

大多數“智能客服失敗”,不是模型不行,而是期望錯了
如果你做過或接觸過智能客服項目,大概率會經歷一個相似的心理過程:
一開始覺得:
“現在大模型這麼強,客服這種問答場景,不是正好對口嗎?”
然後你會很快發現現實是:
- 問題很雜
- 規則很多
- 灰度極多
- 一句話答錯,後果可能很嚴重
最後,團隊往往會把希望寄託在一件事上:
“那我們給模型微調一下吧。”
而真正的問題是——
你往往是在還沒想清楚“客服到底在幹什麼”的情況下,就開始微調了。
一個必須先説清楚的事實:智能客服 ≠ 問答機器人
這是所有判斷的起點。
問答機器人解決的是:
“我問一個問題,你給我一個答案。”
而智能客服解決的,其實是:
- 是否該回答
- 回答到什麼程度
- 是否要引導用户
- 是否需要轉人工
- 是否要安撫情緒
- 是否要遵守規則優先級
換句話説,客服的核心不是“答對”,而是“處理得當”。
這也是為什麼,很多“看起來很聰明”的模型,一放進客服系統就開始出問題。
為什麼客服場景天然容易“被微調沖壞”
客服是一個高約束、低容錯、強邊界的場景。
這意味着三件事:
- 輸出不能隨意發揮
- 行為不能前後不一致
- 邊界問題比正確答案更重要
而微調,尤其是不加區分地微調,本質上是在做一件事:
把歷史行為固化進模型。
如果你不非常清楚“哪些行為是好行為”,
那微調只會把歷史系統的混亂,永久寫進模型參數裏。
智能客服裏,最容易被拿去微調、但風險最高的數據
這是一個必須説清楚的話題。
在客服項目裏,最容易被認為“很寶貴”的數據,往往是:
- 歷史真實對話
- 人工客服的回覆記錄
- 運營總結的標準話術
但這些數據裏,隱藏着非常多的雷:
- 人工客服有大量“臨場判斷”和“例外處理”
- 同一問題,不同客服給過不同尺度的回答
- 有些回覆只是為了“先安撫用户”,並不是真正的規則解答
如果你把這些數據直接拿去做 SFT 或 PPO 微調,
模型學到的往往不是“規範行為”,而是人類的隨意性。
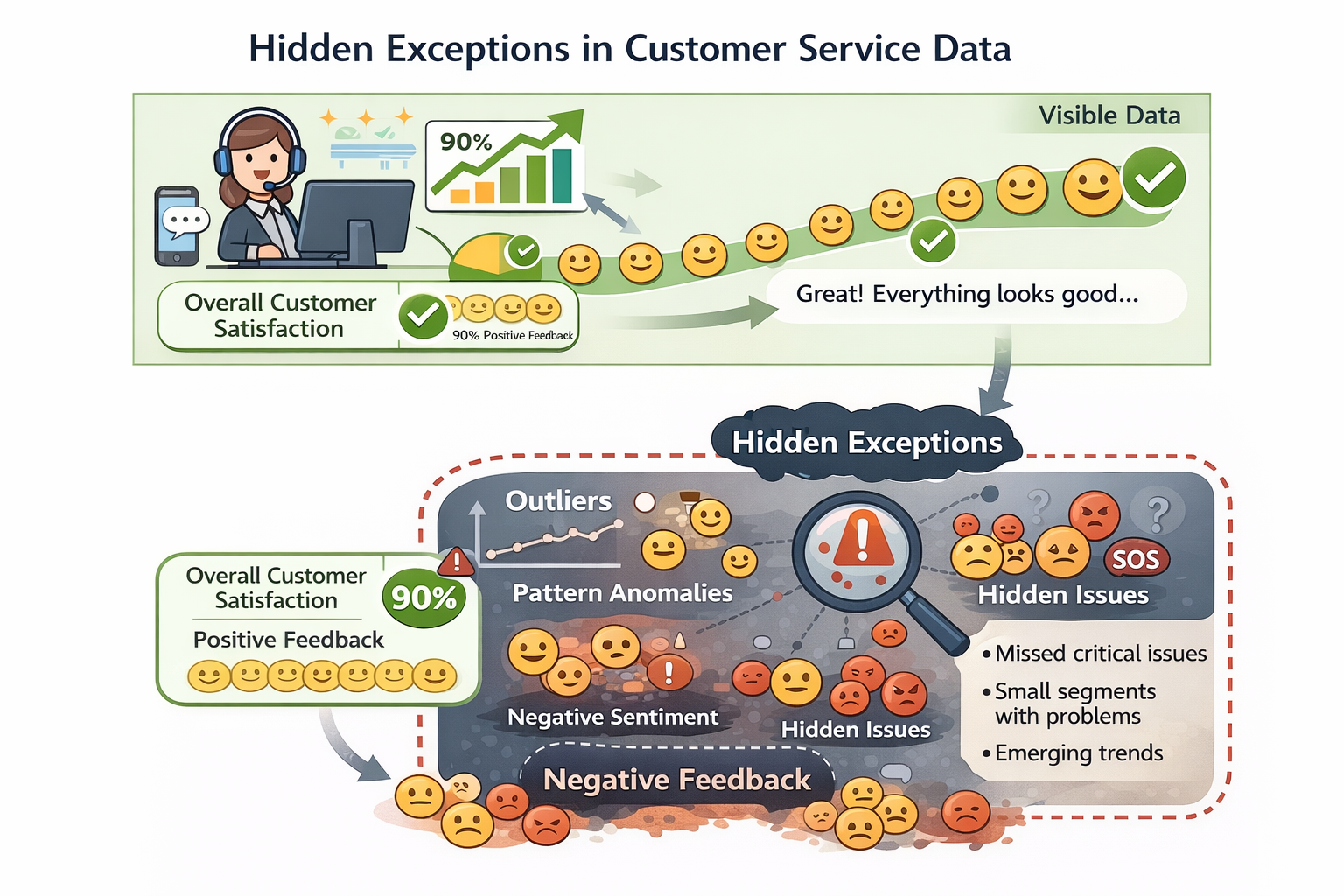
客服數據中的“隱性例外”示意圖
微調在客服系統中,真正“適合做”的三類事情
説清楚風險之後,我們再來講微調的正向價值。
在客服場景裏,微調並不是沒用,
但它只能用在非常有限、非常明確的目標上。
第一類:穩定輸出風格,而不是擴展知識
客服大模型最常見的問題之一是:
同一問題,不同時間回答風格不一致。
比如:
- 有時很官方
- 有時很隨意
- 有時解釋很多
- 有時一句話打發
這種不一致,會極大降低用户信任感。
在這種情況下,微調的目標不是“教模型新知識”,
而是:
在模型已經會回答的前提下,
固定它的表達方式和語氣邊界。
這類微調,風險相對可控,收益也比較明確。
第二類:高頻、規則明確、幾乎沒有灰度的問題
比如:
- 發票怎麼開
- 退款流程是什麼
- 工單狀態怎麼查
這類問題的特點是:
- 答案相對固定
- 規則來源明確
- 例外情況少
如果你已經通過 RAG 或規則驗證了答案的正確性,
再用微調去減少模型胡亂發揮的概率,是合理的。
但這裏的關鍵詞是:
減少發揮,而不是增加發揮。
第三類:安全拒答與轉人工的“行為傾向”
在客服系統裏,有一類問題不是“答什麼”,而是:
- 要不要答
- 要不要轉人工
- 要不要先安撫
這些行為,很難通過規則完全覆蓋,
但人類在對比多個回覆時,往往很容易選出“更合適的”。
這正是 PPO / DPO 類微調在客服場景裏最有價值的地方。
你不是在教模型規則,
而是在教它:
什麼情況下該收手。
智能客服裏,哪些問題“不該”通過微調解決
這一部分,比“該做什麼”更重要。
不該微調的第一類:知識經常變的問題
比如:
- 活動規則
- 臨時政策
- 地域差異條款
這類問題,如果用微調,一定會遇到:
- 更新慢
- 回滾難
- 歷史版本混亂
RAG 或規則系統,幾乎總是更好的選擇。
不該微調的第二類:高度依賴上下文和狀態的問題
比如:
- 用户當前工單狀態
- 歷史投訴記錄
- 賬户風險等級
這些信息,本來就不應該被“學進模型”,
而應該在推理時動態注入。
微調在這裏,不但幫不上忙,還會製造安全隱患。
不該微調的第三類:本身就存在爭議的業務判斷
如果你的業務方自己都説不清楚:
- 這個問題到底該不該答
- 該答到什麼程度
那你就不可能通過微調,把問題解決掉。
微調只會把“當前的不確定狀態”固化。
一個真實的工程現象:客服模型越微調,越“像老客服”
這句話聽起來像好事,但在工程裏往往不是。
“老客服”的特點包括:
- 很多隱性規則
- 很多歷史包袱
- 很多“看人下菜”的判斷
這些特質,一旦被寫進模型,就很難再統一收回。
所以在客服場景裏,
微調不是讓模型“像人”,而是讓模型“像規範”。
一個客服微調項目,最容易忽略的評估維度
很多團隊評估客服模型,只看:
- 命中率
- 滿意度
但在微調之後,你更應該關注的是:
- 是否更容易越界
- 是否更難拒絕
- 是否更少轉人工
- 是否在邊界問題上變得自信
這些指標,一旦惡化,後果往往比“答不出來”更嚴重。
客服微調的一個健康技術組合(而不是單點押注)
在真實系統裏,一個更健康的架構往往是:
- 規則系統:兜底紅線
- RAG:提供事實和流程
- 微調模型:穩定行為風格
- 人工客服:處理灰度與例外
微調,永遠不是主角,而是收斂器。
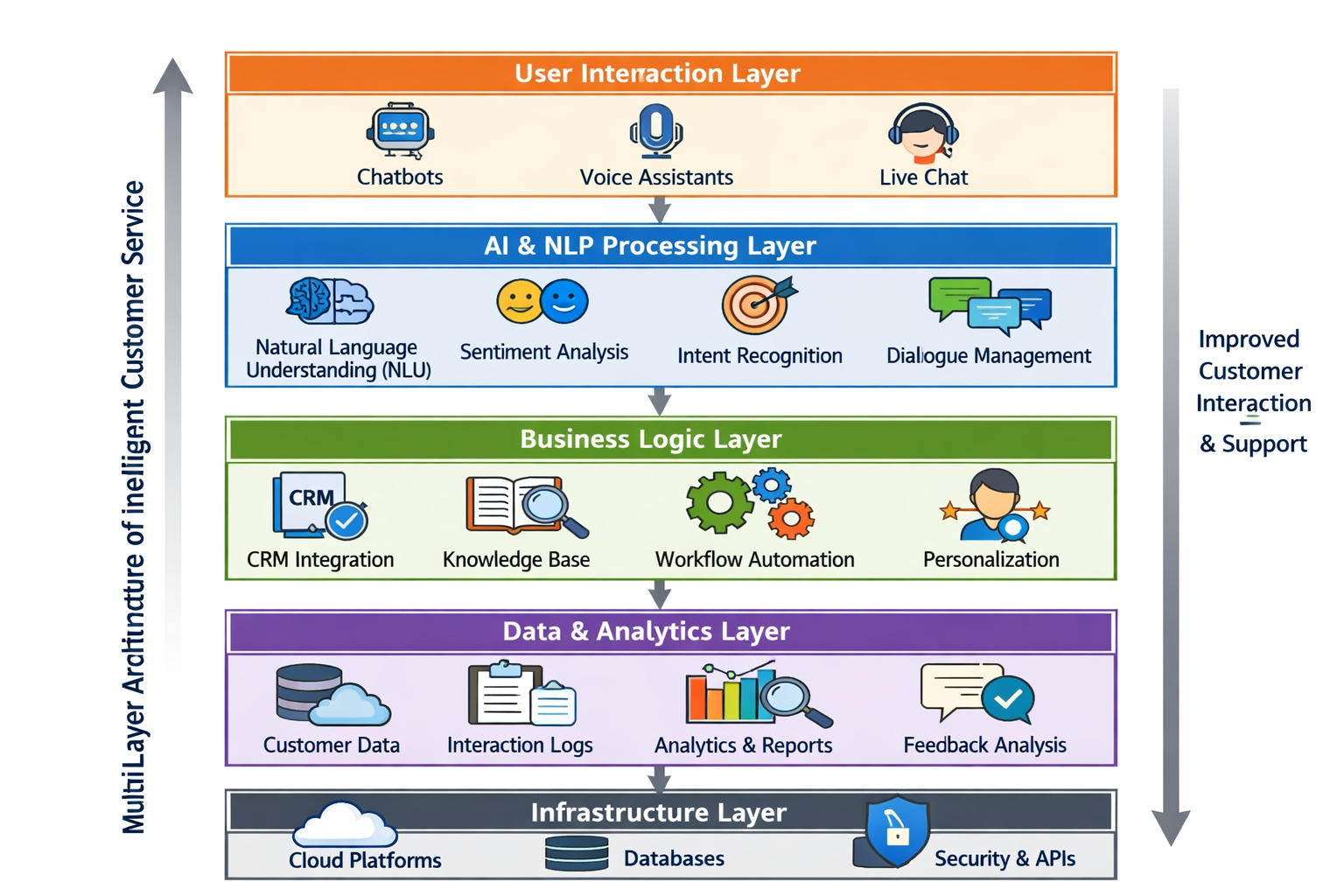
智能客服多層架構示意圖
一個簡單示意:客服 PPO 微調在幹什麼(非教學)
responses = policy.generate(prompt, n=3)
# 人工或規則選出“更合適的行為”
preferred = choose_best(responses)
# PPO 學的不是“答案”
# 而是:在客服場景下,哪種處理方式更穩妥
reward = compare(preferred, responses)
你會發現,這裏根本沒有“正確答案”的概念。
在客服場景下做微調,最難的往往不是訓練,而是評估行為變化是否真的變“穩”了。用LLaMA-Factory online先對固定客服評估集跑小規模微調、對比不同 checkpoint 在拒答、轉人工、安撫語氣上的差異,比直接全量上線要安全得多,也更容易和業務方對齊預期。
總結:智能客服的微調,本質是一次“風險管理決策”
如果要給這篇文章一個真正的結論,那應該是這句話:
在智能客服裏,你調的不是模型能力,
而是系統願意承擔的風險邊界。
當你把微調當成“能力增強”,
它往往會反噬你;
當你把微調當成“行為收斂工具”,
它才會發揮真正的價值。
真正成熟的客服系統,從來不是“模型多強”,
而是在複雜、模糊、充滿情緒的場景裏,依然能穩住。
你選一個,我繼續按這套標準寫。