

摘要 12 月 19 日 -20 日,AICon 大會在北京圓滿落地。在這場面向 AI 資深開發者的大會上,GMI Cloud 資深架構師汪小康受邀參加,並進行了主題分享,本文為演講內容精華整理。
12 月 19 日 - 20 日,備受矚目的 AICon 全球人工智能開發與應用大會在北京圓滿舉行。此次大會由極客邦科技旗下 InfoQ 中國主辦,聚焦 AI 技術落地與產業創新,匯聚全球頂尖技術領袖、企業決策者與資深開發者,深度探討大模型應用、算力基建、全球化部署等核心議題,為行業發展提供前沿思路與實踐範本。
GMI Cloud 資深架構師汪小康受邀出席,在"出海時代的基礎設施構建與模型場景實踐"主題分論壇中發表了題為《全球化場景下,基於大規模"跨雲異構"算力的 MaaS 平台構建實踐》的技術演講。全面展示了 GMI Cloud 在全球多雲算力調度與 MaaS 平台構建上的創新能力與實戰成果,以下是演講內容精華整理:
Part 1
核心洞察:
**AI 出海成必然趨勢,**算力基建是關鍵支撐
全球 AI 市場正保持穩步增長,行業年均複合增長率介於 19.20%-27.67% 之間,預計 2034 年市場規模將突破 3.6 萬億美元,這背後是海量 AI 應⽤的爆發式增⻓,尤其是出海應⽤的快速擴張,對算⼒的需求也隨之提升。
用户層面,2025 年 9 ⽉,海外 AI 應⽤⽉活⽤户已突破 14 億,中國市場也超過 4.6 億。這組數據背後,是 AI 技術在海外市場的⼴泛應用⸺從歐美成熟市場到新興經濟體,⽤户對 AI 的接受度遠超預期,為中國 AI 應⽤出海提供了龐⼤的⽤户基礎。更重要的是,⽤户習慣已經養成。調研顯示,全球 58% 的受訪者會主動使用 AI 工具,31% 為每週甚至每天使用的高頻用户,50% 的人在工作、學習場景中使用過 AI,用户使用習慣已全面養成。出海企業⽆需從零進⾏市場教育,這極⼤降低了出海⻔檻,也讓推理需求的爆發成為必然。
從市場環境來看,國內市場競爭激烈、增長空間趨緩,而全球市場呈現增長潛力,企業採購預算與個人付費意願翻倍增長,拉丁美洲等新興市場增速超 50%,這種市場需求的巨大⽔位差,讓出海成為中國 AI 產業釋放產能的最佳路徑。據預測,到 2035 年中國 AI 產業收⼊將佔全球 30.6%,中國企業深度融⼊全球價值鏈已是必然。

Part 2
應需而生:
Inference Engine 解 AI 出海算力困境
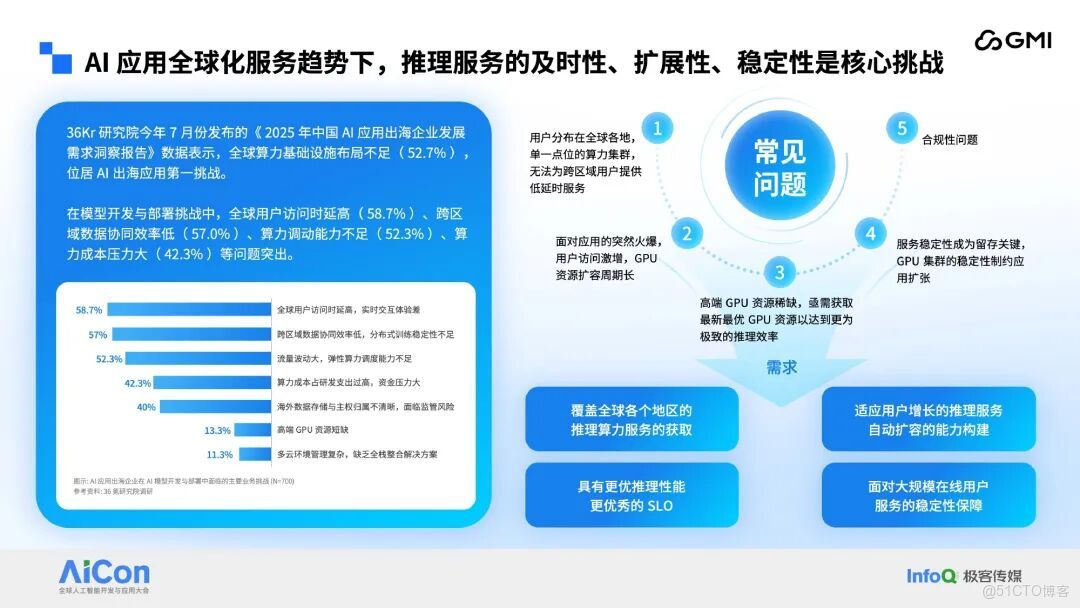
但機遇背後,挑戰同樣嚴峻。36Kr 研究院的調研顯示,全球算⼒基礎設施佈局不⾜是 AI 出海的第⼀⼤挑戰。 具體來看,接近 6 成的企業⾯臨全球⽤户訪問時延⾼的問題以及存在跨區域數據協同效率低的困擾,缺乏彈性算⼒調度能⼒⾼昂的算⼒成本。此外,合規⻛險、⾼端 GPU 短缺、多雲管理複雜等問題也不容忽視。 這些挑戰集中體現在:單⼀點位算⼒⽆法滿⾜跨區域低延時需求;⽤户激增時 GPU 擴容週期⻓;⾼端 GPU 資源稀缺;服務穩定性制約應⽤擴張;還有複雜的合規要求,這些都成為 AI 應⽤出海的攔路⻁。
⽬前,推理技術的發展也是⽇新⽉異。⼀⽅⾯,多節點推理成為主流,P/D 分離、EP 架構讓推理吞吐量⼤幅提升,⽐如 DeepSeek-R1 671B 模型 4 個⽉內吞吐量提升 26 倍;另⼀⽅⾯,推理價格持續下降,兩年內 GPT-4 級模型的 Token 成本降低 240 倍。這意味着,企業不僅要應對多節點系統的複雜性,還要在成本優化上持續發⼒,端到端的系統調優⾄關重要。
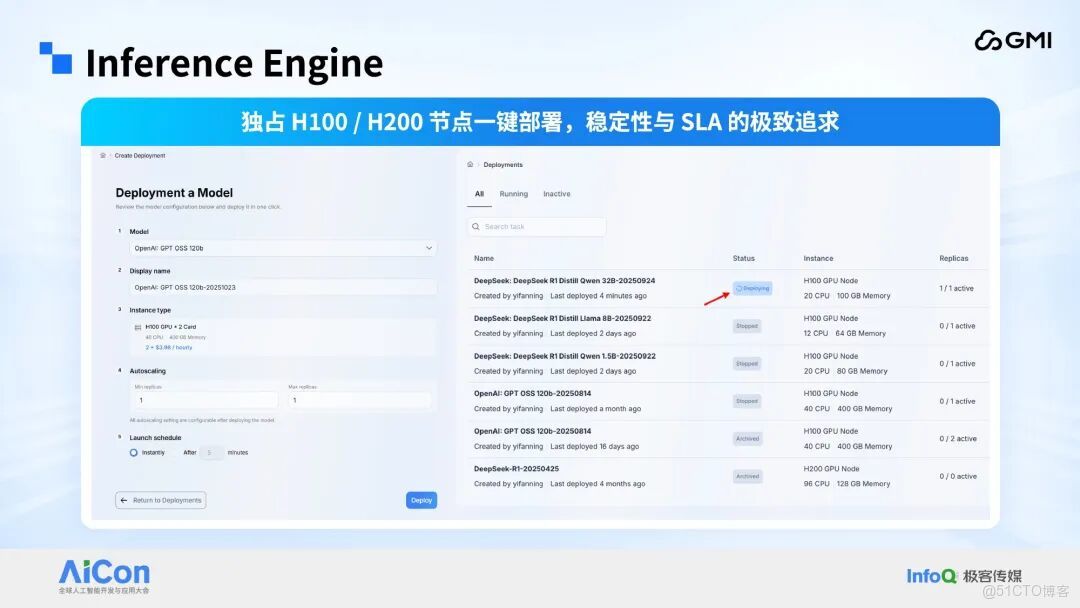
在此背景下,GMI Cloud 推出 Inference Engine 平台。作為 NVIDIA 全球六大雲推薦合作伙伴之一,GMI Cloud 能夠獲取 H200、GB300 等最先進的算力資源,並在全球運營 10 餘個算力中心,近期投資 5 億美元在亞太地區建設萬卡規模的 GB300 集羣的 AI Factory。Inference Engine 平台覆蓋了 語⾔、⾳視頻、圖像等全類型 AI 模型,跨境 AI 聊天⼯具、海外視頻⽣成應⽤,還是多語⾔語⾳交互產品在這個平台上基本上都能找到適配的模型和算⼒⽀撐,實現⼀站式部署。其次,平台提供獨佔式 H100/H200 節點部署,⽤户可以⼀鍵選擇實例類型,從 單卡推理到多卡任務,可以靈活配置,按⼩時計費,成本可控。從實際部署案例來看,多個版本的 DeepSeek、GPT OSS 模型都已成功上線,實例狀態實時可⻅。
在服務可靠性上,Inference Engine 構建了完善的可觀測性體系。通過 Tracing 鏈路追蹤和實時性能監控,⽤户可以清晰看到每⼀次推理請求的耗時、狀態,P99 延遲等關鍵指標⼀⽬瞭然。 為了降低⽤户接⼊⻔檻,平台提供 OpenAI 兼容的端點 URL,⽤户⽆需修改代碼就能快速接⼊。同時⽀持靈活的參數配置,⽐如温度、最⼤ Token 數、頻率懲罰等,滿⾜不同場景的推理需求。簡單來説,Inference Engine 部署了⼤量的也就先進的主流模型並提供 api 服務。企業只需要調⽤api 服務即可。對於企業的⾃有模型,平台也提供了模型託管服務,企業不再需要為複雜的基礎設施層⽽費⼼費⼒,⼀鍵部署,全球可達。
Part 3
核心痛點:
**全球「高性價比算力資源」獲取難、**管理複雜度高
隨着 AI 出海浪潮的深化,MaaS 行業出現了一系列新變化,原本的解決方案已難以適配企業的複雜需求。⽬前 gpu 雲市場格局不再由傳統的⼤型公有云⼚商主導,涌現出了很多的新的 gpu 雲⼚商,比如 CoreWeave、Runpod 。然⽽市場多元化帶來了新的問題:標準不統⼀。每家雲⼚商的技術棧以及接⼊⽅式都不⼀樣。這意味着,企業如果同時使⽤多家雲⼚商的資源,需要做出針對性的適配開發⼯作。
到 2024 年已經有九成的組織採⽤多雲方案,來避免單⼀⼚商鎖定,並且優化成本。但是多雲方案也增加了很多隱形的成本,以及複雜的採購流配置流程。Flexera 報告顯示 2024 年 89% 的組織採用多雲策略,67% 的工作負載分佈在多個雲服務商,卻伴隨高昂隱性成本:
大型企業年均多雲相關成本達 3.48 億美元,遷移人力成本佔 28%,停機損失佔 24%,跨雲數據傳輸、配置調試等成本持續攀升,100 億參數模型遷移成本約 450 萬美元;且企業平均需對接 3.4 個雲平台,採購審批平均耗時 27 天,配置調試需 14 天,嚴重影響項目推進效率。
此外,全球算力資源地域失衡明顯,加劇了資源管理難度。北美佔比 42%、歐洲 18%、中國 15%,中東、拉美、非洲等新興市場供給嚴重不足,企業使⽤這些分佈不均勻的算⼒會有極大挑戰。同時算力利用率普遍偏低,AI 訓練場景 GPU 利用率僅 35%,推理場景 62%,數據中心平均 48%,遠低於行業良好水平的 85%,核心瓶頸包括 73% 企業採用靜態分配導致的資源分配僵化、推理負載 3-8 倍的峯值波動、傳統系統 27% 的資源碎片率及硬件兼容差異等。
當前市場環境下,單一廠商的算力供給已難以覆蓋企業多樣化 AI 需求,而企業在眾多 MaaS 平台中進行篩選時面臨較高決策成本;採用多雲策略雖能分散風險,卻導致管理複雜度和總體成本飆升;同時,全球各地部署推理服務需要應對網絡延遲、數據合規、資源調度等多重挑戰。這一系列問題,催生了對新一代 MaaS 平台的迫切需求。

Part 4
效能躍升:
Inference Engine 2.0 四大核心能力
優化出海算力部署
異構資源統一納管:BRS 概念簡化資源管理
面對 MaaS 市場的深刻變革,Inference Engine 2.0 確立了四大核心能力:異構資源的統一納管、多雲資源調度、全球化部署、高度彈性擴縮容,旨在構建一個真正面向全球的算力調度網絡。⾯向分佈在全球各地的資源,幫助企業精準找到算⼒和⾼效利⽤算⼒。

全球多雲資源調度:分層架構 + 兩級調度提升資源適配性
設計 “總控制層 - 區域控制面 - 數據面(BRS)” 的三層架構,搭配 “兩級調度” 機制,實現對全球範圍內多雲異構資源的統一管控與智能調度:
最上層為總控制層,基於中心化部署的 Kubernetes(K8s)集羣構建,核心職責涵蓋全局資源統籌調度、多集羣協同管理、跨區域任務編排等核心能力;
各區域部署區域控制面,同樣以 K8s 集羣為技術底座,主要承擔區域內資源精細化管控、二級調度執行及本地流量智能分發等功能;
最下層為數據面,由 BRS(Backend Resource Slice,後端資源切片)構成。每個 BRS 實例啓動後,會自動註冊至對應區域控制面,並映射為該集羣下的虛擬節點。

而兩級調度是 Inference Engine 2.0 的核⼼調度機制。
一級調度部署於總控制層,聚焦全局資源統籌,核心目標是實現任務就近部署與全局負載均衡;二級調度部署於各區域子集羣,聚焦區域內資源調度效率,核心目標是實現資源最優匹配,且在調度失敗時觸發自動重調度。
具體調度流程如下:一級調度接收任務請求後,先解析任務資源需求、收集全局多雲資源狀態信息,再基於一級調度評估因子進行綜合打分,最終篩選出最優目標集羣並完成任務下發;二級調度接收任務後,收集區域內資源實時狀態信息,基於二級調度評估因子對候選節點進行打分;若目標節點資源充足,直接完成任務與資源的綁定;若資源不足,則自動觸發彈性擴容機制,保障調度任務高效完成。
三層架構與兩級調度機制,共同構成該平台的核心設計理念。

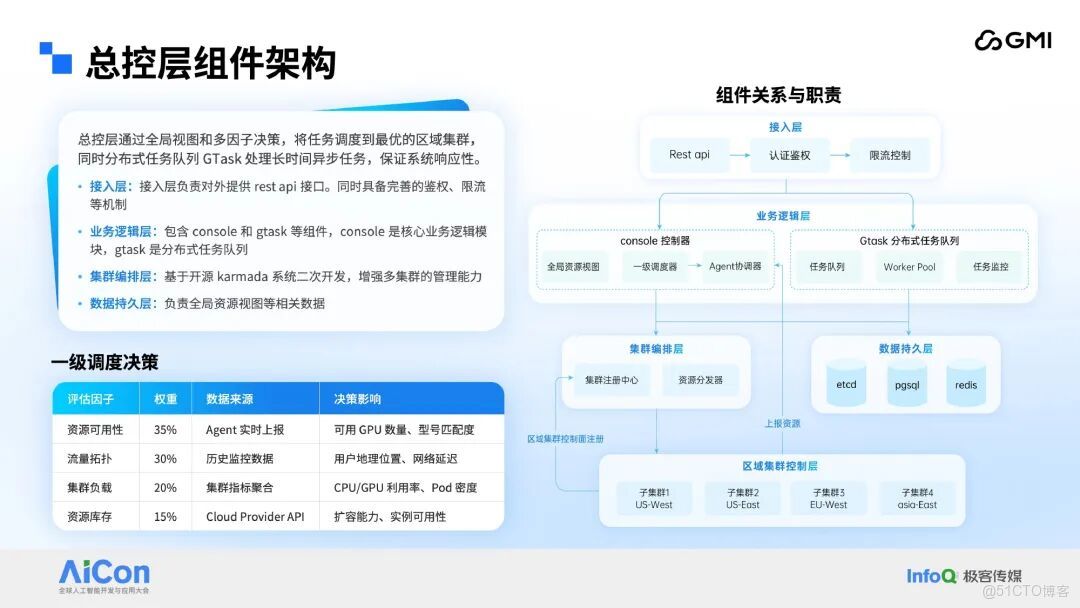
總控制層是整個系統的核心,其組成架構可詳細拆解如下:
對外統一 API 接入層:承擔與外部系統的 API 交互職責,提供標準化的接口接入能力;
Console 控制器:作為系統業務邏輯的核心實現載體,負責業務規則的解析與執行;
異步分佈式任務隊列:專注於異步任務的接收、分發與處理,保障非實時任務的高效流轉;
多集羣資源編排層:核心組件包含集羣註冊中心與資源分發器,該層基於開源 Karmada 構建,並在其基礎上自定義擴展了大量 CRD(CustomResourceDefinition,自定義資源定義),以此增強 Karmada 的多集羣管理與資源編排能力。
此外,總控制層內置一級調度器,可基於多維度指標完成任務的一級調度決策。
上述組件協同配合,共同構成總控制層的完整能力體系。
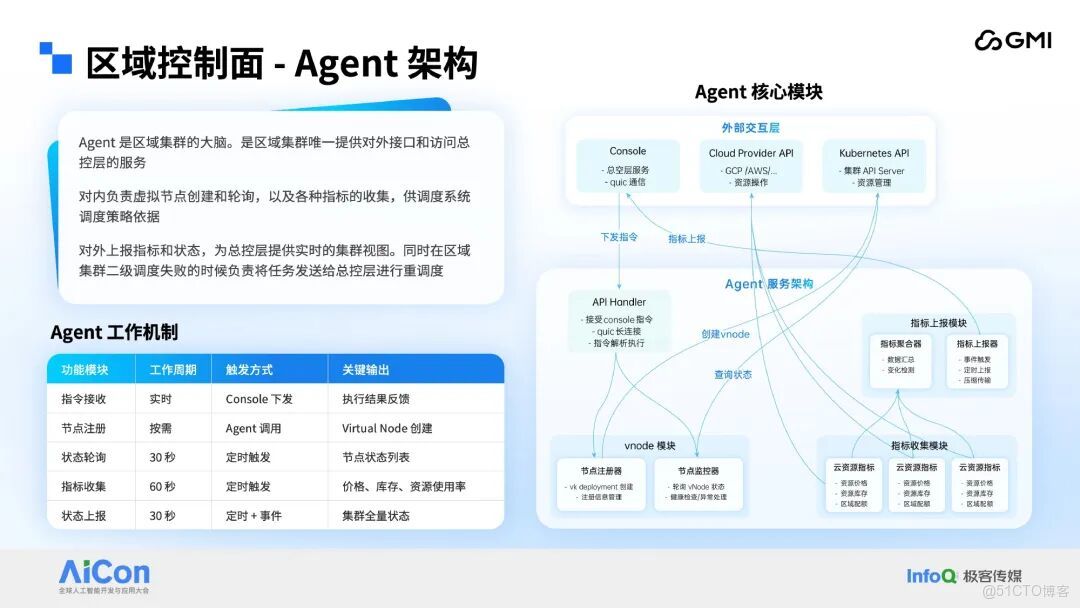
區域控制面的核心支撐服務為 Agent,該服務承擔着多重關鍵職責:對內負責虛擬節點的全生命週期管理,同時完成各類指標的採集與聚合,生成標準化指標數據供二級調度模塊調用;對外則定期向總控制面上報區域子集羣的指標數據與運行狀態,為總控制面構建近乎實時的子集羣全局視圖提供核心數據支撐,此外,當區域子集羣內二級調度任務執行失敗時,Agent 還會負責將任務回傳至總控制面,觸發全局重新調度流程以保障任務執行連續性。
區域控制面需實現的另一項關鍵能力為高度彈性擴縮容,該能力通過二級調度與 HPA(Horizontal Pod Autoscaler)的協同機制落地實現。其中,二級調度通過過濾與打分兩個核心階段完成區域內資源的最優匹配與分配,HPA 則基於集羣負載實時變化動態調整資源規模,兩者的協同運作既保證了資源的高效利用,又實現了對業務負載變化的快速響應。
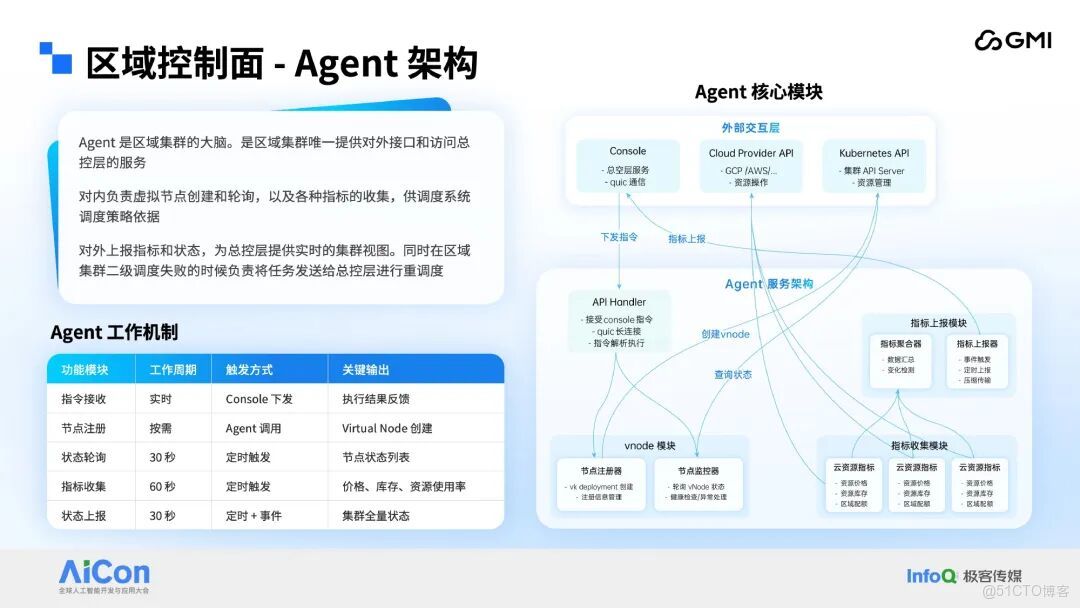
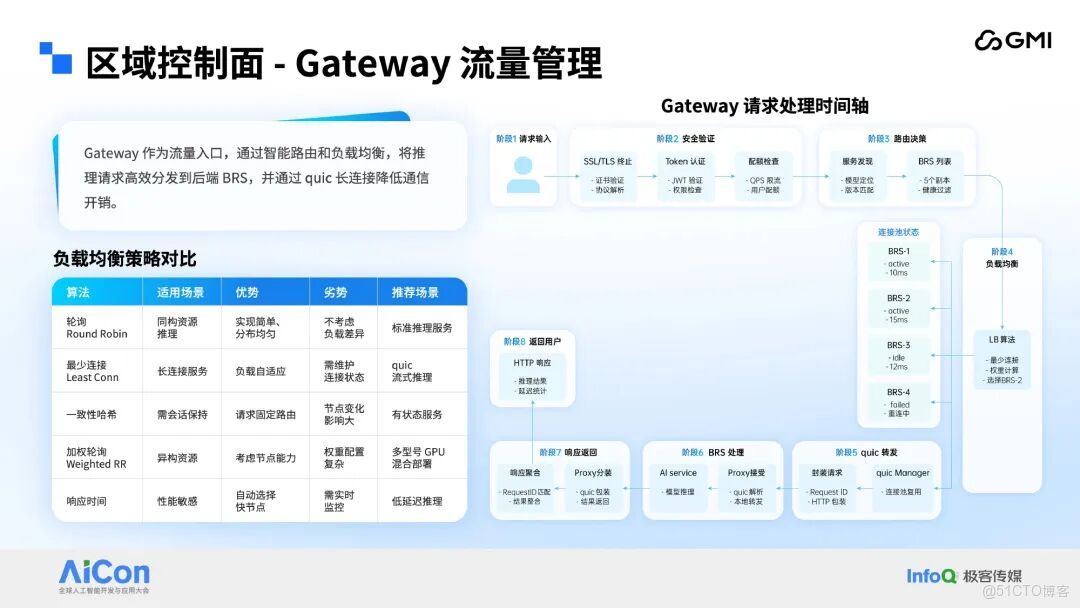
區域控制面還具備一項關鍵特性 —— 流量管理。考慮到總控制層採用中心化部署,而服務的用户羣體覆蓋全球,若流量經總控制層轉發,將導致延遲過高且穩定性無法保障。因此,對應的流量轉發方案設計為僅通過區域控制面完成轉發:各區域控制面均部署自研網關(Gateway)服務,該服務負責承接外部各類流量,隨後通過多種路由算法精準定位後端 BRS,再借助 QUIC 協議將流量轉發至 BRS 上的模型負載,最終完成請求的處理閉環。
接下來聚焦三層架構最底層的數據面,即 BRS 內部的詳細技術實現。Kubernetes(K8s)數據面的核心服務為 Kubelet,該組件負責與 API Server 交互,在物理節點上完成容器啓停、CNI 插件初始化等一系列複雜操作。BRS 借鑑 Kubelet 的架構設計,在每個 BRS 實例上部署 BRSlet 組件,同時對其功能實現進行大幅簡化。BRSlet 的核心能力聚焦於 Pod 在 BRS 上的生命週期管理,其運行機制參考當前主流容器運行時技術,配套自研 Shim 服務。該 Shim 服務內置面向異構資源的多類型負載運行時環境,BRSlet 通過調用 Shim 服務完成 Pod 在不同 BRS 實例上的部署與運行,以此實現 BRSlet 與業務負載之間的進程隔離,達成組件間的解耦設計。
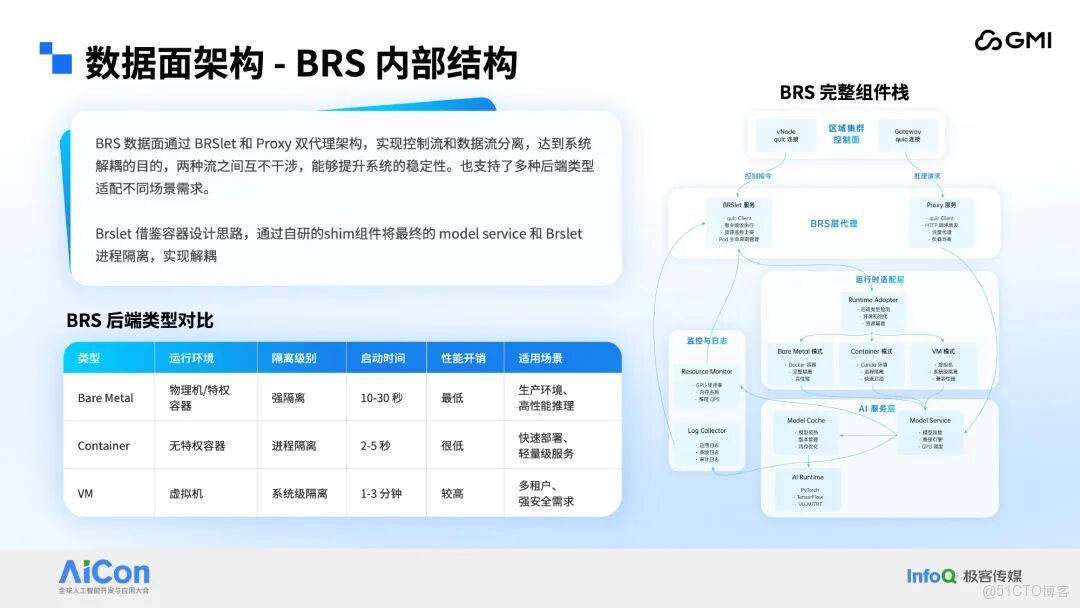
區域控制面與 BRS 層的交互依賴兩條獨立通信鏈路,分別為控制鏈路與請求鏈路。考慮到系統面向跨雲場景的公網通信需求,為保障複雜網絡環境下的通信穩定性,該交互鏈路採用 QUIC 協議承載數據傳輸 —— 該協議的傳輸特性高度適配混合雲公網場景的通信需求,同時系統額外疊加多重通信保障機制,進一步提升鏈路可靠性。其中,控制鏈路承擔區域控制面虛擬節點服務與 BRSlet 之間的通信任務,主要用於傳輸創建 Pod 等系統內部指令;請求鏈路則負責區域控制面 Gateway 服務與部署在 BRS 上的 Proxy 組件之間的數據交互,核心功能是轉發外部推理請求與傳輸業務數據。兩條鏈路獨立運行、互不干擾,從通信層面強化了系統整體穩定性。

高度彈性擴縮容:協同調度提升資源利用率
在兩級調度機制之外,BRS 擴縮容機制同樣是系統的核心能力模塊。該機制的調度執行聚焦於子集羣級別,依託多維度決策策略完成擴縮容觸發與執行邏輯的判定。擴縮容的完整邏輯可通過時間線進行階段拆解,此處不展開贅述。該機制具備完善的智能決策與優雅處理能力,能夠在保障服務質量的前提下,實現企業算力成本的最優控制。
為支撐多機多卡任務的運行需求,技術方案為 BRS 引入 Group 分組概念。具體而言,處於同一網絡環境下的多個 BRS 會被劃入同一個 Group。例如,IDC 集羣內部啓動的 3 個搭載 IB 網絡的 BRS,將自動組成一個具備 IB 網絡能力的 Group,此類 Group 可承接 PD 分離、SFT 等需要多機多卡協同的任務。上層調度系統可基於不同 Group 的網絡屬性與資源特徵,制定差異化的調度策略。

全球化部署 + 高可靠保障:兼顧低延時與安全穩定
模型部署任務由總控制層的 API 服務發起創建,經兩級調度機制逐層分發後,最終被調度至目標 BRS 實例;隨後由 BRSlet 完成 Pod 的解析與加載,最終實現模型在 BRS 上的運行,整個流程需經由多模塊服務的協同流轉。
附表為模型部署全流程的時間消耗拆解,各階段耗時均為參考值,具體時長受資源狀態、網絡環境等多重因素影響。在底層資源充足,且鏡像與模型文件已完成預熱的前提下,模型部署可實現秒級啓動。
最後對系統的可觀測性體系展開説明,該體系是保障系統穩定運行的核心支撐。當前系統已構建起完善的監控告警體系,可實時感知並反饋系統運行狀態;配套的安全防護機制可實現數據與服務的雙重安全保障;精細化的權限模型能夠支撐粒度可控的訪問管控;同時,平台會採集多維度運行指標,為上層業務的分析與決策提供數據支撐。
