

《新興數據湖倉設計與實踐手冊·數據湖倉建模及模型命名規範(2025年)》 由四篇遞進式指南組成,以“模型架構—公共規範—分層規範—命名規範”為主線,系統構建可演進、可治理、可共享的現代數據湖倉。
首篇 《數據模型架構原則》 提出了 “ODS-DW-APP” 四層(含DW內DWD/DWM/DWS)數據分層架構,並圍繞主題域劃分、高內聚低耦合、公共邏輯下沉及成本性能平衡四大原則,為湖倉一體的維度建模奠定統一且可擴展的設計基石。
本文為系列文章第二篇,詳細剖析了數倉公共設計所遵循的規範,包括層次調用規範、數據類型規範、字符串等數倉設計規範。
後續兩篇將在此框架內,依次剖析數倉各層細化規範及統一命名體系,幫助企業用一套方法論完成從數據入湖到價值變現的全鏈路建設,敬請期待完整版。
1. 層次調用規範:把控數倉數據流向與引用原則
🚀業務數據流向設計與分層引用要點
穩定業務按照標準的數據流向進行設計,即 ODS –> DWD –> DWS –> APP。非穩定業務或探索性需求,可以遵循 ODS -> DWD -> APP 或者 ODS -> DWD -> DWM ->APP 兩個模型數據流。
在保障了數據鏈路的合理性之後,也必須保證模型分層引用原則:
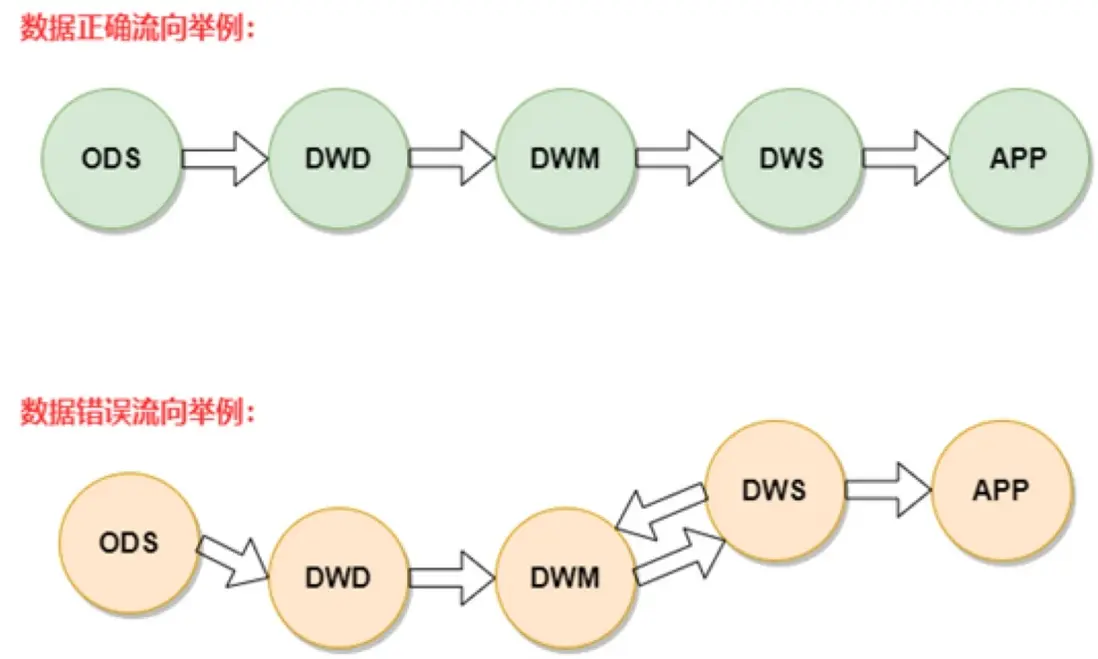
- 正常流向:ODS -> DWD -> DWM -> DWS -> APP,當出現 ODS -> DWD -> DWS -> APP 這種關係時,説明主題域未覆蓋全。應將 DWD 數據落到 DWM 中,對於使用頻度非常低的表允許 DWD -> DWS。
- 儘量避免出現 DWS 寬表中使用 DWD 又使用(該 DWD 所歸屬主題域)DWM 的表。
- 同一主題域內對於 DWM 生成 DWM 的表,原則上要儘量避免,否則會影響 ETL 的效率。
- DWM、DWS 和 APP 中禁止直接使用 ODS 的表, ODS 的表只能被 DWD 引用。
- 禁止出現反向依賴,例如 DWM 的表依賴 DWS 的表。
舉例:
2. 數據類型規範:統一數倉數據類型的標準設定
🔍各類數據的精確類型定義
需統一規定不同的數據的數據類型,嚴格按照規定的數據類型執行:
- 金額:double 或 使用 decimal(28,6) 控制精度等,明確單位是分還是元。
- 字符串:string。
- id類:bigint。
- 時間:string。
- 狀態:string
3. 數據冗餘規範:寬表冗餘字段的合理把控
🤔高頻使用、低延後與低重複率的考量
寬表的冗餘字段要確保:
- 冗餘字段要使用高頻,下游3個或以上使用。
- 冗餘字段引入不應造成本身數據產生過多的延後。
-
冗餘字段和已有字段的重複率不應過大,原則上不應超過60%,如需要可以選擇join或原表拓展。
4. NULL字段處理規範:維度與指標字段的 NULL 值處理策略
❓為何如此設置 NULL 字段值
- 對於維度字段,需設置為-1
-
對於指標字段,需設置為 0
5. 指標口徑規範:確保數倉指標口徑一致性
🧩指標梳理與管理的具體方法
需要保證主題域內,指標口徑一致,無歧義。
通過數據分層,提供統一的數據出口,統一對外輸出的數據口徑,避免同一指標不同口徑的情況發生。
1) 指標梳理
指標口徑的不一致使得數據使用的成本極高,經常出現口徑打架、反覆核對數據的問題。在數據治理中,我們將需求梳理到的所有指標進行進一步梳理,明確其口徑,如果存在兩個指標名稱相同,但口徑不一致,先判斷是否是進行合併,如需要同時存在,那麼在命名上必須能夠區分開。
2) 指標管理
指標管理分為原子指標維護和派生指標維護。
原子指標:
- 選擇原子指標的歸屬產線、業務板塊、數據域、業務過程
- 選擇原子指標的統計數據來源於該業務過程下的原始數據源
- 錄入原子指標的英文名稱、中文名稱、概述
- 填寫指標函數
- 系統根據指標函數自動生成原子指標的定義表達式
- 系統根據指標定義表達式以及數據源表生成原子指標SQL
- 派生指標:
-
在原子指標的基礎之上選擇了一些維度或者修飾限定詞。
6. 數據表處理規範:解析數倉不同類型數據表特點
⚡增量表、全量表、快照表與拉鍊表的差異
1) 增量表
新增數據,增量數據是上次導出之後的新數據。
- 記錄每次增加的量,而不是總量;
- 增量表,只報變化量,無變化不用報;
- 每天一個分區。
2) 全量表
每天的所有的最新狀態的數據。
- 全量表,有無變化,都要報;
- 每次上報的數據都是所有的數據(變化的 + 沒有變化的);
- 只有一個分區。
3) 快照表
按日分區,記錄截止數據日期的全量數據。
- 快照表,有無變化,都要報;
- 每次上報的數據都是所有的數據(變化的 + 沒有變化的);
- 一天一個分區。
4) 拉鍊表
記錄截止數據日期的全量數據。
- 記錄一個事物從開始,一直到當前狀態的所有變化的信息;
- 拉鍊表每次上報的都是歷史記錄的最終狀態,是記錄在當前時刻的歷史總 量;
- 當前記錄存的是當前時間之前的所有歷史記錄的最後變化量(總量);
- 只有一個分區。
7. 表的生命週期管理:依據歷史數據與表類型制定策略
⏳歷史數據等級劃分與表類型劃分生成管理矩陣
這部分主要是要通過對歷史數據的等級劃分與對錶類型的劃分生成相應的生命週期管理矩陣。
1) 歷史數據等級劃分
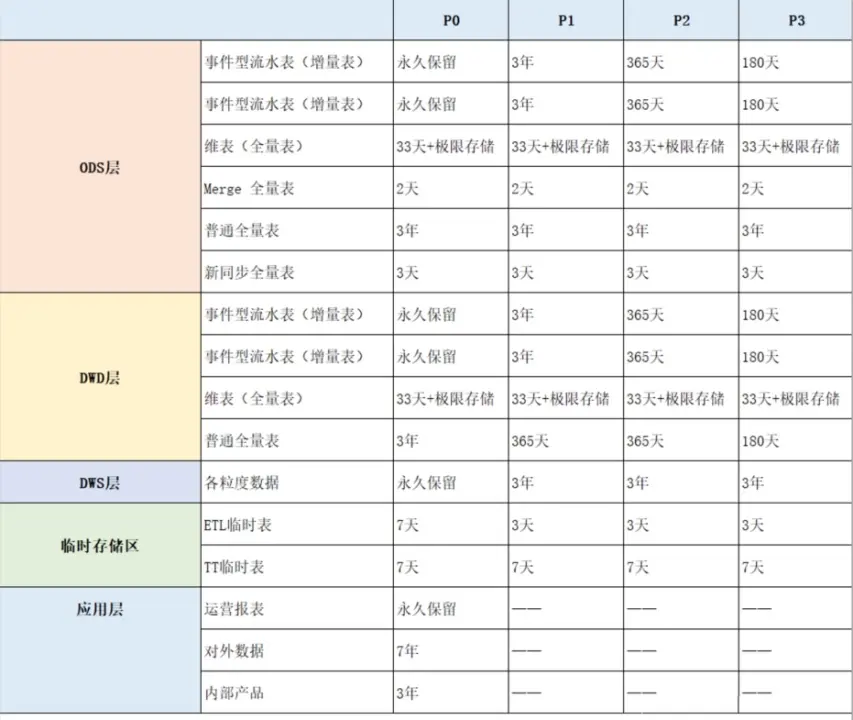
主要將歷史數據劃分P0、Pl、P2、P3 四個等級,其具體定義如下:
- P0 :非常重要的主題域數據和非常重要的應用數據,具有不可恢復性,如交易、日誌、集團 KPI 數據、 IPO 關聯表。
- Pl :重要的業務數據和重要的應用數據,具有不可恢復性,如重要的業務產品數據。
- P2 :重要的業務數據和重要的應用數據,具有可恢復性,如交易線 ETL 產生的中間過程數據。
- P3 :不重要的業務數據和不重要的應用數據,具有可恢復性,如某些 SNS 產品報表。
2) 表類型劃分
- 事件型流水錶(增量表)
事件型流水錶(增量表)指數據無重複或者無主鍵數據,如日誌。 - 事件型鏡像表(增量表)
事件型鏡像表(增量表)指業務過程性數據,有主鍵,但是對於同樣主鍵的屬性會發生緩慢變化,如交易、訂單狀態與時間會根據業務發生變更。 - 維表
維表包括維度與維度屬性數據,如用户表、商品表。 - Merge 全量表
Merge 全量表包括業務過程性數據或者維表數據。由於數據本身有新增的或者發生狀態變更,對於同樣主鍵的數據可能會保留多份,因此可以對這些數據根據主鍵進行 Merge 操作,主鍵對應的屬性只會保留最新狀態,歷史狀態保留在前一天分區 中。例如,用户表、交易表等都可以進行 Merge 操作。 - ETL 臨時表
ETL 臨時表是指 ETL 處理過程中產生的臨時表數據,一般不建議保留,最多7天。 - TT 臨時數據
TT 拉取的數據和 DbSync 產生的臨時數據最終會流轉到 DS 層,ODS 層數據作為原始數據保留下來,從而使得 TT&DbSync 上游數據成為臨時數據。這類數據不建議保留很長時間,生命週期默認設置為 93天,可以根據實際情況適當減少保留天數。 - 普通全量表
很多小業務數據或者產品數據,BI一般是直接全量拉取,這種方式效率快,對存儲壓力也不是很大,而且表保留很長時間,可以根據歷史數據等級確定保留策略。
通過上述歷史數據等級劃分與表類型劃分,生成相應的生命週期管理矩陣,如下表所示:
- 上文回顧:《(一)數據模型架構原則:四層七階,數據湖倉建模的“第一塊基石”》
- 下文預告:數倉各層設計規範