎無損地承載10個文本Token的驚人效率。
下面我們沿着 \(O(N^2)\) 危機 \(\rightarrow\) 結構感知 \(\rightarrow\) 語義對齊 的路徑,來梳理這背後的技術基石。
Part I:多模態基石的構建與 \(O(N^2)\) 危機
我們先來回顧下多模態模型的技術基石,我們將按照模型結構->多模態對齊->指令生成這條路徑進行深入。
ViT: 圖像的 BERT 化與 \(O(N^2)\) 的起點
- Google: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
💡 ViT的本質像是圖像領域的Bert,只不過把文字token轉換成了圖像的像素塊。在ViT出現之前,圖像領域清一色使用CNN、ResNET,強調各種圖片特徵提取例如平移不變性,局部特徵等等。但是ViT的出現,再一次證明大力出奇跡,只要數據量足夠大,簡單的Transformer Encoder勝過一切。
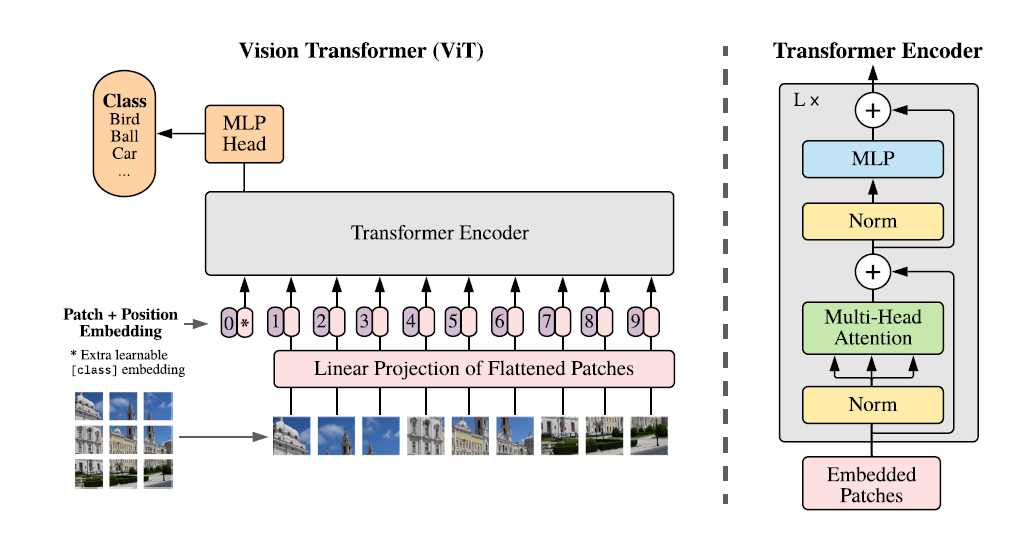
如果我們通過和NLP Transformer類比來認識ViT的話,整個模型結構會分成以下幾個部分
-
Tokenization
在文本中,句子被tokenize成token,作為模型的輸入。在圖像中,一個Height * Width * Channel大小的圖像,會被分割成固定大小1616的像素塊(Patch)。如果圖片的長寬是224224,則模型的輸入會有224224/(1616)=196個像素塊。 -
輸入層
ViT的輸入層包含兩個部分
- Patch Embedding:因為圖像不像文本有可枚舉的token,因此無法使用詞典向量進行映射,所以ViT選擇通過線性映射層(MLP)來把patch映射到固定的維度D。
- Positional Encoding:和NLP相同,為了保留位置信息,ViT加入了1D的position embedding(2D經試驗沒有效果提升,因為大量數據會讓模型在一維關係中學習到空間特徵)
- Class Head:和BERT相同,ViT也加入了一個可學習的全局token,用於表徵圖片的整體信息。
-
中間層
中間層就是傳統的Transformer結構了,通過交替的多頭注意力,MLP線性映射層和LayerNorm歸一化層。 -
訓練策略
考慮論文本身就是為了證明訓練數據的Scaling戰勝一切,因此在訓練策略上也做了很相近的消融策略,包括
- 數據量試驗:在Image-Net這種1M左右的小數據上效果弱於ResNet,但是當在300M+的數據上進行訓練時,效果全面超越CNN
- 分辨率試驗:在低分辨率預訓練,在高分辨率微調。其實和現在長上文的NLP模型訓練思路一致,在預訓練輸出長度較短,在post-train階段在漸進式增長。
- 位置編碼實驗:為了適配上面分辨率增長的問題,ViT在固定位置便馬上進行差值
- 訓練超參:使用Adam,低正則參數(數據量足夠大很少過擬合)
VIT在後面任務中面臨最大的問題就是\(O(N^2)\)的視覺token膨脹,隨着輸入圖片分辨率的變大,當輸入1024*1024高分辨率圖片時,輸入token數將高達4096。
VIT-DET:解決\(O(N^2)\)的局部注意力方案
- Meta: Exploring plain vision transformer backbones for object detection
💡 ViTDet 解決了 Plain ViT 無法用於高分辨率密集預測(如檢測、分割、OCR)的痛點,其解決方案與 NLP 領域的 Longformer 思路高度相似:局部窗口 Attention + 稀疏全局連接。
-
窗口注意力機制
將高分辨率圖像劃分成14 *14或者16 * 16的塊,內部進行Attention,這樣不論輸入的圖像像素如何變化,在Self-Attention層的計算複雜度都是恆定不會變化的。這樣每個圖像patch只關注它所在窗口內的相鄰patch。這也是後面DeepSeek-OCR能處理高分辨率圖像的技術基礎。 -
稀疏全局 Attention 層
那局部Attention肯定要配合全局Attention能力,才能讓block之間的信息互通。VIT-DET在網絡中插入了4個標準的全局Attention層,例如如果整個VIT有24層,則每6層插入一個全局層,這樣保證全局信息交互只在有限層進行,用於在保證顯存和計算成本可控的前提下,兼顧全局信息的共享。
Segment Anything Model:圖像分割領域的 GPT-3
- Meta:Segment Anything
- Meta: Exploring Plain Vision Transformer Backbones for Object Detection
💡 SAM是一個支持Prompt Engineering的生成式模型,但生成的不是token而是mask。它引入了promptable segmentation任務,給模型一個提示(點、框、文本),模型負責切割對應的物體。為DeepSeek-OCR提供了感知圖片結構和幾何的模型基礎。

如上圖所示,SAM模型包含三個組成部分
- Image Encoder:使用MAE預訓練的VIT模型,作為強大的特徵提取器提取每張圖片的Embedding。MAE類似NLP裏面BERT的訓練方式,BERT是完形填空,MAE是遮掩部分圖片進行重構還原。
- Prompt Encoder:這裏的圖像分割指令有兩種
- Sparse:包含points(用户點中了圖像中的某個物體)和boxes(用户框柱了圖像的一個矩形區域)。分別用單個座標和左上右下兩個座標點,使用可訓練的位置編碼表徵。
- Dense:文本描述,例如一把黑色的剪刀。使用預訓練CLIP的Text Encodier
- Mask Decoder:輕量的Transformer Decoder,簡單解釋Image Embedding就是Key/Value, Prompt Embedding是Query,通過cross-Attention去圖像裏面撈出對應的像素區域,使用輸出頭在整個圖片上進行分類預測,預測每個位置是否應該被Mask。
同時為了解決Prompt Ambiguity的問題,例如如果用户點擊了T恤,那用户究竟是想分割人?還是想分割T恤?論文提出了同時預測3個MASK的方案,同時預測多個可能的分割掩碼結果,並用模型置信度打分選擇最優可能的一個進訓練,類似NLP模型的Beam-Search。
CLIP:視覺與文本的“羅塞塔石碑”
- OpenAI: Learning Transferable Visual Models From Natural Language Supervision
💡 CLIP本質就是一個Dual-Encoder對齊模型,可以類比NLP領域的SimCSE。通過InfoNCE Loss進行大規模對比學習,把文本和圖像映射到同一個向量空間。被當前多模態太模型提供了核心的模態對齊能力。
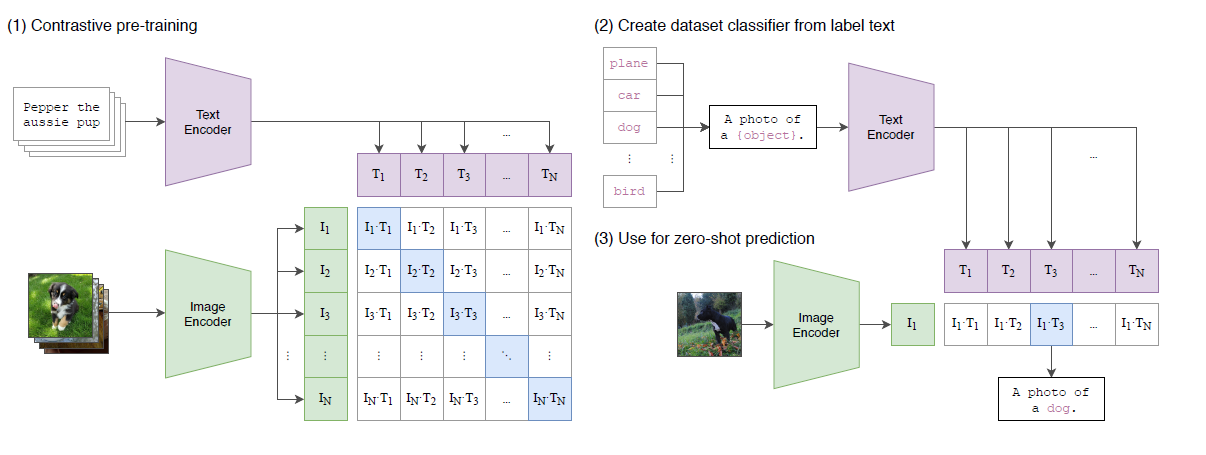
感覺直接看qseudo code比看圖來的更清晰,整個CLIP的訓練過程如下
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
- 多模態映射: 選取對應模態的預訓練模型來對不同模態的輸入進行特徵提取
- Text encoder: CBOW或者Bert,N*I -> N * L * D
- image encoder:ViT或者Resnet, NHW*C -> N * L * D
- 再通過線性投影層,把不同模態的向量維度映射到相同的維度空間
- 對比訓練
訓練策略是通過Batch Contrastive Loss進行的,每個樣本都有圖片和對應的文字描述構成,因此一個batch內文本表徵和圖片表徵的叉乘矩陣,應該只有對角線的相似度最高為正樣本,其餘都為負樣本。
之所以選擇InfoNCE,而非傳統的Image Caption預測,因為論文發現這種訓練方式模型收斂很慢,畢竟一個圖片其實有無數種語言的描述方案,只讓模型精準預測其中一種描述本身就不合理。而直接對齊高維向量表徵的訓練效率顯著更高
- 樣本構建
圖片和對應的文字描述樣本集總共4億條,為了保證圖片概念的覆蓋率,論文采用了搜索進行構建,先構建query集,再通過搜索構建(image,text) pair對。
- 模型使用
使用以上對比訓練得到的圖像和文本Encoder,可以在兩個領域之間進行零樣本的知識遷移,類比GPT3水平的zero-shot,可以通過提示詞“Transfer English to French”實現指令理解。CLIP訓練過的圖文Encoder同樣可以,例如你要對象進行分類,只需要把1000個標籤填入“A photo of {label}”,然後用Text Encoder進行編碼,再計算和圖像Encoder相似度最高的文本向量,就是該圖片的分類了。
CLIP不僅為圖像和文本模態對齊提供了思路,同時也是較早關注圖像領域zero-shot開放域遷移的。
Part II:DeepSeek-OCR 的核心貢獻:光學壓縮秘籍
- DeepSeek-OCR: Contexts Optical Compression
DeepSeek-OCR的核心亮點在於它提出了一個革命性的觀點:通過高分辨率圖像渲染 + 專用壓縮架構,可以將長文本內容壓縮成數量更少的視覺 Token,從而為LLM 的長上下文難題提供新的壓縮思路。
OCR其實只是一個實驗場景,論文核心要回答的是“一張包含 1000 個單詞的圖片,到底最少需要多少個 Visual Token 才能讓 LLM 完美還原出這 1000 個詞?”
串行壓縮的 DeepEncoder 架構
DeepSeek-OCR 的 DeepEncoder 僅有 380M 參數,但通過巧妙的串行(Serial)結構,完美平衡了“高分辨率”與“低 Token 數”的需求。
- 80M SAM預訓練VIT-DET
通過window-Attention,能在高分辨率圖像下保持相對較低的顯存佔用,負責圖片核心的結構特徵提取。
- 兩層16*16CNN Compressor
用於對SAM輸出的圖像特徵進一步降採樣,降低激活率,是DeepSeek-OCR高保真,極高壓縮率的核心。
- 300M CLIP預訓練VIT-Large
移除了首層的Embedding層,因為輸入從圖片變成了CNN降採樣後的圖像向量,採用全局注意力機制,對CNN降採樣後的視覺Token進行全局語義的整合。
雖然都是VIT模型結構,但DeepSeek-OCR的組合方式大有學問。前面我們提到SAM本身的訓練目標是邊緣檢測,因此預訓練後的模型對於幾何結構、筆畫邊界、佈局線條有更強的捕捉能力,所以使用SAM預訓練模型作為OCR的特徵提取器再合適不過。而使用CLIP作為後端,接受經過壓縮的視覺特徵自然是使用CLIP本身和文本語義對齊的特性,把SAM提取的結構特徵,站在全局視角翻譯成包含語音信息Latent Tokens,用於後續解碼器的解碼。
用SAM“看清”,用CLIP“看懂”之後,最後就到解碼器“講給我聽”,論文使用了DeepSeek-3B-MOE,總參數是3B,但推理時每個token只激活64個專家中的6個,對應570M左右的參數。之所以選擇MOE,也是充分考慮到OCR任務本身的多元性,涉及到多語音、多符號(公式、圖表)、多排版,而MOE可以根據輸入的不同,選擇不同的專家進行解碼。
而之所以沒有像Qwen使用位置編碼,因為DeepSeek-OCR還是個單任務模型,因此只需要模型在訓練過程中學習和原圖圖像token信息一一對應的文本token信息,那SAM的局部信息提取,加上從左到右,從上到下固定的token拼接順序,再配合CLIP的全局語義理解(這是一個三欄排列還是個單欄報紙),其實就完全足夠了。
動態分辨率
為了適配不同的下游圖片尺寸,DeepSeek-OCR對於動態多分辨率設計了兩種方案。這裏借鑑了InternVL1.5提出的tiling思路。
- Native Resolution
論文預定義了四種分辨率Tiny(512),Small(640), Base(1024), Large(1280)。輸入圖片會保持原有的長寬比,把短邊padding到最近的分辨率。
- Gundam Mode
主要針對超高分辨率的長圖(例如報紙,在我的場景中是收集拍照或截圖的長圖)。這時會採用多分辨率組圖,類似NLP中的chunking邏輯。包括
- Global View:把全圖reszie到1024 * 1024,提供全局上下文
- Local View:將大圖切分成多個640*640的圖片快,提供局部視野。這裏使用了InternVL提供的tiling方案。
這樣通過Gloabl+Local的方案,讓模型既能獲取全局排版,也能看清局部小字。
模型訓練
DeepSeek-OCR收集處理了海量的相關語料,大致涵蓋以下三個方向
- OCR 1.0: 30M的PDF文檔,有直接用pymuPDF提取的粗標樣本,也有用MinerU、GOT-OCR精標的樣本,還有用word反向構建的合成數據來保證公式與表格的準確。注意這裏不同質量的樣本在訓練時會配合使用不同的指令來實現帶噪學習。
- OCR 2.0: 主要覆蓋圖表、公式、化學方程式等結構化數據。其中包括使用image-to-HTML構建得到的數據。
- 通用文本和圖像:保證Decoder和CLIP Encoder的通用文本和圖像能力的災難性遺忘
使用以上數據論文進行了兩階段的模型訓練
- DeepEncoder預熱訓練:讓編碼器輸出高質量圖像Token,有點類似先訓練embedding層
- Encoder+Decoder聯合訓練:把Encoder模塊中的SAM和Compressor參數都凍結,只保留CLIP可訓練用於和Decoder的文本表徵進行對齊。
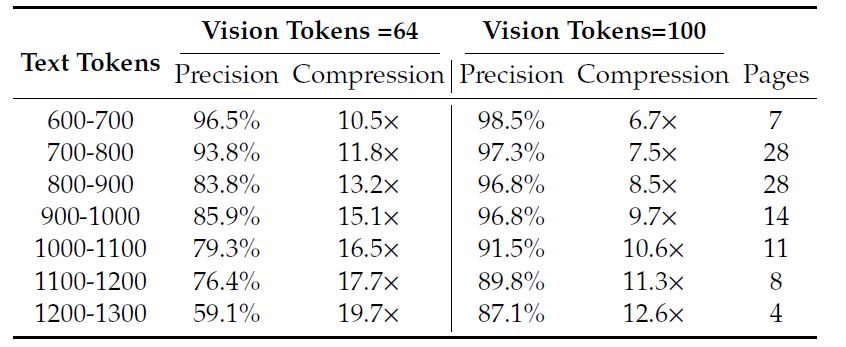
核心發現:上下文光學壓縮的 Scaling Law
通過在 OCR 任務上的實驗,DeepSeek-OCR 得到了關於視覺信息密度最關鍵的結論,為 LLM 的長期記憶和遺忘機制提供了新的理論依據。
- 10*無損壓縮,既當文本token/視覺token<10,COR的解碼精準度可以保持在97%+。
- 20*優雅遺忘,既當文本token/視覺token=20,OCR的解碼準確率仍有60%沒有完全遺忘。
第一個結論其實是反常識的,之前普遍認為圖像token的信息密度更低,但其實這是對不同體裁圖片的差異化認知導致的。而論文論證在當前的文本tokenizer的效果上,視覺模態可以成文文本模態的超級壓縮格式。
而第二個結論其實和超長上文的記憶壓縮機制相契合,對於超長文檔的問答,是有可能通過圖像token進行信息壓縮,只保留核心語義信息。
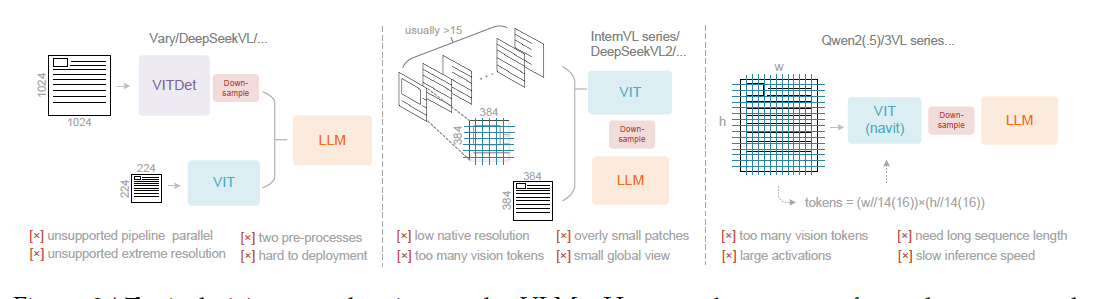
Part III:橫向對比:多模態 VLM 的不同路線
- Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
- Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.
- InterVL 1.5: How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
最後,我們通過一張表,清晰地對比 DeepSeek-OCR 與其他主流 VLLM 在處理高分辨率和 Token 效率上的技術路線差異。
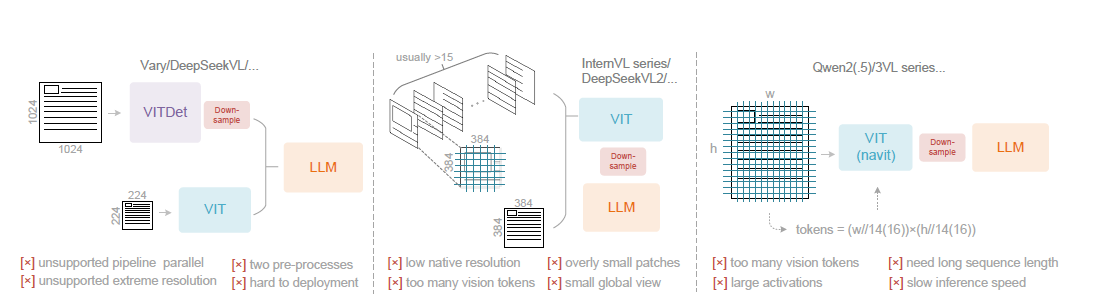
| 模型 | 核心 Token 策略 | 架構拓撲 | 關鍵技術 | 優勢與劣勢 | 借鑑 |
|---|---|---|---|---|---|
| DeepSeek-OCR | 串行壓縮 (Token Deflation) | SAM → Conv → CLIP ViT → LLM | ViTDet (Window Attn) + 16x Conv Compressor | 優勢:Token壓縮率最高,推理效率最高;在文檔領域實現 1:10 無損壓縮。 | |
| Qwen2-VL | 線性增長 (Token Inflation) | ViT → Pooling → LLM | Naive Dynamic Resolution + M-RoPE (3D 位置編碼) | 優勢:保真度高,位置感知優秀;
劣勢:Token 數量隨分辨率線性增長,推理昂貴。 |
不用通用位置編碼而藉助物理壓縮 |
| InternVL2 | Tiling | InternViT (6B) → QLLaMA (8B) → LLM | 巨型 ViT Encoder + LLaMA-based Adapter | 優勢:視覺基座能力強;
劣勢:整體參數量巨大,輸入VIT分辨率低導致圖像分割碎片化,token數過高、推理成本極高。 |
借鑑tiling |
| Vary | 並行詞表擴充 | CLIP、SAM+Conv → Concat Fusion → LLM | SAM-based Tiny Vocabulary + Parallel Dual-Branch | 優勢:增強文檔理解;
劣勢:並行結構顯存佔用大,Token 數量是兩者之和,計算冗餘。 |
借鑑Conv壓縮,把Vary並行架構改為串行 |