

PPO 難,不是因為算法複雜,而是因為它在幹一件反直覺的事
如果你第一次接觸 PPO 微調,大概率會有一種強烈的挫敗感。
你可能已經:
- 看過 PPO 的算法圖
- 看過 reward / value / policy 的關係
- 甚至跑過一次訓練
但只要你認真問自己一個問題:
“PPO 到底在改模型的哪一部分?”
你很可能説不清楚。
你只知道:
- reward 在漲
- loss 在變
- 輸出風格在變化
但這些變化為什麼會發生,
發生在模型的哪一層邏輯上,
你並沒有一個“工程上能落地的解釋”。
而這,正是 PPO 最容易被誤解的地方。
一個必須先説清楚的前提:PPO 微調不是“能力學習”,而是“行為選擇”
這是理解 PPO 的第一道門檻。
在 SFT(監督微調)裏,模型學的是:
“在這個輸入下,正確答案長這樣。”
但 PPO 學的不是“正確答案”,
而是:
“在這個輸入下,我更應該選擇哪種回答方式。”
這是一個策略選擇問題,而不是知識學習問題。
PPO 從來不關心模型“會不會”,
它關心的是:
模型在多個可能回答中,選哪個更好。
SFT vs PPO 學習目標對比圖
為什麼 PPO 一定要引入“獎勵”,而不是直接算 loss
這是很多人第一次看 PPO 時最困惑的地方。
你會問:
既然已經有 loss,為什麼還要 reward?
原因非常簡單,但非常關鍵:
loss 只能衡量“像不像訓練數據”,
reward 才能衡量“你想不想要這種行為”。
在 PPO 裏,你想優化的往往是一些不可直接寫成標籤的東西:
- 回答是否謹慎
- 是否拒絕不該回答的問題
- 是否遵循偏好順序
- 是否避免某類風險
這些東西,很難通過“正確答案”來定義,
但可以通過“好 / 不好”來判斷。
於是,reward 出現了。
PPO 裏的核心角色,其實只有一個:Policy(策略)
在 PPO 的論文圖裏,你會看到很多模塊:
- Policy
- Reference
- Reward
- Value
但如果從工程視角看,
真正被更新的,只有 Policy。
Policy 本質上是什麼?
就是你正在微調的那個模型。
其它模塊,全部都是為了一件事服務的:
限制、引導、校正 Policy 的更新方向。
PPO 的核心問題:模型“想變”,但不能亂變
這是 PPO 名字裏“Proximal”的真正含義。
PPO 要解決的問題,不是:
“怎麼讓模型變得更符合 reward”
而是:
“怎麼讓模型在不偏離原模型太遠的情況下,
慢慢朝 reward 指向的方向移動”
為什麼要這樣?
因為在大模型裏,一次“走太遠”的更新,幾乎一定會帶來災難性副作用。
KL 約束:PPO 裏真正的“安全帶”
很多人第一次看到 PPO,會覺得 KL 是個“技術細節”。
但在大模型微調裏,
KL 約束是 PPO 能用的前提條件。
KL 在這裏乾的事情只有一件:
懲罰模型“和原來太不一樣”。
你可以把它理解成:
- reward 在踩油門
- KL 在踩剎車
沒有 reward,模型不知道往哪走;
沒有 KL,模型會直接衝出賽道。
reward 與 KL 的拉扯關係示意圖
為什麼 PPO 會“改風格”,卻不一定“變聰明”
這是很多人 PPO 調完後最困惑的點。
你會發現:
- 模型回答更謹慎了
- 更會拒絕問題
- 更符合偏好
- 但並沒有學到新知識
這是因為 PPO 的更新信號根本不是知識型的。
PPO 優化的是:
在已有能力空間中,
哪些輸出更值得被選擇。
它不會擴展模型的知識邊界,
只會重排“行為概率”。
PPO 訓練流程,用“工程語言”重新走一遍
下面我們不用論文語言,而用工程視角,重新走一遍 PPO。
第一步:Policy 生成多個候選輸出
responses = policy_model.generate(prompt, n=4)
這一步非常關鍵:
PPO 需要選擇空間,而不是單一答案。
第二步:Reward Model 給每個輸出打分
rewards = reward_model.score(prompt, responses)
注意:
reward 是相對信號,不是絕對真理。
第三步:計算 Policy 更新方向(帶 KL 約束)
loss = -reward + kl_coef * kl(policy, reference)
你可以把 PPO loss 理解成一句話:
“我想要高 reward,但不想和原模型差太遠。”
第四步:更新 Policy(而不是 Reward)
loss.backward()
optimizer.step()
整個 PPO 過程中,
唯一被訓練的,始終是 Policy。
為什麼 PPO 一定需要 Reference Model
很多人會問:
“既然我已經有 policy,為什麼還要 reference?”
答案是:
因為你需要一個‘不會動的錨點’。
Reference model 通常是:
- SFT 後的模型
- 或 PPO 初始模型
它的作用只有一個:
告訴你:你現在離“原來的自己”有多遠。
沒有 reference,KL 就失去了意義。
PPO 在大模型微調中,真正改變的是“概率分佈形狀”
這是一個非常關鍵、但極少被講清楚的點。
PPO 不會:
- 新增 token
- 改變詞表
- 加新知識
它只是在做一件事:
重新拉伸或壓縮輸出分佈。
某些回答方式概率被放大,
某些被壓低。
於是你看到的“行為變化”,
本質上是概率變化的結果。
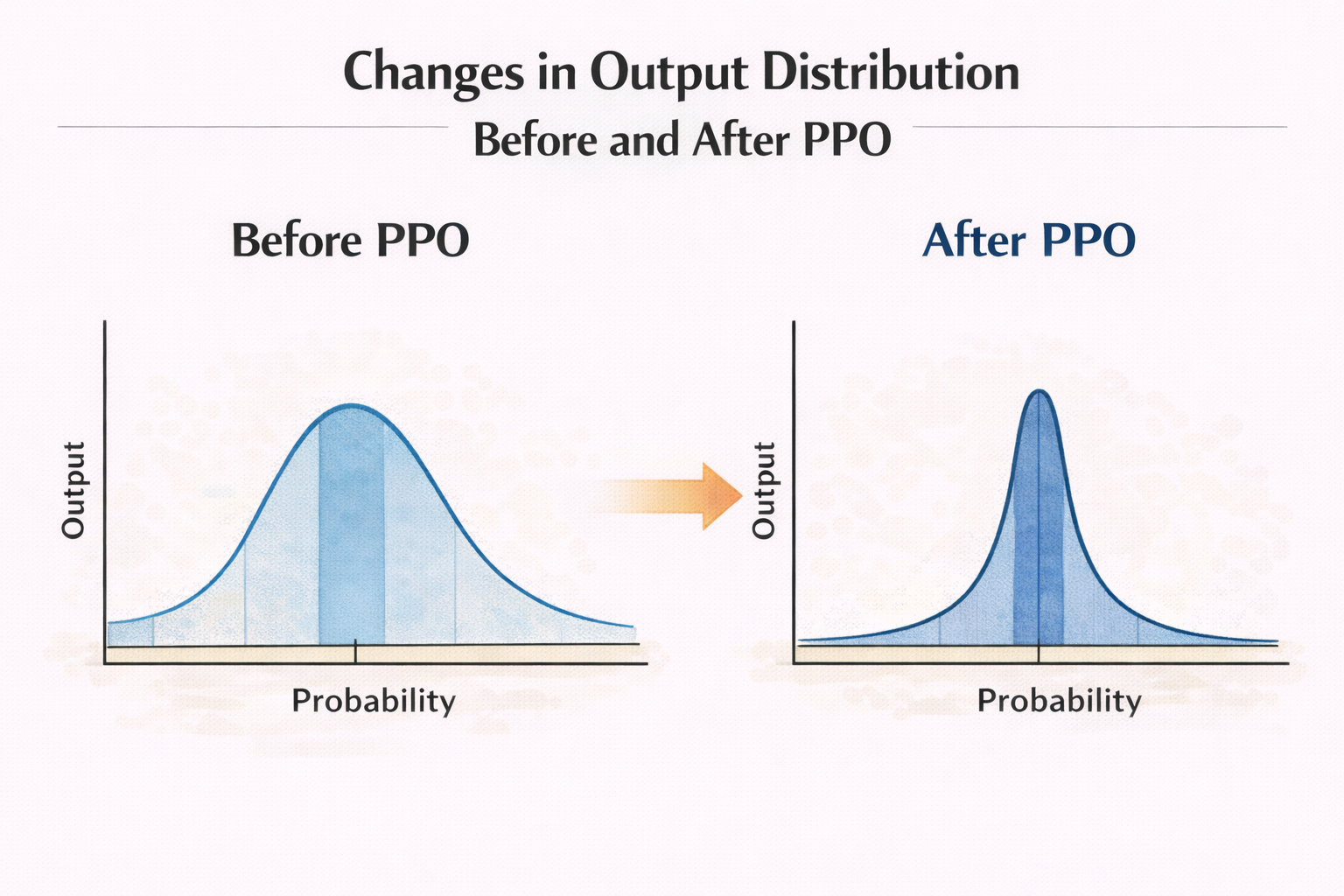
PPO 前後輸出分佈變化示意圖
為什麼 PPO 對“邊界行為”影響最大
你會發現一個現象:
PPO 調完後,
模型在“模糊、邊界、灰色問題”上的變化最大。
原因很簡單:
- 確定性強的問題,分佈本來就集中
- 邊界問題,分佈本來就發散
PPO 的 reward,恰恰最容易在這些地方起作用。
PPO 為什麼“風險高”,但又“不可替代”
PPO 風險高,是因為:
- reward 本身可能有偏
- 模型可能走捷徑
- 行為變化難以預測
但它又不可替代,是因為:
你無法用 SFT 教會模型“偏好”。
偏好,本質上是比較、權衡、取捨。
而 PPO,正是為這類問題而生的。
一個非常重要的結論:PPO 是“行為對齊工具”,不是“性能優化工具”
如果你把 PPO 用來:
- 提升準確率
- 學新知識
- 糾正事實錯誤
那你幾乎一定會失望。
但如果你用它來:
- 調整風格
- 強化安全邊界
- 對齊人類偏好
那 PPO 會非常強大。
另外一個很實際的點是:PPO 的“對齊效果”好不好,很多時候要靠對照評估集反覆測試、對比不同 checkpoint 的輸出風格。這個過程如果全靠本地腳本手動切版本,很容易把精力耗在搬運和對比上。用 LLaMA-Factory online 做快速版本對照和小規模迭代驗證,會比你一開始就重工程投入更容易把方向跑正。
總結:理解 PPO,關鍵不在算法,而在“你到底想改什麼”
寫到這裏,其實可以把整篇文章濃縮成一句話:
PPO 不是在教模型新東西,
而是在告訴模型:你已經會的東西里,哪種更值得選。
一旦你用“行為選擇”而不是“參數優化”來理解 PPO,
你會發現:
- reward 的意義清晰了
- KL 的必要性清晰了
- 風險從哪裏來,也清晰了
而這,正是後面所有 PPO 實戰、調參、評估、踩坑的基礎。