

為什麼 PPO 在真實業務裏越來越重要
如果你是從論文或者課程裏接觸 PPO 的,那大概率會有一種“這東西看起來很厲害”的感覺。策略梯度、clip、KL 約束、reward model,一整套體系下來,很容易讓人產生錯覺:只要把 PPO 跑起來,大模型就能被“精細打磨”。
但真正進到業務裏,你會發現情況完全不是這麼回事。
大多數業務方找你,並不是因為模型“不會回答”,而是因為模型“回答得讓人不放心”。要麼太自信、要麼太囉嗦、要麼在不該説的時候亂説。你用 SFT 反覆微調,效果始終有限;你上 RAG,幻覺依然存在;你堆數據,邊際收益越來越低。
很多團隊就是在這個階段,開始真正認真考慮 PPO 的。
但問題也恰恰出在這裏:PPO 往往被用錯位置了。
如果你把 PPO 當成“提升能力”的手段,它幾乎一定會讓你失望;
如果你把 PPO 當成“行為對齊工具”,它反而會非常好用。
這篇文章想做的事情很簡單:不談公式,不談理論最優解,只從真實業務出發,聊聊 PPO 在工程裏最常見、也最值得投入精力的三種用法。
技術原理:先把 PPO 在大模型裏的位置擺正
在聊具體場景之前,有必要先統一一個認知,否則後面的內容很容易產生誤解。
我一直覺得,PPO 在大模型體系裏,更像是一個行為調節器,而不是能力增強器。前提是,你的模型已經“能幹活了”,無論是靠預訓練,還是靠 SFT,總之它已經具備了基本的語言理解和生成能力。
PPO 乾的事情,並不是教模型新知識,而是在儘量不破壞原有能力的情況下,重新分配它的輸出概率。
這也是為什麼 PPO 一定要有 reference model,一定要盯着 KL。如果沒有 KL 約束,reward 再好,模型也可能被推到一個極端狀態,最後你得到的可能是一個“特別聽話、但完全不好用”的模型。
從工程角度看,你可以把 PPO 理解成:
模型在一個已經學會走路的前提下,被人牽着繩子往某個方向多走一點點,而不是重新學走路。
理解了這一點之後,很多“為什麼 PPO 在我這裏不好用”的問題,其實就已經有答案了。
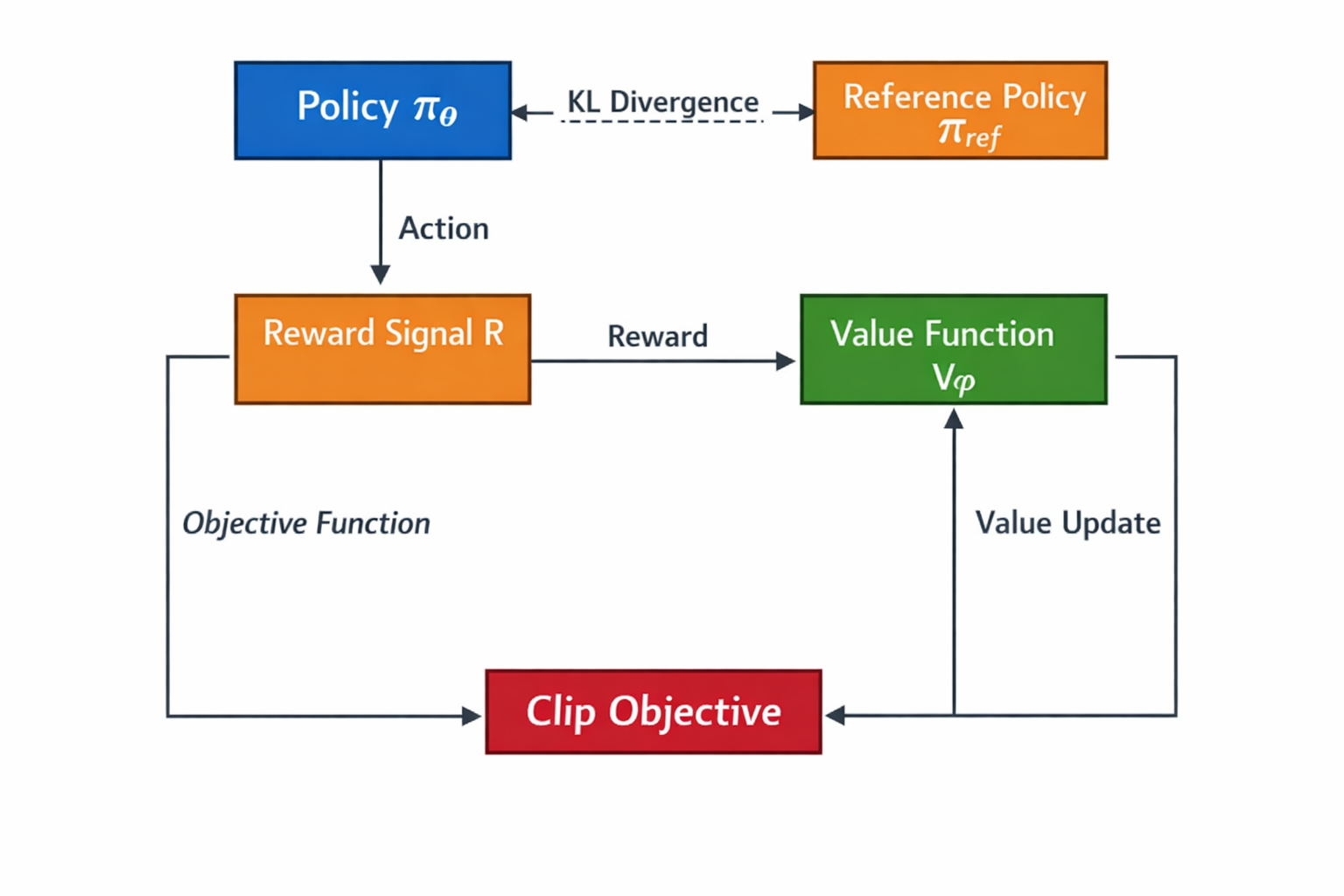
PPO 中 Policy / Reference / Reward / Value 的關係示意圖
真實業務裏的 3 種典型 PPO 用法
用法一:對齊輸出風格,而不是提升“智商”
這是我個人用 PPO 用得最多、也最穩的一類場景。
很多時候,業務方對模型的不滿,根本不是“答錯了”,而是“答得不好用”。比如回答太長、廢話太多、結構混亂、重點不突出,或者語氣完全不符合業務調性。這些問題,你靠 SFT 往往只能緩解一部分,因為它們並不是一個“標準答案”的問題。
PPO 在這裏的優勢就在於,它並不要求你給出一個唯一正確的回答,而是允許你表達一種偏好。
在實際操作中,我很少一開始就設計特別複雜的 reward。更多時候,是用非常樸素的方式:
同一個問題,準備兩類回答,一類是“業務覺得可以直接上線用的”,另一類是“雖然沒錯,但明顯不太行的”。reward model 只要學會區分這兩類,就已經足夠支撐 PPO 訓練。
真正需要花心思的,是訓練過程本身。風格類 PPO 特別容易出現一種情況:reward 很快漲,KL 也跟着漲,模型輸出開始變得“刻意”,每句話都像在迎合規則。這時候,如果你繼續訓,模型往往會越來越不像人。
我自己的經驗是,在這種場景下,寧可少訓一點,也不要追求極致 reward。PPO 的價值在於“輕微但穩定的行為偏移”,而不是一次性推到極端。
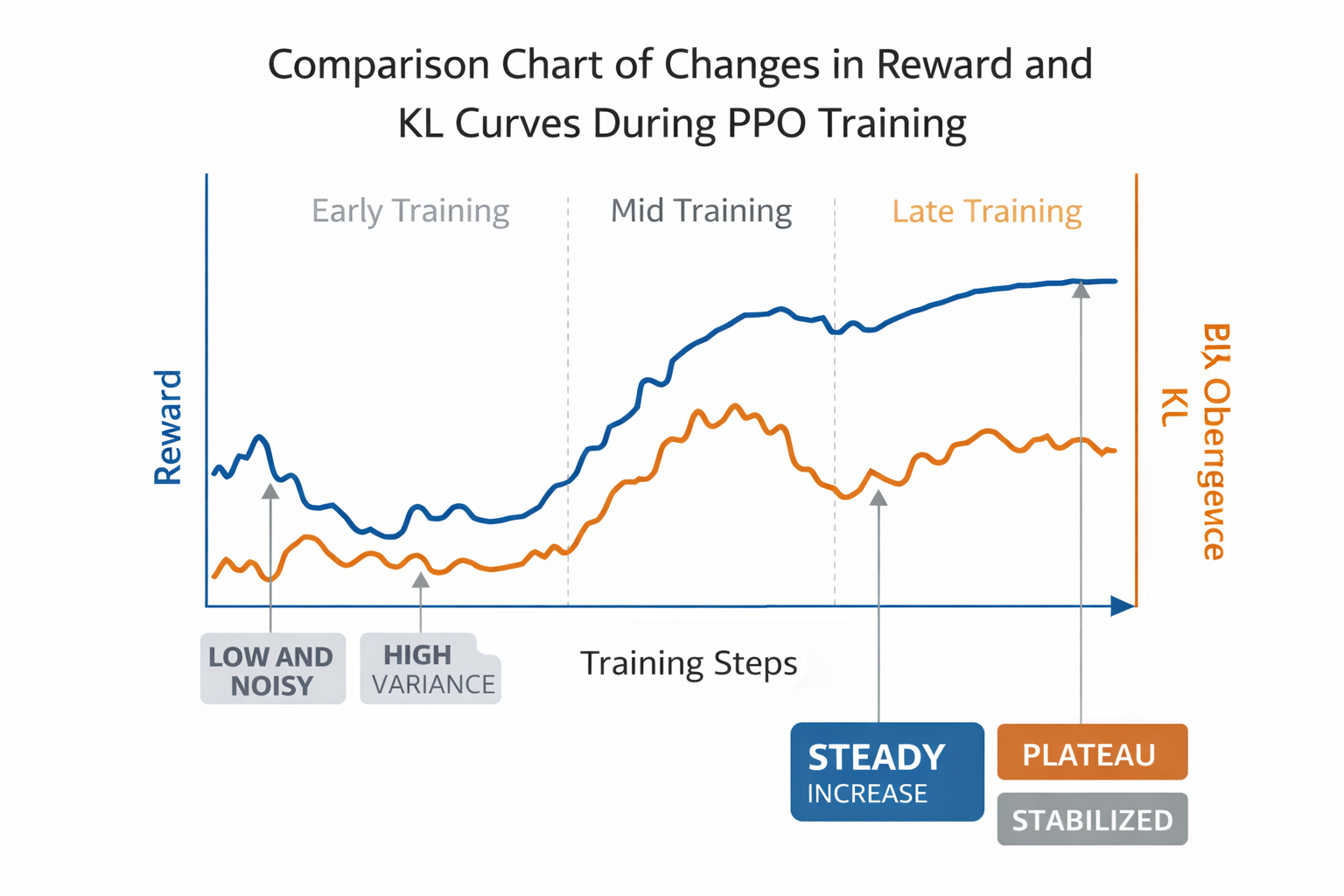
PPO 訓練過程中 reward 與 KL 曲線變化對比圖
用法二:降低幻覺,而不是追求“完全正確”
這是第二個非常典型、而且在真實業務中極其重要的場景。
在很多對外服務系統裏,模型最大的風險從來不是“不知道”,而是“胡説”。尤其是在客服、政策解讀、專業問答這類場景中,一個看起來很自信、但事實錯誤的回答,往往比直接拒答要危險得多。
很多團隊第一反應是上 RAG,這當然有幫助,但你會很快發現,RAG 只能解決“有資料可查”的問題。一旦用户的問題本身就超出知識範圍,模型還是會傾向於硬答。
這時候,PPO 的優勢就體現出來了。
你可以用 PPO 明確告訴模型:
- 在不確定時,選擇保守、拒答、引導用户補充信息,是好行為
- 在沒有依據的情況下,編造一個完整答案,是壞行為
注意這裏一個非常關鍵的點:你並不需要模型知道正確答案。你訓練的不是“知識正確性”,而是“決策邊界”。
在工程上,這類 PPO 的難點往往不在算法,而在負樣本構造。負樣本如果太假,模型學不到邊界;負樣本如果本身就模糊,reward 會變得非常噪聲,訓練過程也會非常不穩定。這部分工作通常最耗時間,但也是最值的。
用法三:強化偏好選擇,而不是生成能力
第三種用法,更多出現在策略選擇或者偏好排序場景中。
比如客服系統裏,模型並不是直接輸出最終回覆,而是需要在多個回覆策略中選一個;或者推薦系統裏,模型要在多個候選方案之間做權衡。這類問題的本質,其實不是生成,而是決策。
在這種場景下,PPO 更像是一個策略優化器。
模型通常已經能理解輸入,也能理解候選項的含義,但並不知道業務真正想要什麼。reward 往往來自複雜規則、線上反饋,或者一些難以直接監督的數據指標。
很多人會糾結這種場景到底該用 PPO 還是 DPO。我的實際經驗是,如果你的偏好數據非常乾淨、成對關係非常明確,DPO 確實更省事;但只要 reward 來源複雜、規則經常變,或者你希望保留更強的控制能力,PPO 的靈活性優勢就會非常明顯。
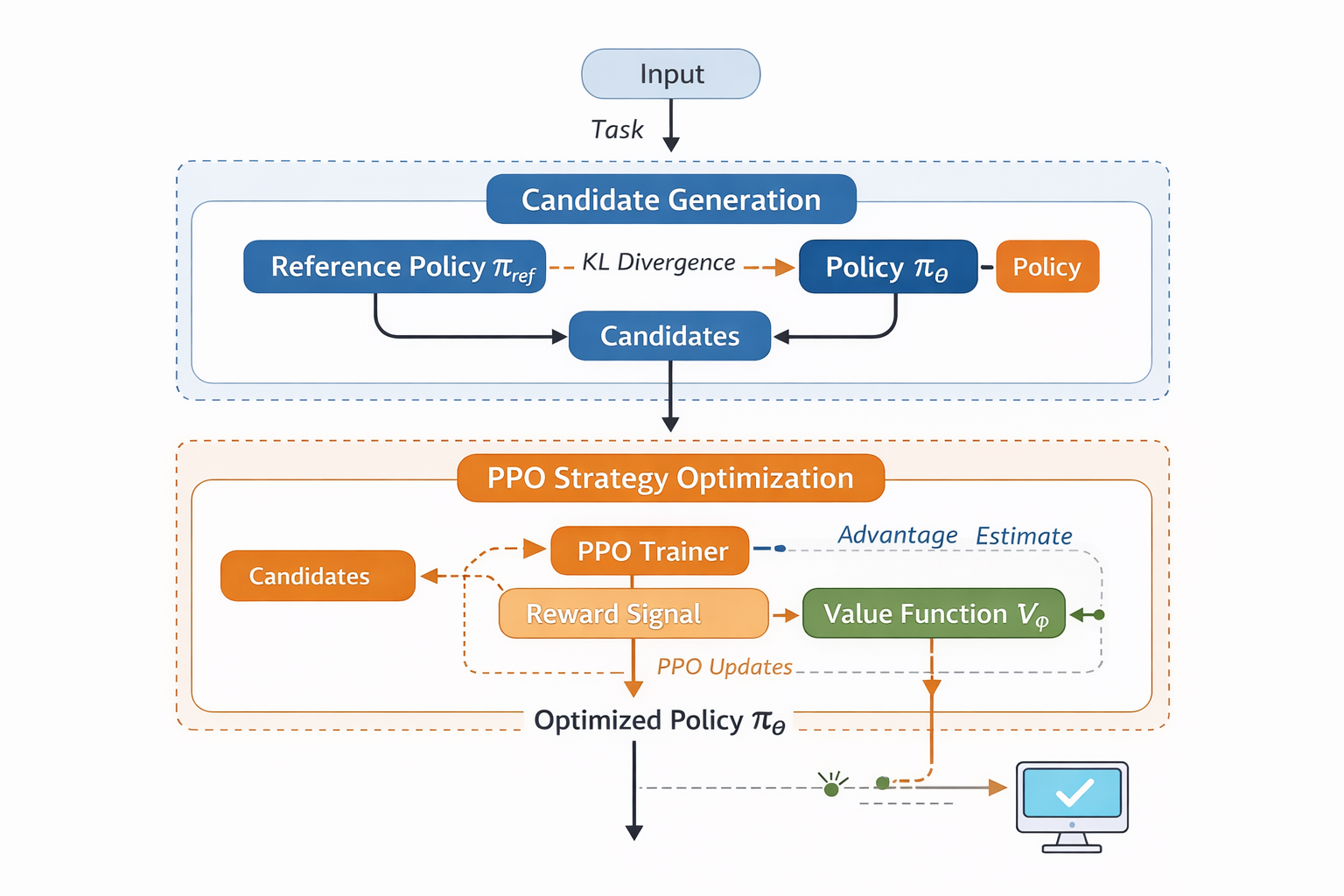
候選生成 + PPO 策略優化流程圖
實踐步驟:一個真實可落地的 PPO 流程
在真實項目裏,我並不建議一開始就把 PPO 當成一個“完整工程”來搭。更現實、也更安全的做法,是先跑一個最小流程,驗證方向是不是對的。
通常我會從非常簡單的配置開始:
- 一個已經做過 SFT 的模型
- 一個儘量簡單的 reward 設計
- 非常少的訓練步數
- 嚴格監控 KL 變化
只要你能看到輸出行為在朝着你期望的方向變化,就説明這條路是值得繼續走的。等方向確認了,再去考慮更復雜的 reward、更精細的訓練策略。
在這個階段,使用 LLaMA-Factory online 這類工具,先把 PPO 的整體流程跑通,往往會比從零搭工程更高效。它能幫你把注意力集中在 reward 和輸出分析上,而不是被環境和訓練細節拖住。
效果評估:如何判斷 PPO 是否真的生效
評估 PPO 的效果時,我一直不太建議只盯着 loss 或 reward 曲線。那些指標更多是“訓練是否正常”的信號,而不是“業務是否變好”的證明。
更有效的方式,永遠是對同一批測試問題,在訓練前後跑一遍,然後人工去看輸出變化。是不是更穩了?是不是更符合業務直覺了?是不是少了一些讓你看了心裏發緊的回答?
在我看來,PPO 的價值,幾乎永遠體現在輸出分佈的變化上,而不是某個單點指標的提升。
總結與技術的未來展望
寫到最後,其實可以很明確地説一句:PPO 並不是一個“必須用”的技術。
但一旦你的業務開始關心“模型怎麼説”“什麼時候該説”“什麼時候不該説”,PPO 往往會成為一個非常順手的工具。
我也越來越不覺得 PPO、DPO 這些方法是在互相替代。在真實工程裏,它們更像是不同層級的工具,解決不同的問題。未來的大模型對齊,很可能就是這些方法和規則、在線反饋一起組合使用,而不是押注某一種算法。
在這樣的趨勢下,能夠快速驗證不同對齊策略、低成本試錯的工具,會越來越重要。