

一、前言
在分佈式系統架構中,消息隊列如同暢通的“信息神經網絡”,承擔着解耦、削峯與異步通信的核心使命。在眾多成熟方案中,RocketMQ憑藉其阿里巴巴與Apache雙重基因,以卓越的金融級可靠性、萬億級消息堆積能力和靈活的分佈式特性脱穎而出,成為構建高可用、高性能數據流轉樞紐的關鍵技術選型。本文將深入解析RocketMQ的核心架構、設計哲學與實踐要義。
二、RocketMQ架構總覽
官網圖片

RocketMQ架構上主要分為四部分,如上圖所示:
RocketMQ作為一款高性能、高可用的分佈式消息中間件,其核心架構採用了經典的四組件協同設計,實現了消息生產、存儲、路由與消費的全鏈路解耦與高效協同。四大組件——生產者(Producer)、消費者(Consumer)、路由中心(NameServer)和代理服務器(Broker)——各司其職,共同構建了其堅實的基石。
生產者(Producer) 作為消息的源頭,負責將業務消息高效、可靠地發佈到系統中。它支持分佈式集羣部署,並通過內置的智能負載均衡機制,自動選擇最優的Broker節點與隊列進行投遞。
消費者(Consumer) 是消息的處理終端,同樣以集羣化方式工作,支持推送(Push)和拉取(Pull)兩種消息獲取模式。它提供了集羣消費與廣播消費兩種模式,並能動態維護其訂閲關係。
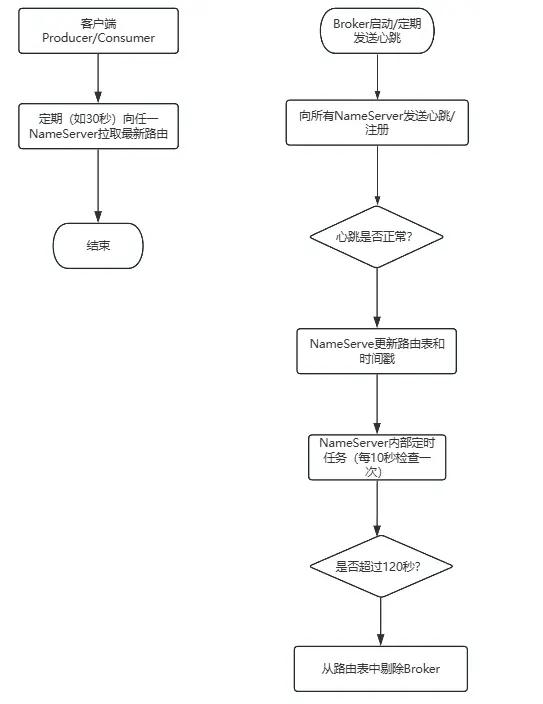
路由中心(NameServer) 是整個架構的“註冊中心”,扮演着輕量級服務發現的角色。所有Broker節點都會向NameServer註冊,並通過定期心跳彙報健康狀態。生產者與消費者則從NameServer獲取實時的主題路由與Broker信息,從而實現消息尋址的完全解耦。
代理服務器(Broker) 是消息存儲與流轉的核心,負責消息的持久化存儲、投遞與查詢。為了保障高可用性,Broker通常採用主從(Master-Slave)部署架構,確保數據與服務在故障時能無縫切換。其內部集成了通信處理、存儲引擎、索引服務和高可用複製等核心模塊。
三、核心組件深度解析
NameServer:輕量級服務發現樞紐
NameServer是RocketMQ的輕量級服務發現與路由中心, 其核心目標是實現生產消費與Broker服務的解耦。 它不存儲消息數據,僅管理路由元數據。
核心是一張的路由表 HashMap<String/ Topic /, List<QueueData>>,記錄了每個Topic對應在哪些Broker的哪些隊列上。
客户端內置了故障規避機制。如果從某個NameServer獲取路由失敗,或根據路由信息訪問Broker失敗,會自動重試其他NameServer或Broker。
1. 核心角色與設計哲學: NameServer的設計哲學是 “簡單、無狀態、最終一致” 。 每個NameServer節點獨立運行,節點間互不通信, 這使其具備極強的水平擴展能力和極高的可用性。客户端會配置所有NameServer地址,並向其廣播請求。
2. 核心工作機制: 其運作圍繞路由信息的生命週期展開,可通過下圖一覽其核心流程:
3. 和kafka註冊中心對比
- NameServer 採用 “去中心化” 和 “最終一致” 思想,追求極致的簡單、輕量和水平擴展, 犧牲了強一致性,以換取架構的簡潔和高可用。這非常適合路由信息變動不頻繁、客户端具備容錯能力的消息場景。
- Kafka (KRaft) 採用 “中心化” 和 “強一致” 思想,追求數據的精確和系統的自包含。 它將元數據管理深度內化,通過共識協議保證全局一致,但代價是架構複雜度和運維成本更高。
優劣分析: NameServer在運維簡易性、集羣擴展性、無外部依賴上佔優;而Kafka KRaft在元數據強一致性、系統自包含、架構統一性上更勝一籌。選擇取決於你對一致性、複雜度、運維成本的具體權衡。
Broker:消息存儲與轉發的核心引擎
解密存儲文件設計
Broker目錄下的文件結構

所有核心存儲文件均位於Broker節點的 ${storePathRootDir}/store/ 目錄下(默認路徑為 ~/store/),其下各子目錄職責分明:
| 目錄/文件 | 核心職責 | 關鍵設計説明 |
|---|---|---|
| commitlog/ | 消息實體存儲庫 | • 設計:所有Topic的消息順序混合追加寫入。• 文件:以起始物理偏移量命名(20位數字),默認每個1GB。lock文件確保同一時刻只有一個進程寫入,保障嚴格順序寫。 |
| consumequeue/ | 邏輯消費隊列索引 | • 結構:按 {Topic}/{QueueId}/三級目錄組織。 • 文件:存儲定長記錄(20字節/條),包含物理偏移量、長度和Tag哈希碼。 • 作用:為消費者提供按Topic和隊列分組的邏輯視圖,實現高效拉取。 |
| index/ | 消息鍵哈希索引 | • 文件:以創建時間戳命名(如20240515080000000)。 • 結構:採用 “哈希槽 + 鏈表” 結構。 • 用途:支持根據 Message Key 或時間範圍進行消息查詢,用於運維排查。 |
| config/ | 運行時元數據 | • 存儲Broker運行期間生成的動態數據,如所有Topic的配置、消費者組的消費進度(offset) 等。 |
| checkpoint | 狀態檢查點文件 | • 記錄 commitlog、consumequeue、index等文件最後一次刷盤的時間戳,用於崩潰恢復時確定數據恢復的起點。 |
| abort | 異常關閉標誌文件 | • 該文件存在即表明Broker上一次是非正常關閉,重啓時會觸發恢復流程。 |
| lock | 鎖文件 | • lock文件確保同一時刻只有一個進程寫入,保障嚴格順序寫。 |
commitLog
消息主體以及元數據的存儲主體, 存儲Producer端寫入的消息主體內容,消息內容不是定長的。 單個文件大小默認1G, 文件名長度為20位,左邊補零,剩餘為起始偏移量, 比如00000000000000000000代表了第一個文件,起始偏移量為0,文件大小為1G=1073741824;當第一個文件寫滿了,第二個文件為00000000001073741824,起始偏移量為1073741824,以此類推。消息主要是順序寫入日誌文件,當文件滿了,寫入下一個文件;
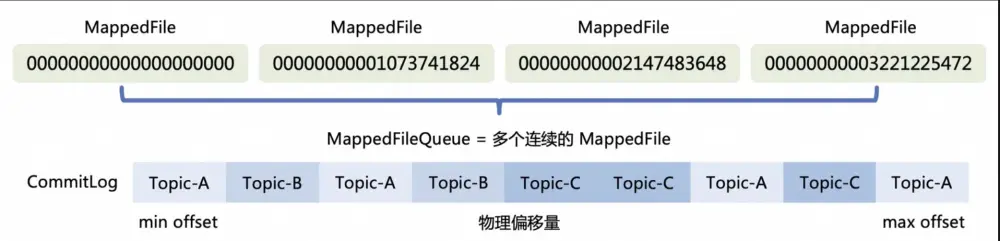
當我們消息發送到RocketMQ以後,消息在commitLog中,因為body大小是不固定的,所以每個消息的長度也是不固定的,其存儲格式如下:

下面每個表格列舉了每個字段的含義
| 字段 | 字段名 | 數據類型 | 字節數 | 説明與用途 |
|---|---|---|---|---|
| 1 | MsgLen / TOTALSIZE | int | 4 | 消息總長度,即從本字段開始到結束的總字節數,是解析消息的起點。 |
| 2 | MagicCode | int | 4 | 魔術字,固定值(如 0xdaa320a7),用於標識這是一個有效的消息存儲起始點,也用於區分消息體和文件末尾空白填充區。 |
| 3 | BodyCRC | int | 4 | 消息體內容的CRC校驗碼, 用於校驗消息體在存儲過程中是否損壞。 |
| 4 | QueueId | int | 4 | 隊列ID,標識此消息屬於Topic下的哪個邏輯隊列。 |
| 5 | Flag | int | 4 | 消息標誌位,供應用程序自定義使用,RocketMQ內部未使用。 |
| 6 | QueueOffset | long | 8 | 消費隊列偏移量,即此消息在其對應ConsumeQueue中的順序索引,是連續的。 |
| 7 | PhysicalOffset | long | 8 | 物理偏移量,即此消息在所有CommitLog文件中的起始字節偏移量。由於消息長度不定,此偏移量不是連續的。 |
| 8 | SysFlag | int | 4 | 系統標誌位,是一個二進制組合值,用於標識消息特性,如:是否壓縮、是否為事務消息、是否等待事務提交等。 |
| 9 | BornTimestamp | long | 8 | 消息生成時間戳,由Producer客户端在發送時生成。 |
| 10 | BornHost | 8字節 | 8 | 消息發送者地址。其編碼並非簡單字符串,而是將IP的4個段和端口號的2個字節,共6個字節,按大端序組合並填充到8字節中。 |
| 11 | StoreTimestamp | long | 8 | 消息存儲時間戳,即Broker收到消息並寫入內存的時間。 |
| 12 | StoreHost | 8字節 | 8 | Broker存儲地址,編碼方式同BornHost。 |
| 13 | ReconsumeTimes | int | 4 | 消息重試消費次數,用於死信隊列判斷。 |
| 14 | PreparedTransationOffset | long | 8 | 事務消息專用,存儲與之關聯的事務日誌(Transaction Log)的偏移量。 |
| 15 | BodyLength | int | 4 | 消息體實際長度,後跟Body內容。 |
| 16 | Body | byte[] | 不定 | 消息體內容,即Producer發送的原始業務數據。 |
| 17 | TopicLength | byte | 1 | Topic名稱的長度(1字節,因此Topic名不能超過255字符)。 |
| 18 | Topic | byte[] | 不定 | Topic名稱的字節數組。 |
| 19 | PropertiesLength | short | 2 | 消息屬性長度,後跟Properties內容。 |
| 20 | Properties | byte[] | 不定 | 消息屬性,用於存儲用户自定義的Key-Value擴展信息。在編碼時,Key和Value之間用特殊不可見字符(如\u0001)分隔,因此屬性中不能包含這些字符。 |
ConsumeQueue
消息消費索引,引入的目的主要是提高消息消費的性能。 由於RocketMQ是基於主題topic的訂閲模式,消息消費是針對主題進行的,如果要遍歷commitlog文件,根據topic檢索消息是非常低效的。
為了解決這個問題中,提高消費時候的速度,RocketMQ會啓動後台的 dispatch 線程源源不斷的將消息從 commitLog 取出消息在 CommitLog 中的物理偏移量,消息長度以及 Tag Hash 等信息作為單條消息的索引,分發到對應的消費隊列,構成了對 CommitLog 的引用。
consumer可根據ConsumeQueue來查找待消費的消息。其中,ConsumeQueue作為消費消息的索引,保存了指定Topic下的隊列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。
consumequeue文件可以看成是基於topic的commitlog索引文件, 故consumequeue文件夾的組織方式如下:
$HOME/store/consumequeue/{topic}/{queueId}/{fileName}
consumequeue文件採取定長設計, 每一個條目共20個字節,前8字節的commitlog物理偏移量、中間4字節的消息長度、8字節tag的hashcode。

indexFile
RocketMQ的IndexFile索引文件提供了通過消息Key或時間區間查詢消息的能力,其存儲路徑為$HOME/store/index/{fileName},其中文件名以創建時間戳命名。單個IndexFile文件大小固定約為400M,可保存2000W個索引,其底層採用類HashMap的哈希索引結構實現。
IndexFile是一個固定大小的文件(約400MB),其物理結構由三部分組成

1.IndexHeader(索引頭,40字節)
beginTimestamp: 第一條消息存儲時間
endTimestamp: 最後一條消息存儲時間
beginPhyoffset: 第一條消息在CommitLog中的物理偏移量
endPhyoffset: 最後一條消息在CommitLog中的物理偏移量
hashSlotCount: 已使用的哈希槽數量
indexCount: 索引單元總數

2.Slots(哈希槽)
每個IndexFile包含500萬個哈希槽位,每個Slot槽位(4字節)存儲的是鏈式索引的第一個索引序號,每個槽位可掛載多個索引單元,形成鏈式結構。
- 如果Slot值為0:表示該槽位沒有索引鏈
- 如果Slot值為N:表示該槽位對應的索引鏈頭節點索引序號為N
3.Indexes(索引單元,20字節/個)
每個索引單元包含以下字段:
- keyHash: 消息Key的哈希值
- phyOffset: 消息在CommitLog中的物理偏移量
- timeDiff: 消息存儲時間與IndexFile創建時間的差值
- preIndexNo: 同一哈希槽中前一個索引單元的序號

這個結構和hashmap結構很像,但是支持每個key通過時間排序,就可以進行時間範圍的檢索。
通過定長索引結構和整體設計可以通過key快速定位索引數據,拿到真實數據的物理偏移量。
4.索引查詢流程
消費者通過消息Key查詢時,執行以下步驟:
- 計算槽位序號slot序號 = key哈希值 % 500萬
- 定位槽位地址slot位置 = 40 + (slot序號 - 1) × 4
- 獲取首個索引位置index位置 = 40 + 500萬 × 4 + (索引序號 - 1) × 20
- 遍歷索引鏈從槽位指向的索引開始,沿preIndexNo鏈式查找,匹配目標Key並校驗時間範圍
- 獲取物理偏移量從匹配的索引單元中讀取phyOffset,最終從CommitLog獲取完整消息內容
通過此機制,IndexFile實現了基於Key的高效點查和基於時間範圍的快速檢索。
整體流程
RocketMQ 高性能存儲的核心,在於其 “混合存儲” 架構,這正是一種精妙的存儲層讀寫分離設計。
其工作流程可以這樣理解:
- 統一寫入,保證極致性能: 所有消息順序追加寫入一個統一的 CommitLog 文件。這種單一的順序寫操作,是它能承受海量消息寫入的根本。
- 異步構建,優化讀取路徑: 消息一旦持久化至 CommitLog,即視為安全。隨後,後台服務線程會異步地構建出專供消費的 ConsumerQueue(邏輯隊列索引)和用於查詢的 IndexFile。這相當於為數據建立了高效的“目錄”。
- 消費消息: 消費者實際拉取消息時,是先讀取 ConsumerQueue 找到消息在 CommitLog 中的物理位置,再反查 CommitLog 獲取完整消息內容。
- 可靠的消費機制: 基於上述持久化保障,配合消費者自身的偏移量管理及Broker的長輪詢機制,共同實現了消息的可靠投遞與高效獲取。
這種 “讀寫分離” 設計的好處在於:將耗時的寫操作(順序寫CommitLog)與複雜的讀操作(構建索引、分散查詢)解耦,讓兩者可以異步、獨立地進行優化,從而在整體上獲得更高的吞吐量和更低的延遲。這體現了“各司其職,異步協同”的經典架構思想。
下圖是官方文檔的流程圖

寫入流程
1.消息預處理
基礎校驗: 檢查Topic名稱、消息體長度等是否合法。
生成唯一ID: 結合Broker地址和CommitLog偏移量等,生成全局唯一的MsgID。
設置系統標誌: 根據消息屬性(如是否事務消息、是否壓縮)設置SysFlag。
2.CommitLog核心寫入
獲取MappedFile: 根據當前寫入位置,定位或創建對應的1GB內存映射文件。這裏採用雙重檢查鎖模式來保證性能和安全。
串行加鎖寫入: 獲取全局或文件級鎖(PutMessageLock),確保同一時刻只有一個線程寫入文件,嚴格保證順序性。
序列化與追加: 將消息按照之前分析的二進制協議, 序列化到MappedByteBuffer中,並更新寫入指針。
3.刷盤(Flush)
同步刷盤: 消息寫入內存映射區後,會創建一個GroupCommitRequest並放入請求組。寫入線程會等待,直到刷盤線程完成該請求對應文件的物理刷盤後,才返回成功給Producer。數據最可靠,但延遲較高。
異步刷盤(默認): 消息寫入內存映射區後,立即返回成功給Producer。同時喚醒異步刷盤線程, 該線程會定時或當PageCache中待刷盤數據積累到一定量時,執行一次批量刷盤。性能高,但有宕機丟數風險。
4.異步索引構建
由獨立的ReputMessageService線程處理。它不斷檢查CommitLog中是否有新消息到達。
一旦有新消息被確認持久化(對於同步刷盤是已落盤,對於異步刷盤是已寫入映射區),該線程就會讀取消息內容。
隨後,它會為這條消息在對應的consumequeue目錄下構建消費隊列索引(記錄CommitLog物理偏移量和消息長度),更新index索引文件。
消費流程
1.啓動與負載均衡
消費者啓動後,會向NameServer獲取Topic的路由信息(包含哪些隊列、分佈在哪些Broker上)。
如果消費者組內有多個實例,會觸發隊列負載均衡(默認策略是平均分配)。例如,一個Topic有8個隊列,兩個消費者實例,則通常每個消費者負責消費4個隊列。這一步決定了每個消費者“認領”了哪些消息隊列。
2.拉取消息循環
每個消費者實例內部都有一個PullMessageService線程,它循環從一個PullRequest隊列中獲取任務。
PullRequest包含了拉取目標(如Broker-A, 隊列3)以及下一次要拉取的位點(offset)。
消費者向指定的Broker發送網絡請求,請求體中就攜帶了這個offset。
3.Broker端處理與返回
Broker收到請求後,根據Topic、隊列ID和offset,去查詢對應的ConsumeQueue索引文件。
ConsumeQueue中存儲的是定長(20字節)的記錄,包含消息在CommitLog中的物理偏移量和長度。
Broker根據物理偏移量,從CommitLog文件中讀取完整的消息內容,通過網絡返回給消費者。
4.消息處理與位點提交
消費者將拉取到的消息提交到內部的消費線程池進行處理,你的業務邏輯就在這裏執行。
消費位點的管理至關重要:
位點存儲: 位點由OffsetStore管理。在集羣模式(CLUSTER) 下,消費位點存儲在Broker上;在廣播模式(BROADCAST) 下,位點存儲在本地。
位點提交: 消費成功後,消費者會異步(默認方式)向Broker提交已消費的位點。Broker將其持久化到store/config/consumerOffset.json文件中。
5.消息重試與死信
如果消息消費失敗(拋出異常或超時未返回CONSUME_SUCCESS),RocketMQ會觸發重試機制。
對於普通消息,消息會被髮回Broker上一個特殊的重試主題(%RETRY%<ConsumerGroup>),延遲一段時間(延遲級別:1s、5s、10s…)後再被原消費者組拉取。
如果重試超過最大次數(默認16次),消息會被投遞到死信主題(%DLQ%<ConsumerGroup>),等待人工干預。死信隊列中的消息不會再被自動消費。
一體與分離:Kafka和RocketMQ的核心架構博弈
説起RocketMQ就不能不提起Kafka了,兩者都是消息中間件這個領域的霸主,但它們的核心架構設計差異, 直接決定了各自不同的性能特性和適用場景,這也是技術選型時必須深入理解的重點。
核心架構設計差異
Kafka:讀寫一體的“分區日誌”模型, Kafka的架構哲學是極簡與統一。 它將每個主題分區抽象為一個僅追加(append-only)的物理日誌文件。 生產者和消費者都直接與這個日誌文件交互:生產者順序寫入尾部,消費者通過維護偏移量順序讀取。這種設計下,數據的讀寫路徑完全一致, 邏輯與物理結構高度統一。
RocketMQ:讀寫分離的“二級制”模型 , RocketMQ的架構哲學是分工與優化。 它採用了物理CommitLog + 邏輯ConsumeQueue的二級結構。 所有消息都順序寫入一個統一的CommitLog物理文件,實現磁盤的最高效順序寫。同時,為每個消息隊列異步構建一個輕量級的ConsumeQueue索引文件,消費者讀取時先查詢內存中的ConsumeQueue定位,再到CommitLog中獲取消息體。這是一種邏輯與物理分離的設計。
優劣勢對比
基於上述架構設計根本差異,兩者在關鍵指標上各顯優劣:
| 維度 | Kafka(讀寫一體) | RocketMQ(讀寫分離) |
|---|---|---|
| 核心優勢 | 極致吞吐與低延遲:讀寫同路徑,數據寫入後立即可讀,端到端延遲極低。架構簡單:無中間狀態,副本同步、故障恢復邏輯清晰。 | 高併發讀與豐富功能:索引與數據分離,支持海量消費者併發讀。業務友好:原生支持事務消息、定時/延時消息、消息軌跡查詢。 |
| 存儲效率 | 磁盤順序IO最大化:生產和消費都是嚴格順序IO,尤其適合機械硬盤。 | 寫性能極致化:所有消息順序寫CommitLog,但存在“寫放大” ,一條消息需寫多次(1次CommitLog + N次ConsumeQueue)。 |
| 讀性能 | 消費者落後時可能觸發隨機讀:若消費者要讀取非尾部歷史數據,可能需磁盤尋道。但現代SSD和預讀機制已大大緩解此問題。 | 讀路徑優化:ConsumeQueue小而固定,可全量緩存至內存,讀操作變為“內存尋址 + CommitLog順序/隨機讀”。在PageCache命中率高時表現優異。 |
| 擴展性與成本 | 文件句柄(inode)開銷大:每個分區都是獨立目錄和文件,海量分區時運維成本高。 | 存儲成本與效率更優:多Topic共享CommitLog,文件數少,特別適合中小消息體、多Topic的場景。 |
| 典型場景 | 日誌流、指標監控、實時流處理:作為大數據管道,與Flink/Spark生態無縫集成。 | 電商交易、金融業務、異步解耦:需要嚴格順序、事務保障、業務查詢的在線業務場景。 |
總而言之,Kafka像一個設計精良的高速公路系統, 核心目標是讓數據車輛(消息)能夠高吞吐、低延遲地持續流動,並方便地引向各個處理工廠(流計算)。而RocketMQ則像一個高度可靠的快遞網絡, 不僅確保包裹(消息)準確送達,還提供預約配送(定時)、簽收確認(事務)、異常重投(重試)等一系列服務於業務邏輯的增值功能。
RocketMQ對於隨機讀取的優化
RocketMQ在消費時候的流程
消費者請求 → ConsumeQueue(內存/順序)獲取commitlog上的物理偏移量 → 根據物理偏移量定位CommitLog(磁盤/隨機) → 返回消息從ConsumeQueue獲取到消息在commitlog中的偏移量的時候,回查時候可能產生隨機IO
- 第一次隨機IO: 根據ConsumeQueue中的物理偏移量,在CommitLog中定位消息位置
- 可能的連續隨機IO: 如果一次拉取多條消息,這些消息在CommitLog中可能物理不連續
為了保證RocketMQ的高性能,採用一些優化措施,儘量避免隨機IO
1. ConsumeQueue的內存映射優化
實際上,RocketMQ將ConsumeQueue映射到內存,每個ConsumeQueue約5.72MB,可完全放入PageCache,讀索引操作幾乎是內存操作。
public class ConsumeQueue {
private MappedFile mappedFile; // 內存映射文件
// 20字節每條:8(offset) + 4(size) + 8(tagHashCode)
}2. PageCache的充分利用
Linux PageCache工作流程:
- 消息寫入CommitLog → 進入PageCache
- 消費者讀取 → 優先從PageCache獲取
- 如果PageCache命中:內存速度(≈100ns)
- 如果PageCache未命中:磁盤隨機讀取(≈10ms)
3. 批量讀取優化
// DefaultMessageStore.java
public GetMessageResult getMessage(...) {
// 一次讀取多條消息(默認最多32條)
// 即使這些消息物理不連續,通過批量讀取減少IO次數
for (int i = 0; i < maxMsgNums; i++) {
// 使用同一個文件channel批量讀取
readMessage(ctx, msgId, consumerGroup);
}
}4. 讀取順序性的保持
雖然CommitLog中不同Topic的消息是隨機存放的,但同一個Queue的消息在CommitLog中是基本連續的:
Queue1: | Msg1 | Msg3 | Msg5 | ... | 在ConsumeQueue中連續
↓ ↓ ↓
CommitLog: | Msg1 | Msg2(T2) | Msg3 | Msg4(T3) | Msg5 |
↑_________________________↑
物理上相對連續,減少磁頭尋道高可用設計:雙軌並行的可靠性架構
主從架構(Master-Slave)
經典主從模式: RocketMQ早期採用Master-Slave架構,Master處理所有讀寫請求,Slave僅作為熱備份。這種模式下,故障切換依賴人工干預或半自動腳本, 恢復時間通常在分鐘級別。
Dledger高可用集羣: RocketMQ 4.5引入的Dledger基於Raft協議實現真正的主從自動切換。 當Master故障時,集羣能在秒級(通常2-10秒)內自動選舉新Leader,期間消息仍可寫入(寫入請求會阻塞至新Leader選出)。
多副本機制: 現代部署中,建議採用2主2從或3主3從架構。例如在阿里雲上,每個Broker組包含1個Master和2個Slave,形成跨可用區的三副本, 單機房故障不影響服務可用性。
同步/異步複製
同步複製保證強一致(消息不丟失),異步複製追求更高性能。
// Broker配置示例
brokerRole = SYNC_MASTER
// 生產者發送消息後,必須等待至少一個Slave確認
// 確保即使Master宕機,消息也不會丟失- 強一致性保證:消息寫入Master後,同步複製到Slave才返回成功
- 性能代價:延遲增加約30-50%,TPS下降約20-40%
- 適用場景:金融交易、資金變動等對數據一致性要求極高的業務
同步/異步刷盤
同步刷盤保證消息持久化不丟失,異步刷盤提升吞吐。
brokerRole = ASYNC_MASTER
// 消息寫入Master即返回成功,Slave異步複製
// 存在極短時間的數據丟失風險- 高性能模式: 延遲降低,吞吐量接近單節點性能
- 風險窗口: Master宕機且數據未同步時,最近幾秒消息可能丟失
- 適用場景: 日誌收集、監控數據、可容忍微量丟失的業務消息
刷盤策略的工程優化
同步刷盤(SYNC_FLUSH)
生產者 → Broker內存 → 磁盤強制刷盤 → 返回成功- 零數據丟失: 即使機器掉電,消息也已持久化到磁盤
- 性能瓶頸: 每次寫入都觸發磁盤IO,機械硬盤下TPS通常<1000
- 優化手段: 使用SSD硬盤可大幅提升性能
異步刷盤(ASYNC_FLUSH)
生產者 → Broker內存 → 立即返回成功 → 異步批量刷盤- 高性能選擇: 依賴PageCache,SSD下TPS可達數萬至數十萬
- 可靠性依賴: 依賴操作系統的刷盤機制(通常5秒刷盤一次)
- 配置調優:
# 調整刷盤參數
flushCommitLogLeastPages = 4 # 至少4頁(16KB)才刷盤
flushCommitLogThoroughInterval = 10000 # 10秒強制刷盤一次四、Producer與Consumer:高效的生產與消費模型
Producer
消息路由策略:
// 內置多種隊列選擇算法
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroup");
// 1. 輪詢(默認):均勻分佈到所有隊列
// 2. 哈希:相同Key的消息路由到同一隊列,保證局部順序
// 3. 機房就近:優先選擇同機房的Broker
producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
// 自定義路由邏輯
return mqs.get(arg.hashCode() % mqs.size());
}
});發送模式對比:
| 模式 | 特點 | 性能 | 適用場景 |
|---|---|---|---|
| 同步發送 | 阻塞等待Broker響應 | TPS約5000-20000 | 重要業務消息,需立即知道發送結果 |
| 異步發送 | 回調通知結果 | TPS可達50000+ | 高併發場景,如日誌、監控數據 |
| 單向發送 | 發送後不等待 | TPS最高(100000+) | 可容忍少量丟失的非關鍵數據 |
失敗重試與熔斷:
- 智能重試: 發送失敗時自動重試(默認2次),可配置退避策略
- 故障規避: 自動檢測Broker可用性,故障期間路由到健康節點
- 慢請求熔斷: 統計發送耗時,自動隔離響應慢的Broker
Consumer
負載均衡策略:
// 集羣模式:同一ConsumerGroup內消費者均分隊列
consumer.setMessageModel(MessageModel.CLUSTERING);
// 廣播模式:每個消費者消費全量隊列
consumer.setMessageModel(MessageModel.BROADCASTING);消費進度管理:
Broker託管: 默認方式,消費進度存儲在Broker
本地維護: 某些場景下可自主管理offset(如批量處理)
重置策略:
// 支持多種消費起點
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET); // 從最後
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET); // 從頭
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_TIMESTAMP); // 從時間點併發控制優化:
// 關鍵併發參數
consumer.setConsumeThreadMin(20); // 最小消費線程數
consumer.setConsumeThreadMax(64); // 最大消費線程數
consumer.setPullBatchSize(32); // 每次拉取消息數
consumer.setConsumeMessageBatchMaxSize(1); // 批量消費大小
// 流控機制
consumer.setPullThresholdForQueue(1000); // 隊列堆積閾值
consumer.setPullInterval(0); // 拉取間隔(0為長輪詢)五、核心流程與特性背後的架構支撐
1 .順序消息如何保證?
全局順序: 單Topic單隊列(犧牲併發)。
分區順序: 通過MessageQueue選擇器確保同一業務鍵(如訂單ID)的消息發往同一隊列,Consumer端按隊列順序消費。
2.事務消息的兩階段提交
流程詳解: Half Message -> 執行本地事務 -> Commit/Rollback。
架構支撐: Op消息回查機制,解決分佈式事務的最終一致性,是架構設計中“狀態可回溯”思想的體現。
3.延時消息的實現奧秘
並非真正延遲投遞: 為不同延遲級別預設獨立的SCHEDULE_TOPIC, 定時任務掃描到期後投遞至真實Topic。
設計權衡: 以存儲和計算換取功能的靈活與可靠。
六、其他性能優化關鍵技術點
- 零拷貝(Zero-copy): 通過sendfile或mmap+write方式,減少內核態與用户態間數據拷貝,大幅提升網絡發送與文件讀寫效率。
- 堆外內存與內存池: 避免JVM GC對大數據塊處理的影響,實現高效的內存管理。
- 文件預熱: 啓動時將存儲文件映射到內存並寫入“假數據”,避免運行時缺頁中斷。
七、總結:RocketMQ架構設計的啓示
RocketMQ的架構設計,尤其是其在簡潔性、高性能和雲原生演進方面的平衡,為構建現代分佈式系統提供了許多寶貴啓示。
- 在簡單與完備間權衡: RocketMQ沒有采用強一致性的ZooKeeper,而是自研了極其簡單的NameServer。這説明在非核心路徑上,犧牲一定的功能完備性來換取簡單性和高可用性,可能也是個不錯的選擇。
- 以寫定存儲,以讀優查詢: 其存儲架構是典型的寫優化設計。所有消息順序追加寫入,保證了最高的寫入性能。而針對消費和查詢這兩種主要的“讀”場景,則分別通過異步構建索引數據結構(ConsumeQueue和IndexFile)來優化。
八、參考資料
- RocketMQ官方文檔
- RocketMQ中文社區
往期回顧
1.PAG在得物社區S級活動的落地
2.Ant Design 6.0 嚐鮮:上手現代化組件開發|得物技術
3.Java 設計模式:原理、框架應用與實戰全解析|得物技術
4.Go語言在高併發高可用系統中的實踐與解決方案|得物技術
5.從0到1搭建一個智能分析OBS埋點數據的AI Agent|得物技術
文 /磊子
關注得物技術,每週更新技術乾貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。