

RAG 最常見的失敗,並不是“沒效果”,而是“用錯地方”
如果你觀察過一段時間大模型落地項目,會發現一個非常有意思的現象。
很多團隊做 RAG,並不是因為認真分析過需求,
而是因為:
“大家都在用 RAG。”
於是 RAG 成了一種默認選項:
- 有知識問題 → RAG
- 模型不懂 → RAG
- 業務效果不好 → 再加一層 RAG
結果就是:
系統越來越複雜,
效果卻始終説不清楚“好在哪裏”。
後來你會發現一個非常扎心的事實:
RAG 不是沒用,而是被用在了大量不適合它的地方。
一個必須先講清楚的前提:RAG 解決的是“信息獲取”,不是“能力提升”
這是理解“RAG 適合什麼、不適合什麼”的第一把鑰匙。
RAG 的核心能力只有一件事:
在模型生成之前,把相關信息取出來,交給模型閲讀。
它並不會:
- 提升模型的推理能力
- 改變模型的價值判斷
- 讓模型學會新技能
RAG 能做的,只是把模型“看不到的信息”,變成“看得到的信息”。
一旦你把 RAG 當成“能力增強工具”,很多決策從一開始就錯了。
RAG 非常適合的第一類場景:穩定但經常變化的知識
這是 RAG 最經典、也最成功的應用場景。
比如:
- 產品文檔
- 內部流程説明
- 政策條款
- 技術規範
這些知識有幾個共同特點: - 內容本身是確定的
- 更新頻率不低
- 不適合寫死在模型裏
如果你用微調來解決這類問題,你會立刻遇到幾個現實問題: - 每次更新都要重新訓練
- 歷史版本難以回溯
- 風險極高(模型記住舊規則)
而 RAG 天然適合這種場景:
你只需要更新文檔或索引,模型本身無需變化。
知識更新頻率 vs 技術方案選擇對比圖
RAG 非常適合的第二類場景:可解釋性要求高的系統
在很多業務裏,“為什麼這麼答”和“答對了”同樣重要。
比如:
- 企業內部系統
- 法律 / 合規輔助
- 運維 / 排障工具
在這些場景中,你往往需要: - 告訴用户信息來源
- 追溯引用依據
- 在出問題時能快速定位責任
RAG 的一個巨大優勢在於:
答案是“有出處的”。
哪怕模型回答得不完美,你也可以清楚地知道:
它是基於哪些材料生成的。
這是純生成模型或深度微調很難做到的。
RAG 非常適合的第三類場景:長尾問題密集的知識型應用
如果你的系統面對的是:
- 問題分佈極其分散
- 單個問題出現頻率不高
- 但整體知識面很廣
那 RAG 幾乎是必選方案。
典型例子包括: - 內部知識助手
- 技術支持系統
- 運維知識庫
在這些場景中,用微調去“覆蓋所有問題”幾乎不可能。
而 RAG 可以通過檢索,把長尾問題“變成已知問題”。
RAG 適合的第四類場景:你還不確定需求會怎麼變
這是一個經常被忽略,但非常現實的點。
在很多項目早期,你其實並不清楚:
- 用户會問什麼
- 哪些問題最重要
- 哪些信息最常被用到
在這種不確定階段,RAG 的低承諾成本非常重要。
你可以: - 快速增刪文檔
- 調整切分和索引
- 改檢索策略
而不用動模型本身。
從工程管理角度看,RAG 非常適合作為探索期方案。
探索期 vs 穩定期的技術選型對比
RAG 明顯不適合的第一類場景:強邏輯推理任務
這是一個非常常見、但經常被誤判的地方。
如果你的問題本質是:
- 多步推理
- 條件組合
- 狀態演化
那麼 RAG 能提供的幫助非常有限。
RAG 可以把相關信息取出來,
但它無法替模型完成複雜推理。
比如: - 複雜規則判斷
- 多條件決策
- 動態策略計算
在這些場景中,你更需要的是: - 明確的規則系統
- 專用算法
- 或直接人工介入
而不是一層又一層 RAG。
RAG 不適合的第二類場景:答案高度依賴“隱含經驗”
有些問題,人類能答得很好,但很難寫成文檔。
比如:
- 經驗判斷
- 語境理解
- 潛規則
如果答案高度依賴“人怎麼想”,而不是“文檔怎麼寫”,
那 RAG 很可能會讓模型輸出看起來很像答案,但實際上很危險的內容。
因為 RAG 給模型的是“文本”,而不是“經驗”。
RAG 不適合的第三類場景:對實時性要求極高的系統
RAG 的每一步,都會引入額外延遲:
- embedding
- 檢索
- rerank
- 上下文拼接
如果你的系統對響應時間極其敏感,
比如毫秒級交易、實時控制系統,
RAG 往往不是合適的選擇。
即使你能把延遲壓下來,
複雜度和穩定性成本也非常高。
RAG 不適合的第四類場景:你需要“非常確定的輸出”
這是很多人容易忽略的一點。
RAG 本質上是“概率系統 + 檢索系統”的組合。
哪怕檢索結果相同,
模型的生成結果也可能有差異。
如果你的業務要求的是:
- 輸出高度一致
- 可預測
- 可形式化驗證
那 RAG 往往不是最安全的方案。
在這類場景中,
規則系統或結構化查詢,往往更可靠。
一個非常實用的判斷方法:RAG 前三問
在決定是否使用 RAG 之前,我通常會先問三個問題。
第一:
問題的核心,是“不知道信息”,還是“不會處理信息”?
如果是前者,RAG 很合適;
如果是後者,RAG 基本幫不上忙。
第二:
答案是否可以清晰地寫成文檔?
如果答案本身寫不清楚,RAG 只會放大混亂。
第三:
出錯的代價有多大?
如果出錯成本很高,而你又無法完全控制上下文質量,
那 RAG 風險很高。
一個簡單的代碼示例:展示 RAG 的“能力邊界”
下面這段代碼不是為了教你怎麼寫 RAG,
而是用來説明:RAG 只能基於檢索內容發揮。
context = """
退款規則:
- 支付寶:1-3 個工作日到賬
- 銀行卡:3-7 個工作日到賬
"""
question = "如果用户在節假日退款,什麼時候到賬?"
prompt = f"""
請根據以下信息回答問題:
{context}
問題:{question}
"""
# 模型只能在給定 context 內推斷
在這個例子裏,
模型不可能“知道”節假日如何處理,
因為 context 里根本沒有這條信息。
你再大的模型,結果也不會更“正確”。
為什麼很多 RAG 項目,看起來“什麼都能答一點”
這是一個非常危險的信號。
當你發現一個 RAG 系統:
- 什麼問題都敢答
- 回答都很流暢
- 但你又不太敢完全相信
那往往意味着:
RAG 被用在了不適合它的地方。
模型開始用語言能力,去彌補信息缺失,
而不是用檢索結果支撐回答。
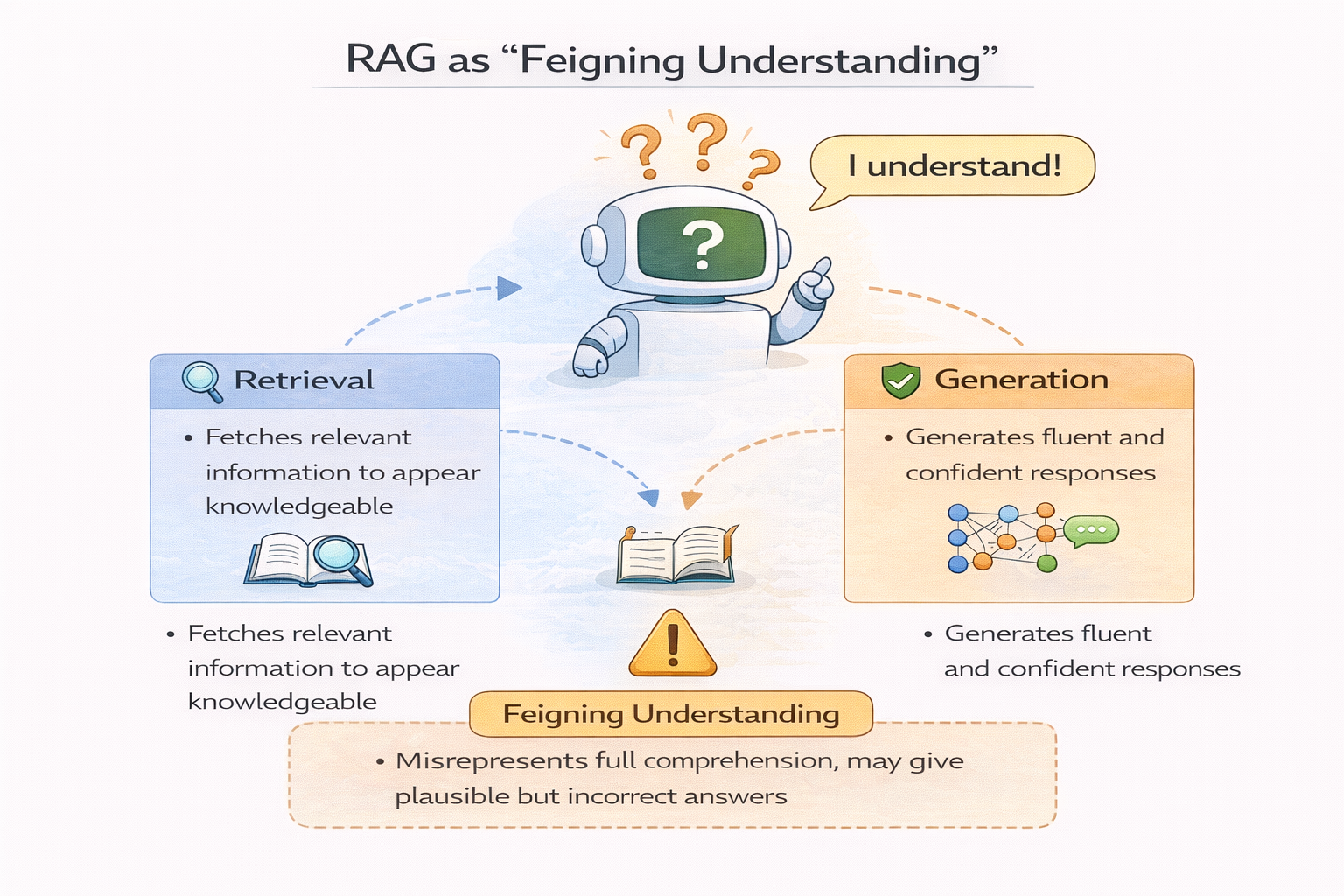
RAG 退化為“裝懂”的示意圖
一個現實建議:RAG 不是默認選項,而是“被選擇的方案”
成熟的系統設計裏,RAG 不應該是默認開啓的。
它更像是:
在你確認“問題本質是信息獲取”之後,
才被引入的一種解決方案。
否則,你會不知不覺地,把大量不適合的問題,
塞進一個不適合它的系統裏。
工程實踐中的一個常見組合思路
在真實項目中,一個更健康的架構往往是:
- 規則系統:處理確定性強的問題
- RAG:處理知識檢索型問題
- 模型生成:處理表達和總結
而不是“所有問題都先過 RAG”。
在探索階段,RAG 更適合“先小規模試”
RAG 的工程成本,往往被低估。
- 切分策略
- 檢索質量
- 評估方式
- 維護成本
這些都不是一次性工作。
在探索 RAG 是否適合當前業務時,先用 LLaMA-Factory online 這類工具快速驗證不同 RAG 方案、觀察真實效果,再決定是否大規模投入,會比一開始就自建複雜系統更安全。
總結:RAG 適合解決“找得到就能答”的問題
如果要用一句話總結 RAG 的適用邊界,那就是:
RAG 適合解決“只要把信息找對,模型就能答好”的問題。
一旦問題超出了這個邊界,
RAG 不但幫不上忙,
還可能讓系統看起來“更聰明、但更危險”。
真正成熟的使用方式,
不是問“能不能用 RAG”,
而是問:
“這個問題,本質上是不是一個檢索問題?”