

當你開始懷疑模型的時候,問題往往已經被帶偏了
如果你真的在項目裏落地過 RAG(Retrieval-Augmented Generation),你大概率經歷過下面這個過程。
一開始,你很有信心。
Embedding 模型選了主流的,
向量庫也搭好了,
Prompt 看起來也挺專業。
但一測效果,你開始皺眉。
- 有些問題明明“庫裏有”,模型卻答不出來
- 有些答案看起來很像“胡説”,但你又説不清楚錯在哪
- 換了個更大的模型,好像也沒好多少
這時候,一個非常自然的念頭就會冒出來:
“是不是模型不夠強?”
於是你開始換模型、調參數、加上下文長度,
但效果依然不穩定。
很多 RAG 項目,就是在這一步,被徹底帶偏方向的。
因為在絕大多數真實項目中:
RAG 效果差,問題真的很少出在模型上。
一個必須先認清的事實:RAG 是“檢索系統”,不是“模型能力放大器”
這是理解 RAG 失敗原因的第一步。
很多人潛意識裏,會把 RAG 理解成這樣一件事:
“模型本來不會的問題,只要把知識塞進去,它就會了。”
但 RAG 的本質其實更接近於:
一個以自然語言為接口的檢索系統。
模型在 RAG 裏做的事情,非常有限:
- 理解用户問題
- 利用給定上下文生成答案
而真正決定 RAG 上限的,是:
你到底給模型檢索到了什麼。
如果檢索階段出了問題,
模型再強,也只能在“錯誤或無關的信息”上發揮。
第一個常見誤判:把“答不好”當成“模型不會”
這是 RAG 實戰中最容易出現、也最容易誤導判斷的一點。
很多時候,模型不是不會答,
而是根本沒看到該看的內容。
你可以做一個非常簡單的自檢:
在生成之前,把檢索到的內容單獨打印出來,自己讀一遍。
你會非常頻繁地發現:
- 檢索結果本身就不相關
- 只命中了關鍵詞,沒命中語義
- 真正關鍵的信息被擠在很後面
在這種情況下,模型答不好,是完全正常的。
切分(Chunking),是 RAG 翻車的第一大源頭
如果讓我在 RAG 裏只選一個“最容易被低估,但殺傷力最大”的環節,那一定是:
文檔切分。
很多人切文檔時,腦子裏只有一個目標:
“切小一點,方便檢索。”
於是你會看到:
- 固定長度切分
- 不管語義直接截斷
- 表格、列表被打散
- 上下文依賴完全丟失
這樣做的直接後果是:
檢索出來的 chunk,本身就無法獨立表達有效信息。
模型看到的,不是“知識片段”,
而是“信息殘骸”。
一個非常常見的場景:答案就在庫裏,但永遠檢索不到
這是很多 RAG 項目裏最讓人崩潰的時刻。
你明明知道:
“這個問題,文檔裏絕對有。”
但檢索就是命不中。
原因往往不是 embedding 不行,而是:
- 問題和文檔的表達方式差異太大
- 文檔是“説明式”,問題是“場景式”
- 切分後,關鍵信息被拆散了
Embedding 模型不是魔法,它無法在信息本身已經被破壞的情況下,自動幫你“拼回語義”。
TopK 並不是“越大越好”
這是另一個非常典型的工程誤區。
很多人發現 RAG 效果差,第一反應是:
“那我多給模型一點上下文。”
於是 TopK 從 3 → 5 → 10 → 20。
結果往往是:
- 上下文越來越長
- 噪聲越來越多
- 模型開始抓不住重點
因為模型並不會自動幫你判斷“哪段最重要”。
在很多場景下:
TopK 變大,只是在稀釋真正有用的信息。
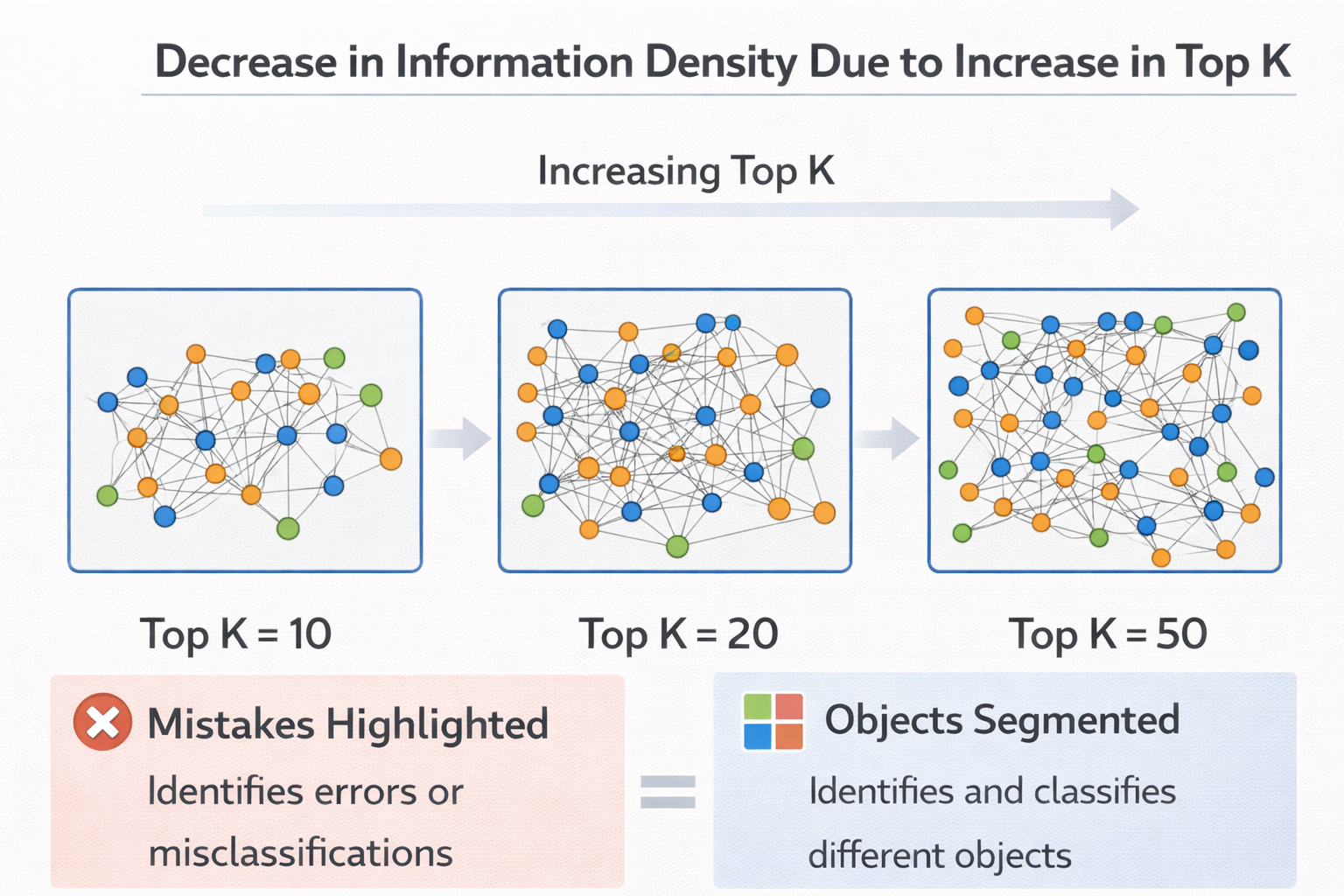
TopK 增大導致信息密度下降示意圖
檢索“命中”≠ 檢索“可用”
這是一個非常關鍵、但經常被混為一談的概念。
很多系統在調試 RAG 時,只看一個指標:
有沒有命中相關文檔。
但真正重要的,是:
命中的內容,能不能直接支撐答案生成。
比如:
- 命中了背景介紹,但缺少結論
- 命中了定義,但缺少條件
- 命中了局部描述,但缺少上下文
對模型來説,這些信息是“不完整的線索”,
而不是“可用的依據”。
為什麼換更大的模型,RAG 也不一定會變好
這是很多團隊花了最多錢、卻收穫最少的一步。
當 RAG 效果差時,換模型往往是性價比最低的優化路徑。
原因很簡單:
- 模型只能基於已有上下文發揮
- 它不能憑空補全缺失的信息
- 更大的模型,只會更“自信地胡説”
在檢索質量不高的情況下,
模型能力提升,很可能只會放大錯誤輸出的流暢度。
Rerank:很多 RAG 項目“救回來”的關鍵一步
在真實工程中,Rerank 往往是 RAG 效果的分水嶺。
初始向量檢索,解決的是“快”和“召回”;
Rerank,解決的是“相關性排序”。
很多時候,你的庫裏其實有正確答案,
只是它排在第 7、第 8 個位置,
模型根本沒機會看到。
加入 rerank 後,
你會突然發現:
模型“好像變聰明瞭”。
但實際上,是你終於把對的內容,放到了它面前。
一個最小可用的 RAG 排查流程(非常實用)
當 RAG 效果不理想時,我非常建議你按下面這個順序排查,而不是直接怪模型。
第一步:
固定模型,不動生成參數
第二步:
單獨檢查檢索結果是否可讀、可用
第三步:
檢查切分方式是否破壞語義
第四步:
減少 TopK,看效果是否反而變好
第五步:
再考慮 rerank 或 query rewrite
這是一個非常“反直覺”,但成功率極高的流程。

RAG 排查流程圖
一個簡單的調試技巧:把模型當“人”用一次
這是我個人非常常用的一個方法。
在調試 RAG 時,你可以做一件很簡單的事:
把檢索結果直接貼給一個人,讓他回答問題。
如果這個人都覺得:
“信息不夠”“看不懂”“缺關鍵條件”,
那模型答不好,真的不是模型的問題。
Query 本身,也可能是 RAG 的隱形短板
很多人會忽略:
用户問題,並不一定適合直接拿去做檢索。
尤其是在真實應用中,用户問題往往:
- 口語化
- 信息不完整
- 帶有上下文依賴
在這種情況下,
簡單地用原始問題做 embedding,很容易偏離真正的檢索目標。
這也是為什麼 query rewrite 在很多項目裏是“隱形剛需”。
一個很容易被忽略的問題:RAG 的評估方式本身可能是錯的
很多團隊在評估 RAG 時,只看最終答案。
但這樣做,會把所有問題都歸因到“模型輸出”。
更合理的評估方式,應該拆成三層:
- 檢索是否命中正確 chunk
- 提供的上下文是否足以支撐答案
- 模型是否合理使用了上下文
如果第一層就失敗了,後面再討論模型,毫無意義。
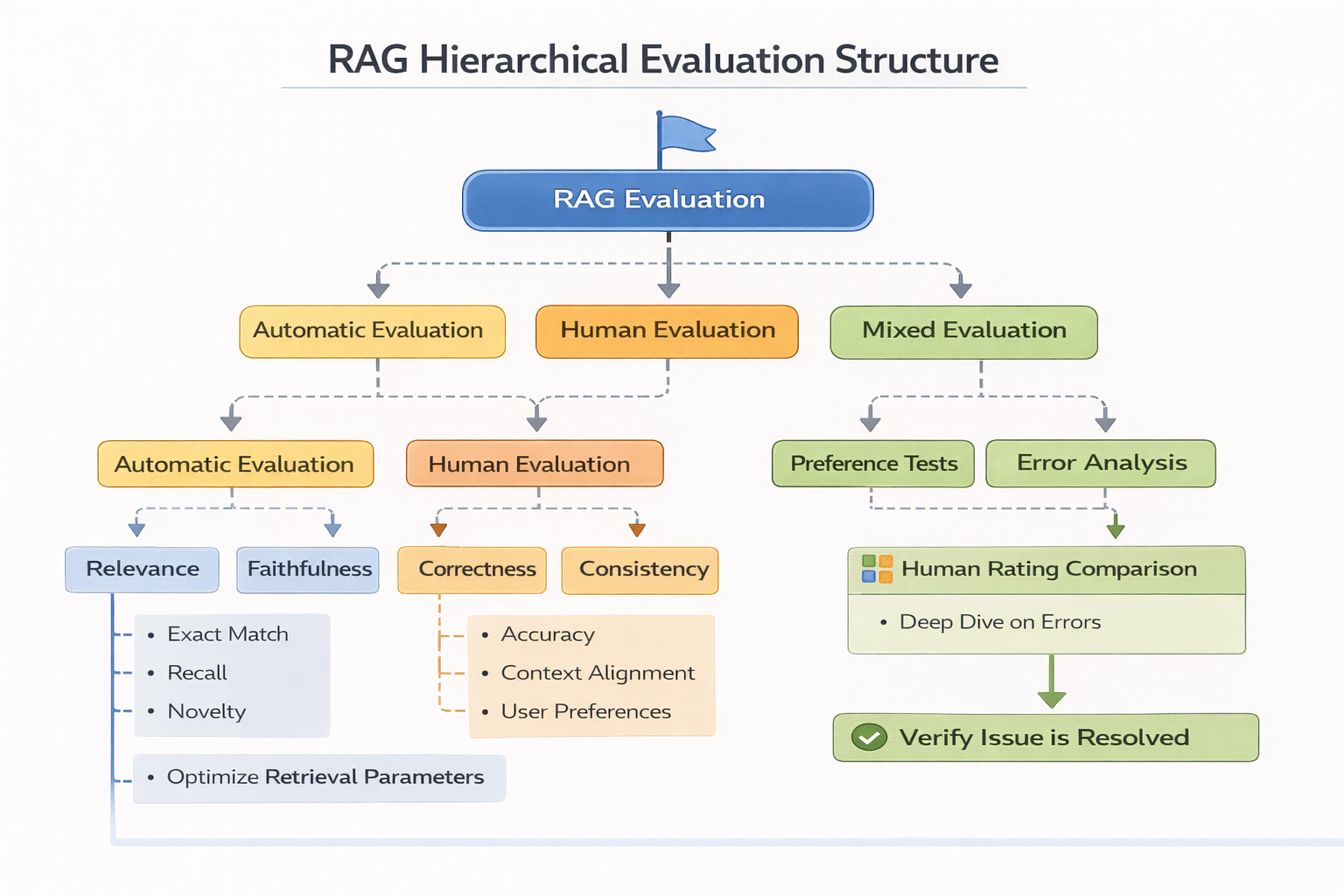
RAG 分層評估結構圖
為什麼 RAG 的工程成本,遠高於你的第一印象
這是一個你在教程裏幾乎看不到的事實。
RAG 看起來很簡單:
“檢索 + 生成”。
但在真實項目中,它涉及:
- 文檔治理
- 數據版本管理
- 檢索質量監控
- 切分策略演進
- 評估體系搭建
模型,反而是其中最穩定的一環。
一個現實建議:先把 RAG 當“檢索系統”做好
如果你只記住這一篇裏的一句話,那應該是這句:
RAG 成功與否,80% 決定於檢索系統,而不是模型能力。
當你真的把檢索質量、數據結構、切分策略打磨好之後,
你會發現:
哪怕用一個不那麼大的模型,效果也會明顯提升。
在驗證 RAG 架構和數據組織是否合理時,先用 LLaMA-Factory online 快速對比不同檢索策略下的生成效果,比一開始就深度綁定某個模型方案更容易定位問題。
總結:RAG 效果差,通常不是模型“不行”,而是你沒把該給的東西給它
寫到最後,其實結論已經非常明確了。
模型在 RAG 裏,並不是主角。
它更像是一個“閲讀理解能力很強的執行者”。
如果你給它的是:
- 破碎的內容
- 無關的信息
- 排序混亂的上下文
那它能給你的,也只能是一個看起來很像答案的東西。
真正成熟的 RAG 實戰,不是不斷換模型,而是反覆打磨:你到底在讓模型讀什麼。