

RAG 真正讓人頭疼的地方,從來不是“搭不起來”
如果你已經做過一段時間 RAG,大概率會有一種非常熟悉的感覺:
系統是能跑的,流程也是完整的,embedding 用的也不差,向量庫、召回、rerank 該有的都有,但整體效果始終差點意思。
有時候是召回的內容看起來“擦邊”,
有時候是答案明明就在文檔裏,模型卻像沒看到,
還有時候,模型引用了一堆內容,但就是沒真正解決用户的問題。
很多人第一反應是換 embedding 模型、加 reranker、堆上下文窗口,甚至懷疑是不是模型本身太弱。但在真實項目裏,我越來越確定一件事:RAG 的問題,絕大多數並不出在模型上,而是出在文檔切分上。
切分這件事,太容易被低估了。
它看起來不像模型那麼“高大上”,甚至很多教程裏一筆帶過,但它卻決定了 RAG 系統能不能真正理解你的知識。
一個非常現實的事實:RAG 本質上是“先切碎,再找回”
在討論切分策略之前,有必要先把 RAG 的工作方式説清楚。
不管你的 RAG 架構多複雜,本質流程都繞不開這幾步:
- 原始文檔 → 切分成 chunk → embedding → 相似度搜索 → 拼上下文 → 交給大模型生成答案。
也就是説,從模型的視角來看,它從來沒有見過完整文檔,它看到的永遠只是你提前切好的碎片。
這件事如果你不刻意去想,很容易忽略。但一旦你意識到這一點,很多 RAG 的“怪現象”就説得通了。
模型答不上來,有可能不是因為模型不懂,而是因為你切出來的 chunk,本身就無法支撐模型理解問題。

原始文檔 → chunk → embedding → 檢索 → 生成的整體流程示意圖
為什麼大多數 RAG 項目一開始都會“切錯”
我見過太多團隊,一開始做切分時,採用的都是一種非常“工程直覺”的方式:
按固定長度切,比如 500 token 一段,100 token overlap。
這種方式本身不能説錯,它甚至是很多教程裏的默認方案。但問題在於,它只考慮了模型的限制,卻完全沒有考慮內容本身的結構。
文檔不是隨機 token 的集合,而是有語義、有層次、有上下文依賴的。
當你用固定長度去切一個本來有結構的內容時,很容易出現幾種情況:
- 一句話被切成兩半
- 一個定義和它的解釋被拆開
- 一個流程的前因後果落在不同 chunk 裏
這些 chunk 單獨拿出來 embedding,看起來都“有點像”,但實際上都不完整。
切分做錯時,RAG 會出現哪些典型症狀
很多人並不知道自己的切分有問題,只是感覺 RAG 不太好用。這裏我總結幾個非常典型的症狀,你可以對照看看自己有沒有遇到過。
最常見的一種情況是:召回的 chunk 看起來都相關,但沒有一個真正有用。
你點開看每一條,發現關鍵詞都對,但拼不出完整答案。
還有一種情況是:模型引用了文檔,但結論明顯不對。
你回頭去查原文,發現關鍵條件剛好被切到了另一個 chunk 裏。
更隱蔽的一種,是系統在小樣本測試時表現還行,一到真實用户場景就開始翻車。
這是因為真實用户的問題,往往比你測試時想得更復雜,對上下文依賴更強。
這些問題,很少是 embedding 模型的問題,幾乎都是切分階段就已經埋下了雷。
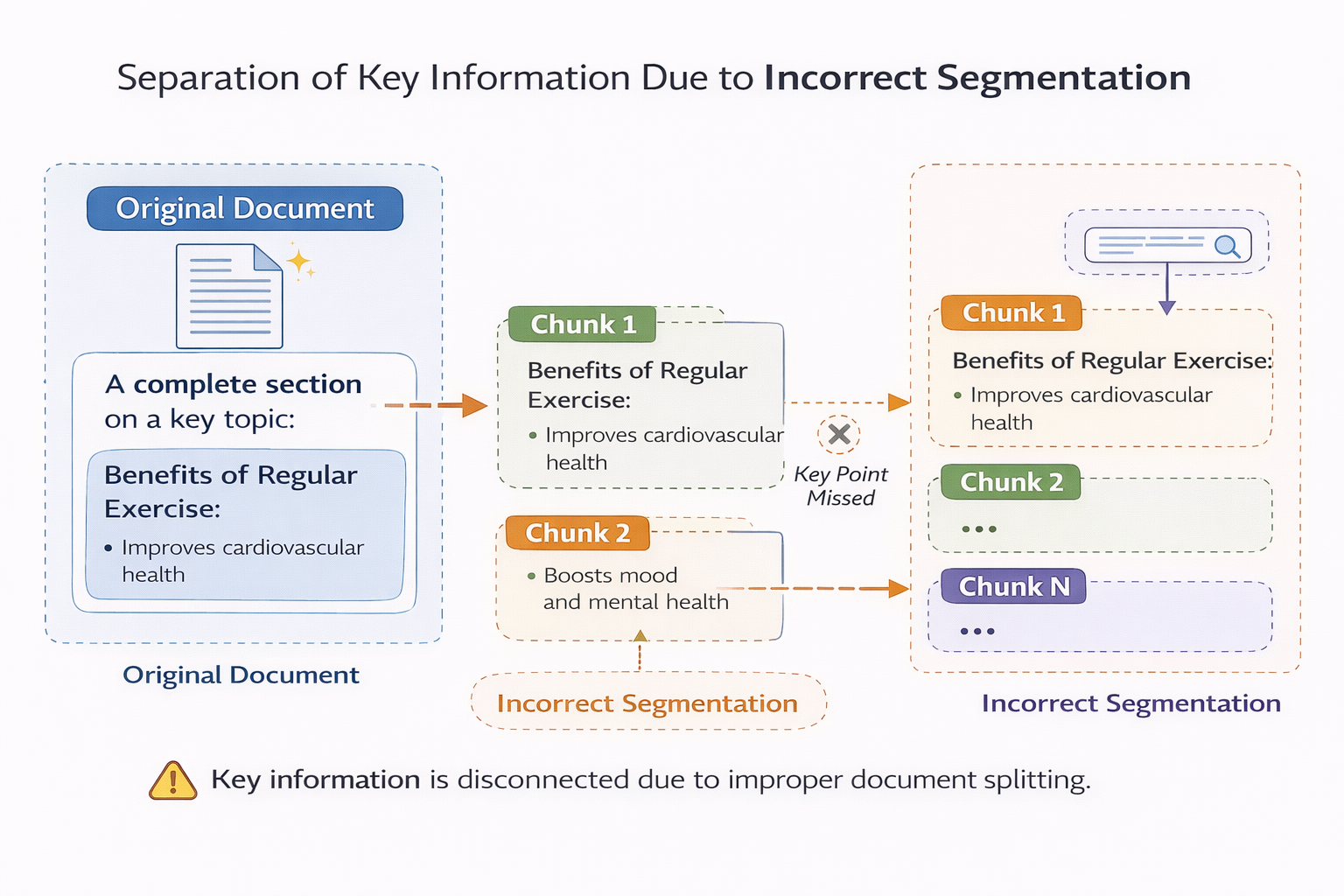
錯誤切分導致關鍵信息分離的示意圖
一個核心認知:chunk 不是“越小越好”
很多人在意識到切分重要之後,會走向另一個極端:
既然切分有問題,那我就切得更細。
這是一個非常自然的反應,但在 RAG 裏,chunk 過小同樣是災難。
chunk 太小,意味着每一段包含的語義信息非常有限。embedding 雖然能抓住關鍵詞相似度,但卻丟失了“為什麼”“在什麼條件下”“有什麼限制”這些關鍵信息。
結果就是:
- 召回數量上來了,噪聲也上來了。
- 模型看到了一堆“相關但不完整”的碎片,只能靠自己猜。
這也是為什麼你會看到一些 RAG 系統,召回結果看起來很多,但回答質量反而下降了。
真正有用的切分,必須尊重“語義完整性”
在我看來,好的切分策略,核心只有一個原則:
一個 chunk 本身,應該是“可以被人單獨讀懂的”。
這句話聽起來很樸素,但真正做到並不容易。
什麼叫“單獨讀懂”?
不是語法完整,而是語義完整。
讀完這一段,你至少能知道它在講什麼、解決什麼問題、有哪些前提。
這意味着,切分時你必須開始關心文檔結構,而不是隻看 token 數。
不同類型文檔,切分策略應該完全不同
一個非常常見的錯誤,是用同一種切分方式處理所有文檔。
技術文檔、產品説明、客服 FAQ、法律條款,這些內容的結構差異非常大,如果一刀切,效果幾乎一定不好。
技術文檔往往有明確的標題層級,非常適合按小節切分;
客服 FAQ 通常是一問一答,天然就是 chunk;
流程類文檔,最好把一個完整流程放在同一段裏;
而規範、條款類內容,則需要保留上下限制條件。
你越是尊重文檔本身的表達方式,RAG 的效果越容易提升。
overlap 不是“保險”,用不好反而是噪聲源
很多教程都會建議加 overlap,看起來很合理:
前後多留一點上下文,避免信息被切斷。
但在真實項目裏,overlap 用不好,反而會引入大量冗餘。
尤其是在 chunk 已經比較小的情況下,再加大量 overlap,等於在向量庫裏反覆存儲相似內容。
結果就是:相似度搜索時,返回一堆幾乎一模一樣的 chunk。
模型看到這些內容,並不會更清楚,反而更混亂。
我的經驗是,overlap 只在“語義邊界不清晰”的情況下有意義,而不是作為默認配置。
一個容易被忽略的問題:切分直接影響 rerank 的上限
很多人會把希望寄託在 reranker 上,覺得只要 rerank 足夠強,就能彌補前面的不足。
但現實是,rerank 只能在你提供的候選集合裏做選擇。
如果切分階段已經把語義切碎了,rerank 再強,也選不出完整答案。
你可以把 rerank 理解成一個“精修工具”,而不是“救命工具”。
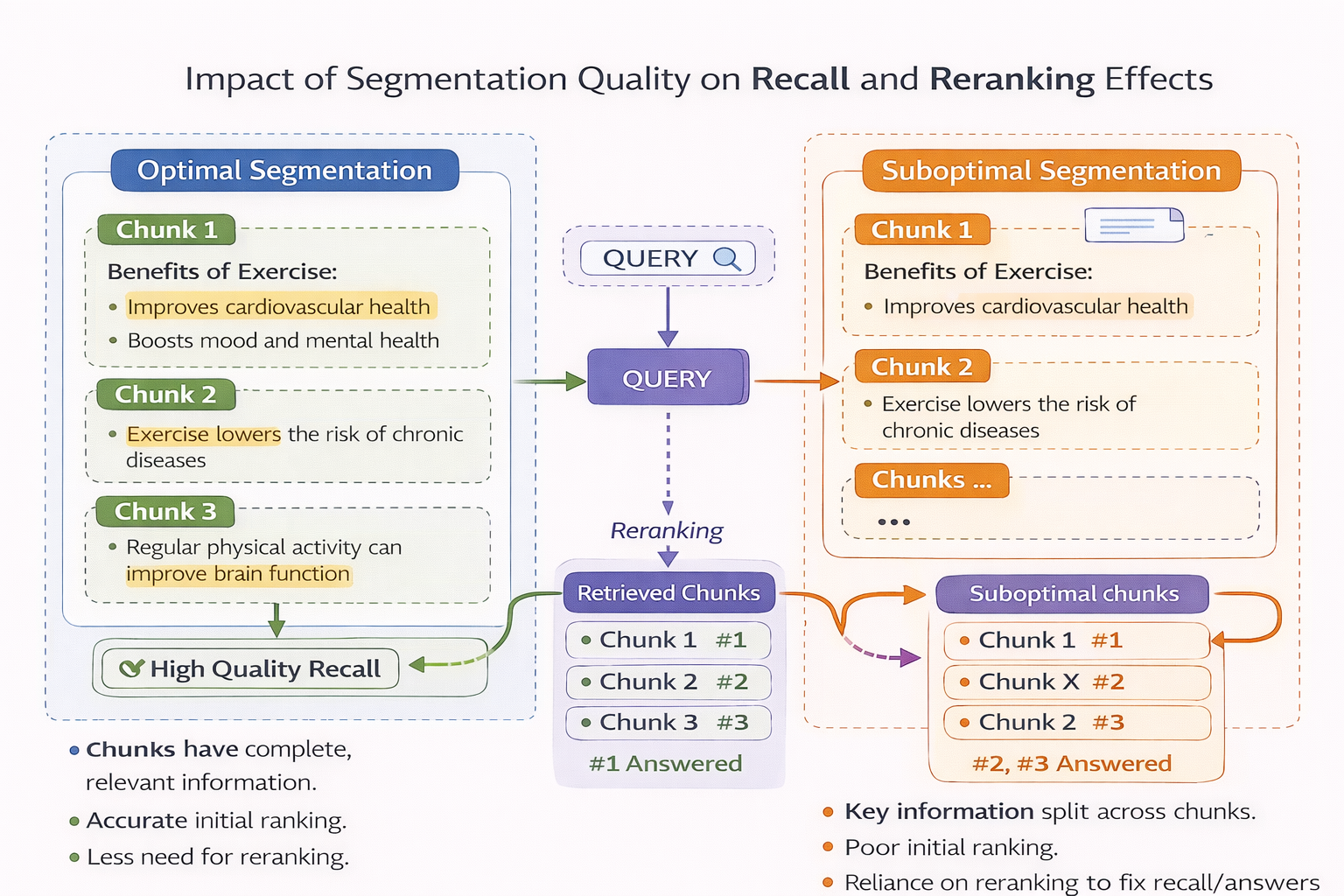
切分質量對召回與 rerank 效果的影響示意圖
一個實用的切分思路:先人為理解,再讓模型理解
在很多項目裏,我會建議團隊先做一件“看起來很笨”的事:
隨機抽幾篇文檔,手工切一版。
不是為了最終使用,而是為了建立對“什麼樣的 chunk 是有用的”的直覺。
當你自己能接受把某一段單獨交給別人閲讀時,它大概率也適合作為 RAG 的最小知識單元。
等這個感覺建立起來,再去用規則或者模型自動化,效果會好很多。
在驗證切分策略是否合理時,先通過在線方式快速嘗試不同切分方案,對比召回結果和生成效果,往往比一開始就全量入庫更省時間。像 LLaMA-Factory online 這類工具,在這個階段能明顯降低試錯成本。
如何判斷你的切分是不是在“拖後腿”
這裏有一個非常實用的小測試方法。
找幾個你非常確定答案就在文檔裏的問題,讓 RAG 系統只返回檢索結果,不生成答案。
然後你自己去看這些 chunk:
如果你作為人,讀完這些內容,依然很難回答問題,那問題基本就不在模型。
這個方法簡單粗暴,但幾乎百試百靈。
總結:切分不是細節,而是 RAG 的地基
很多團隊在做 RAG 時,把 80% 的精力放在模型、參數、架構上,卻只花 20% 的精力在切分上。
但現實往往正好相反:切分這種“看起來很基礎”的工作,決定了 RAG 能走多遠。
當你真正把切分當成一個需要反覆打磨的工程問題,而不是一次性配置,你會發現 RAG 的很多“玄學問題”,其實都有跡可循。
在這個過程中,能夠讓你快速驗證切分效果、反覆調整策略的工具,比追逐更大的模型更有價值。