

訓練跑通了,並不意味着你“完成了微調”
如果你已經做過幾次大模型微調,很可能會有一種奇怪的感覺。
訓練這件事,其實沒那麼難。
數據準備好,參數配一配,模型一跑,loss 往下走,看起來一切都很正常。只要環境不炸,顯存夠用,大多數人都能把訓練流程跑完。
但等你真正停下來,準備回答一個問題時,事情就開始變得不那麼確定了。
“這次微調,到底算不算成功?”
模型是不是更好了?
好在哪裏?
這種“好”是不是穩定的?
會不會只是在你測試的那幾個問題上湊巧表現不錯?
你會發現,這些問題遠比“訓練能不能跑”要難回答得多。
也正是在這裏,很多微調項目開始失控:
- 要麼過早自信上線,要麼永遠陷在“再調一輪看看”的循環裏。
一個必須先明確的前提:訓練是確定的,評估是不確定的
這是理解“為什麼評估更難”的關鍵。
訓練這件事,本質上是一個確定性很強的過程。
你給定模型、數據、參數,訓練過程要做的事情其實非常明確:最小化一個目標函數。
只要代碼沒 bug、數值沒爆炸,訓練就一定會“有結果”。
loss 會降,參數會更新,checkpoint 會生成。
但評估完全不是這樣。
評估面對的是一個模糊的問題:
“你想要的‘好’,到底是什麼?”
這個問題,在大多數微調項目開始時,甚至是沒有被認真想清楚的。
為什麼 loss 在評估裏幾乎派不上用場
很多人第一次微調時,會下意識把 loss 當成主要參考指標。
這其實非常自然,因為 loss 是你唯一能立刻看到、而且是數值化的信號。
但問題在於,loss 回答的從來不是你真正關心的問題。
loss 只在回答一件事:
模型在多大程度上擬合了你給它的訓練樣本。
它不關心模型在真實輸入上的表現,
不關心模型有沒有學到你示例裏的“潛台詞”,
更不關心模型是不是開始在不該自信的時候亂説。
在微調階段,loss 更多像一個訓練健康度指標,而不是效果指標。
loss 能覆蓋的信息範圍示意圖
評估真正難的地方:你很難定義“什麼叫變好了”
這是評估比訓練難的第一個根本原因。
在訓練階段,你的目標函數是清晰的;
但在評估階段,你面對的是一種非常複雜的判斷。
舉個很常見的例子:
你希望模型“回答更專業一點”。
那什麼叫“更專業”?
是用詞更正式?
是結構更清晰?
還是少説廢話、多給結論?
這些標準,幾乎不可能被壓縮成一個簡單指標。
這也是為什麼在很多項目裏,評估討論到最後,都會回到一句話:
“感覺好像是比之前好了一點,但也説不太清楚。”
這不是你不專業,而是問題本身就不簡單。
第二個難點:評估面對的永遠是“分佈外世界”
訓練時,你看到的是訓練數據;
評估時,你面對的是未來真實用户的問題。
這兩者之間,幾乎一定存在分佈差異。
哪怕你準備了驗證集,它也往往和訓練集來自同一批數據來源,同一種表達習慣。
而真實用户的問題,通常更加隨意、更不完整、更不可預測。
於是你會看到一個非常經典的現象:
驗證集表現不錯,真實使用一塌糊塗。
這不是模型“突然變壞了”,而是你評估時看的世界,本來就不是真實世界。
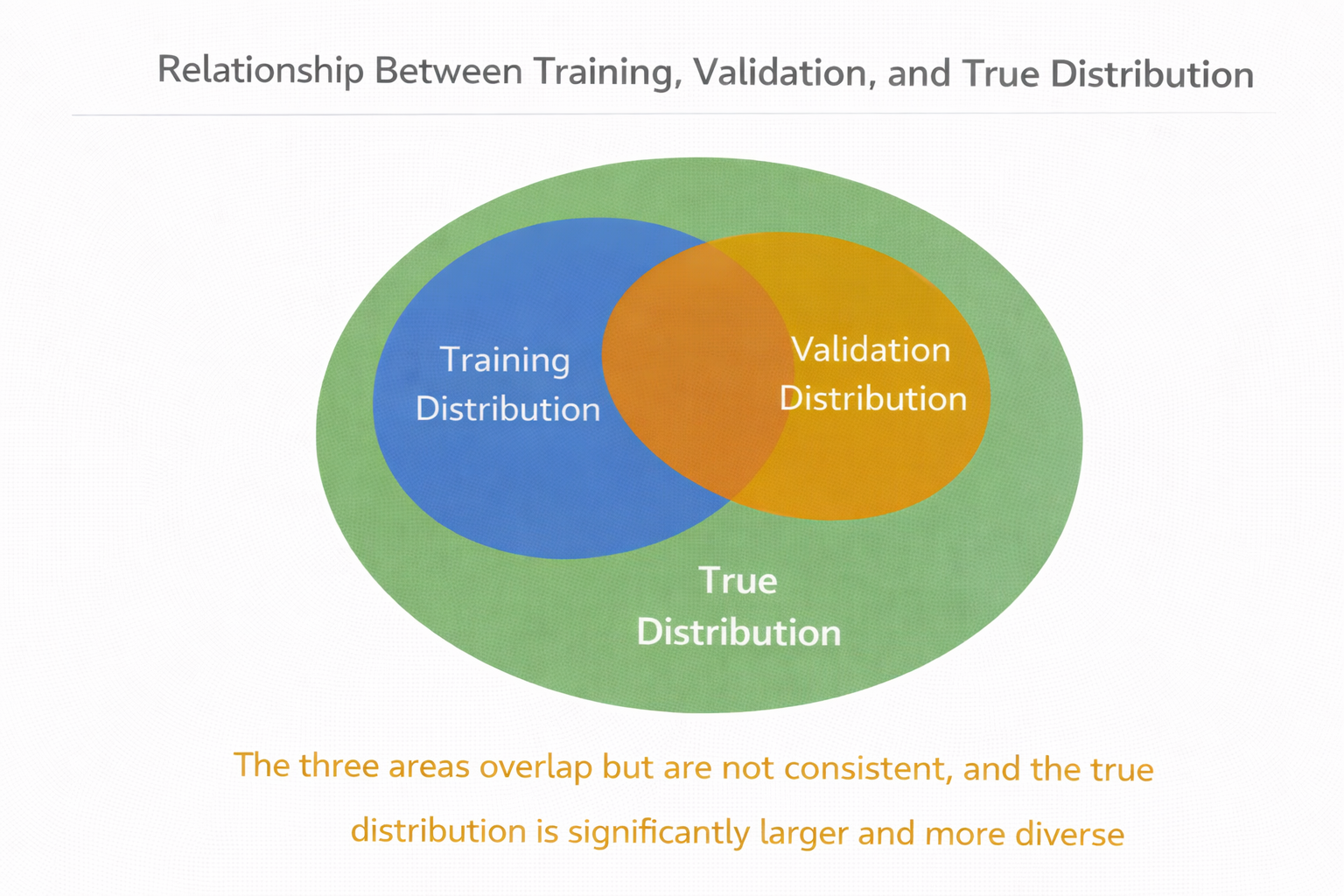
訓練分佈 / 驗證分佈 / 真實分佈的關係圖
為什麼“人工評估”不可替代,但又如此痛苦
當 loss 不再可靠,自動指標又很有限,最終你一定會走向人工評估。
但人工評估恰恰是很多工程師最抗拒的部分。
原因很現實:
- 慢
- 主觀
- 難復現
- 很難規模化
但你不得不承認,在微調這種高度依賴目標定義的任務裏,人工判斷本身就是最核心的信息來源。
你想讓模型更“謹慎”,
更“像客服”,
更“不像胡説八道”,
這些東西,本質上就只能由人來判斷。
一個現實問題:人工評估為什麼經常變成“拍腦袋”
很多團隊做過人工評估,但效果並不好,原因通常不是“人不專業”,而是流程設計有問題。
最常見的幾個問題是:
- 沒有固定對照問題
- 每次看的問題都不一樣
- 評估標準不統一
- 評估結論無法沉澱
結果就是:
每一輪評估都像一次新的討論,無法積累共識。
一個更可執行的做法:固定對照集 + 對比輸出
在工程實踐中,我更推薦一種非常樸素、但可持續的方法。
準備一小批你非常熟悉的問題,數量不需要多,十幾到幾十個就夠。
這些問題應該覆蓋你最關心的風險點、邊界點和核心場景。
每一輪微調後,用完全相同的輸入,對比模型前後的輸出。
你不需要一開始就給分數,只需要回答幾個問題:
- 這次輸出在哪些地方變了?
- 這些變化是不是我想要的?
- 有沒有明顯的副作用?
這種方式雖然“笨”,但信息密度極高。
對照評估流程示意圖
什麼時候“量化評估”才真正有意義
這並不是否定量化評估,而是要把它放在合適的位置。
量化指標在以下幾種情況下,才會真正有價值:
- 目標已經被明確拆解
- 評估維度相對單一
- 你關心的是趨勢,而不是絕對值
比如在偏好排序、拒答率、結構合規率等場景中,量化指標就非常有用。
但在模型行為仍然模糊、目標尚未收斂的階段,過早追求量化,只會製造假象。
一個簡單但實用的半自動評估示例
下面是一個非常簡單的示例,展示如何在人工評估基礎上,做一點輕量的統計輔助。
questions = load_eval_questions()
before = run_model(base_model, questions)
after = run_model(tuned_model, questions)
def contains_refusal(text):
keywords = ["無法", "不能", "不確定", "建議聯繫人工"]
return any(k in text for k in keywords)
refusal_before = sum(contains_refusal(x) for x in before)
refusal_after = sum(contains_refusal(x) for x in after)
print("Refusal rate before:", refusal_before / len(questions))
print("Refusal rate after:", refusal_after / len(questions))
這段代碼並不能告訴你模型“好不好”,
但它能幫你驗證一個非常具體的問題:
你期望的行為,有沒有在整體上變得更常見。
為什麼評估幾乎一定是一個“反覆推翻自己的過程”
這是評估比訓練更讓人痛苦的地方。
訓練一旦跑完,結果就在那裏;
但評估過程中,你很可能會不斷髮現:
- 之前定義的“好”不夠準確
- 之前關注的指標並不重要
- 模型的副作用被低估了
評估本身,會不斷逼着你修正目標。
而這,恰恰是很多團隊不願意面對的事情。
一個現實建議:別指望一次評估就“蓋棺定論”
評估不是一個“通過 / 不通過”的開關。
它更像一個不斷校準認知的過程。
你應該期待的,不是一個完美結論,而是:
你對模型行為的理解越來越清楚。
在需要頻繁對比不同微調版本、快速回放輸出變化時,使用 LLaMA-Factory online 這類工具來縮短驗證路徑,往往能把評估成本壓到一個可接受的範圍。
總結:評估之所以更難,是因為它逼你面對“你到底想要什麼”
寫到這裏,其實答案已經很清楚了。
訓練難,是工程問題;
評估難,是認知問題。
評估要求你不斷追問:
- 你真正關心的是什麼?
- 你願意為哪些變化付出代價?
- 哪些“看起來更好”的東西,其實並不重要?
也正因為如此,評估才是微調裏最有價值、也最不可替代的一環。