

1. 背景
團隊歸屬於後方業務支撐部門,組內的項目都以pc中後台應用為主。對比移動端應用,代碼庫比較龐大,業務邏輯也相對複雜。在持續的迭代過程中,我們發現當前的代碼倉庫仍然有不少可以優化的點:
可以減弱對ui框架的依賴
21年前端平台決定技術棧統一遷移到React生態,後續平台的基礎建設也都圍繞React展開,這就使得商家使用Vue生態做開發的系統面臨技術棧遷移的難題,將業務邏輯和UI框架節藕變得異常重要。
代碼風格可以更加統一
隨着代碼量和團隊成員的增加,應用裏風格迥異的代碼也越來越多。為了能夠持續迅速的進行迭代,團隊急需一套統一的頂層代碼架構設計方案。
可以集成自動化測試用例
隨着業務變得越來越複雜,在迅速的迭代過程中團隊需要頻繁地對功能進行迴歸,因此我們對於自動化單測用例的訴求也變的越來越強烈。
為了完成以上的優化,四組對現有的應用架構做了一次重構,而重構的核心就是整潔架構。
2. 整潔架構(The Clean Architecture)
整潔架構(The clean architecture)是由 Robert C. Martin (Uncle Bob)在2012年提出的一套代碼組織的理念,其核心主要是依據各部分代碼作用的不同將其拆分成不同的層次,在各層次間制定了明確的依賴原則,以達到以下目的:
- 與框架無關:無論是前端代碼還是服務端代碼,其邏輯本身都應該是獨立的,不應該依賴於某一個第三方框架或工具庫。一套獨立的代碼可以把第三方框架等作為工具使用。
- 可測試:代碼中的業務邏輯可以在不依賴ui、數據庫、服務器的情況下進行測試。
- 和ui無關:代碼中的業務邏輯不應該和ui做強綁定。比如把一個web應用切換成桌面應用,業務邏輯不應該受到影響。
- 和數據庫無關:無論數據庫用的是mysql還是mongodb,無論其怎麼變,都不該影響到業務邏輯。
- 和外部服務無關:無論外部服務怎麼變,都不影響到使用該服務的業務邏輯。
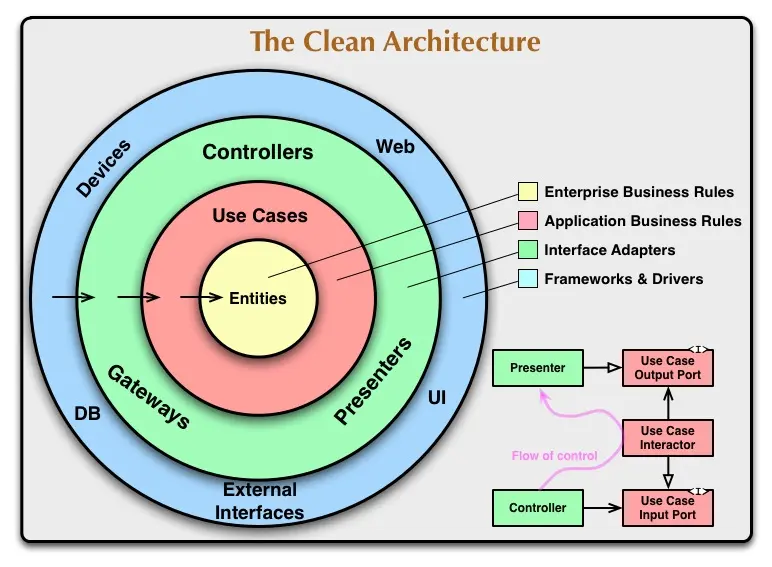
為了實現以上目的,整潔架構把應用劃分成了entities、use cases、interface adapters(MVC、MVP等)、Web/DB等至少四層。這套架構除了分層之外,在層與層之間還有一個非常明確的依賴關係,外層的邏輯依賴內層的邏輯。
Entity
entities封裝了企業級的業務邏輯和規則。entities沒有什麼固定的形式,無論是一個對象也好,是一堆函數的集合也好,唯一的標準就是能夠被企業的各個應用所複用。
Use Case
entities封裝了企業裏最通用的一部分邏輯,而應用各自的業務邏輯就都封裝在use case裏面。日常開發中最常見的對於某個模型的crud操作就屬於usecase這一層。
Interface Adapter
這一層類似於膠水層,需要負責內圈的entity和use case同外圈的external interfaces之間的數據轉化。需要把外層服務的數據轉化成內層entity和usecase可以消費的數據,反之亦然。如上面圖上畫的,這一層有時候可能很簡單(一個轉化函數), 有時候可能複雜到包含一整個MVC/MVP的架構。
External Interfaces
我們需要依賴的外部服務,第三方框架,以及需要糊的頁面UI都歸屬在這一層。這一層完全不感知內圈的任何邏輯,所以無論這一層怎麼變(ui變化),都不應該影響到內圈的應用層邏輯(usecase)和企業級邏輯(entity)。
依賴原則
在整潔架構的原始設計中,並不是強制一定只能寫這麼四層,根據業務的需要還可以拆分的更細。不過無論怎麼拆,都需要遵守前面提到的從外至內的依賴原則。即entity作為企業級的通用邏輯,不能依賴任何模塊。而外層的ui等則可以使用usecase、entity。
3. 重構
前面介紹了當前代碼庫目前的一些具體問題,而整潔架構的理念正好可以幫助我們優化代碼可維護性。
作為前端,我們的業務邏輯不應該依賴視圖層(ui框架及其生態),同時應當保證業務邏輯的獨立性和可複用性(usecase & entity)。最後,作為數據驅動的端應用,要保證應用視圖渲染和業務邏輯等不受數據變動的影響(adapter & entity)。
根據以上的思考,我們對“整潔架構”做了如下落地。
Entities
對於前端應用來説,在entity層我們只需要將服務端的生數據做一層簡單的抽象,生成一個貧血對象給後續的渲染和交互邏輯使用。



以上是商家後台訂單模型的entity工廠函數,工廠主要負責對服務端返回的生數據進行加工處理,讓其滿足渲染層和邏輯層的要求。除了抽象數據之外,可以看到在entity工廠還對數據進行了校驗,將髒數據、不符合預期的數據全部處理掉或者進行兜底(具體操作要看業務場景)。
有一點需要注意的是,在設計entity的時候(尤其是基礎entity)需要考慮複用性。舉個例子,在上面orderEntity的基礎上,我們通過簡單的組合就可以生成一個虛擬商品訂單entity:

如此一來,我們就通過entity層達到了2個目的:
- 把前端的邏輯和服務端接口數據隔離開,無論服務端怎麼變,前端後續的渲染、業務代碼不需要變,我們只需要變更entitiy工廠函數;並且經過entity層處理過後,所有流入後續渲染&交互邏輯的數據都是可靠的;對於部分異常數據,前端應用可以第一時間發現並報警。
- 通過對業務模型進行抽象,實現了模塊間的組合、複用。另外,抽象出的entity對代碼的維護性也有非常大的幫助,開發者可以非常直觀的知道所使用的entity所包含的所有字段。
Usecase
usecase這一層即是圍繞entity展開的一系列crud操作,以及為了頁面渲染做的一些聯動(通過ui store實現)。由於當前架構的原因(沒有bff層),usecase還可能承擔部分微服務串聯的工作。
舉個例子,商家後台訂單頁面在渲染前有一堆準備邏輯:
- 根據route的query參數以及一些商家類型參數來決定默認選中哪個tab
- 根據是國內商家還是境外商家,調用對應的供應商接口來更新供應商下拉框
現在大致的實現是:


我們能看到7-15、24-125行對this.subType進行了賦值。但由於我們無法確定20行的函數是否也對this.subType進行了賦值,所以光憑mounted函數的代碼我們並不能完全確定subType的值究竟是什麼,需要跳轉到getAllLogisticsCarrier函數確認。這段代碼在這裏已經做了簡化,實際的代碼像getAllLogisticsCarrier這樣的調用還有好幾個,要想搞清楚邏輯就得把所有函數全看一遍,代碼的可讀性一般。同時,由於函數都封裝在ui組件裏,因此要想給函數覆蓋單測的話也需要一些改造。
為了解決問題,我們將這部分邏輯都拆分到usecase層:



首先,可以看到所有usecase一定是一個純函數,不會存在副作用的問題。
其次,prepareOrderPage usecase專門為訂單頁定製,拆分後一眼就能看出來訂單頁的準備工作需要幹決定選中的tab和拉取供應商列表兩件事情。而另一個拆分出來的queryLogisticsCarriers則是封裝了商家後台跨境、國內兩種邏輯,後續無論跨境還是國內的邏輯如何變更,其影響範圍被限制在了queryLogisticsCarriers函數,我們需要對其進行功能迴歸;而對於prepareOrderPage來説,queryLogisticsCarriers只是() => Promise<{ carriers: ICarrires }>的一個實現而已,其內部調用queryLogisticsCarriers的邏輯完全不受影響,不需要進行迴歸。
最後,而由於我們做了依賴倒置,我們可以非常容易的給usecase覆蓋單測:


單測除了進行功能迴歸之外,它的描述(demo裏使用了Given-When-Then的格式,由於篇幅的原因,關於單測的細節在後續的文章再進行介紹)對於瞭解代碼的邏輯非常非常非常有幫助。由於單測和代碼邏輯強行綁定的緣故,我們甚至可以將單測描述當成一份實時更新的業務文檔。
除了方便寫單測之外,在通過usecase拆分完成之後,ui組件真正成為了只負責“ui”和監聽用户交互行為的組件,這為我們後續的React技術棧遷移奠定了基礎;通過usecase我們也實現了很不錯的模塊化,對於使用比較多的一些entity,他的crud操作可以通過獨立的usecase具備了在多個頁面甚至應用間複用的能力。
Adapter
上面usecase例子中的fetchAllLogisticsCarrier就是一個adapter,這一層起到的作用是將外部系統返回的數據轉化成entity,並以一種統一的數據格式返回回來。
這一層很核心的一點即是可以依賴entity的工廠函數,將接口返回的數據轉化成前端自己設計的模型數據,保證流入usecase和ui層的數據都是經過處理的“乾淨數據”。除此之外,通常在這一層我們會用一種固定的數據格式返回數據,比如例子中的 {success: boolean, data?: any}。這樣做主要是為了抹平對接多個系統帶來的差異性,同時減少多人協作時的溝通成本。

通過Adapter + entity的組合,我們基本形成了前端應用和後端服務之間的防腐層,使得前端可以在完全不清楚接口定義的情況下完成ui渲染、usecase等邏輯的開發。在服務端產出定義後,前端只需要將實際接口返回適配到自己定義的模型(通過entity)即可。這一點對前端的測試周提效非常非常非常重要,因為防腐層的存在,我們可以在測試周完成需求評審之後根據prd的內容設計出業務模型,並以此完成需求開發,在真正進入研發周後只需要和服務端對接完成adapter這一層的適配即可。
在實踐過程中,我們發現在對接同一個系統的時候(對商家來説就是stark服務)各個adapter對於異常的處理幾乎一模一樣(上述的11-15行),我們可以通過Proxy對其進行抽離實現複用。當然,後續我們也完全有機會根據接口定義來自動生成adapter。
UI
在經過前面的拆分之後,無論咱們的UI層用React還是Vue來寫,要做的工作都很簡單了:
- 監聽交互事件並調用對應的usecase來進行響應
- 通過usecase來獲取entity數據進行渲染
由於entity已經做了過濾和適配處理,所以在ui層我們可以放心大膽的用,不需要再寫一堆莫名其妙的判斷邏輯。另外由於entity是由前端自己定義的模型,無論開發過程中服務端接口怎麼變,受影響的都只有entity工廠函數,ui層不會受到影響。
最後,在ui層我們還剩下令人頭痛的技術棧遷移問題。整個團隊目前使用vue的項目有10個,按迭代頻率和項目規模遷移的方案可以分為兩類:
- 迭代頻繁的大應用:主要包括代碼行數較多、邏輯較為複雜的幾個中大型應用。這些應用想要一把梭直接完成遷移成本極高,但同時每個迭代又有相當的需求。基於這種情況,對於這三個應用我們採取了微前端的方式進行遷移。每個應用分別起一個對應的React應用,對於新頁面以及部分邏輯已經完全和ui解藕遷移成本不高的業務,都由React應用來承接,最後通過module federation的方式實現融合。
- 迭代不頻繁的小應用:剩下的應用均是複雜度不高的小應用,這部分應用迭代的需求不多,以維護為主。因此我們的方案是對現有邏輯進行整潔架構重構,在ui和邏輯分層之後直接對ui層進行替換完成遷移。
4. 後續
通過整潔架構我們形成了統一的編碼規範,在前端應用標準化的道路上邁下了堅實的一步。可以預見的是整個標準化的過程會非常漫長,我們會陸續往標準中增加新的規範使其更加完善,短期內在規劃中的有:
- 單測即文檔:上面提到了usecase通過依賴倒置來配合單測落地,後續團隊期望將一些業務邏輯的實現細則通過單測的描述來進行沉澱,解決業務文檔實時性的問題。
- 完善監控體系:前端常遇到的3種異常包括 代碼邏輯異常、性能瓶頸(渲染卡頓、內存不足等)、數據導致異常。對於數據異常,我們可以在entity層映射的過程中加入對異常數據的埋點上報來填補目前監控的空白。(代碼邏輯異常通過sentry已經監控,性能監控對於中後台應用不需要)
後續在標準逐漸穩定之後,我們也期望基於穩定的規範進行一些工程化的實踐(比如根據mooncake文檔自動生成adapter層、基於usecase實現功能開關等),敬請期待。
參考鏈接:
The Clean Architecture:https://blog.cleancoder.com/u...
Module Federation:https://webpack.js.org/concep...
Anti-corruption Layer pattern:https://docs.microsoft.com/en...
*文/陳子煜
@得物技術公眾號