

PPO 為何成了大模型微調“最後的底牌”?一篇真正能跑通的工程實戰指南
開篇:無數大模型,是怎麼被「一行 PPO 參數」訓廢的
如果你真正做過大模型微調,大概率經歷過這些瞬間:
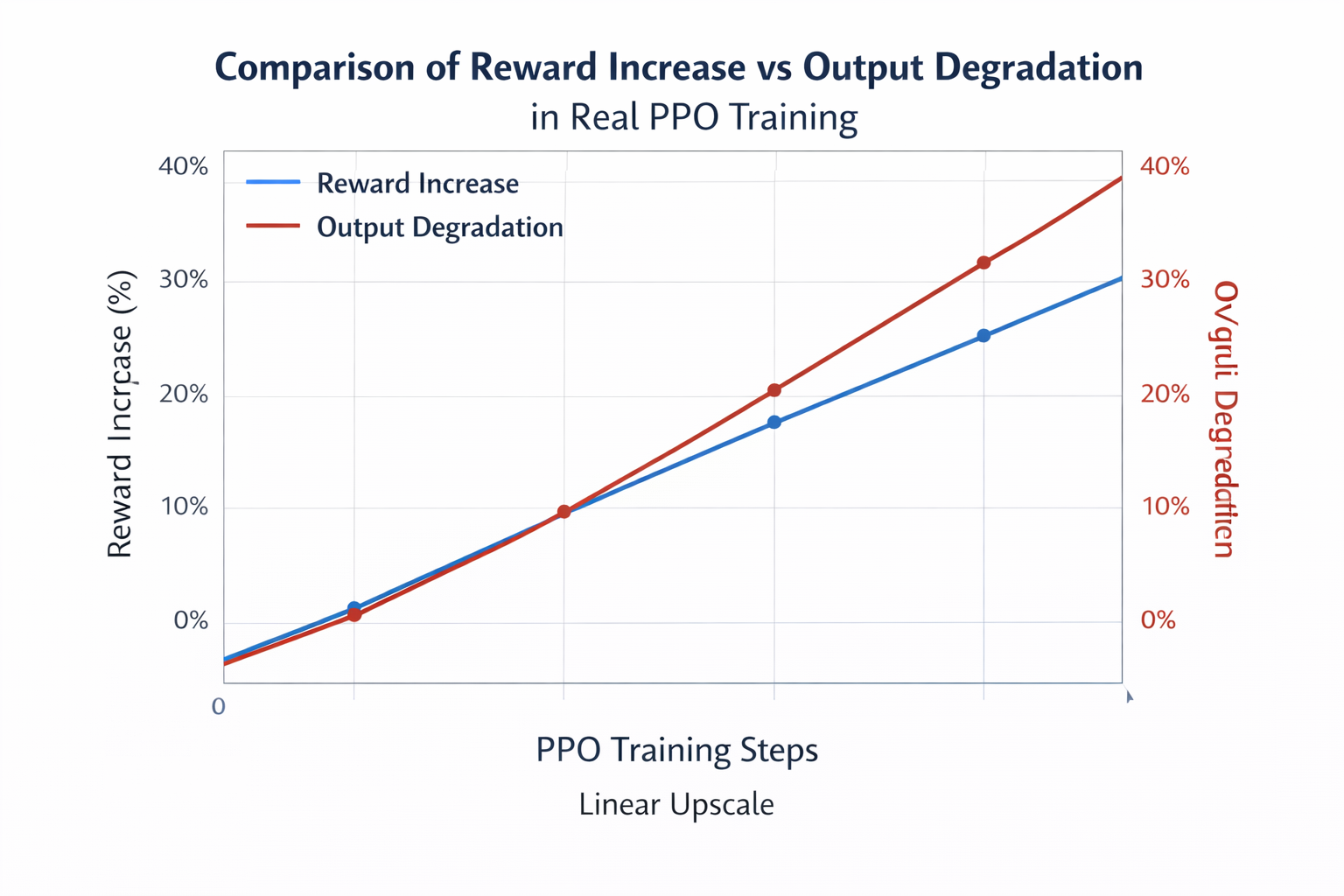
- reward 曲線一路狂飆,但模型開始胡説八道
- 模型突然學會“拍馬屁”,卻忘了基本常識
- 微調前還能正常回答,微調後像換了個“性格”
很多工程師第一次做 RLHF,都會天真地以為:
reward 提升 = 模型變好
直到 PPO 狠狠給你上了一課。
現實是:
大模型不是不能優化,而是不能被“猛優化”。
這也是為什麼,在幾乎所有成功落地的大模型對齊系統中,PPO 最終都成了“兜底方案”。
不是因為它最先進,而是因為——
它最不容易把模型訓崩。
為什麼「直接優化 reward」一定會出事?
先説一個反直覺的事實:
在大模型上,reward 提升越快,越危險。
原因很簡單。
語言模型的策略空間太大了。
在強化學習的數學世界裏,策略梯度聽起來很美:
最大化期望回報
但在真實工程裏,它等價於:
- 允許模型為了 reward 做任何事
- 包括鑽 reward model 的空子
- 包括破壞語言分佈本身
於是你會看到:
- 模型開始重複關鍵詞
- 回答越來越模板化
- 一切都“看起來很對”,但人類一看就不對勁
問題不在 reward,而在“變化幅度沒人管”。
PPO 的核心價值:它不是教模型更聰明,而是不讓模型亂來
理解 PPO,只需要記住一句話:
PPO 乾的不是“怎麼多學一點”,而是“每次只學一點點”。
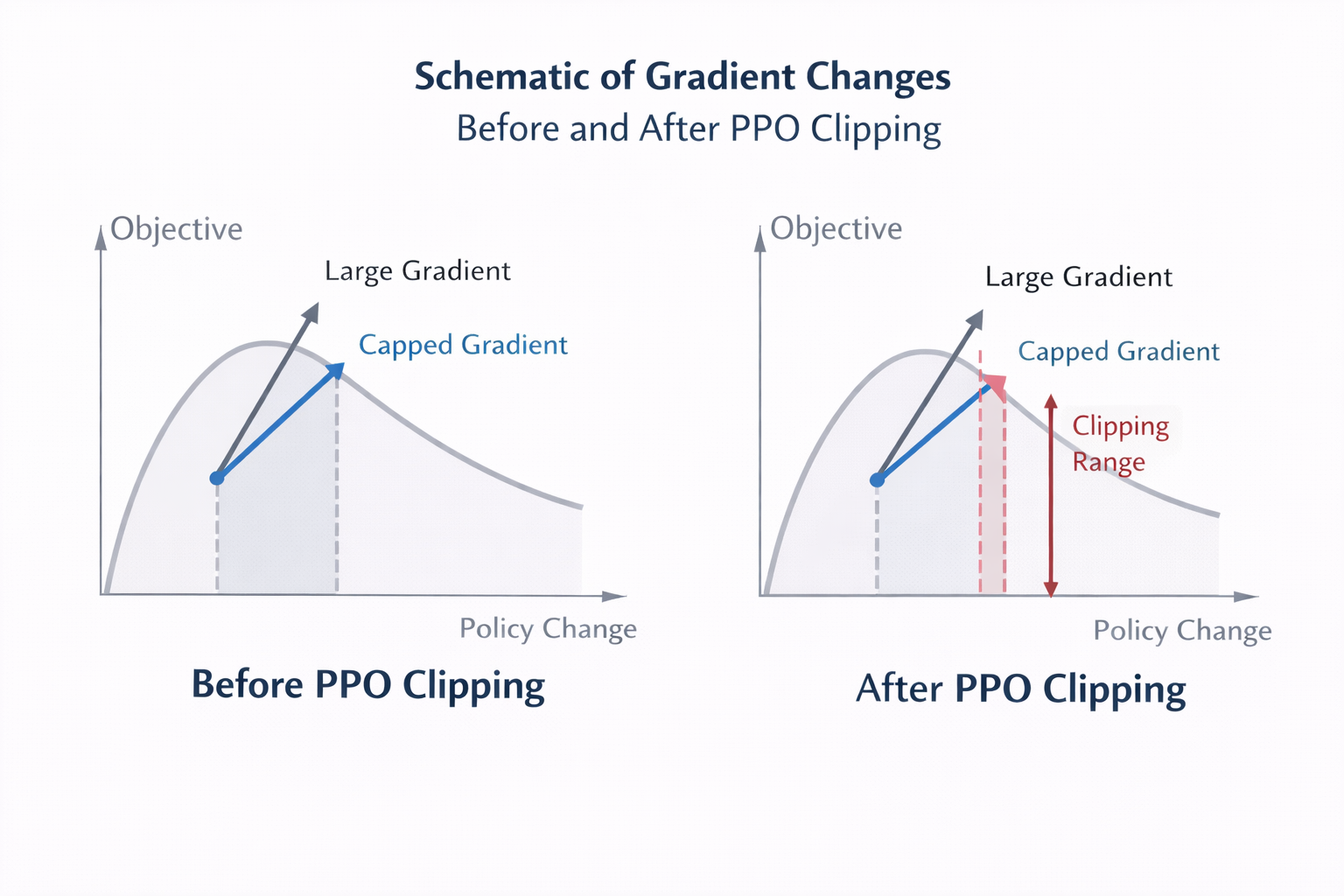
那個改變一切的「裁剪」
PPO 最核心的設計,是一個極其工程化的妥協:
- 你可以更新策略
- 但更新幅度不能太大
- 否則收益直接被砍掉
數學上,它通過一個 clipping 機制實現。
直覺版解釋是:
- 更新合理 → 正常給梯度
- 更新過猛 → 直接封頂
這就是為什麼 PPO 在大模型裏異常穩定。
為什麼 PPO 一定要搭配 KL?這是無數次事故換來的結論
如果你只記 PPO 的一個工程經驗,那就是這條:
不加 KL 的 PPO,遲早翻車。
KL 項的本質是:
- 告訴模型:
“你可以變好,但別變成另一個物種”
在 RLHF 場景中,KL 的作用比 reward 本身還重要。
KL 太小,模型會:
- 獎勵優先
- 語言能力退化
- 出現 reward hacking
KL 太大,模型會:
- 基本不動
- reward 提升極慢
真正成熟的系統,都會:
- 監控 KL 曲線
- 動態調節 KL 係數
PPO 在大模型裏的真實工作流(不是教科書版)
下面這部分,是工程師最該看的地方。
一輪真正可落地的 PPO 微調,長這樣。
起點不是 Base Model,而是 SFT
這是 90% 新手會犯的錯誤。
PPO 從來不是用來“教模型説話”的,而是:
- 在模型已經會説話的前提下
- 微調它的行為偏好
沒有 SFT 打底,PPO 只會放大噪聲。
Reward Model:寧可簡單,也別不穩定
一個現實結論:
一個穩定的 6B Reward Model
比一個不穩定的 70B 好得多
Reward Model 的一致性,遠比“聰不聰明”重要。
工程建議是:
- reward 分佈不要太極端
- 避免強規則一票否決
- 允許一定模糊空間
PPO 的一次完整訓練循環,其實沒那麼神秘
高度簡化後,PPO 在大模型裏的核心邏輯是:
responses = policy.generate(prompts)
reward = reward_model(responses)
kl_penalty = kl(policy, ref_policy)
total_reward = reward - beta * kl_penalty
advantage = total_reward - value_prediction
update_policy_with_ppo(advantage)
真正影響穩定性的,從來不是公式,而是:
- batch size
- PPO epoch 次數
- KL 係數策略
如果你不想一開始就陷入 PPO 工程細節地獄,LLaMA-Factory online 已經把 PPO + KL + Reward Model 的完整鏈路跑通,非常適合作為第一版對齊實驗環境。
PPO 參數怎麼調?這些是“訓崩模型”換來的經驗
一些非常值錢的經驗:
- PPO epoch 不宜多
- learning rate 比 SFT 更小
- KL 一定要監控趨勢
- value loss 不能忽略
正確順序是:
- 先讓 KL 穩住
- 再看 reward 是否持續上升
- 最後看輸出質量
如何判斷 PPO 微調是不是“真有效”?
如果你只看 reward,那你基本已經走偏了。
靠譜的評估方式一定包括:
- 固定 prompt 迴歸測試
- 人工抽樣評估
- 輸出多樣性檢查
你要問的不是:
reward 漲了嗎?
而是:
模型是不是還像個正常人?

寫在最後:PPO 會被淘汰嗎?
會,但不是現在。
DPO、IPO、各種“無 RL 對齊”方法正在快速發展,但在真實工程裏:
- PPO 依然最穩
- 最可控
- 最容易 debug
它不是最優雅的算法,
但是最像工程方案的算法。
如果你的目標是 穩住模型 + 快速驗證對齊策略,用 LLaMA-Factory online 跑通 PPO 全流程,再逐步精細化,是目前性價比極高的一條路徑。