

顯存不夠,幾乎是每個微調項目的“入場儀式”
如果你做過大模型微調,那“顯存不夠”這四個字,你幾乎不可能陌生。
第一次跑,直接 OOM。
換個 batch size,再 OOM。
開 bf16,還是不夠。
關掉一些東西,終於能跑了,但速度慢得離譜。
很多人會在這個階段得出一個結論:
“是我顯卡不行。”
但當你真的開始拆解顯存使用之後,你會發現一個非常反直覺的事實:
大多數顯存,並不是被模型參數吃掉的。
而你之所以總感覺顯存不夠,往往是因為你根本不知道顯存是怎麼被花掉的。
一個必須先説清楚的事實:顯存不是“模型大小 × 2”
這是新手最常見、也最危險的一個誤解。
很多人心裏都有一筆非常粗糙的賬:
模型參數多少 GB,我有多少顯存,差不多就能跑。
但在真實訓練中,這個估算幾乎一定是錯的。
因為模型參數,只是顯存賬單裏最小的一項。

顯存構成的“賬單拆解圖”
顯存第一大户:激活(Activation),而且它非常“隱蔽”
很多人第一次被問到“顯存主要花在哪”,會下意識回答:
模型參數。
但在訓練階段,真正吃顯存的,往往是 activation。
activation 是什麼?
簡單説,就是模型前向計算過程中,每一層產生的中間結果,用來在反向傳播時算梯度。
關鍵在於兩點:
第一,activation 和 batch size 強相關
batch size 一大,activation 幾乎線性增長。
第二,activation 和模型深度強相關
層數越多,存的中間結果就越多。
所以你會看到一個非常典型的現象:
模型參數看起來不大,但一開訓練就 OOM。
不是模型“太大”,而是 activation 在默默吃顯存。
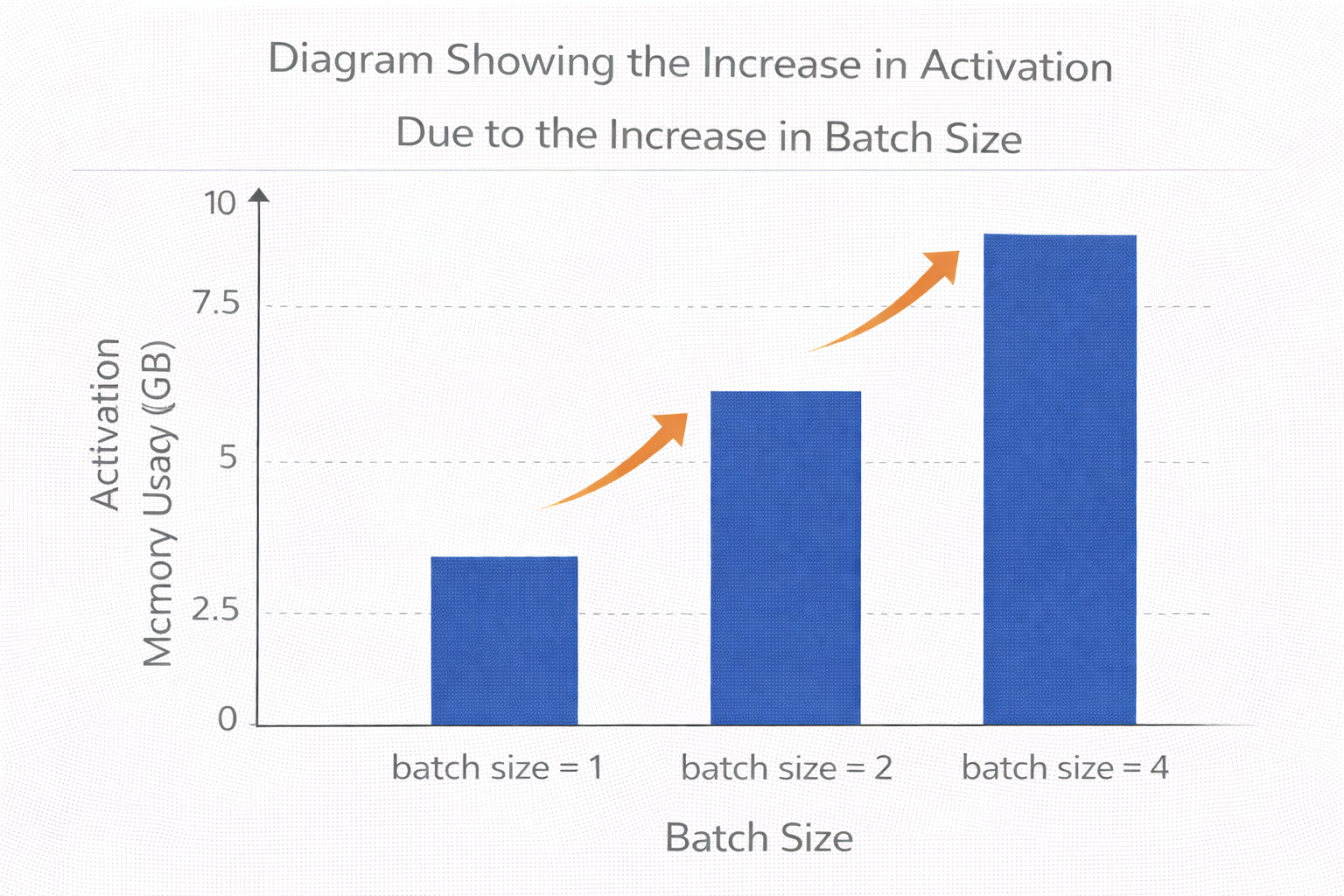
batch size 增加導致 activation 激增示意圖
第二大頭:優化器狀態,尤其是 Adam
如果你用的是 Adam 或 AdamW,那你幾乎一定低估了它的顯存消耗。
Adam 至少要為每一個可訓練參數,維護兩份額外狀態:
- 一份一階動量
- 一份二階動量
也就是説:
參數 × 3,才是 Adam 的真實顯存賬單。
在全參數微調裏,這個成本是災難性的;
在 LoRA 微調裏,它看起來“還好”,但依然不可忽視。
第三個被忽略的消耗:梯度本身
很多人以為梯度“算完就沒了”,但實際上,在反向傳播過程中,梯度也要完整存儲。
尤其是在沒有梯度累積、沒有清理緩存的情況下,梯度會和 activation 一起,佔據一大塊顯存。
這也是為什麼你會看到:
前向還好,
一到 backward 就直接炸顯存。
顯存殺手中的“隱形 Boss”:PyTorch 緩存與碎片化
這是很多人查了一天 nvidia-smi 都想不明白的問題。
你明明看到:
顯存用了 20GB,卡有 24GB,
但就是分配不了一個 1GB 的 tensor。
原因很簡單:
顯存碎片化。
PyTorch 會緩存顯存以加速後續分配,但這也意味着,顯存並不是一整塊連續空間。
你“看得到”的空閒,不等於“用得上”。
為什麼你“已經開了 bf16”,顯存還是不夠
很多人會覺得:
“我已經用 bf16 / fp16 了,應該很省顯存了。”
但半精度,只解決了一件事:
參數和部分激活的存儲大小。
它並沒有解決:
- activation 數量本身
- 優化器狀態數量
- 緩存和碎片化
所以 bf16 是“必要條件”,但絕不是“充分條件”。
gradient checkpointing:顯存的“以時間換空間”
這是最常見、也最有效的一種顯存優化方式。
gradient checkpointing 的核心思想非常樸素:
我不保存所有中間激活,需要時再算一遍。
這會明顯降低 activation 的顯存佔用,但代價是:
前向計算要重複做,訓練時間會變長。
下面是一段非常典型的開啓方式(示意):
model.gradient_checkpointing_enable()
這一行代碼,往往能直接救活一個“差一點就 OOM”的訓練。

checkpointing 前後顯存 vs 時間對比圖
梯度累積:你以為在調 batch,其實在拆賬單
當 batch size 太大顯存扛不住時,梯度累積是最常見的替代方案。
它的本質是:
把一個大 batch,拆成多個小 batch,梯度累加後再更新。
loss = loss / grad_accum_steps
loss.backward()
if step % grad_accum_steps == 0:
optimizer.step()
optimizer.zero_grad()
這樣做的好處是:
activation 顯存按“小 batch”算,
但優化效果近似“大 batch”。
壞處是:
- 訓練邏輯更復雜
- 調試更容易出錯
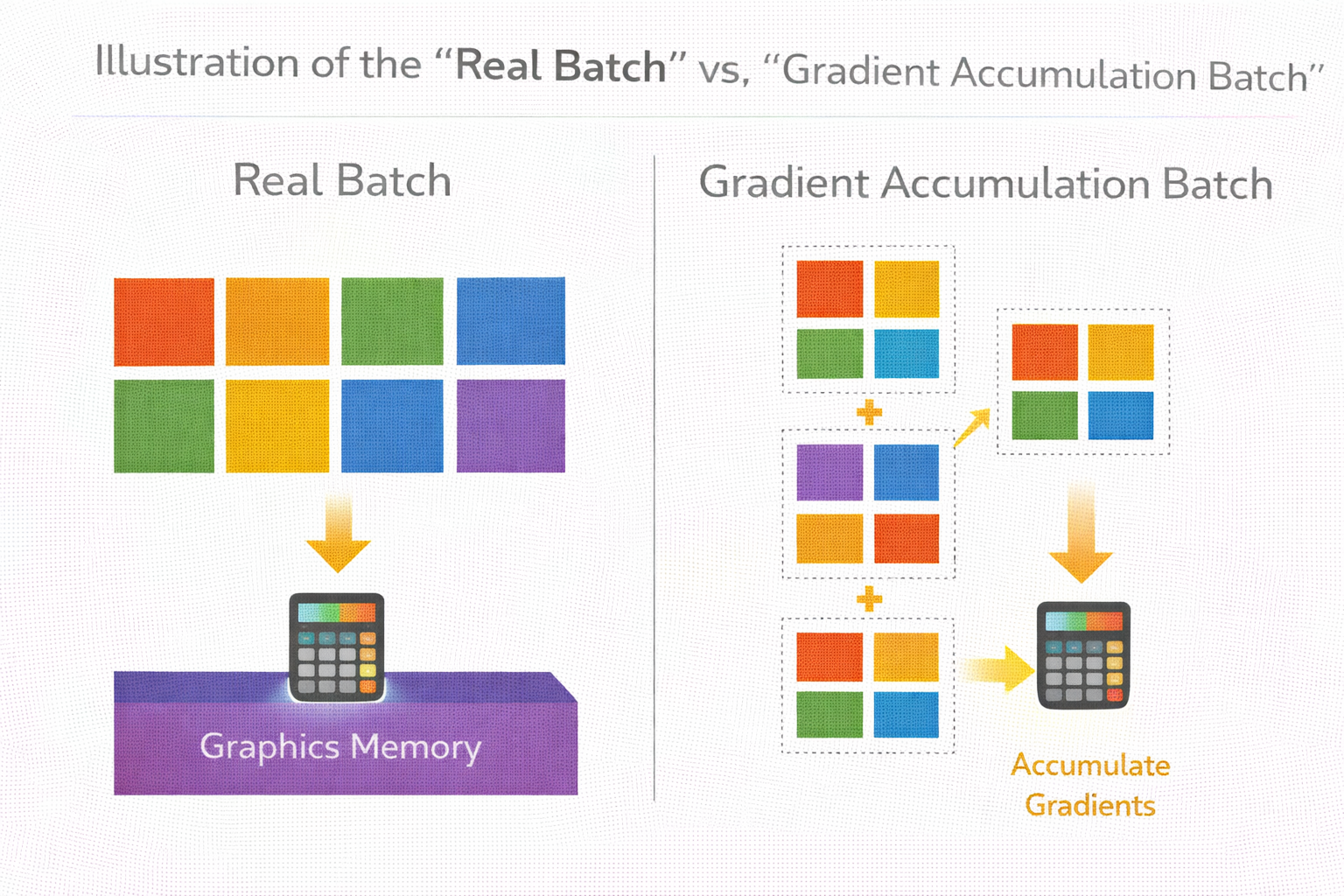
真實 batch vs 梯度累積 batch 示意圖
Offload:顯存省了,但系統開始“喘氣”
當你開始把 optimizer state 或部分參數 offload 到 CPU,你確實能省下一大截顯存。
但你也必須意識到:
你是在用 PCIe 帶寬換顯存。
一旦 offload 過多,訓練速度可能直接腰斬,甚至不穩定。
這類優化,非常不適合新手“無腦打開”。
一個容易被忽略的問題:你可能根本不需要“這麼大”
這是一個很多人不願意面對的問題。
你顯存不夠,真的是因為模型必須這麼大嗎?
還是因為你默認選了一個“看起來更強”的模型?
在微調階段,模型大小的邊際收益往往非常低。
有時候,換一個小一點的基座模型,反而比死磕顯存優化更理性。
一個現實建議:別一開始就把顯存榨乾
這是我見過最多人踩的坑。
剛好能跑 ≠ 穩定能跑
剛好不 OOM ≠ 可以反覆試錯
你永遠需要給顯存留餘地,用來:
- 調試
- 評估
- 臨時開 profiler
- 打印中間結果
顯存問題,往往是“系統設計問題”,不是參數問題
當你已經打開 bf16、checkpointing、梯度累積,還是跑不動時,通常意味着一件事:
你該停下來重新審視整體方案了。
繼續摳顯存,只會讓系統越來越脆。
一個健康的顯存優化順序(經驗總結)
不是“能開什麼開什麼”,而是:
- bf16 / fp16
- 減 batch size
- 梯度累積
- gradient checkpointing
- 評估是否需要 offload
- 重新審視模型規模
在顯存受限階段,更重要的是“驗證方向”
這點和前面幾篇其實是一脈相承的。
當你顯存很緊張時,你真正該做的,不是把訓練堆到極限,而是儘快驗證:
這個方向值不值得繼續投入。
在顯存和算力都受限的階段,先用 LLaMA-Factory online 快速跑通微調流程、驗證數據和目標是否有效,再決定是否投入重資源,會比一開始就死磕本地顯存更理性。
總結:顯存不夠,往往是你“算錯賬”,而不是你“資源太少”
寫到最後,其實可以把這篇文章壓縮成一句話:
顯存問題,本質上是一個系統認知問題。
當你真正搞清楚顯存是怎麼被吃掉的,你會發現:
很多 OOM,並不是不可避免的;很多顯存優化,也不是必須的。
真正成熟的工程師,不是“把顯存榨到 0”,而是知道哪些錢該省,哪些錢不該省。