

向量數據庫火,不代表你“必須用”
如果你這兩年做過和大模型相關的系統,很難繞開“向量數據庫”這個詞。
幾乎所有 RAG 架構圖裏,都有它的位置。
幾乎所有教程裏,都在説:
“把文檔向量化,存進向量數據庫,就好了。”
於是,向量數據庫很自然地從一個解決特定問題的工具,
變成了一種默認選項。
但如果你真的做過幾個項目,就會慢慢意識到一件事:
向量數據庫確實很強,
但它從來不是“白拿的能力”。
它解決了一些你以前解決不了的問題,
同時,也悄悄把系統複雜度、調試成本、不可解釋性,一起帶進來了。
一個必須先説清楚的前提:向量數據庫解決的是“相似性”,不是“正確性”
這是理解它優劣的第一把鑰匙。
向量數據庫本質上只做一件事:
在高維空間裏,幫你快速找到“看起來像”的東西。
它並不關心:
- 語義是否真的等價
- 信息是否完整
- 內容是否可用
它只關心:
向量距離近不近。
一旦你在系統設計中,默認“相似 = 有用”,
那後面很多問題,幾乎是必然發生的。
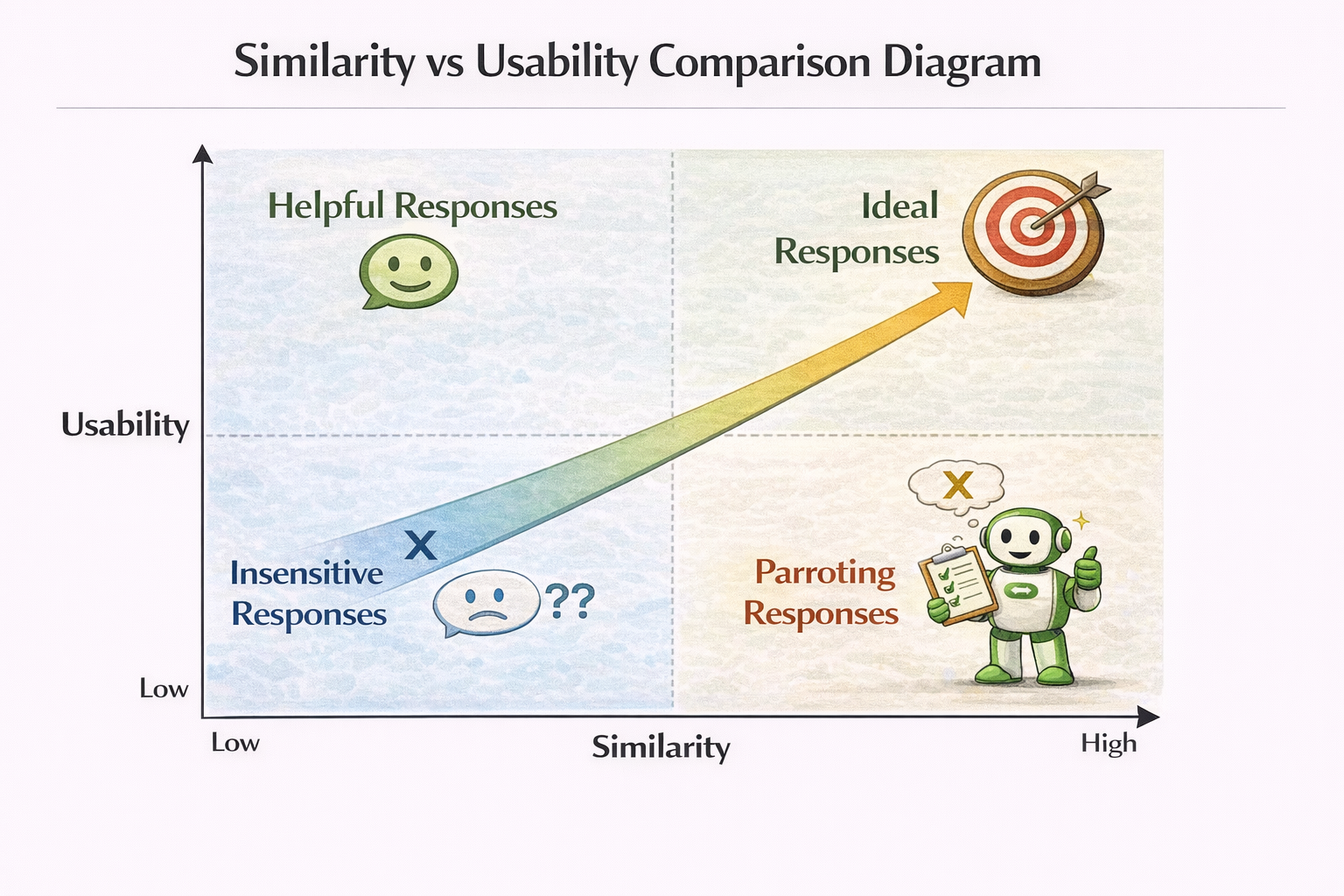
相似性 vs 可用性對比示意圖
向量數據庫的第一個巨大優勢:它讓“模糊檢索”第一次變得可工程化
在向量數據庫出現之前,
你幾乎很難在工程裏系統性地解決下面這種問題:
- 用户問法和文檔表達完全不一致
- 關鍵詞不重合,但意思很接近
- 問題是“場景式”的,而不是“定義式”的
傳統關鍵詞檢索,在這些場景下幾乎無能為力。
向量數據庫的出現,第一次讓:
- “差不多的意思”
- “看起來在説同一件事”
變成了一種可落地的檢索能力。
這也是它能在 RAG 裏迅速普及的根本原因。
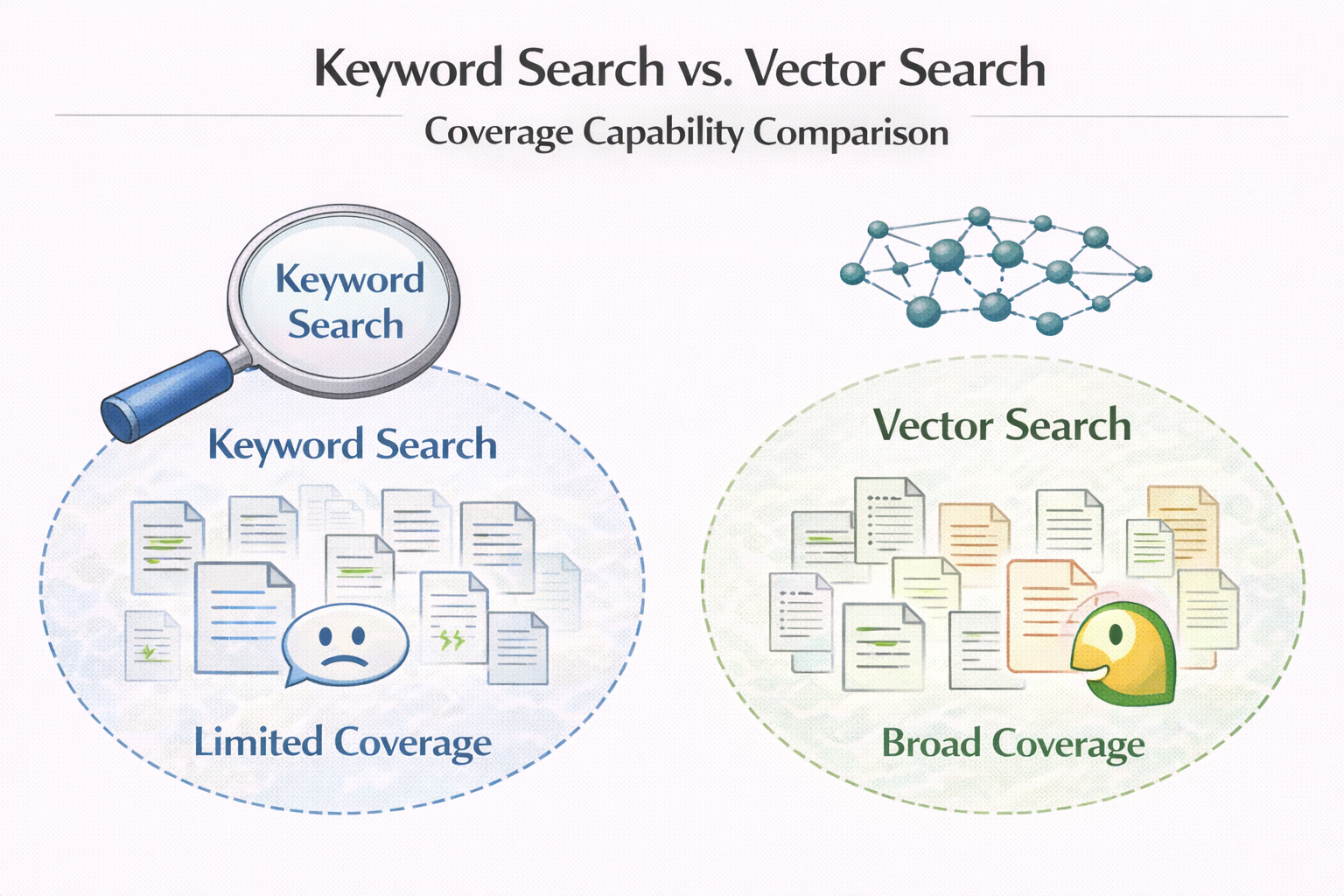
關鍵詞檢索 vs 向量檢索能力覆蓋對比
第二個優勢:它天然適配“長尾問題密集”的場景
如果你的系統面對的是:
- 問題種類極多
- 單個問題頻率很低
- 但整體知識面很廣
那向量數據庫幾乎是唯一現實可行的方案。
你不可能為每個問題寫規則,
也不可能通過微調覆蓋所有問法。
向量數據庫在這裏的價值在於:
它把“沒見過的問題”,
映射到“見過的相似問題或文檔”。
這是一種非常工程化的“兜底能力”。
第三個優勢:它極大降低了“知識更新”的工程成本
這一點,在真實項目裏非常重要。
如果你用微調來解決知識問題,那麼:
- 每次知識變更,都意味着重新訓練
- 模型版本管理複雜
- 風險極高
而向量數據庫的模式是:
- 知識在模型外
- 可隨時更新
- 可回滾、可刪除
這使得系統在“內容層面”的靈活性,大幅提升。
但問題來了:這些優勢,是有前提條件的
向量數據庫的優勢,並不是無條件成立的。
它至少隱含了幾個假設:
- 你的文檔本身是“可檢索的”
- 你的切分是“語義合理的”
- 你的 embedding 能表達你關心的相似性
一旦這些前提不成立,
向量數據庫的優勢,很快就會反轉成劣勢。
第一個被低估的劣勢:相似性很容易“騙過你”
這是向量數據庫最危險、也最隱蔽的問題。
你會看到很多這樣的情況:
- 檢索結果“看起來很相關”
- 關鍵詞命中了
- embedding 分數也不低
但你真正讀完之後,會發現:
- 信息不完整
- 條件缺失
- 結論根本不適用
這是因為:
相似性,並不等價於“可用於回答當前問題”。
而向量數據庫,並不會幫你區分這兩者。
第二個劣勢:向量數據庫極度依賴“前處理質量”
很多人低估了這一點。
在傳統數據庫裏:
- 數據結構清晰
- schema 明確
- 查詢語義穩定
但在向量數據庫裏:
- 數據是“被解釋後的結果”
- embedding 是不可逆的
- 任何前處理錯誤,都會被放大
尤其是在 RAG 場景中:
- 文檔切分一旦做錯
- 表格結構被破壞
- 上下文依賴丟失
後面你再怎麼調檢索、調模型,都只是在錯誤輸入上努力。
第三個劣勢:向量數據庫讓系統“變得很難解釋”
這是很多工程師在系統跑了一段時間後,才真正感受到的痛點。
當用户問:
“為什麼系統會給我這個答案?”
在向量數據庫參與的系統裏,你往往只能回答:
- 因為它們“比較像”
- 因為 embedding 距離近
但這對排查問題、説服業務方、做安全審計,幫助都非常有限。
尤其是在:
- 合規
- 法律
- 內部決策系統
這類對“可解釋性”要求極高的場景裏,
向量數據庫本身就是一個風險放大器。
第四個劣勢:你會不知不覺地,把“判斷權”交給 embedding 模型
這是一個非常容易被忽略,但後果很深遠的問題。
一旦你用了向量數據庫,你實際上默認了一件事:
“embedding 模型對‘什麼算相似’的理解,是可信的。”
但 embedding 模型本身:
- 有訓練偏好
- 有表達盲區
- 有領域不適配問題
你可能從來沒有認真驗證過:
它的“相似性判斷”,是不是你真正想要的。
一個真實工程現象:向量數據庫用久了,系統越來越“玄學”
這是很多團隊都會經歷的階段。
一開始:
- 效果明顯提升
- 解決了很多關鍵詞檢索解決不了的問題
後來:
- 某些問題突然開始答錯
- 改一點切分,影響一大片
- embedding 一升級,效果整體波動
你很難回答一個簡單的問題:
“系統為什麼會變成現在這樣?”
因為系統行為,已經被埋在了高維空間裏。
向量數據庫,並不擅長“精確邊界判斷”
如果你的問題是:
- 明確條件
- 明確規則
- 明確邊界
比如:
- 是否滿足某個條款
- 是否符合某個閾值
- 是否允許某種操作
那向量數據庫往往是不合適的工具。
它擅長的是“模糊匹配”,
而不是“是 / 否判斷”。
在這類問題上,用向量數據庫,很容易得到:
- 看起來合理
- 但實際上不可靠
的結果。

模糊匹配 vs 精確判斷適用場景對比
一個簡單代碼示例:向量相似≠答案可用
下面這段代碼,只是為了直觀説明問題:
query = "節假日退款多久到賬?"
docs = vector_db.search(query, top_k=3)
for d in docs:
print(d.score, d.text)
你可能會得到:
- 分數很高
- 內容提到“退款”、“到賬”
但文檔裏並沒有節假日規則。
向量數據庫已經完成了它該做的事,
但答案依然是缺失的。
向量數據庫最大的隱性成本:它改變了你排查問題的方式
在沒有向量數據庫的系統裏:
- 問題往往可復現
- 路徑相對清晰
但在向量數據庫參與後:
- 結果受 embedding、切分、索引多重影響
- 排查路徑變長
- 很多問題只能靠經驗判斷
這對團隊成熟度要求非常高。
什麼時候向量數據庫會從“優勢”變成“負資產”
這是一個非常重要、但很少被正面討論的問題。
向量數據庫,往往在以下情況下,開始成為負擔:
- 數據規模並不大
- 問題類型相對固定
- 規則本可以解決
- 但你仍然引入了向量檢索
這時你會發現:
- 系統複雜度上升
- 效果卻沒有顯著提升
- 調試成本指數級增加
一個更健康的工程認知:向量數據庫是“工具”,不是“架構核心”
在成熟系統裏,向量數據庫往往只是:
- 檢索層的一種手段
- 而不是系統的“中樞神經”
它應該:
- 和規則系統配合
- 和結構化查詢互補
- 而不是一統天下
在探索階段,謹慎引入向量數據庫反而是好事
這是一個很反直覺的建議。
如果你還不清楚:
- 用户真正問什麼
- 哪些問題最重要
- 文檔是否適合被檢索
那一開始就引入向量數據庫,
很可能會掩蓋真正的問題。
在驗證“是否真的需要向量數據庫”以及對比不同檢索方案效果時,用LLaMA-Factory online這類工具先快速跑通 RAG 流程、對比有無向量檢索的真實輸出差異,會比一開始就投入完整向量庫工程更容易看清取捨點,避免過早把系統複雜度拉滿。
總結:向量數據庫的價值,在於“解決問題”,而不是“顯得先進”
如果要用一句話總結向量數據庫的優勢和劣勢,那應該是:
它非常擅長解決“人類覺得差不多”的問題,
但也非常容易掩蓋“系統其實不確定”的地方。
真正成熟的使用方式,不是問:
- “我們要不要用向量數據庫?”
而是問:
- “這個問題,本質上是不是一個相似性問題?”
當你能回答清楚這個問題時,
向量數據庫,才會真正成為資產,而不是負擔。