

為什麼很多客服大模型,看起來很聰明,卻一點也不好用
如果你做過客服相關的項目,大概率會經歷一個非常相似的過程。
一開始,大家都很興奮。
把歷史客服文檔、FAQ、知識庫一股腦丟進 RAG,接上一個看起來很強的模型,測試時效果還不錯。大多數常見問題都能答上來,語氣也挺自然,看起來“已經能替代人工了”。
但只要一上線,問題就開始接連出現。
模型開始亂承諾
模型開始“過度熱情”
模型在不該回答的時候給出非常完整的答案
模型不懂什麼時候該升級人工
模型回答本身沒錯,但業務方看了直搖頭
慢慢你會意識到一個問題:
不是模型不夠聰明,而是你一開始就把客服這件事想簡單了。
客服從來就不是一個“問什麼答什麼”的系統,它本質上是一個決策系統。而你用問答機器人的方式去做它,幾乎註定會出問題。
一個必須先認清的事實:客服的核心目標,從來不是“回答問題”
這是做客服大模型之前,最容易被忽略、但又最關鍵的一點。
從技術視角看,我們習慣把客服理解為“用户提問 → 系統回答”。
但從業務視角看,客服真正關心的從來不是答案本身,而是風險、成本和結果。
客服要做的事情包括但不限於:
- 避免給出錯誤承諾
- 避免觸發法律或合規風險
- 儘量減少人工介入成本
- 在必要時及時升級人工
- 控制用户情緒,而不是單純輸出信息
這些目標,和“答對一個問題”關係並不大。
一旦你意識到這一點,就會發現:
把客服大模型當成問答機器人,本身就是方向性錯誤。
為什麼“FAQ + RAG + 大模型”的方案天然不適合客服
這是目前最常見的一種做法,也是失敗率最高的一種。
邏輯看起來非常順:
用户提問 → 檢索知識 → 模型生成答案 → 完成客服。
問題在於,這套流程默認了一個前提:
“只要知識是對的,回答就是安全的。”
但在客服場景裏,這個前提幾乎從來不成立。
舉個非常常見的例子。
用户問:“如果我現在退款,大概多久能到賬?”
知識庫裏可能有非常明確的説明,但真實情況取決於支付方式、銀行、節假日、用户歷史行為等多個因素。一個完整、看似專業的回答,在業務上反而是危險的。
人類客服在這種情況下,往往會下意識地模糊表達、加前置條件、甚至直接引導用户走人工流程。但模型如果只是被訓練成“儘量回答”,就會非常自信地踩雷。
客服系統真正需要的能力,不是“會答”,而是“會判斷”
這是客服大模型和問答系統的本質分界線。
一個合格的客服系統,至少要具備幾類判斷能力:
- 這是不是一個高風險問題
- 這是不是一個需要人工介入的問題
- 我是否掌握了足夠的信息來回答
- 我現在的回答,會不會被用户當成承諾
- 我是不是應該先澄清,而不是直接給結論
這些判斷,本質上都不是知識問題,而是策略問題。
而策略問題,靠 RAG 是解決不了的。
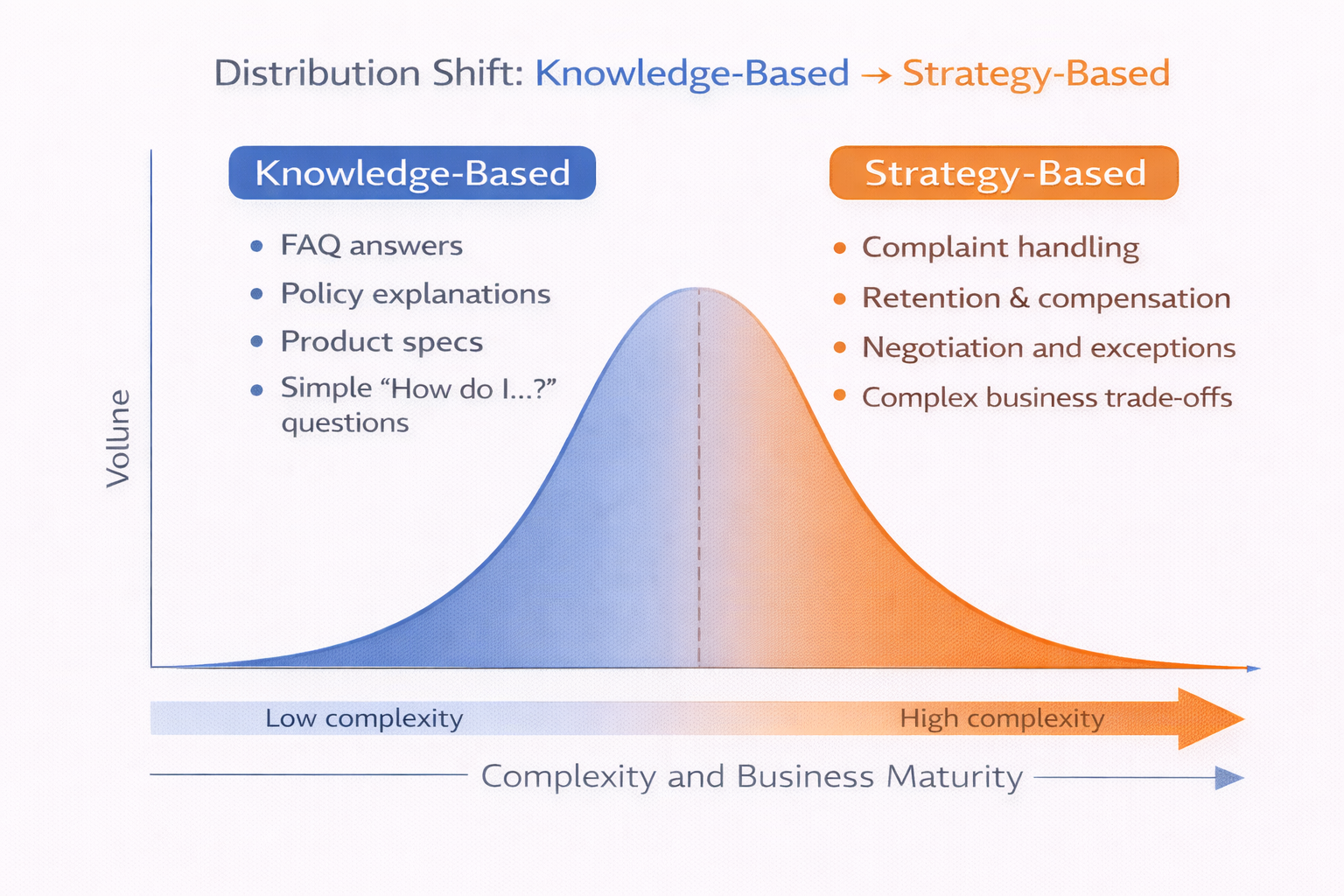
客服問題從“知識型”到“策略型”的分佈示意圖
為什麼客服場景幾乎一定繞不開微調
很多團隊一開始會對“微調”非常抗拒,覺得成本高、週期長、風險大,希望靠 prompt 和 RAG 解決一切問題。
但在客服場景裏,如果你不做微調,幾乎一定會踩同一批坑。
原因很簡單:
你希望模型學會的,並不是“怎麼回答某個具體問題”,而是“在什麼情況下該怎麼表現”。
這類能力,如果沒有通過訓練顯式地教給模型,它是學不會的。
你可以通過 prompt 提示模型要“謹慎”“不要亂承諾”,但在複雜對話中,這種提示的約束力非常有限。一旦上下文變長、問題變複雜,模型還是會回到它最熟悉的模式:儘量給出一個完整、有幫助的回答。
客服微調的數據,和你想象的完全不一樣
這是第二個非常容易走錯的地方。
很多人一提到客服微調,第一反應是:
“那我是不是要準備很多問答數據?”
實際上,單純的問答數據,對客服微調的價值非常有限。
真正有價值的數據,往往來自這些地方:
- 模型不該回答,但歷史上回答過的問題
- 人工客服選擇拒答或升級的對話
- 業務明確要求“只能這樣説”的場景
- 同一個問題,不同處理策略導致不同結果的案例
這些數據,表面上看起來“囉嗦”“不標準”,但它們恰恰包含了客服系統最需要學習的東西:邊界。
客服微調真正困難的地方:不是模型,而是“態度”
這是一個很多技術團隊低估的問題。
在客服場景裏,模型的“態度”往往比“內容”更重要。
太冷漠,會激怒用户
太熱情,會抬高預期
太肯定,會變成承諾
太模糊,會被投訴敷衍
而這些東西,幾乎沒辦法通過規則完全控制。
這也是為什麼很多團隊在 SFT 之後,模型依然“看起來不對勁”。它每一句話都沒錯,但組合在一起,就非常不像一個合格的客服。
這個時候,引入偏好對齊類方法(比如 PPO 或 DPO),往往會有明顯改善。
客服場景下,PPO/DPO 到底在對齊什麼
在客服微調裏,PPO 或 DPO 很少是用來“讓模型更懂業務”的,它們更多是在做一件事:
強化某些表達方式,壓制另一些表達方式。
比如:
- 在不確定時,偏向澄清而不是直接給結論
- 在高風險問題上,偏向升級而不是解釋
- 在用户情緒激動時,優先安撫而不是輸出信息
這些偏好,很難用硬規則描述,但非常適合通過對齊訓練來完成。
在實際工程中,常見的做法是:
- 先用 SFT 讓模型“像個客服”
- 再用 PPO/DPO 把“客服邊界”一點點拉清楚
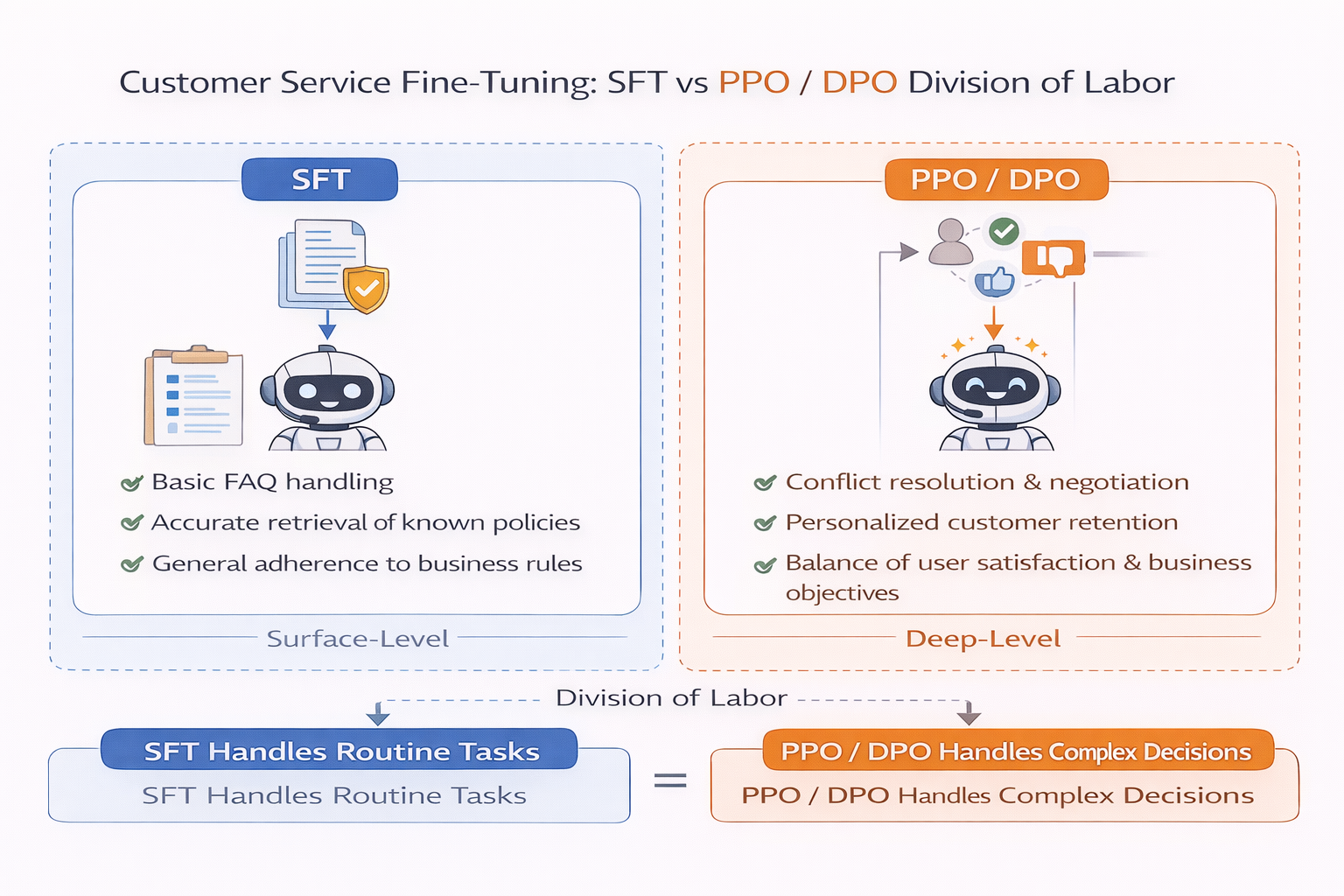
客服微調中 SFT 與 PPO/DPO 分工示意圖
一個真實的工程經驗:客服大模型一定要“允許它説不知道”
這是我在多個項目裏反覆驗證過的一點。
如果你的客服大模型從來不説不知道,那它遲早會出問題。
人類客服在面對複雜或高風險問題時,説“不確定”“需要確認”“我幫你轉人工”,是一種非常成熟的職業行為。但模型如果沒有被訓練過這種行為,會天然傾向於“盡力回答”。
所以在客服微調數據中,我會刻意保留大量“拒答樣本”和“升級樣本”,並且在對齊階段給它們非常明確的正反饋。
一個被忽略的事實:客服大模型的成功標準,從來不是“命中率”
很多團隊在評估客服大模型時,依然沿用問答系統的指標:
- 回答是否正確
- 是否命中知識
- 用户是否得到答案
但在客服系統裏,更重要的指標往往是:
- 投訴率有沒有下降
- 人工介入是否更合理
- 高風險問題是否被攔截
- 用户情緒是否被有效緩解
如果你只盯着“答得準不準”,那你很可能會把一個高風險模型推上線。
實踐層面的建議:別一開始就想“完全自動化”
這是最後一個我特別想強調的點。
很多客服大模型項目失敗,並不是因為技術不行,而是因為目標定得太激進。一上來就想“完全替代人工”,反而讓模型承受了它根本不該承擔的責任。
更現實、也更安全的路徑,往往是:
- 先做輔助型客服
- 再做低風險自動回覆
- 逐步擴大模型的決策範圍
在這個過程中,微調和對齊不是一次性任務,而是一個持續過程。
在這種逐步演進的節奏下,能夠快速驗證不同微調和對齊策略、反覆對比模型行為變化的工具,會比“一次性大工程”更適合大多數團隊。像 LLaMA-Factory online 這種在線方式,在早期階段能明顯降低試錯成本。
總結:客服不是技術問題,而是邊界問題
寫到這裏,其實可以很明確地説一句:
客服大模型失敗的原因,90% 都不是模型不夠強,而是你讓它做了不該做的事。
一旦你把客服從“問答系統”裏抽離出來,開始認真對待它的風險、邊界和策略,你會發現很多之前看起來很難的問題,其實都有解法。
而真正難的,從來不是算法,而是你是否願意承認:
客服大模型,永遠不只是一個會回答問題的模型。