

大多數向量數據庫項目,不是“失敗”,而是“半死不活”
如果你問一個已經上線向量數據庫的團隊:
“你們的向量檢索效果怎麼樣?”
得到的回答往往是:
- “還行吧,有時候挺準”
- “大部分時候能用,但偶爾很怪”
- “不好説,反正模型有時候答得不對”
這類系統,通常不是完全不能用,
但也很少讓人真正放心。
原因並不在於向量數據庫“不成熟”,
而在於:從建庫到穩定可用,中間有一整段工程空白,被嚴重低估了。
一個必須先説清楚的現實:向量數據庫實戰 ≠ 建庫成功
很多教程,會把“向量數據庫實戰”理解成:
- 選一個向量庫
- 把 embedding 存進去
- 調用 search 接口
但在真實項目裏,這三步只是:
“系統剛剛有可能開始工作”
真正決定成敗的,是後面這些問題:
- 數據怎麼進來
- 文檔怎麼切
- 檢索結果怎麼用
- 出問題怎麼排查
- 迭代時怎麼不把系統搞崩
第一步:選向量數據庫之前,你必須先搞清楚“你要它幹嘛”
這是幾乎所有實戰翻車的起點。
很多人選向量數據庫的理由是:
“RAG 不是都要用嗎?”
但在工程上,這是一個非常危險的動機。
在真正選型前,你至少要回答清楚三件事:
- 你要解決的是模糊匹配,還是精確查詢?
- 數據規模是幾千、幾十萬,還是上千萬?
- 查詢是高併發在線,還是低頻內部使用?
不同答案,對向量數據庫的要求,完全不同。
第二步:Embedding 選型,往往比數據庫本身更重要
這是一個非常容易被忽略的事實。
在向量數據庫實戰中,embedding 模型幾乎定義了你整個系統的“世界觀”。
因為一旦 embedding 選定:
- 什麼算相似
- 什麼算不相似
- 哪些差異會被忽略
這些判斷,就已經被固化進向量空間了。
如果 embedding 本身就不適合你的領域,
那後面所有檢索優化,基本都是在“補救”。

不同 embedding 模型導致的相似性差異示意圖
一個真實工程現象:embedding 一換,系統像換了一個腦子
很多團隊在系統上線一段時間後,會嘗試升級 embedding。
然後你會看到:
- 原本很準的問題,突然不準了
- 原本答不出來的問題,突然能答了
- 整體行為變得難以預測
這是因為:
向量數據庫不是“無狀態組件”,
它的行為強烈依賴 embedding 的語義空間。
所以在實戰中,embedding 版本管理,是必須被認真對待的。
第三步:建庫之前,先把“切分策略”當成核心工程
這一點前面那篇《RAG 文檔切分》已經講過很多,但在實戰裏,還是值得再強調一次。
在向量數據庫裏:
- 你檢索的不是“文檔”
- 而是 chunk
而 chunk 的質量,直接決定:
- 檢索是否命中
- 命中的內容是否可用
如果你在建庫時,隨意切分、一次性切完所有文檔,
那後面你幾乎一定會後悔。
切分策略在向量庫中的位置示意圖
第四步:建庫成功,只是“第一天不報錯”
很多人第一次看到:
vector_db.insert(embeddings)
不報錯,
查詢能返回結果,
就會產生一種錯覺:
“向量數據庫這塊,應該沒問題了。”
但從工程經驗來看,這只是:
第一天不報錯而已
真正的問題,往往在:
- 數據量上來之後
- 查詢變複雜之後
- 業務開始依賴結果之後
一個非常真實的場景:TopK 一開始看起來很準,後來越來越怪
在向量數據庫實戰中,你幾乎一定會遇到這個階段。
初期:
- 數據少
- 文檔乾淨
- TopK=3 很準
後期:
- 數據越來越多
- 文檔類型混雜
- TopK=3 開始頻繁命中“看起來相關,但沒用”的內容
這不是數據庫退化了,
而是數據分佈變了,而你的策略沒變。
第五步:你遲早要面對“相似但不可用”的檢索結果
這是向量數據庫實戰中最頭疼、但無法迴避的問題。
你會看到很多這樣的結果:
- embedding 分數很高
- 關鍵詞命中
- 但內容缺條件、缺結論、缺上下文
在這一刻,你會意識到:
向量數據庫只負責“找像的”,
不負責“找對的”。
這也是為什麼,單純的向量檢索,在真實系統裏,幾乎一定不夠。
Rerank:向量數據庫從“能用”到“好用”的分水嶺
在很多真實項目中,向量數據庫效果的質變,發生在引入 rerank 的那一刻。
向量檢索解決的是:
- 快速召回
- 模糊匹配
Rerank 解決的是:
- 精細排序
- 可用性判斷
如果你只用向量數據庫,不做 rerank,
那系統遲早會被噪聲淹沒。
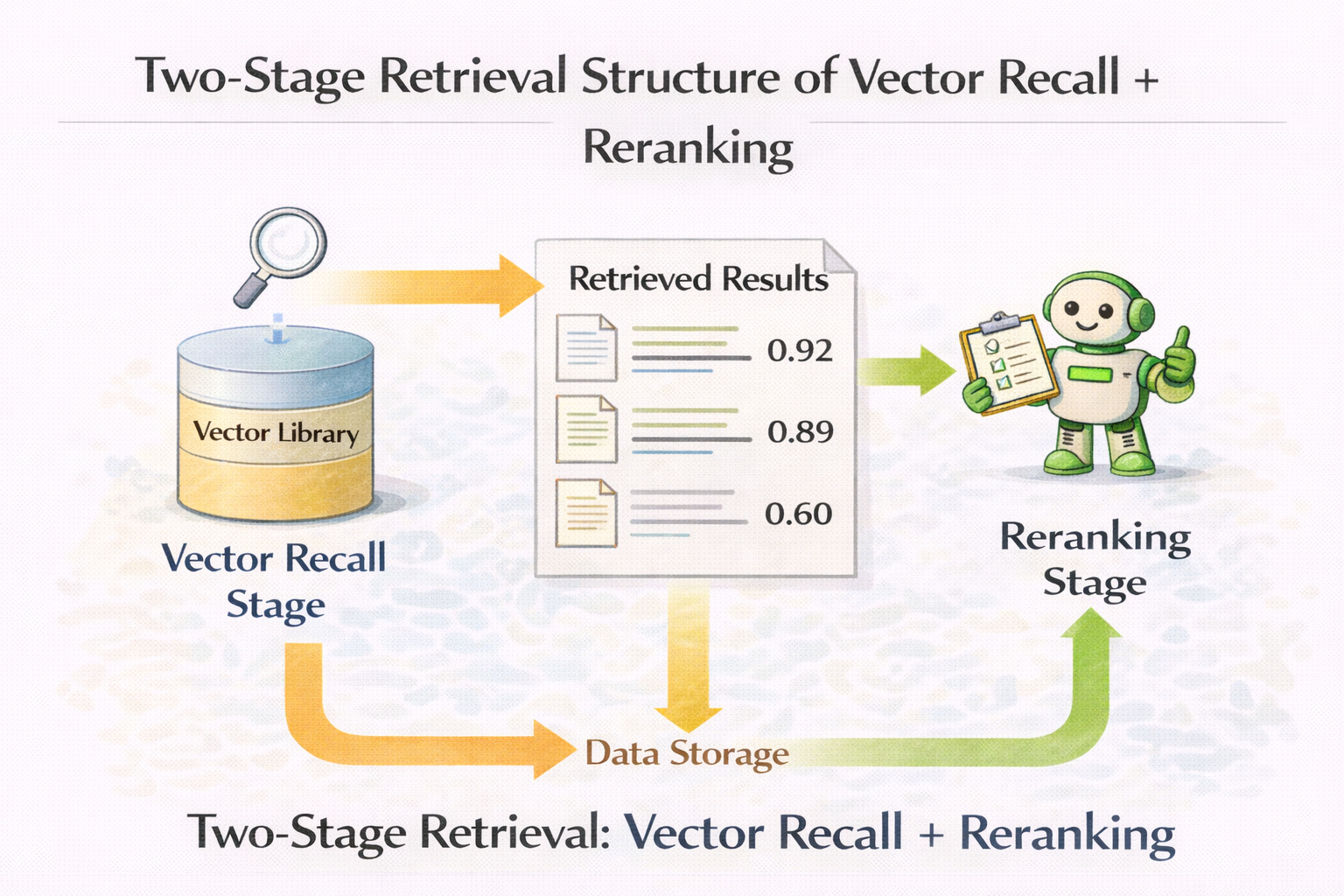
向量召回 + rerank 的兩階段檢索結構圖
一個簡化但真實的兩階段檢索示例
candidates = vector_db.search(query, top_k=20)
reranked = rerank_model.rank(query, candidates)
final = reranked[:3]
這段代碼看起來很簡單,
但它背後表達的是一個非常重要的工程認知:
向量數據庫適合做“第一輪篩選”,
而不是最終裁決。
第六步:你需要為“壞結果”設計排查路徑
這是很多團隊在實戰中才意識到的事。
當用户反饋:
“這個問題答錯了。”
你必須能回答:
- 是沒檢索到?
- 還是檢索到了但沒用?
- 是切分問題?
- embedding 問題?
- 還是模型生成問題?
如果你回答不上來,
那系統就不可維護。
一個實用但樸素的排查順序
在實戰中,我非常推薦下面這個順序:
- 固定模型,不動生成
- 只看檢索結果本身
- 人工判斷是否“可用”
- 再考慮 rerank / prompt
這個順序,能幫你避免 80% 的誤判。
第七步:向量數據庫不是“一次性工程”,而是長期系統
這是很多團隊在後期最痛的地方。
向量數據庫一旦成為系統依賴,你就必須考慮:
- 數據更新策略
- 向量重建成本
- embedding 升級影響
- 歷史版本回滾
這時候你會發現:
向量數據庫,已經不是一個“組件”,
而是系統的一部分。
一個常被忽略的問題:向量數據庫的評估方式
很多團隊在評估向量數據庫效果時,只看最終答案。
但在實戰中,更合理的評估應該拆成:
- 是否命中正確 chunk
- 命中的 chunk 是否可用
- 模型是否正確使用了 chunk
如果第一步就失敗了,
後面討論模型沒有意義。
什麼時候你應該停下來,重新考慮向量數據庫
這是一個很重要、但很多人不願面對的問題。
如果你發現:
- 數據規模其實不大
- 問題類型高度集中
- 規則能解決大部分問題
那向量數據庫,很可能已經變成負資產。
一個更健康的實戰策略:先小規模跑通,再放大
在真實工程中,一個更穩妥的路徑往往是:
- 少量核心文檔
- 多種切分方式
- 不同 embedding 對比
- 人工強介入評估
而不是一開始就:
- 全量建庫
- 高併發上線
在向量數據庫實戰的早期階段,如果你還在反覆驗證“向量檢索到底是不是適合當前業務”,用LLaMA-Factory online先快速搭一套 RAG + 向量檢索原型、對比不同 embedding 和切分策略下的真實輸出效果,會比直接投入完整向量庫工程更容易看清問題本質,也更容易止損。
總結:向量數據庫實戰,難的從來不是“用”,而是“用對”
如果要用一句話總結向量數據庫實戰,那應該是:
向量數據庫不是“裝上就行”的基礎設施,
而是一個會深度影響系統行為的核心組件。
真正成熟的實戰,不是問:
- “這個向量庫性能夠不夠?”
而是問:
- “這個問題,本質上是不是一個相似性問題?”
當你能清楚地回答這個問題時,
向量數據庫,才會成為資產,而不是拖累。