

簡述
異地多活的概念以及為什麼要做異地多活這裏就不進行概述了。概念性的很多,像什麼同城雙活、兩地三中心、三地五中心等等概念。如果有對這些容災架構模式感興趣的可以閲讀下這篇文章進行了解:《淺談業務級災備的架構模式》。
閲讀本篇文章之前,我們先明確一下背景,這樣大家後續在看的時候就不會產生困惑。
1.1 機房劃分
得物多活改造一期目前有兩個機房,分別是機房A和機房B。文章中大部分圖中都會有標識,這就説明是兩個不同的機房。
A機房我們定義為中心機房,也就是多活上線之前正在使用的機房。如果説到中心機房那指的就是A機房。另一個B機房,在描述的時候可能會説成單元機房,那指的就是B機房。
1.2 單元化
單元化簡單點我們直接就可以認為是一個機房,在這個單元內能夠完成業務的閉環。比如説用户進入APP,瀏覽商品,選擇商品確認訂單,下單,支付,查看訂單信息,這整個流程都在一個單元中能夠完成,並且數據也是存儲在這個單元裏面。
做單元化無非就兩個原因,容災和提高系統併發能力。但是也得考慮機房建設的規模和技術,硬件等投入的成本。具體的就不多講了,大家大概理解了就行。
2. 改造點
瞭解改造點之前我們先來看下目前單機房的現狀是什麼樣子,才能更好的幫助大家去理解為什麼要做這些改造。
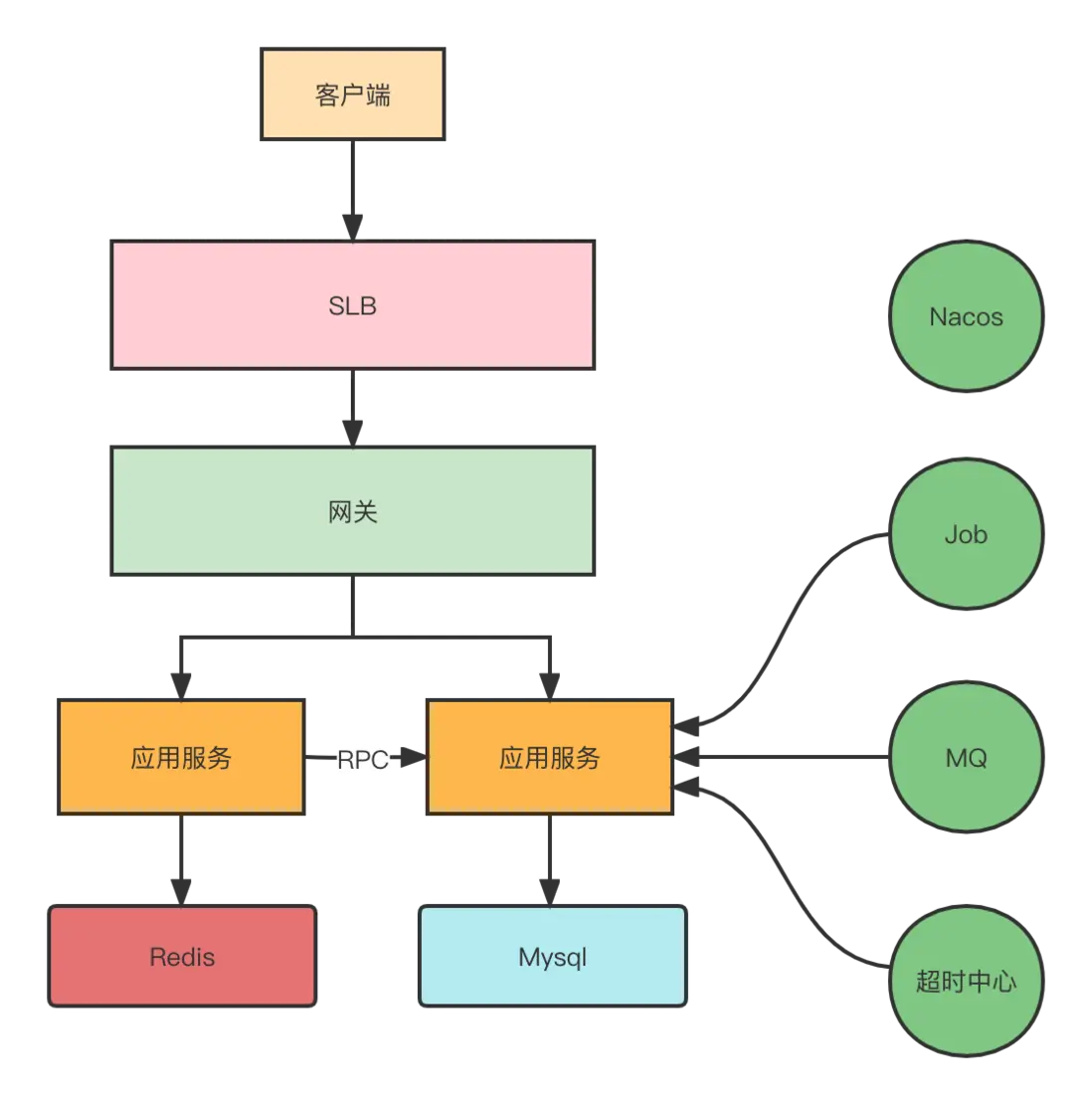
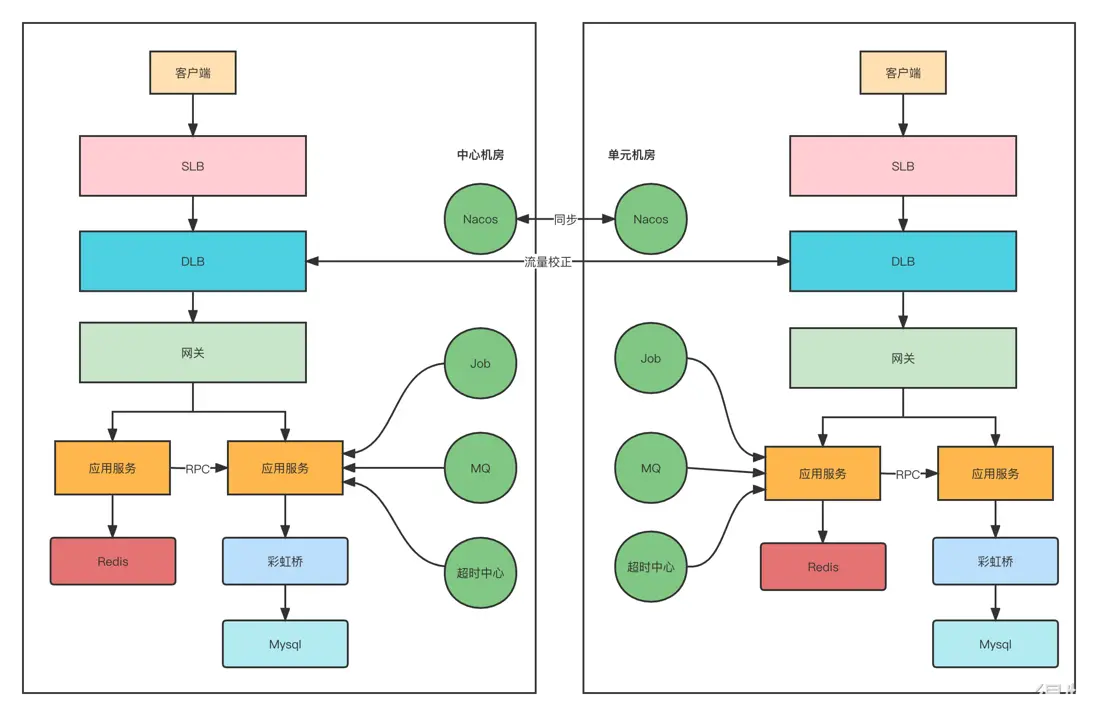
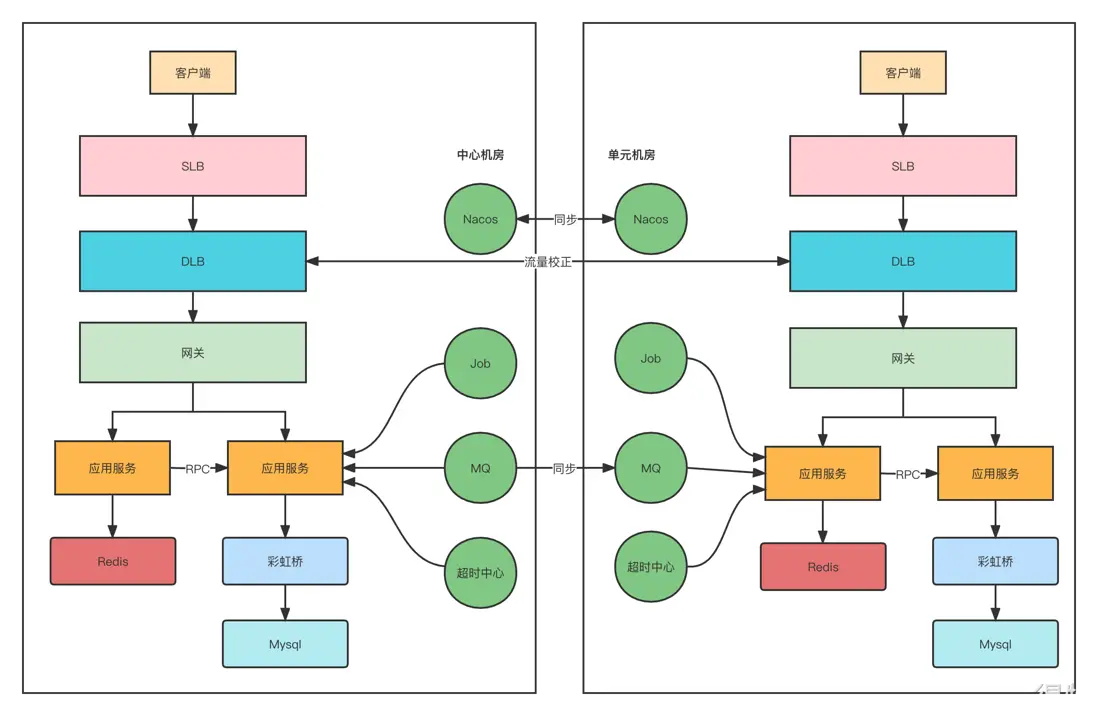
如上圖所示,客户端的請求進來會先到SLB(負載均衡),然後到我們內部的網關,通過網關再分發到具體的業務服務。業務服務會依賴Redis, Mysql, MQ, Nacos等中間件。
既然做異地多活,那麼必然是在不同地區有不同的機房,比如中心機房,單元機房。所以我們要實現的效果如下圖所示:
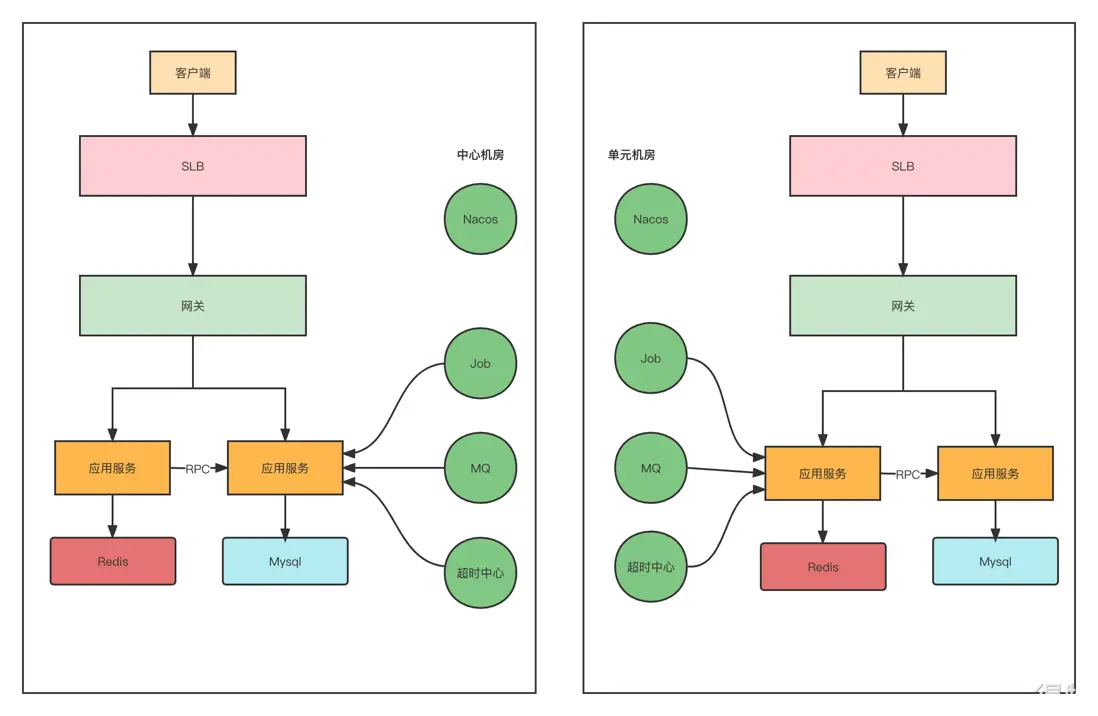
大家看上面這張圖可能會感覺很簡單,其實也就是一些常用的中間件,再多一個機房部署罷了,這有什麼難度。如果你這樣想我只能説一句:格局小了啊。
2.1 流量調度
用户的請求,從客户端發出,這個用户的請求該到哪個機房,這是我們要改造的第一個點。
沒做多活之前,域名會解析到一個機房內,做了多活後,域名會隨機解析到不同的機房中。如果按照這種隨機的方式是肯定有問題的,對於服務的調用是無所謂的,因為沒有狀態。但是服務內部依賴的存儲是有狀態的呀。
我們是電商業務,用户在中心機房下了一個單,然後跳轉到訂單詳情,這個時候請求到了單元機房,底層數據同步有延遲,一訪問報個錯:訂單不存在。 用户當場就懵了,錢都付了,訂單沒了。
所以針對同一個用户,儘可能在一個機房內完成業務閉環。為了解決流量調度的問題,我們基於OpenResty二次開發出了DLB流量網關,DLB會對接多活控制中心,能夠知道當前訪問的用户是屬於哪個機房,如果用户不屬於當前機房,DLB會直接將請求路由到該用户所屬機房內的DLB。
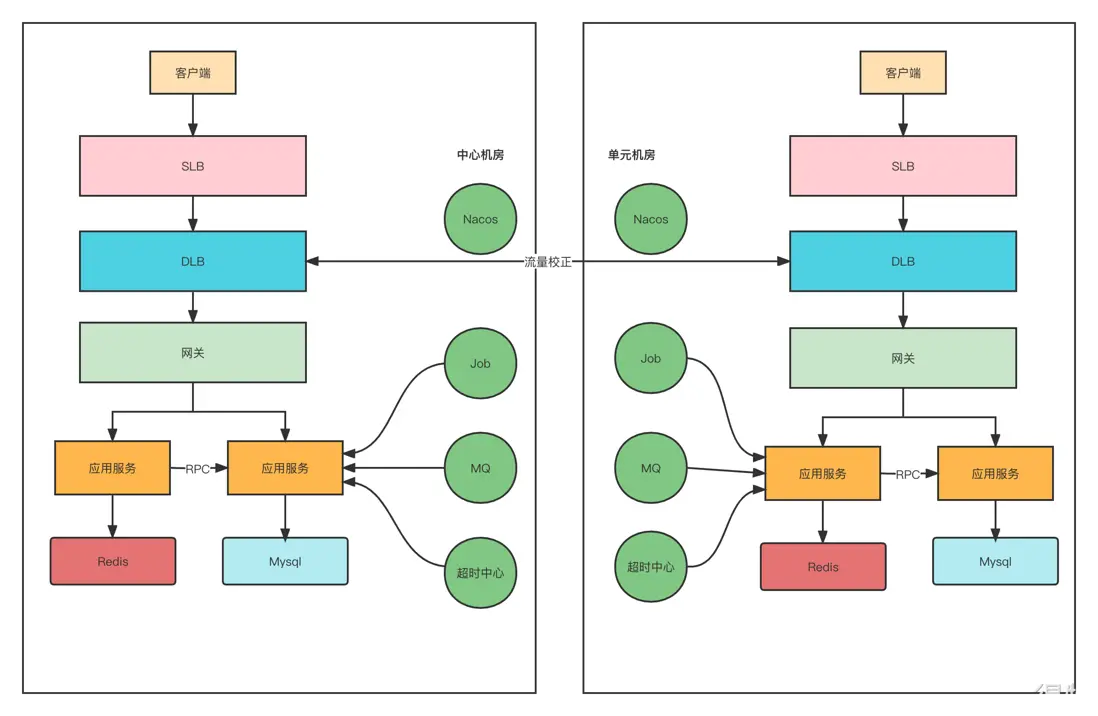
如果每次都隨機到固定的機房,再通過DLB去校正,必然會存在跨機房請求,耗時加長。所以在這塊我們也是結合客户端做了一些優化,在DLB校正請求後,我們會將用户對應的機房IP直接通過Header響應給客户端。這樣下次請求的時候,客户端就可以直接通過這個IP訪問。
如果用户當前訪問的機房掛了,客户端需要降級成之前的域名訪問方式,通過DNS解析到存活的機房。
2.2 RPC框架
當用户的請求達到了單元機房內,理論上後續所有的操作都是在單元機房完成。前面我們也提到了,用户的請求儘量在一個機房內完成閉環,只是儘量,沒有説全部。
這是因為有的業務場景不適合劃分單元,比如庫存扣減。所以在我們的劃分裏面,有一個機房是中心機房,那些不做多活的業務只會部署在中心機房裏面,那麼庫存扣減的時候就需要跨機房調用。
請求在中心機房,怎麼知道單元機房的服務信息?所以我們的註冊中心(Nacos)要做雙向同步,這樣才能拿到所有機房的服務信息。
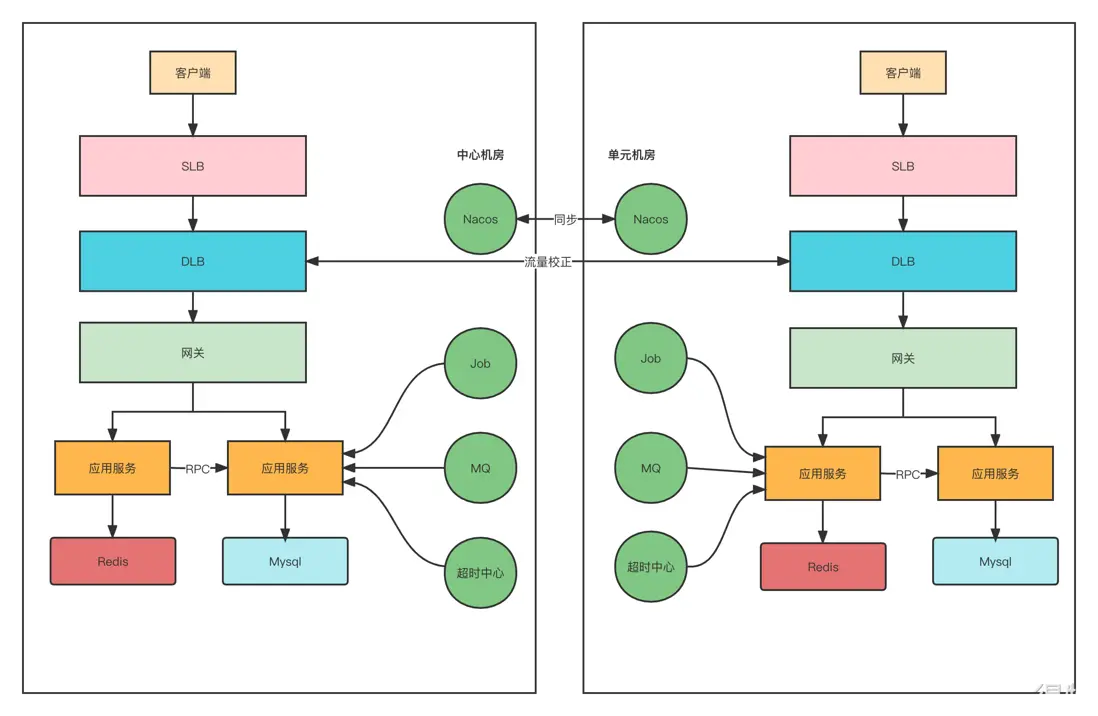
當我們的註冊信息採用雙向複製後,對於中心服務,直接跨機房調用。對於單元服務會存在多個機房的服務信息,如果不進行控制,則會出現調用其他機房的情況,所以RPC框架要進行改造。
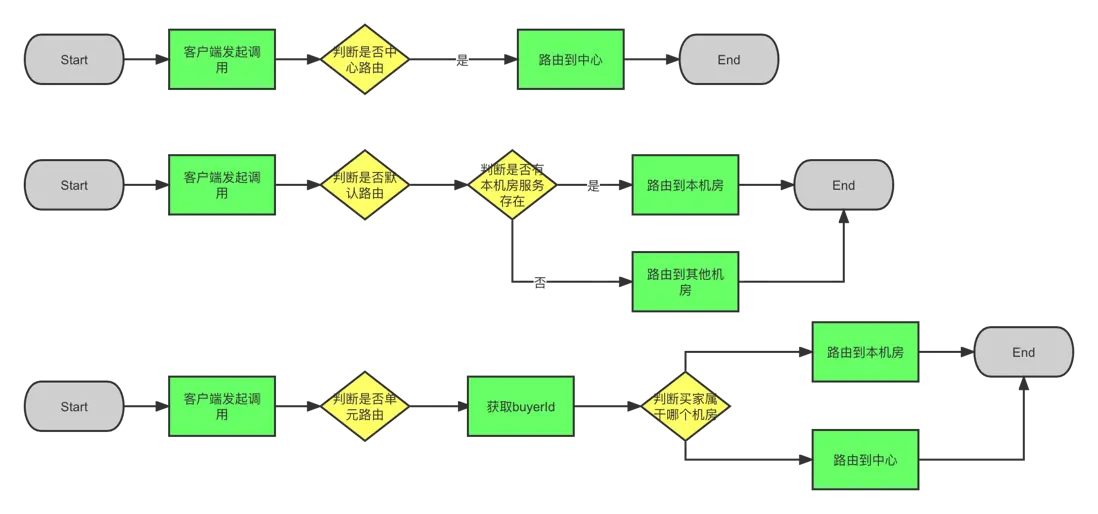
2.2.1 定義路由類型
- 默認路由
請求到中心機房,會優先調用中心機房內的服務,如果中心機房無此服務,則調用單元機房的服務,如果單元機房沒有此服務則直接報錯。
- 單元路由
請求到單元機房,那麼説明此用户的流量規則是在單元機房,接下來所有的RPC調用都只會調用單元機房內的服務,沒有服務則報錯。
- 中心路由
請求到單元機房,那麼直接調用中心機房的服務,中心機房沒有服務則報錯。請求到中心機房,那麼就本機房調用。
2.2.2 業務改造
業務方需要對自己的接口(Java interface)進行標記是什麼類型,通過@HARoute加在接口上面。標記完成後,在Dubbo接口進行註冊的時候,會把路由類型放入到這個接口的元數據裏面,在Nacos後台可以查看。後面通過RPC調用接口內部所有的方法都會按照標記類型進行路由。
如果標記為單元路由,目前我們內部的規範是方法的第一個參數為小寫的long buyerId,RPC在路由的時候會根據這個值判斷用户所在的機房。
路由邏輯如下:
2.2.3 改造過程
- 接口複製一份,命名為UnitApi,第一個參數加long buyerId。在新接口的實現裏面調用老接口,新舊接口共存。
- 將UnitApi發佈上線,此時沒有流量。
- 業務方需要升級其他域的API包,將老接口的調用切換為新的UnitApi,此處增加開關控制。
- 上線後,通過開關控制調用走UnitApi,有問題可關閉開關。
- 下線老的API,完成切換。
2.2.4 遇到的問題
2.2.4.1 其他場景切單元接口
除了RPC直接調用的接口,還有一大部分是通過Dubbo泛化過來的,這塊在上線後也需要將流量切到UnitApi,等老接口沒有請求量之後才能下線。
2.2.4.2 接口分類
接口進行分類,之前沒有多活的約束,一個Java interface中的方法可能各種各樣,如果現在你的interface為單元路由,那麼裏面的方法第一個參數都必須加buyerId,其他沒有buyerId場景的方法要挪出去。
2.2.4.3 業務層面調整
業務層面調整,比如之前查詢訂單隻需要一個訂單號,但是現在需要buyerId進行路由,所以接入這個接口的上游都需要調整。
2.3 數據庫
請求順利的到達了服務層,接下來要跟數據庫打交道了。數據庫我們定義了不同的類型,定義如下:
- 單元化
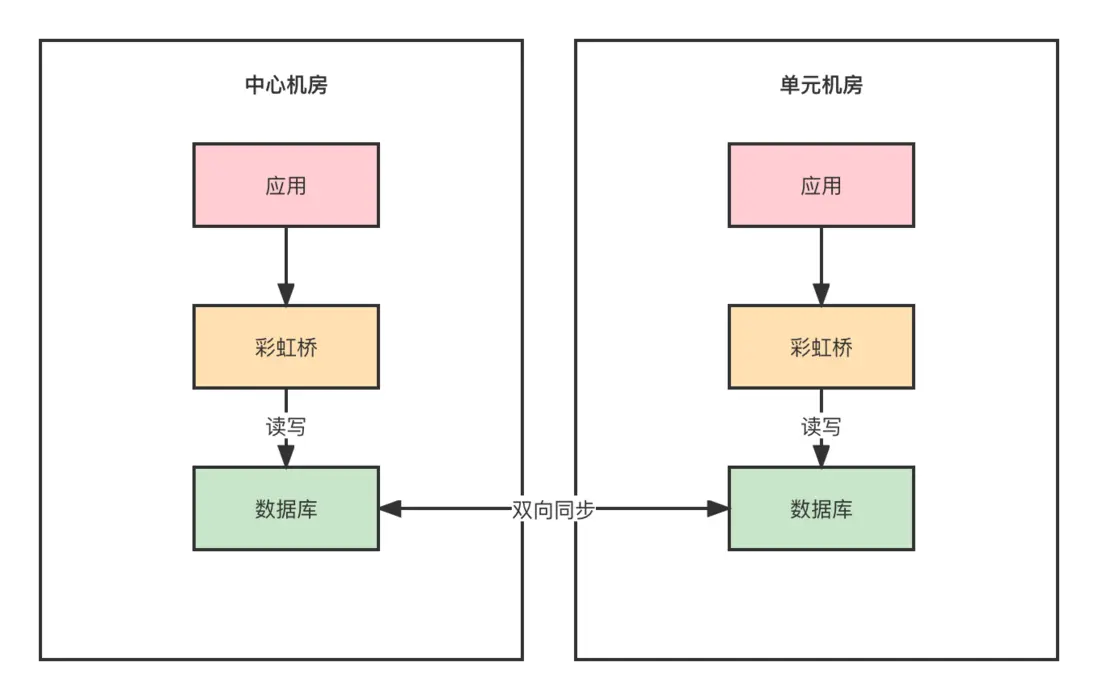
此庫為單元庫,會同時在兩個機房部署,每個機房都有完整的數據,數據採用雙向同步。
- 中心化
此庫為中心庫,只會在中心機房部署。
- 中心單元化
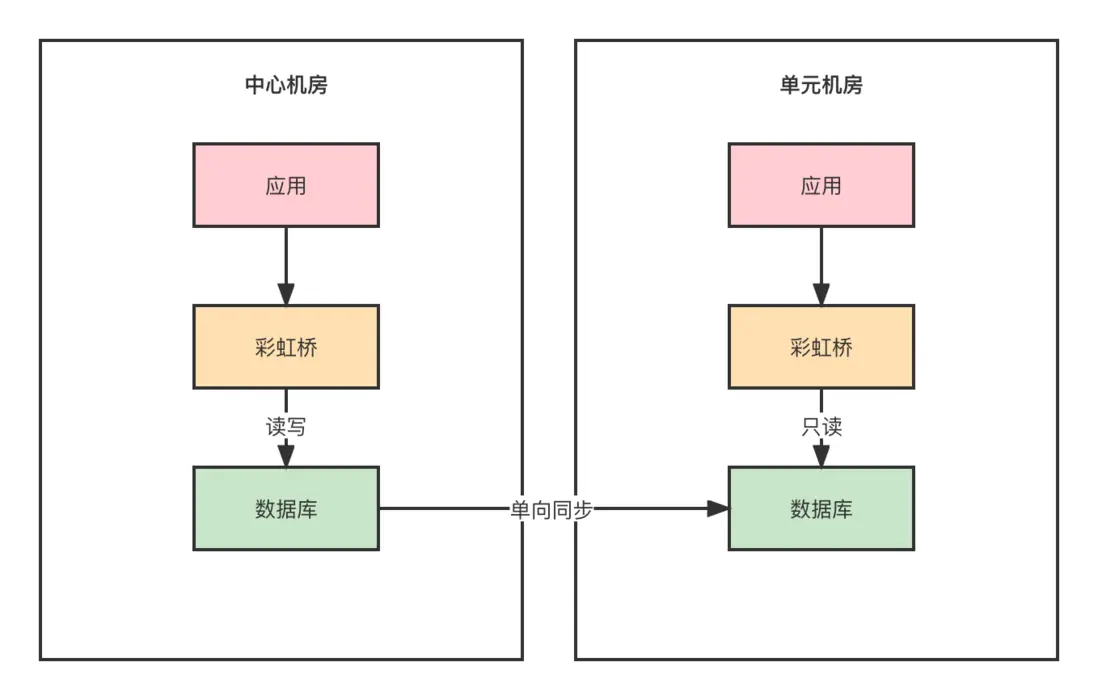
此庫為中心單元庫,會同時在兩個機房部署,中心可以讀寫,其他機房只能讀。中心寫數據後單向複製到另一個機房。
2.3.1 代理中間件
目前各個業務方用的都是客户端形式的Sharding中間件,每個業務方的版本還不一致。在多活切流的過程中需要對數據庫禁寫來保證業務數據的準確性,如果沒有統一的中間件,這將是一件很麻煩的事情。
所以我們通過對ShardingSphere進行深度定製,二次開發數據庫代理中間件 彩虹橋。各業務方需要接入彩虹橋來替換之前的Sharding方式。在切換過程中,如何保證穩定平滑遷移,出問題如何快速恢復,我們也有一套成功的實踐,大家可以看下我之前寫的這篇文章《客户端分片到Proxy分片,如絲般順滑的平穩遷移》,裏面有實現方式。
2.3.2 分佈式ID
單元化的庫,數據層面會做雙向同步複製操作。如果直接用表的自增ID則會出現下面的衝突問題:

這個問題可以通過設置不同機房id有不同的自增步長來解決,但比較麻煩,後續可能會增加更多的機房。我們採用了一種一勞永逸的方式,接入全局唯一的分佈式ID來避免主鍵的衝突。
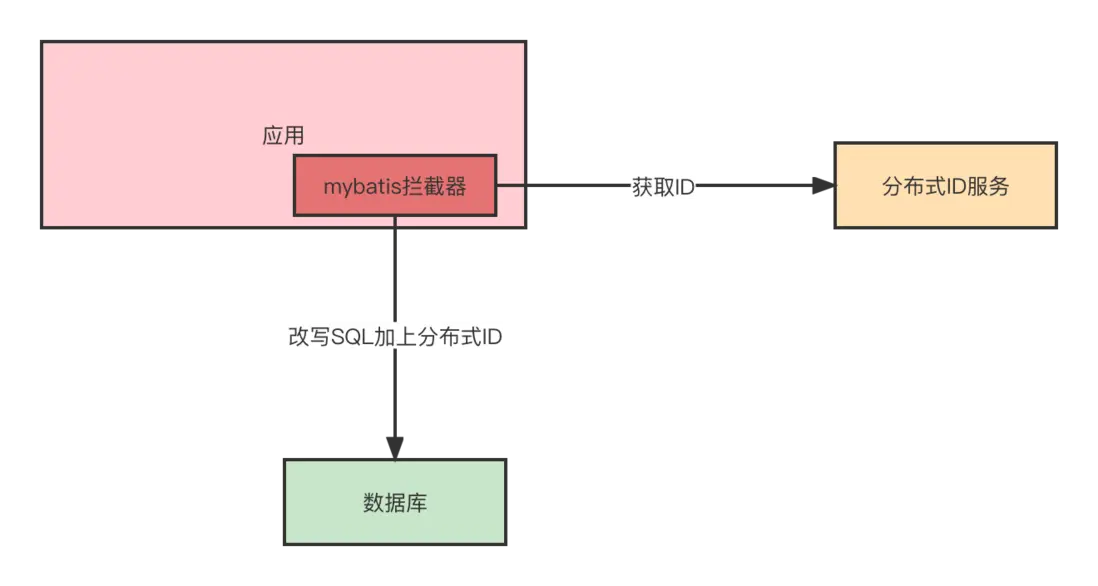
2.3.2.1 客户端接入
目前,接入分佈式ID有兩種方式,一種是應用內通過基礎架構提供的jar包接入,具體邏輯如下:
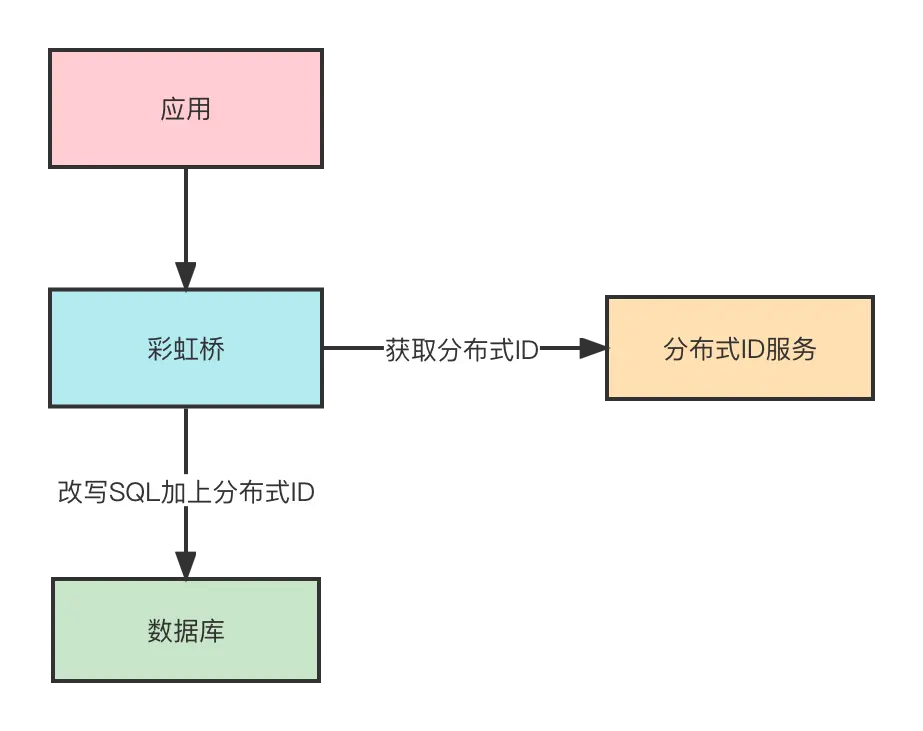
2.3.2.2 彩虹橋接入
另一種就是在彩虹橋中對具體的表配置ID的生成方式,支持對接分佈式ID服務。
2.3.3 業務改造
2.3.3.1 單元化庫寫請求必須攜帶ShardingKey
在Dao層對錶進行操作的時候,會通過ThreadLocal設置當前方法的ShardingKey,然後通過Mybatis攔截器機制,將ShardingKey通過Hint的方式放入SQL中,帶給彩虹橋。彩虹橋會判斷當前的ShardingKey是否屬於當前機房,如果不是直接禁寫報錯。
這裏跟大家簡單的説明下為什麼切流過程中要禁寫,這個其實跟JVM的垃圾回收有點相似。如果不對操作禁寫,那麼就會不斷的產生數據,而我們切流,一定要保證當前機房的數據全部同步過去了之後才開始生效流量規則,否則用户切到另一個機房,數據沒同步完,就會產生業務問題。除了彩虹橋會禁寫,RPC框架內部也會根據流量規則進行阻斷。
2.3.3.2 數據庫連接指定連接模式
連接模式的定義有兩種,分別是中心和單元。
如果應用的數據源指定了連接模式為中心,那麼在中心機房可以正常初始化數據源。在單元機房不會初始化數據源。
如果應用的數據源指定了連接模式為單元,那麼在中心機房和單元機房都可以正常初始化數據源。
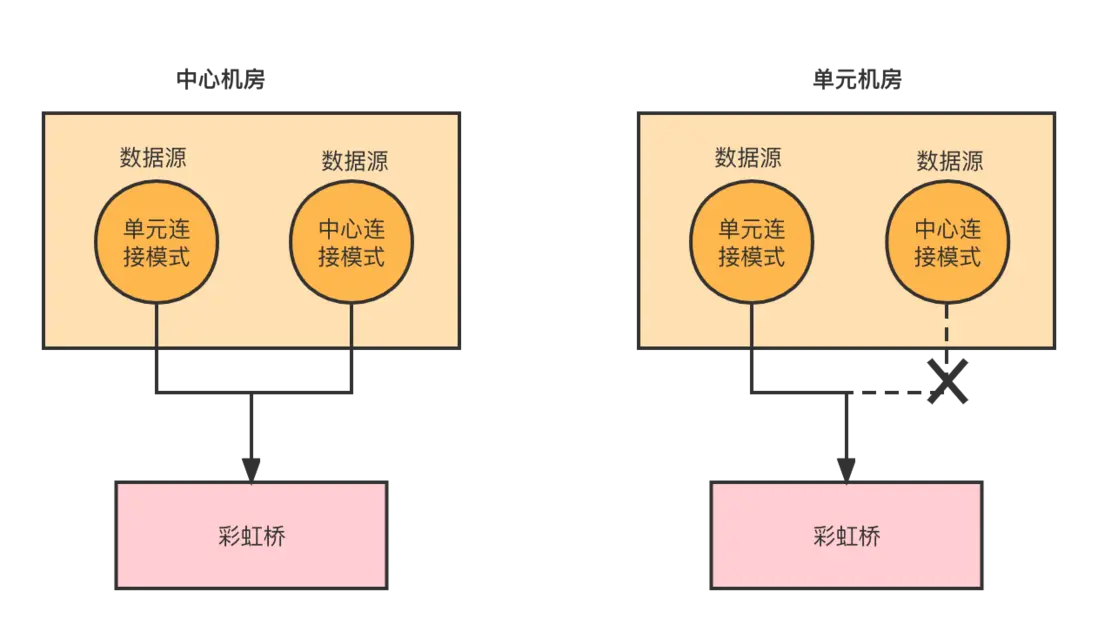
這裏解釋下為什麼要有連接模式這個 設計 ?
在我們的項目中,會出現同時連接2個庫的情況,一個單元庫,一箇中心庫。如果沒有連接模式,上層代碼是一份,這個項目會在中心和單元兩個機房同時部署,也就是兩個地方都會去創建數據源。
但實際上,我的中心庫只需要在中心機房連接就可以了,因為中心庫所有的操作都是中心接口,流量必定會走中心,我在單元機房去連接是沒有意義的。另一個問題就是我不需要在單元機房維護中心庫的數據庫信息,如果沒有連接模式,那麼單元機房的彩虹橋也必須要有中心庫的信息,因為項目會進行連接。
2.3.4 遇到的問題
2.3.4.1 單元接口中不能訪問中心數據庫
如果接口標記成了單元接口,那麼只能操作單元庫。在以前沒有做多活改造的時候,基本上沒有什麼中心和單元的概念,所有的表也都是放在一起的。多活改造後,我們會根據業務場景對數據庫進行劃分。
劃分後,中心庫只會被中心機房的程序使用,在單元機房是不允許連接中心庫。所以單元接口裏面如果涉及到對中心庫的操作,必定會報錯。這塊需要調整成走中心的RPC接口。
2.3.4.2 中心接口不能訪問單元數據庫
跟上面同樣的問題,如果接口是中心的,也不能在接口裏面操作單元庫。中心接口的請求都會強制走到中心機房,如果裏面有涉及到另一個機房的操作,也必須走RPC接口進行正確的路由,因為你中心機房不能操作另一個機房的數據庫。
2.3.4.3 批量查詢調整
比如批量根據訂單號進行查詢,但是這些訂單號不是同一個買家。如果隨便用一個訂單的買家作為路由參數,那麼其他一些訂單其實是屬於另一個單元的,這樣就有可能存在查詢到舊數據的問題。
這樣批量查詢的場景,只能針對同一個買家可用,如果是不同的買家需要分批調用。
2.4 Redis
Redis在業務中用的比較多,在多活的改造中也有很多地方需要調整。對於Redis首先我們明確幾個定義:
不做雙向同步
Redis不會和數據庫一樣做雙向同步,也就是中心機房一個Redis集羣,單元機房一個Redis集羣。每個機房的集羣中只存在一部分用户的緩存數據,不是全量的。
Redis類型
Redis分為中心和單元,中心只會在中心機房部署,單元會在中心和單元兩個機房部署。
2.4.1 業務改造
2.4.1.1 Redis多數據源支持
多活改造之前,每個應用都有一個單獨的Redis集羣,多活改造後,由於應用沒有進行單元化和中心的拆分,所以一個應用中會存在需要連接兩個Redis的情況。一箇中心Redis,一個單元Redis。
基礎架構提供的Redis包需要支持多數據源的創建,並且定義通用的配置格式,業務方只需要在自己 的配置裏面指定集羣和連接模式即可完成接入。此處的連接模式跟數據庫的一致。
具體的Redis實例信息會在配置中心統一維護,不需要業務方關心,這樣在做機房擴容的時候,業務方是不需要調整的,配置如下:
spring.redis.sources.carts.mode=unit
spring.redis.sources.carts.cluster-name=cartsCuster 同時我們在使用Redis的時候要指定對應的數據源,如下:
@Autowired
@Qualifier(RedisTemplateNameConstants.REDIS_TEMPLATE_UNIT)
private RedisTemplate<String, Object> redisTemplate; 2.4.1.2 數據一致性
數據庫緩存場景,由於Redis不會雙向同步,就會存在數據的不一致性問題。比如用户一開始在中心機房,然後緩存了一份數據。進行切流,切到單元機房,單元機房又緩存了一份數據。再進行切回中心機房的操作,此時中心機房裏的緩存是舊的數據,不是最新的數據。
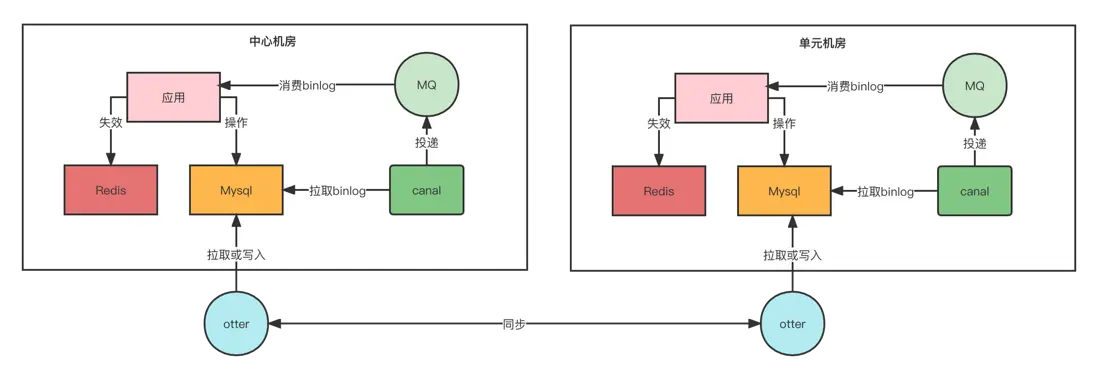
所以在底層數據變更的時候,我們需要對緩存進行失效操作,這樣才能保證數據的最終一致性。單純依靠緩存的失效時間來達到一致性不是一個合適的方案。
這裏我們的方案是採用訂閲數據庫的binlog來進行緩存的失效操作,可以訂閲本機房的binlog,也可以訂閲其他機房的binlog來實現所有機房的緩存失效。
2.4.2 遇到的問題
2.4.2.1 序列化協議兼容
在接入新的Redis Client包後,測試環境出現了老數據的兼容問題。大部分應用都沒問題,有個別應用雖然用了統一的底層包,但是自己定製了序列化方式,導致Redis按新的方式裝配後沒有用到自定義的協議,這塊也是進行了改造,支持多數據源的協議自定義。
2.4.2.2 分佈式鎖的使用
目前項目中的分佈式鎖是基於Redis實現,當Redis有多個數據源之後,分佈式鎖也需要進行適配。在使用的地方要區分場景,默認都是用的中心Redis來加鎖。
但是單元接口裏面的操作都是買家場景,所以這部分需要調整為單元Redis鎖對象進行加鎖,這樣能夠提高性能。其他的一些場景有涉及到全局資源的鎖定,那就用中心Redis鎖對象進行加鎖。
2.5 RocketMQ
請求到達服務層後,跟數據庫和緩存都進行了交互,接下來的邏輯是要發一條消息出去,其他業務需要監聽這個消息做一些業務處理。
如果是在單元機房發出的消息,發到了單元機房的MQ中,單元機房的程序進行消費,是沒有問題的。但如果中心機房的程序要消費這個消息怎麼辦?所以MQ跟數據庫一樣,也要做同步,將消息同步到另一個機房的MQ中,至於另一個機房的消費者要不要消費,這就要讓業務場景去決定。
2.5.1 定義消費類型
2.5.1.1 中心訂閲
中心訂閲指的是消息無論是在中心機房發出的還是單元機房發出的,都只會在中心機房進行消費。如果是單元機房發出的,會將單元的消息複製一份到中心進行消費。
2.5.1.2 普通訂閲
普通訂閲就是默認的行為,指的是就近消費。在中心機房發送的消息就由中心機房的消費者進行消費,在單元機房發送的消息就由單元機房的消費進行消費。
2.5.1.3 單元訂閲
單元訂閲指的是消息會根據ShardingKey進行消息的過濾,無論你在哪個機房發送消息,消息都會複製到另一個機房,此時兩個機房都有該消息。通過ShardingKey判斷當前消息應該被哪個機房消費,符合的才會進行消費,不符合的框架層面會自動ACK。
2.5.1.4 全單元訂閲
全單元訂閲指的是消息無論在哪個機房發出,都會在所有的機房進行消費。
2.5.2 業務改造
2.5.2.1 消息發送方調整
消息發送方,需要結合業務場景進行區分。如果是買家場景的業務消息,在發消息的時候需要將buyerId放入消息中,具體怎麼消費由消費方決定。如果消費方是單元消費的話那麼必須依賴發送方的buyerId,否則無法知道當前消息應該在哪個機房消費。
2.5.2.2 消息消費方指定消費模式
前面提到了中心訂閲,單元訂閲,普通訂閲,全單元訂閲多種模式,到底要怎麼選就是要結合業務場景來定的,定好後在配置MQ信息的時候指定即可。
比如中心訂閲就適合你整個服務都是中心的,其他機房都沒部署,這個時候肯定適合中心訂閲。比如你要對緩存進行清除,就比較適合全單元訂閲,一旦數據有變更,所有機房的緩存都清除掉。
2.5.3 遇到的問題
2.5.3.1 消息冪等消費
這個點其實根據多活沒有多大關係,就算不做多活,消息消費場景,肯定是要做冪等處理的,因為消息本身就有重試機制。單獨拎出來説是因為在多活場景下除了消息本身的重試會導致消息重複消費,另外在切流的過程中,屬於切流這部分用户的消息會被複制到另一個機房重新進行消費,在重新消費的時候,會基於時間點進行消息的重新投放,所以有可能會消費到之前已經消費了的消息,這點必須注意。
再解釋下為什麼切流過程中會有消息消費失敗以及需要複製到另一個機房去處理,如下圖所示:
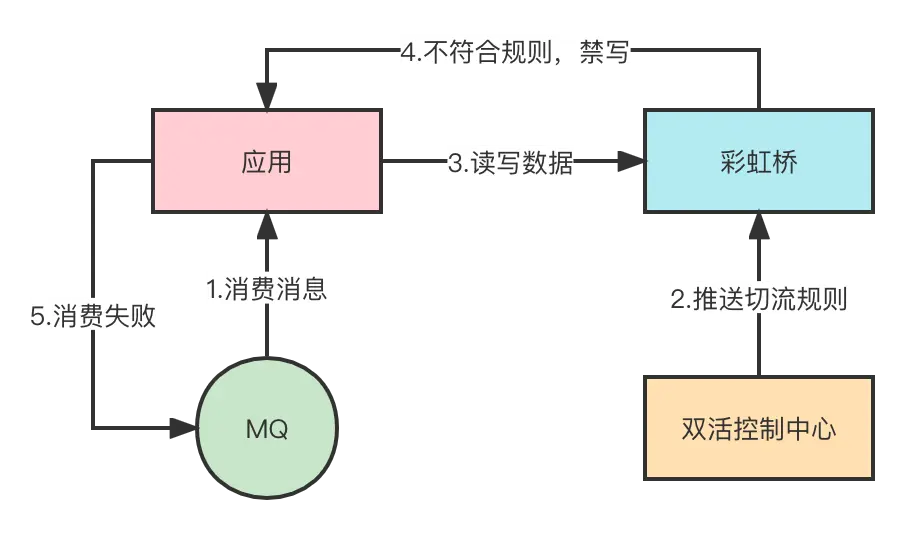
用户在當前機房進行業務操作後,會產生消息。由於是單元訂閲,所以會在當前機房進行消費。消費過程中,發生了切流操作,消費邏輯裏面對數據庫進行讀寫,但是單元表的操作都攜帶了ShardingKey,彩虹橋會判斷ShardingKey是否符合當前的規則,發現不符合直接禁寫報錯。這批切流用户的消息就全部消費失敗。等到流量切到另一個機房後,如果不進行消息的重新投遞,那麼這部分消息就丟失了,這就是為什麼要複製到另一個機房進行消息的重新投遞。
2.5.3.2 切流場景的消息順序問題
上面講到了在切流過程中,會將消息複製到另一個機房進行重新消費,然後是基於時間點去回放的,如果你的業務消息本身就是普通的Topic,在消息回放的時候如果同一個場景的消息有多條,這個順序並不一定是按照之前的順序來消費,所以這裏涉及到一個消費順序的問題。
如果你之前的業務場景本身就是用的順序消息,那麼是沒問題的,如果之前不是順序消息,這裏就有可能有問題,我舉個例子説明下:
有個業務場景,觸發一次功能就會產生一條消息,這個消息是用户級別的,也就是一個用户會產生N條消息。消費方會消費這些消息進行存儲,不是來一次消息就存儲一條數據,而是同一個用户的只會存儲一條,消息裏面有個狀態,會根據這個狀態進行判斷。
比如下面的消息總共投遞了3條,按正常順序消費最終的結果是status=valid。
10:00:00 status=valid
10:00:01 status=invalid
10:00:02 status=valid 如果消息在另一個機房重新投遞的時候,消費順序變成了下面這樣,最終結果就是status=invalid。
10:00:00 status=valid
10:00:02 status=valid
10:00:01 status=invalid 解決方案有下面幾種:
- Topic換成順序消息,以用户進行分區,這樣就能保證每個用户的消息嚴格按照發送順序進行消費
- 對消息做冪等,已消費過就不再消費。但是這裏跟普通的消息不同,會有N條消息,如果對msgId進行存儲,這樣就可以判斷是否消費過,但是這樣存儲壓力太大,當然也可以只存儲最近N條來減小存儲壓力。
- 消息冪等的優化方式,讓消息發送方每發送一次,都帶一個version,version必須是遞增。消費方消費消息後把當前version存儲起來,消費之前判斷消息的version是否大於存儲的version,滿足條件才進行消費,這樣既避免了存儲的壓力也能滿足業務的需求。
2.6 Job
Job在我們這邊用的不多,而且都是老的邏輯在用,只有幾個凌晨統計數據的任務,新的都接入了我們自研的TOC(超時中心)來管理。
2.6.1 業務改造
2.6.1.1 中心機房執行
由於Job是老的一套體系,目前也只有個位數的任務在執行,所以在底層框架層面並沒有支持多活的改造。後續會將Job的邏輯遷移到TOC中。
所以我們必須在業務層面進行改造來支持多活,改造方案有兩種,分別介紹下:
- 兩個機房同時執行Job,數據處理的時候,比如處理用户的數據,通過基礎架構提供的能力,可以判斷用户是否屬於當前機房,如果數據就執行,否則就跳過這條數據。
- 從業務場景出發,Job都是凌晨去執行的,不屬於在線業務,對數據一致性要求沒那麼高。即使不按單元化去處理數據,也沒什麼問題。所以只需要在中心機房執行Job即可,另一個機房我們可以通過配置讓Job任務不進行生效。
但是這種方式需要去梳理Job裏的數據操作,如果有對中心庫操作的,沒關係,本身就是在中心機房跑。如果有對單元庫操作的,需要調整為走RPC接口。
2.7 TOC
TOC是我們內部用的超時中心,當我們有需求需要在某個時間點進行觸發業務動作的時候都可以接入超時中心來處理。
舉個例子:訂單創建後,N分鐘內沒有支付就自動取消。如果業務方自己實現,要麼定時掃表進行處理,要麼用MQ的延遲消息。有了TOC後,我們會在訂單創建之後,往TOC註冊一個超時任務,指定某個時間點,你要回調我。在回調的邏輯邏輯裏去判斷訂單是否已完成支付,如果沒有則取消。
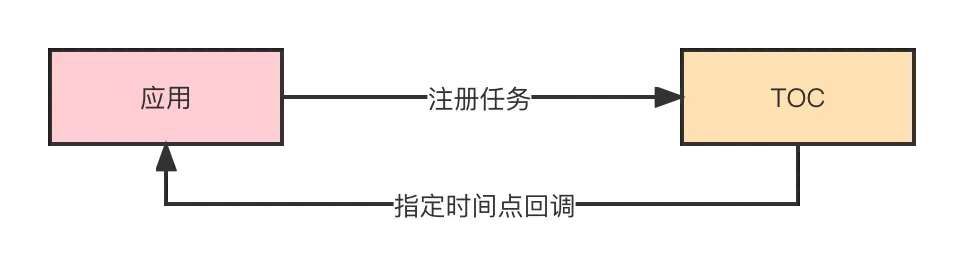
2.7.1 業務改造
2.7.1.1 任務註冊調整
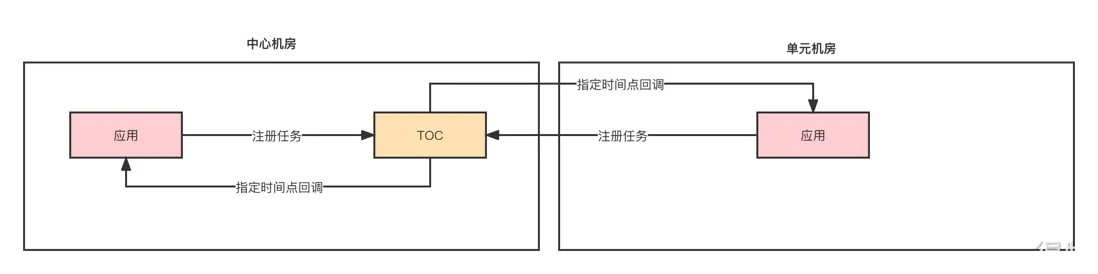
在註冊超時中心任務的時候,業務方需要識別任務是否要符合單元化的標準。如果此任務只是對中心數據庫進行操作,那麼這個任務回調在中心機房即可。如果此任務是對單元數據庫操作,那麼在註冊任務的時候就需要指定buyerId,超時中心在觸發回調的時候會根據buyerId進行路由到用户所屬機房進行處理。
目前超時中心是隻會在中心機房進行部署,也就是所有的任務都會在中心機房進行調度。如果任務註冊的時候沒有指定buyerId,超時中心在回調的時候就不知道要回調哪個機房,默認回調中心機房。要想讓超時中心根據多活的路由規則進行回調,那麼註冊的時候必須指定buyerId。
3. 服務劃分
閲讀完上面的改造內容,相信大家還有一個疑惑點就是我的服務該怎麼劃分呢?我要不要做單元化呢?
3.1 整體方向
首先要根據整個多活的一個整體目標和方向去梳理,比如我們的整體方向就是買家交易的核心鏈路必須實現單元化改造。那麼這整個鏈路所有依賴的上下游都需要改造。
用户瀏覽商品,進入確認訂單,下單,支付,查詢訂單信息。這個核心鏈路其實涉及到了很多的業務域,比如:商品,出價,訂單,支付,商家等等。
在這些已經明確了的業務域下面,可能還有一些其他的業務域在支撐着,所以要把整體的鏈路都梳理出來,一起改造。當然也不是所有的都必須做單元化,還是得看業務場景,比如庫存,肯定是在交易核心鏈路上,但是不需要改造,必須走中心。
3.2 服務類型
3.2.1 中心服務
中心服務只會在中心機房部署,並且數據庫也一定是中心庫。可以對整個應用進行打標成中心,這樣外部訪問這個服務的接口時都會被路由到中心機房。
3.2.2 單元服務
單元服務會在中心機房和單元機房同時部署,並且數據庫也一定是單元庫。單元服務是買家維度的業務,比如確認訂單,下單。
買家維度的業務,在接口定義上,第一個參數必須是buyerId,因為要進行路由。用户的請求已經根據規則進行分流到不同的機房,只會操作對應機房裏面的數據庫。
3.2.3 中心單元服務
中心單元服務也就是説這個服務裏面既有中心的接口也有單元的接口。並且數據庫也是有兩套。所以這種服務其實也是要在兩個機房同時部署的,只不過是單元機房只會有單元接口過來的流量,中心接口是沒有流量的。
一些底層的支撐業務,比如商品,商家這些就屬於中心單元服務。支撐維度的業務是沒有buyerId的,商品是通用的,並不屬於某一個買家。
而支撐類型的業務底層的數據庫是中心單元庫,也就是中心寫單元讀,寫請求是在中心進行,比如商品的創建,修改等。操作後會同步到另一個機房的數據庫裏面。這樣的好處就是可以減少我們在核心鏈路中的耗時,如果商品不做單元化部署,那麼瀏覽商品或者下單的時候查詢商品信息都必須走中心機房進行讀取。而現在則會就近路由進行接口的調用,請求到中心機房就調中心機房的服務,請求到單元機房就調單元機房的服務,單元機房也是有數據庫的,不需要跨機房。
從長遠考慮,還是需要進行拆分,把中心的業務和單元的業務拆開,這樣會比較清晰。對於後面新同學在定義接口,操作數據庫,緩存等都有好處,因為現在是混合在一起的,你必須要知道當前這個接口的業務屬於單元還是中心。
拆分也不是絕對的,還是那句話得從業務場景出發。像訂單裏面的買家和賣家的業務,我覺得可以拆分,後續維護也比較方便。但是像商品這種,並不存在兩種角色,就是商品,對商品的增刪改成在一個項目中也方便維護,只不過是要進行接口的分類,將新增,修改,刪除的接口標記為中心。
4. 切流方案
前面我們也提到了再切流過程中,會禁寫,會複製MQ的消息到另一個機房重新消費。接下來給大家介紹下我們的切流方案,能夠幫助大家更深刻的理解整個多活的異常場景下處理流程。
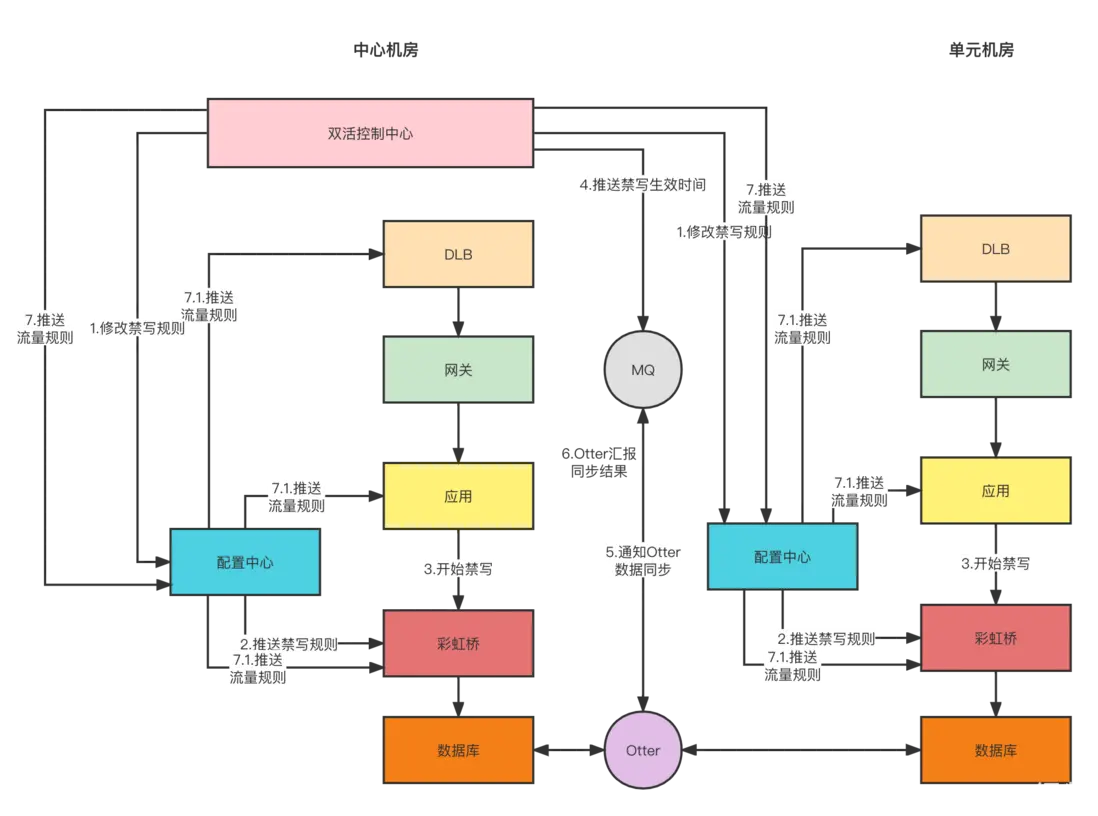
- 下發禁寫規則
當需要切流的時候,操作人員會通過雙活控制中心的後台進行操作。切流之前需要先進行已有流量的清理,需要下發禁寫規則。禁寫規則會下發到中心和單元兩個機房對應的配置中心裏面,通過配置中心去通知需要監聽的程序。
- 彩虹橋執行禁寫邏輯
彩虹橋會用到禁寫規則,當禁寫規則在配置中心修改後,彩虹橋能立馬感知到,然後會根據SQL中攜帶的shardingkey進行規則的判斷,看當前shardingkey是否屬於這個機房,如果不屬於則進行攔截。
- 反饋禁寫生效結果
當配置變更後會推送到彩虹橋,配置中心會感知到配置推送的結果,然後將生效的結果反饋給雙活控制中心。
- 推送禁寫生效時間給Otter
雙活控制中心收到所有的反饋後,會將全部生效的時間點通過MQ消息告訴Otter。
- Otter進行數據同步
Otter收到消息會根據時間點進行數據同步。
- Otter同步完成反饋同步結果
生效時間點之前的數據全部同步完成後會通過MQ消息反饋給雙活控制中心。
- 下發最新流量規則
雙活中心收到Otter的同步完成的反饋消息後,會下發流量規則,流量規則會下發到DLB,RPC,彩虹橋。
後續用户的請求就會直接被路由到正確的機房。
5. 總結
相信大家看了這篇文章,對多活的改造應該有了一定的瞭解。當然本篇文章並沒有把所有多活相關的改造都解釋清楚,因為整個改造的範圍實在是太大了。本篇主要講的是中間件層面和業務層面的一些改造點和過程,同時還有其他的一些點都沒有提到。比如:機房網絡的建設,發佈系統支持多機房,監控系統支持多機房的整個鏈路監控,數據巡檢的監控等等。
多活是一個高可用的容災手段,但實現的成本和對技術團隊的要求非常高。在實現多活的時候,我們應該結合業務場景去進行設計,不是所有系統,所有功能都要滿足多活的條件,也沒有100%的可用性,有的只是在極端場景下對業務的一些取捨罷了,優先保證核心功能。
以上就是得物訂單域在參與多活改造中的一些經驗,分享出來希望可以對正在閲讀的你有一些幫助。
文/YINJIHUAN
關注得物技術,做最潮技術人!