

💡 文章摘要 Anthropic SKILLS 看着只是一堆提示詞和腳本,但其精妙在於“大道至簡”。本文將深入解構 SKILLS 的三層分層加載架構,探討它如何解決傳統 Agent 上下文膨脹、領域任務成功率低的核心痛點。我們將通過一個完整流程展示 SKILLS 如何工作,並延伸思考它對現有 MCP、工作流和多智能體範式帶來的衝擊與重構可能。同時,我們也會探討 SKILLS 在工程實踐中面臨的挑戰,如性能、安全和評估。
🎯SKILL是什麼?三層拆解看本質
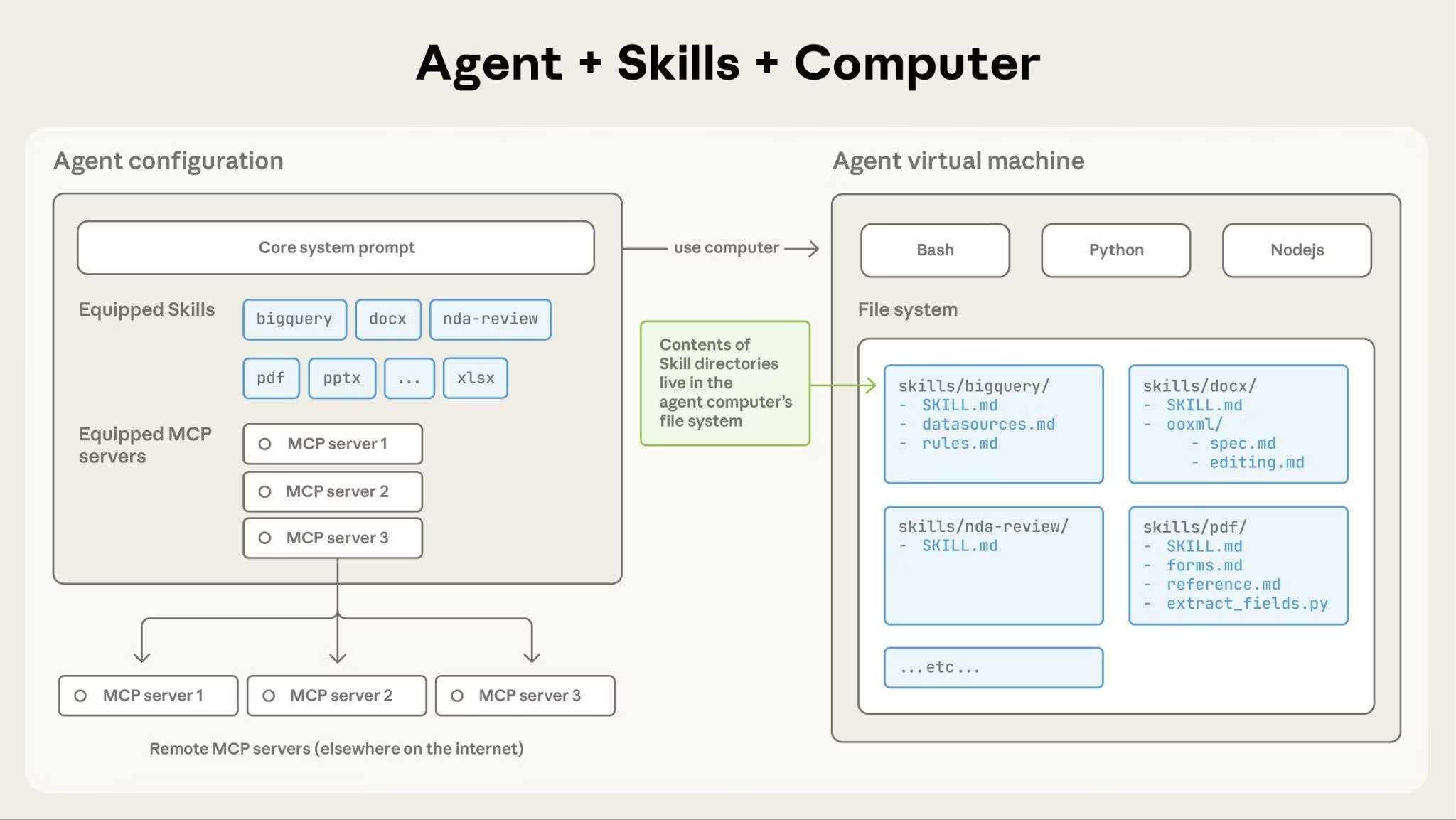
從表面看,一個Skill非常簡單:它就是一個文件夾。
這個文件夾裏通常包含:
- SKILL.md(必備):一個Markdown文件。這是Skill的“説明書”或“SOP”。它用自然語言告訴Claude“如何一步步完成某個特定任務”。
- SKILL中包含元數據,告訴模型這個説明書是完成什麼任務用的,如下
--- name: pdf-processing description: 提取PDF文本和表格,填寫表單...當用户提到PDF時使用。 ---
- SKILL中包含元數據,告訴模型這個説明書是完成什麼任務用的,如下
- 彈藥庫(可選):
- 腳本(scripts/):例如
fill_form.py,是可執行代碼,用於處理LLM不擅長或無法完成的確定性任務。 - 其他文檔(.md, .txt):例如
API_REFERENCE.md或BRAND_GUIDELINES.md。這些是更深入的“參考資料”,支持模型按需讀取。 - 模板(templates/):例如
company_report.pptx、viewer.html是模型完成特定任務的模版。
- 腳本(scripts/):例如
從技術本質來看,SKILLS 的核心創新在於其分層加載機制
┌─────────────────────────────────────────┐
│ Level 1: 元數據(啓動時加載) │
│ name + description (~100 tokens) │
│ ✓ 輕量級發現機制 │
└─────────────────────────────────────────┘
↓ 觸發時才讀取
┌─────────────────────────────────────────┐
│ Level 2: 主指令(SKILL.md body) │
│ 工作流、最佳實踐 (<5k tokens) │
│ ✓ 按需加載到上下文 │
└─────────────────────────────────────────┘
↓ 引用時才訪問
┌─────────────────────────────────────────┐
│ Level 3: 資源與腳本 │
│ • 額外 markdown(指令) │
│ • Python腳本(可執行直接執行) │
│ • 參考資料(schema、模板) │
│ ✓ 無限量存儲,零上下文開銷,固定執行效果 │
└─────────────────────────────────────────┘
🔧SKILLS 解決了哪些痛點?
理解了 SKILLS 的分層設計,它所針對的傳統 Agent 框架痛點就非常清晰了。SKILLS 主要解決了傳統 Agent 框架的以下痛點:
- 智能體上下文無限膨脹:
讓我們以金融數據查詢智能體為例,它的上下文主要來自幾個方面
- 核心指令:如何查宏觀數據、個股基本面、技術面...
- 海量資料:超級多的表描述和字段描述。
- 後續操作:如何建模、如何可視化...
在原始的智能體框架下,還沒開始任務,上下文就可能“幾萬字”了。
而在SKILL的加持下,我們可以把每一類數據查詢邏輯封裝成一個SKILLS,例如宏觀數據查詢.md。這樣在最初的system prompt,我們主需要加載有哪些SKILLS的元數據。當用户提問涉及到宏觀數據時,再把對應SKILL.md加載到上下文中。當需要具體查詢貨幣政的時候再進一步讀取細分參考材料reference/monetary_policy.md 。
腳本化的本質是將確定性任務從 LLM 推理中剝離。
這一點在處理數據時尤其明顯。如果 Agent 要把上一步返回的 CPI 時間序列數據可視化,傳統做法是把冗長的數據 作為文本 傳遞給下一個繪圖工具(例如 Echart),這個“Copy”過程會消耗海量 Token。
而 SKILLS 提供了 scripts 方案:代碼化 + 文件化。數據通過文件 (cpi.csv) 傳遞,模型只需推理出一行調用指令,如 python ts_visualize.py --file cpi.csv。整個可視化或建模過程幾乎不佔用模型上下文。
- 領域任務完成成功率低
領域任務完成率低一般來自兩個方面
- 領域數據在整體訓練中的頻率更低,模型訓練的不充分
- 領域本身有大量主觀流程和“專家經驗”(哈哈,專家們總覺得自己那套最棒)。
SKILLS 通過標準化工作流程(SOP)有效提升領域任務完成率。
這兩種情形都可以通過SKILLS提供工作流程説明來提升任務完成效果。但其實在使用時需要注意粒度和任務特性。SKILLS這裏提供的其實就是類似前面Memory中我們提到的“Procedural Knowledge”程序性知識,告訴模型當你遇到X情況的時候,第一步做A,第二步做B。
而和領域的契合點在於,公司可以把固有的SOP(如銷售物料如何寫、個股基本面如何分析)固化到 SKILLS 中。
- 固定流程任務完成穩定性低
對於極致“一致性”要求的任務,不能依賴模型100%的指令遵從,這時scripts的價值就凸顯了:
讓我們來舉兩個例子
- 對於投研報告的生成:個股基本面分析的標準指標計算固化為腳本
- 對於營銷物料的設計:公司配色和風格通過template固化
腳本提供了無論執行多少次都相同的結果,這才是穩定性的終極保障。
🤖 如何工作?Agent完整的“內心戲”
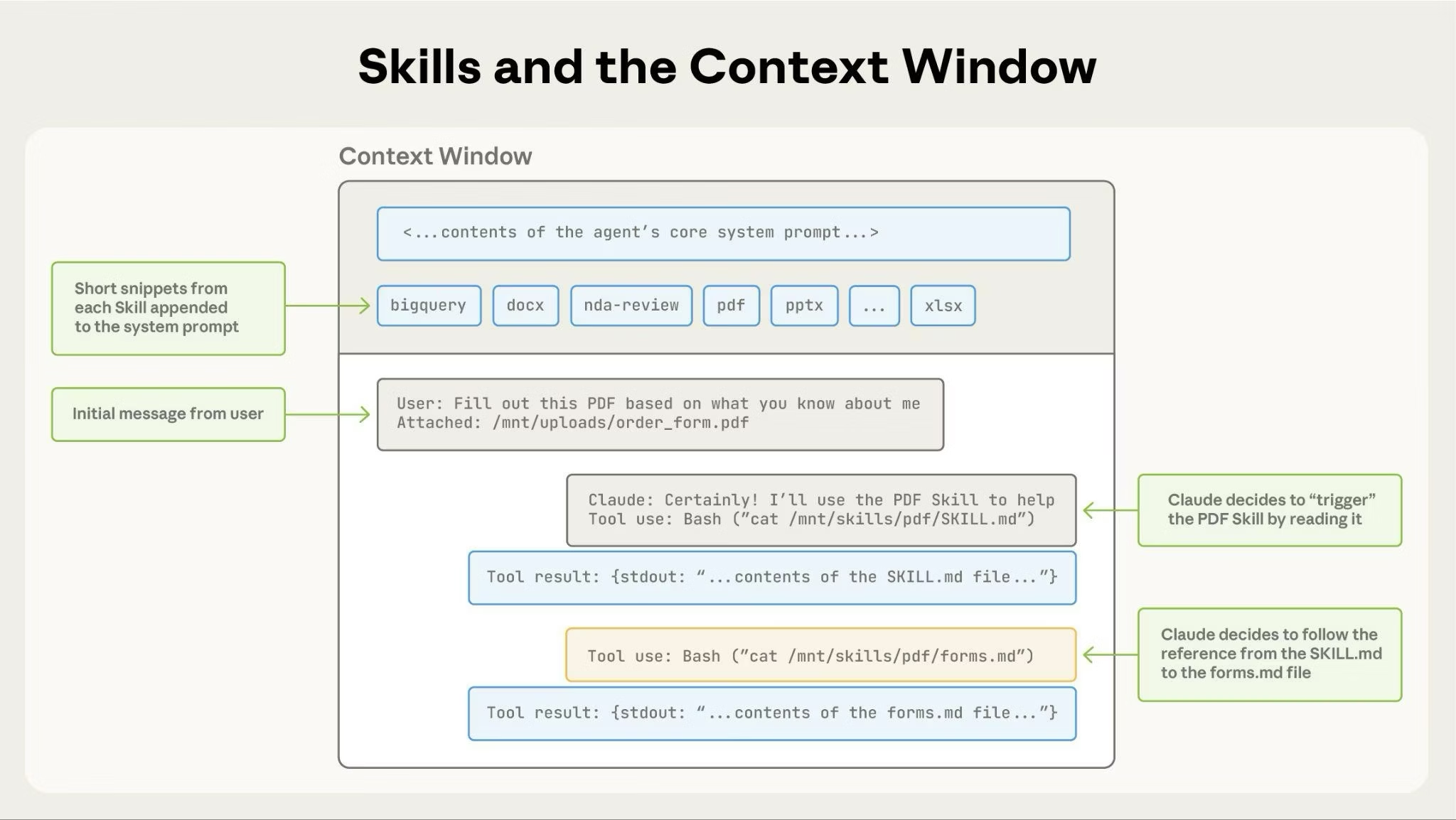
讓我們通過一個具體場景,看看Agent使用SKILL的完整流程。這裏我們降低對Claude的依賴,以更通用的skill使用為例。
場景:你是一個數據分析Agent,已經安裝了"data-analysis" Skill。
- 階段 1:啓動 (Startup & Preload)
- Agent啓動,同時啓動可訪問文件系統的沙箱VM
- 掃描skills/目錄,讀取所有SKILL的元數據(L1)
- 構建漸漸的系統提示:Agent的System Prompt現在包含如下內容:
可用技能:
- name: data-analysis
- description: 用於數據清洗、分析和可視化。當用户提到CSV、Excel或數據庫時使用。
- 階段 2:對話與觸發 (Trigger & Load)
- 用户:“分析一下sales.csv,找出TOP 3銷售”
- LLM推理:匹配用户請求與data-analysis技能描述,生成工具調用:
read /mnt/skills/data-analysis/SKILL.md
- 工具輸出 & 上下文更新:VM執行read命令,並把工具返回結果也就是SKILL.md的內容補充到當前對話的上下文中。
# Data Analysis Workflow
1. **Load Data**: Use pandas.read_csv() to load the file.
2. **Inspect**: Always print the .head() and .info() first.
3. **Clean**: Check for nulls using .isnull().sum().
4. **Execute**: For complex tasks, use the `scripts/analyze.py` script...
- 階段 3:執行與推理 (Execute & Reason)
- LLM推理:模型基於更新的上下文進行推理,例如按照説明第一步是加載數據並檢查,如果SKILL內部提供已經寫好的通用數據EDA的腳本
scripts/inspect_data.py如下
import pandas as pd
def inspect_data(file_name):
df = pd.read_csv(file_name)
print(df.head().to_string())
print(df.info())
print(df.describe())
- 生成腳本調用代碼:則模型會生成工具調用來執行對應的腳本代碼
python scripts/inspect_data.py --file sale_data.csv - 工具輸出 & 上下文更新:VM會執行python代碼,並把數據觀測的結果更新到上下文,例如
(stdout from python):
SalesID Amount Salesperson
0 1 500 Alice
- LLM繼續推理:模型獲得DataFrame的head後會繼續推理,例如進行數據分析,可以進一步調用數據分析的腳本代碼進行例如單因子分析
python scripys/analyze.py --file sale.csv --type single_factor - 循環往復
🧐 實踐中的挑戰與深入思考
但在實際使用中,你還需要考慮幾個工程問題:
- 增加工具推理步驟帶來延時: SKILLS的漸進式加載並非完全沒有成本,每一次加載都需要一次工具調用,因此需要平衡SKILLS能提供的效率提升,以及增加工具調用的延時。【所以沙箱需要提供很詳細的指標監控來進行工程優化,包括SKILL調用數、節省token數etc】
- 何時把SKILL從上下文卸載:哈哈,Claude 的文檔只提了加載,沒提卸載。動態加載進去了,不卸載不還是會撐爆上下文嗎?在長任務中,卸載邏輯至關重要。卸載早了,下次用還得重載;卸載晚了,佔用上下文,還可能導致 SKILL 間指令衝突。【可以考慮對SKILL進行多級分層,cold、warm、hot之類,支持不同offload策略】
- SKILL發現和召回:和MCP工具描述相同,SKILL的meta描述直接決定了模型能否在需要時正確、及時加載説明書。【全面的SKILL測試和驗證是必要的,MCP也是一樣。】
- SKILL增加帶來的指令衝突:當 SKILLS 庫膨脹時,多個 SKILL 之間的指令可能衝突,scripts 之間可能存在命名空間或依賴衝突。如果自由過了火~~~【提供基於AI的一鍵優化和生成方案】
💡 更多切入視角
那SKILLS的引入,對之前的MCP,以n8n、Dify、coze為代表的固定工作流,和以MCP + langgraph為代表的自主智能體,有什麼影響和改變呢?
腳本化 & 文件化 - 重構部分MCP
這裏非替代邏輯,而是從scripts的角度重新考慮一些MCP的設計。
-
高數據輸入工具:對於數據處理類 MCP(如繪圖、分析、建模),調用時必須把全部數據作為輸入 Token 傳遞。而“文件化”後,只需傳遞文件名。
-
固定 Coding 任務:對於文件轉換(如 HTML2PPTX)、固定設計(如海報模板)等任務,與其依賴模型每次生成不穩定且冗長的代碼,不如把流程固化成
scripts或templates直接執行。
可控性 & 穩定性 - 替代部分工作流
為什麼在模型能力很強的今天,公司裏還在跑大量固定工作流?核心是可控性和穩定性。
SKILLS 正在切入這個領域。對於流程的控制,依賴模型對 SKILLS.md 的指令遵從;對於模型無法理解或不該理解的“玄學”(如量化閾值、銷售話術、公司內部系統操作腳本),可以打包放入 scripts 裏。
整體上,SKILLS 更適合那些 “在固化中需要一些靈活性” 的任務。對於完全固化、簡單的任務流,個人感覺還是拖拉拽的平台對於非技術同學的上手成本更低。
可擴展 & 可組合 - 替代部分多智能體
當前多智能體(Multi-Agent)框架的初衷之一就是系統指令隔離。
例如,一個 Planner Agent 為了不讓自己(主智能體)的 System Prompt 過於臃腫,會把“如何搜索”、“如何查詢數據庫”等複雜邏輯(及其對應的長 Prompt)剝離到子智能體中。
而 SKILLS 幾乎完美解決了這個痛點。每個技能的相關説明,都可以通過 SKILL 進行動態加載和卸載。只有當需要時,才把 SOP 加載到上下文中。
優點:相比子智能體模式,SKILLS 模式下上下文共享更完整。子智能體的執行效果極大依賴主智能體傳遞指令的清晰度,而 SKILLS 是在主智能體的完整上下文中執行 SOP。
缺點:需要更好的上下文管理(如前面提到的卸載機制),以保證主智能體的上下文依然乾淨。
關於Anthropic SKILLS我們就聊這麼多,後面該看看Computer-USE Agent最近有什麼新進展了~






