

Stream API
Stream API 是按照map/filter/reduce方法處理內存中數據的最佳工具。
本系列中的教程包含從基本概念一直到collector設計和並行流。

在流上添加中繼操作
將一個流map為另一個流
mapping流就是使用函數轉換其元素。此轉換可能會更改該流處理的元素的類型。
您可以使用 map()) 方法將一個流map為另一個流,該方法用Function作為參數。mapping一個流意味着該流的所有元素都將使用該函數進行轉換。
代碼模式如下:
List<String> strings = List.of("one", "two", "three", "four");
Function<String, Integer> toLength = String::length;
Stream<Integer> ints = strings.stream()
.map(toLength);此代碼粘貼到 IDE 運行時,你不會看到任何東西,你可能想知道為什麼。
答案其實很簡單:該流上沒有定義末端操作。這段代碼沒有做任何事情。它不處理任何數據。
讓我們添加一個非常有用的末端操作collect(Collectors.toList()),它將處理後的元素放在一個列表中。如果您不確定此代碼的真正作用,請不要擔心;我們將在本教程的後面部分介紹這一點。代碼將變為以下內容。
List<String> strings = List.of("one", "two", "three", "four");
List<Integer> lengths = strings.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println("lengths = " + lengths);運行此代碼將打印以下內容:
lengths = [3, 3, 5, 4]您可以看到此模式創建了一個 Stream<Integer>,由 map(String::length)) 返回。你也可以通過調用mapToInt)()來使其成為一個專門的IntStream。這個mapToInt())方法以ToIntFuction作參數。在上一示例中.map(String::length)更改為.mapToInt(String::length) 不會創建編譯器錯誤。String::length方法引用可以是兩種類型:Function<String、Integer> 和 ToIntFunction<String>。
專用流沒有 collect() 方法將Collector作參數。因此,如果用 mapToInt(),)則無法再在列表中收集結果。讓我們獲取有關該流的一些統計信息。這個 summaryStatistics()) 方法非常方便,並且僅在專門的原始類型流上可用。
List<String> strings = List.of("one", "two", "three", "four");
IntSummaryStatistics stats = strings.stream()
.mapToInt(String::length)
.summaryStatistics();
System.out.println("stats = " + stats);結果如下:
stats = IntSummaryStatistics{count=4, sum=15, min=3, average=3,750000, max=5}從 Stream 轉為原始類型流有三種方法:mapToInt)()、mapToLong()) 和 mapToDouble()。)
filter流
filtering就是在流處理中使用Predicate丟棄某些元素。此方法可用於對象流和原始類型流。
假設您需要計算長度為 3 的字符串。您可以編寫以下代碼來執行此操作:
List<String> strings = List.of("one", "two", "three", "four");
long count = strings.stream()
.map(String::length)
.filter(length -> length == 3)
.count();
System.out.println("count = " + count);運行此代碼將生成以下內容:
count = 2請注意,您剛剛使用了 Stream API 的另一個末端操作 count(),)它只計算已處理元素的數量。此方法返回long ,您可以使用它計算很多元素。比 ArrayList 裏面的更多。
flatmap流以處理 1:p 關係
讓我們在一個示例中查看 flatMap) 操作。假設您有兩個實體:State和 City。一個state實例包含多個city實例,存儲在一個列表中。
這是City類的代碼。
public class City {
private String name;
private int population;
// constructors, getters
// toString, equals and hashCode
}這是State類的代碼,以及與City類的關係。
public class State {
private String name;
private List<City> cities;
// constructors, getters
// toString, equals and hashCode
}假設您的代碼正在處理狀態列表,並且在某些時候您需要計算所有城市的人口。
您可以編寫以下代碼:
List<State> states = ...;
int totalPopulation = 0;
for (State state: states) {
for (City city: state.getCities()) {
totalPopulation += city.getPopulation();
}
}
System.out.println("Total population = " + totalPopulation);此代碼的內部循環是 map-reduce 的一種形式,也可以使用流編寫:
totalPopulation += state.getCities().stream().mapToInt(City::getPopulation).sum();外層和內層有點不匹配,將流放入循環中不是一個很好的代碼模式。
這正是flatmap的作用。此運算符在對象之間打開一對多關係,並基於這些關係創建流。flatMap()) 方法將一個特殊函數作為參數,這個函數返回 Stream 對象。類與類之間的關係由此函數定義。
在我們的示例中,此函數很簡單,因為State類中有一個List<City>。所以你可以按以下方式編寫它。
//根據state和city的關係,生成city流
Function<State, Stream<City>> stateToCity = state -> state.getCities().stream();此List類型不是強制的。假設您有一個包含 Map <String,Country>的Continent類,其中鍵是國家/地區的代碼(CAN 表示加拿大,MEX 表示墨西哥,FRA 表示法國等)。假設該類有一個返回此map的方法getCountries()。
這種情況下,可以通過這種方式編寫此函數。
Function<Continent, Stream<Country>> continentToCountry =
continent -> continent.getCountries().values().stream();flatMap()) 方法的處理分兩個步驟。
- 第一步,使用此函數mapping流的所有元素。從
Stream<State>創建一個Stream<Stream<City>>,每個州都map為城市流。 - 第二步,展平產生的流。您最終會得到一個單一的流,其中包含所有州的所有城市。
因此,使用flatmap,之前的嵌套 for 編寫的代碼可以改寫為:
List<State> states = ...;
int totalPopulation =
states.stream()
.flatMap(state -> state.getCities().stream())//對每個state,都轉換為city流,最後合併
.mapToInt(City::getPopulation)
.sum();
System.out.println("Total population = " + totalPopulation);使用flatmap和 MapMulti 驗證元素轉換
flatMap) 可用於流元素的轉換中的驗證。
假設您有一個表示整數的字符串流。您需要用 Integer.parseInt()) 將它們轉為整數。不幸的是,其中一些字符串有問題:也許有些字符串為空,null,或者末尾有額外的空白字符。這些都會使解析失敗,並出現 NumberFormatException。當然,您可以嘗試filter此流,用Predicate刪除錯誤的字符串,但最安全的方法是使用 try-catch 模式。
如下所示。
Predicate<String> isANumber = s -> {
try {
int i = Integer.parseInt(s);
return true;
} catch (NumberFormatException e) {
return false;
}
};第一個缺陷是您需要實際進行轉換以查看它是否有效。然後,您不得不在mapping函數中再次執行此操作:不要這樣做!第二個缺陷是,從catch塊return,絕不是一個好主意。
您真正需要做的是,當此字符串中有一個正確的整數時返回一個整數,如果有問題,則什麼都不返回。這是flatmap的工作。如果可以解析整數,則可以返回包含結果的流。另一種情況下,您可以返回空流。
然後,可以編寫以下函數。
Function<String, Stream<Integer>> flatParser = s -> {//根據String與Integer的關係,生成Integer流
try {
return Stream.of(Integer.parseInt(s));
} catch (NumberFormatException e) {
}
return Stream.empty();
};
List<String> strings = List.of("1", " ", "2", "3 ", "", "3");
List<Integer> ints =
strings.stream()
.flatMap(flatParser)//對每個String,都轉為Integer流,最後合併 flatmap會跳過空流
.collect(Collectors.toList());
System.out.println("ints = " + ints);運行此代碼將生成以下結果。所有有問題的字符串都已靜默刪除。
ints = [1, 2, 3]這種flatmap代碼的使用效果很好,但它有一個開銷:為流的每個元素都會創建一個流。從 Java SE 16 開始,Stream API 中添加了一個方法:當您創建零個或一個對象的多個流時。此方法稱為mapMulti(),)並將BiConsumer作為參數。
此 BiConsumer 使用兩個參數:
- 需要mapping的流元素
- 對mapping結果調用的
Consumer
調用Consumer會將該元素添加到生成的流中。如果mapping無法完成,則biconsumer不會調用此消費者,並且不會添加任何元素。
讓我們用這個 mapMulti()) 方法重寫你的模式。
List<Integer> ints =
strings.stream()
.<Integer>mapMulti((string, consumer) -> {//方法前面聲明Integer
try {
consumer.accept(Integer.parseInt(string));//直接説明跟Integer的關係,生成最終Integer流
} catch (NumberFormatException ignored) {
}
})
.collect(Collectors.toList());
System.out.println("ints = " + ints);運行此代碼會產生與以前相同的結果。所有有問題的字符串都已被靜默刪除,但這一次,沒有創建其他流。
ints = [1, 2, 3]使用此方法,需要告訴編譯器 Consumer 的類型。通過這種特殊語法,在 mapMulti()) 前聲明此類型。它不是您在 Java 代碼中經常看到的語法。您可以在靜態和非靜態上下文中使用它。
刪除重複項並對流進行排序
Stream API 有兩個方法,distinct()) 和 sorted(),)去重和排序。distinct()) 方法使用 hashCode)() 和 equals()) 方法來發現重複項。sorted()) 方法有一個重載,需要一個comparator,用於比較和排序。如果未提供,則假定流元素具有可比性。否則,則會引發 ClassCastException。
您可能還記得本教程的前一部分,流應該是不存儲任何數據的空對象。此規則也有例外,這兩個方法就是。
事實上,為了發現重複項,distinct()) 方法需要存儲流元素。當處理一個元素時,首先檢查該元素是否見到過。
sorted()) 也是如此。此方法需要存儲所有元素,然後在內部緩衝區中對它們進行排序,再發送到管道的下一步。
distinct()) 可以用於非綁定(無限)流,而 sorted()) 不能。
限制和跳過流的元素
Stream API 提供了兩種選擇流元素的方法:基於索引或使用Predicate。
第一種方法,使用 skip)() 和 limit()) 方法,兩者都將 long 作為參數。使用這些方法時,需要避免一個小陷阱。您需要記住,每次在流中調用中繼方法時,都會創建一個新流。因此,如果您在 skip()) 之後調用 limit(),)請不要忘記從該新流開始計算。
假設您有一個包含所有整數的流,從 1 開始。您需要選擇 3 到 8 之間的整數。正確的代碼如下。
List<Integer> ints = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<Integer> result =
ints.stream()
.skip(2)//產生了新流
.limit(5)//不是limit(8)
.collect(Collectors.toList());
System.out.println("result = " + result);此代碼打印以下內容。
result = [3, 4, 5, 6, 7]Java SE 9 又引入了兩種方法。它不是根據元素在流中的索引跳過和限制元素,而是根據Predicate。
dropWhile(Predicate))如果Predicate為true,一直跳過元素,直到Predicate為false。此時,該流後面所有元素都將傳輸到下一個流。takeWhile(Predicate))做相反的事情:如果Predicate為true,它一直將元素傳輸到下一個流,直到Predicate為false,後面都跳過。這個是短路的
請注意,這些方法的工作方式類似於門。一旦 dropWhile()) 打開了門讓處理後的元素流動,它就不會關閉它。一旦 takeWhile()) 關閉了門,它就不能重新打開它,沒有更多的元素將被髮送到下一個操作。
串聯流
Stream API 提供了多種模式,可將多個流連接成一個。最明顯的方法是使用 Stream 接口中定義的工廠方法:concat()。)
此方法接收兩個流並生成一個流,其中包含第一個流的元素,然後是第二個流的元素。
您可能想知道為什麼此方法不用 vararg 來連接任意數量的流。如果你有兩個以上,JavaDoc API文檔建議你使用另一種模式,基於flatmap。
讓我們在一個例子上看看這是如何工作的。
List<Integer> list0 = List.of(1, 2, 3);
List<Integer> list1 = List.of(4, 5, 6);
List<Integer> list2 = List.of(7, 8, 9);
// 1st pattern: concat
List<Integer> concat =
Stream.concat(list0.stream(), list1.stream())
.collect(Collectors.toList());
// 2nd pattern: flatMap
List<Integer> flatMap =
Stream.of(list0.stream(), list1.stream(), list2.stream())//類似city的外層組成的流
.flatMap(Function.identity())//變成了city流,每個Stream<Integer>要變成Stream<Integer>,原樣返回即可
.collect(Collectors.toList());
System.out.println("concat = " + concat);
System.out.println("flatMap = " + flatMap);運行此代碼將產生以下結果:
concat = [1, 2, 3, 4, 5, 6]
flatMap = [1, 2, 3, 4, 5, 6, 7, 8, 9]建議使用 flatMap)() 方式的原因是 concat()) 在連接期間會創建中繼流,來連接兩個流。如果需要連接多個,則最終每次串聯都需要一個很快就會被丟棄的流。
使用flatmap模式,您只需創建一個流來保存所有流並執行flatmap。開銷要低得多。
您可能想知道為什麼添加了這兩種模式。看起來 concat()) 並不是很有用。事實上,如果連接的兩個流的源的大小已知,則生成的流的大小也是已知的,只是兩個串聯流的總和。
如果連接的兩個流的源的大小已知,則生成的流的大小也是已知的。實際上,它只是兩個串聯流的總和。
在流上使用flatmap可能會創建未知數量的元素,以便在生成的流中進行處理。Stream API 會丟失對元素數量的跟蹤。
換句話説:concat 產生一個 SIZED 流,而flatmap不會。此 SIZED 屬性是流可能具有的一種屬性,本教程稍後將介紹。
調試流
有時,在運行時能檢查流處理的元素可能很方便。Stream API 有一個方法:peek()) 方法。此方法用於調試數據處理管道。不應在生產代碼中使用此方法。
絕對不要使用此方法在應用程序中執行一些副作用。
此方法將Consumer作為參數,將每個元素上調用。讓我們實際效果。
List<String> strings = List.of("one", "two", "three", "four");
List<String> result =
strings.stream()
.peek(s -> System.out.println("Starting with = " + s))
.filter(s -> s.startsWith("t"))
.peek(s -> System.out.println("Filtered = " + s))
.map(String::toUpperCase)
.peek(s -> System.out.println("Mapped = " + s))
.collect(Collectors.toList());
System.out.println("result = " + result);如果運行此代碼,您將在控制枱上看到以下內容。
Starting with = one
Starting with = two
Filtered = two
Mapped = TWO
Starting with = three
Filtered = three
Mapped = THREE
Starting with = four
result = [TWO, THREE]讓我們分析一下這個輸出。
- 要處理的第一個元素是
one。你可以看到它被filter掉了。 - 第二個是
two。此元素通過filter,然後map為大寫。然後將其添加到結果列表中。 - 第三個是
three,它也通過filter。 - 最後一個是
four,被filtering步驟拒絕。
有一點你在本教程前面看到,現在很明顯:流確實一一處理了它必須處理的所有元素,從流的開始到結束。這在之前已經提到過,現在你可以看到它的實際效果。
您可以看到,此peek(System.out::println)模式對於逐個跟蹤流處理的元素非常有用,無需調試代碼。調試流很困難,需要小心放置斷點的位置。大多數情況下,在流處理上放置斷點會跳轉到Stream接口的實現。這不是你需要的。您需要將這些斷點放在 lambda 表達式的代碼中。
創建流
創建流
在本教程中,您已經創建了許多流,所有這些都是通過調用 Collection 接口的 stream()) 方法創建的。此方法非常方便:只需要兩行簡單的代碼,您可以使用此流來試驗Stream API 的幾乎任何功能。
如您所見,還有許多其他方法。瞭解這些方法後,您可以在應用程序中的許多位置利用 Stream API,並編寫更具可讀性和可維護性的代碼。
讓我們快速瀏覽您將在本教程中看到的內容,然後再深入研究它們中的每一個。
第一組模式使用 Stream 接口中的工廠方法。使用它們,您可以從以下元素創建流:
- vararg 參數;
- supplier;
- unary operator,從前一個元素生成下一個元素;
- builder。
您甚至可以創建空流,這在某些情況下可能很方便。
您已經看到可以在集合上創建流。如果您擁有的只是一個iterator,而不是一個成熟的集合,那麼您可以在iterator上創建流。如果你有一個數組,那麼還有一個模式可以在數組的元素上創建一個流。
它並不止於此。JDK 中的許多模式也已添加到眾所周知的對象中。然後,您可以從以下元素創建流:
- 字符串的字符;
- 文本文件的行;
- 通過使用正則表達式拆分字符串來創建的元素;
- 一個隨機變量,可以創建隨機數流。
您還可以使用builder模式創建流。
從集合或iterator創建流
您已經知道Collection接口中有一個可用的 stream()) 。這可能是創建流的最經典方法。
在某些情況下,您可能需要基於map的內容創建流。Map 接口中沒有stream()方法,因此無法直接創建。但是,您可以通過三個集合訪問map的內容:
- 鍵的集合,
keySet()) - 鍵值對的集合,
entrySet()) - 值的集合,
values ()。)
Stream API 提供了一種從簡單iterator創建流的模式,它可能是在非標準數據源上創建流的非常方便的方法。模式如下。
Iterator<String> iterator = ...;
long estimateSize = 10L;
int characteristics = 0;
Spliterator<String> spliterator = Spliterators.spliterator(iterator, estimateSize, characteristics);
boolean parallel = false;
Stream<String> stream = StreamSupport.stream(spliterator, parallel);此模式包含幾個神奇元素,本教程稍後將介紹。讓我們快速瀏覽它們。
estimateSize是您認為此流將消費的元素數。在某些情況下,此信息很容易獲得:例如,如果要在數組或集合上創建流。但某些情況下是未知的。
本教程稍後將介紹characteristics參數。它用於優化數據的處理。
parallel參數告知 API 要創建的流是否為並行流。本教程稍後將介紹。
創建空流
讓我們從最簡單的開始:創建一個空流。Stream接口中有一個工廠方法。您可以通過以下方式使用它。
Stream<String> empty = Stream.empty();
List<String> strings = empty.collect(Collectors.toList());
System.out.println("strings = " + strings);運行此代碼會在主機上顯示以下內容。
strings = []在某些情況下,創建空流可能非常方便。事實上,您在本教程的前一部分看到了一個,使用空流和flatmap從流中刪除無效元素。從 Java SE 16 開始,此模式已被 mapMulti()) 模式所取代。
從 vararg 或數組創建流
兩種模式非常相似。第一個在 Stream 接口中使用 of()) 工廠方法。第二個使用 Arrays 工廠類的 stream()) 工廠方法。事實上,如果你檢查 Stream.of()) 方法的源代碼,你會看到它調用了 Arrays.stream()。)
這是第一個實際模式。
Stream<Integer> intStream = Stream.of(1, 2, 3);
List<Integer> ints = intStream.collect(Collectors.toList());
System.out.println("ints = " + ints);運行第一個示例將提供以下內容:
ints = [1, 2, 3]這是第二個。
String[] stringArray = {"one", "two", "three"};
Stream<String> stringStream = Arrays.stream(stringArray);
List<String> strings = stringStream.collect(Collectors.toList());
System.out.println("strings = " + strings);運行第二個示例將提供以下內容:
strings = [one, two, three]從supplier創建流
Stream 接口上有兩種工廠方法。
第一個是 generate()),以supplier為參數。每次需要新元素時,都會調用該supplier。
您可以使用以下代碼創建這樣的流,但不要這樣做!
Stream<String> generated = Stream.generate(() -> "+");
List<String> strings = generated.collect(Collectors.toList());如果你運行這段代碼,你會發現它永遠不會停止。如果您這樣做並且有足夠的耐心,您可能會看到 OutOfMemoryError。如果沒有,最好通過 IDE 終止應用程序。它真的產生了無限的流。
我們還沒有介紹這一點,但擁有這樣的流是完全合法的!您可能想知道它們有什麼用?事實上有很多。要使用它們,您需要在某個時候截斷此流,而Stream API 為您提供了幾種方法來執行此操作。
你已經看到了一個,是調用該流上的 limit()。)讓我們重寫前面的示例,並修復它。
Stream<String> generated = Stream.generate(() -> "+");
List<String> strings =
generated
.limit(10L)
.collect(Collectors.toList());
System.out.println("strings = " + strings);運行此代碼將打印以下內容。
strings = [+, +, +, +, +, +, +, +, +, +]limit()) 方法稱為短路方法:它可以停止流元素的消費。
從unary operator和種子創建流
如果您需要生成常量的流,使用supplier非常有用。如果你需要一個具有不同值的無限流,那麼你可以使用 iterate()) 模式。
此模式適用於種子,種子是第一個生成的元素。然後,它使用 UnaryOperator 轉換前一個元素來生成流的下一個元素。
Stream<String> iterated = Stream.iterate("+", s -> s + "+");//根據前後關係函數,挨個生成無限流
iterated.limit(5L).forEach(System.out::println);您應該看到以下結果。
+
++
+++
++++
+++++使用此模式時,不要忘記限制元素數。
從 Java SE 9 開始,此模式具有重載,它將Predicate作為參數。當此Predicate變為 false 時,iterate()) 方法將停止生成元素。前面的代碼可以通過以下方式使用此模式。
Stream<String> iterated = Stream.iterate("+", s -> s.length() <= 5, s -> s + "+");
iterated.forEach(System.out::println);運行此代碼會得到與上一個代碼相同的結果。
從一系列數字創建流
使用以前的模式可以創建一系列數字。但是,使用專門的數字流及其 range()) 工廠方法會更容易。
range()) 接收初始值和範圍的上限(不包含)為參數。也可以在 rangeClosed()) 方法中包含上限。調用 LongStream.range(0L, 10L)) 將簡單地生成一個流,其中所有long都在 0 到 9 之間。
這個 range()) 方法也可以用來遍歷數組的元素。這是您可以做到這一點的方法。
String[] letters = {"A", "B", "C", "D"};
List<String> listLetters =
IntStream.range(0, 10)
.mapToObj(index -> letters[index % letters.length])//實現了數組的遍歷
.collect(Collectors.toList());
System.out.println("listLetters = " + listLeters);結果如下。
listLetters = [A, B, C, D, A, B, C, D, A, B]基於此模式,您可以做很多事情。請注意,由於 IntStream.range)() 創建了一個 IntStream(原始類型流),因此您需要使用 mapToObj()) 方法將其轉換為對象流。
創建隨機數流
Random類用於創建隨機數字序列。從 Java SE 8 開始,已向此類添加了幾個方法來創建不同類型的隨機數流int,long,double
您可以創建提供種子參數的Random實例。此種子是一個long。隨機數取決於該種子。對於給定的種子,您將始終獲得相同的數字序列。這在許多情況下可能很方便,包括編寫測試。這種情況下,數字序列可以預先知道。
有三種方法可以生成這樣的流,它們都在 Random 類中定義:ints())、longs() ) 和doubles()。)
所有這些方法都有幾個重載可用,它們接受以下參數:
- 此流將生成的元素數;
- 生成的隨機數的上限和下限。
下面是生成 10 個介於 1 和 5 之間的隨機整數的第一種代碼模式。
Random random = new Random(314L);
List<Integer> randomInts =
random.ints(10, 1, 5)
.boxed()//裝箱
.collect(Collectors.toList());
System.out.println("randomInts = " + randomInts);如果您使用的種子與此示例中使用的種子相同,則控制枱中將具有以下內容。
randomInts = [4, 4, 3, 1, 1, 1, 2, 2, 4, 2]請注意,我們在專用數字流中使用了 boxed()) 方法,它只是將此流map為等效的包裝器類型流。因此,通過此方法將 IntStream 轉換為 Stream<Integer>。
這是第二種模式。該流的任何元素都是true,概率為 80%。
Random random = new Random(314L);
List<Boolean> booleans =
random.doubles(1_000, 0d, 1d)
.mapToObj(rand -> rand <= 0.8) // you can tune the probability here
.collect(Collectors.toList());
// Let us count the number of true in this list
long numberOfTrue =
booleans.stream()
.filter(b -> b)//b本身就是boolean
.count();
System.out.println("numberOfTrue = " + numberOfTrue);如果您使用的種子與我們在本示例中使用的種子相同,您將看到以下結果。
numberOfTrue = 773您可以調整此模式以生成具有所需概率的任何類型的對象。下面是另一個示例,它生成帶有字母 A、B、C 和 D 的流。每個字母的概率如下:
- A的50%;
- B的30%;
- C的10%;
- D的10%。
Random random = new Random(314L);
List<String> letters =
random.doubles(1_000, 0d, 1d)
.mapToObj(rand ->
rand < 0.5 ? "A" : // 50% of A
rand < 0.8 ? "B" : // 30% of B
rand < 0.9 ? "C" : // 10% of C
"D") // 10% of D
.collect(Collectors.toList());
Map<String, Long> map =
letters.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));//每個出現的次數
map.forEach((letter, number) -> System.out.println(letter + " :: " + number));使用相同的種子,您將獲得以下結果。
A :: 470
B :: 303
C :: 117
D :: 110此時,使用此 groupingBy()) 構建map可能看起來不明白。不用擔心,本教程稍後將介紹。
從字符串的字符創建流
String 類在 Java SE 8 中添加了一個 chars()) 方法。此方法返回一個 IntStream,該 IntStream 為您提供字符。
每個字符都作為一個整數給出, ASCII 碼。在某些情況下,您可能需要轉換為字符串。
您有兩種模式可以執行此操作,具體取決於您使用的 JDK 版本。
在 Java SE 10 之前,您可以使用以下代碼。
String sentence = "Hello Duke";
List<String> letters =
sentence.chars()
.mapToObj(codePoint -> (char)codePoint)//int => char
.map(Object::toString)// char =>String
.collect(Collectors.toList());
System.out.println("letters = " + letters);在 Java SE 11 的 Character 類中添加了一個 toString()) 工廠方法,您可以使用它來簡化此代碼。
String sentence = "Hello Duke";
List<String> letters =
sentence.chars()
.mapToObj(Character::toString)//int =>String
.collect(Collectors.toList());
System.out.println("letters = " + letters);兩個代碼都打印出以下內容。
letters = [H, e, l, l, o, , D, u, k, e]從文本文件的行創建流
能夠在文本文件上打開流是一種非常強大的模式。
Java I/O API 有一個模式,能從文本文件中讀取一行:BufferedReader.readLine()。)您可以循環調用此方法,逐行讀取整個文本。
使用 Stream API 能為你提供更具可讀性和更易於維護的代碼。
有幾種模式可以創建這樣的流。
如果需要基於buffered reader重構現有代碼,則可以使用在此對象上定義的lines())方法。如果要編寫新代碼,可以使用工廠方法 Files.lines()。)最後一種方法將 Path 作為參數,並具有一個重載方法,添加 CharSet為參數,以防文件不是以 UTF-8 編碼。
您可能知道,文件資源與任何 I/O 資源一樣,當不再需要時,應將其關閉。
好消息是Stream接口實現了AutoCloseable。流本身就是一個資源,您可以在需要時關閉它。上面您看到的所有示例都運行在內存中,並不需要,但下面情況下肯定是必需的。
下面是計算日誌文件中警告數量的示例。
Path log = Path.of("/tmp/debug.log"); // adjust to fit your installation
try (Stream<String> lines = Files.lines(log)) {
long warnings =
lines.filter(line -> line.contains("WARNING"))
.count();
System.out.println("Number of warnings = " + warnings);
} catch (IOException e) {
// do something with the exception
}try-with-resources模式將調用流的 close()) 方法,該方法將正確關閉已解析的文本文件。
從正則表達式創建流
這一系列模式的最後一個示例是添加到 Pattern 類的方法,用於在將正則表達式應用於字符串生成的元素上創建流。
假設您需要用給定的分隔符拆分字符串。您有兩種模式來執行此操作。
- 你可以調用
String.split()) 方法; - 或者,您可以使用
Pattern.compile().split()) 模式。
這兩種模式都為您提供了一個字符串數組,其中包含拆分後的結果元素。
上面您看到了從此數組創建流的模式。讓我們編寫此代碼。
String sentence = "For there is good news yet to hear and fine things to be seen";
String[] elements = sentence.split(" ");
Stream<String> stream = Arrays.stream(elements);Pattern類也有一個適合你的方法。你可以調用 Pattern.compile().splitAsStream()。)下面是可以使用此方法編寫的代碼。
String sentence = "For there is good news yet to hear and fine things to be seen";
Pattern pattern = Pattern.compile(" ");
Stream<String> stream = pattern.splitAsStream(sentence);//
List<String> words = stream.collect(Collectors.toList());
System.out.println("words = " + words);運行此代碼將生成以下結果。
words = [For, there, is, good, news, yet, to, hear, and, fine, things, to, be, seen]您可能想知道這兩種模式中哪一種最好。要回答這個問題,您需要仔細查看下。第一種模式首先,創建一個數組來存儲拆分的結果,然後在此數組上創建一個流。
在第二種模式中沒有創建數組,因此開銷更少。
您已經看到某些流可能使用短路操作(本教程稍後將詳細介紹這一點)。如果您有這樣的流,拆分整個字符串並創建生成的數組可能是一個重要但無用的開銷。流管道不一定非要使用其所有元素才能生成結果。
即使您的流需要使用所有元素,將所有這些元素存儲在數組中仍然是不必要的。
因此,使用 splitAsStream()) 模式更好。在內存和 CPU 方面更好。
使用builder模式創建流
使用此模式創建流的過程分為兩個步驟。首先,在builder中添加流將使用的元素。然後,從此builder創建流。使用builder創建流後,您將無法向其添加更多元素,也無法再次使用它來構建另一個流。如果你這樣做,你會得到一個IllegalStateException。
模式如下。
Stream.Builder<String> builder = Stream.<String>builder();
builder.add("one")
.add("two")
.add("three")
.add("four");
Stream<String> stream = builder.build();//無法再次更改
List<String> list = stream.collect(Collectors.toList());
System.out.println("list = " + list);運行此代碼將打印以下內容。
list = [one, two, three, four]在 HTTP 源上創建流
我們在本教程中介紹的最後一個模式是關於分析 HTTP 響應的主體。您看到您可以在文本文件的行上創建流,也可以在 HTTP 響應的正文上執行相同的操作。此模式由添加到 JDK 11 的 HTTP Client API 提供。
這是它的工作原理。我們將在在線提供的文本中使用它:查爾斯狄更斯的《雙城記》,由古騰堡項目在線提供:https://www.gutenberg.org/files/98/98-0.txt
文本文件的開頭提供有關文本本身的信息。這本書的開頭是“A TALE OF TWO CITIES”。文件的末尾是分發此文件的許可證。
我們只需要本書的文本,並希望刪除此分佈式文件的頁眉和頁腳。
// The URI of the file
URI uri = URI.create("https://www.gutenberg.org/files/98/98-0.txt");
// The code to open create an HTTP request
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder(uri).build();
// The sending of the request
HttpResponse<Stream<String>> response = client.send(request, HttpResponse.BodyHandlers.ofLines());
List<String> lines;
try (Stream<String> stream = response.body()) {
lines = stream
.dropWhile(line -> !line.equals("A TALE OF TWO CITIES"))
.takeWhile(line -> !line.equals("*** END OF THE PROJECT GUTENBERG EBOOK A TALE OF TWO CITIES ***"))
.collect(Collectors.toList());
}
System.out.println("# lines = " + lines.size());運行此代碼將打印出以下內容。
# lines = 15904流由您提供的body handler創建,作為 send()) 方法的參數。HTTP Client API 為您提供了多個body handler。上面是由工廠方法 HttpResponse.BodyHandlers.ofLines()) 創建的。這種消費響應主體的方式非常節省內存。如果仔細編寫流,響應的正文將永遠不會存儲在內存中。
我們這裏將所有文本行放在一個列表中,但是,您不一定需要這樣做。實際上,大多數情況下,將此數據存儲在內存中可能是一個壞主意。
reduce流
reduce流
到目前為止,您在本教程中瞭解到,reduce流包括以類似於 SQL 語言中的方式聚合該流的元素。在您運行的示例中,您還使用collect(Collectors.toList())模式在列表中收集了您構建的流的元素。所有這些操作在Stream API 中稱為末端操作,包括reduce流。
在流上調用末端操作時,需要記住兩件事。
- 沒有末端操作的流不會處理任何數據。如果您在應用程序中發現這樣的流,則很可能是一個錯誤。
- 一個流同時只能有一箇中繼或末端操作調用。您不能重複使用流;如果你嘗試這樣做,你會得到一個
IllegalStateException。
使用binary operator來reduce流
在 Stream 接口中定義的 reduce()) 方法有三個重載。它們都接收 BinaryOperator 對象作為參數。讓我們看看如何使用這個binary operator。
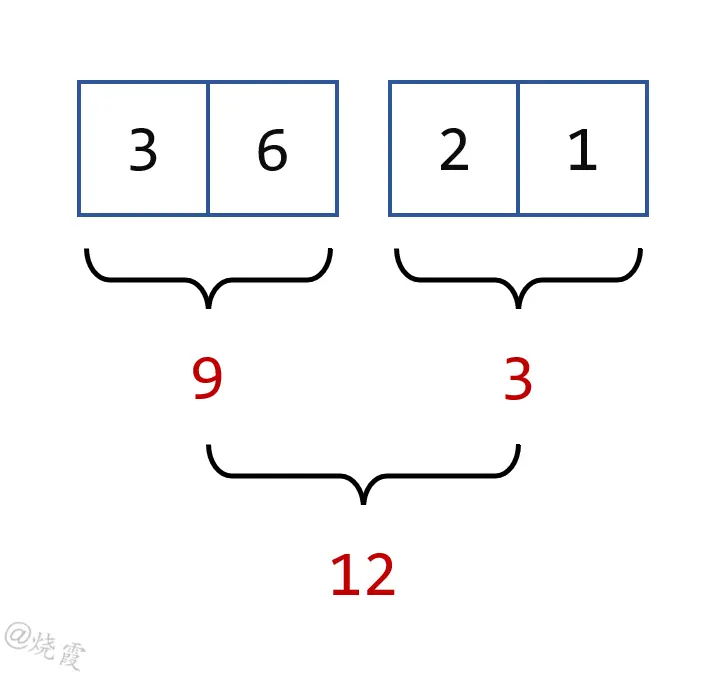
讓我們舉個例子。假設您有一個整數列表,您需要計算這些整數的總和。您可以使用經典的 for 循環模式編寫以下代碼來計算此總和。
List<Integer> ints = List.of(3, 6, 2, 1);
int sum = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
sum += ints.get(index);
}
System.out.println("sum = " + sum);運行它會打印出以下結果。
sum = 12此代碼的作用如下。
- 將列表中的前兩個元素相加。
- 然後取下一個元素並將其求和到您計算的部分總和。
- 重複該過程,直到到達列表末尾。
如果仔細檢查此代碼,可以使用binary operator對 SUM 運算符進行建模,以獲得相同的結果。然後,代碼將變為以下內容。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;//把操作邏輯提取為lambda
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = sum.apply(result, ints.get(index));
}
System.out.println("sum = " + result);現在您可以看到此代碼僅依賴於binary operator本身。假設您需要計算一個 MAX。您需要做的就是為此提供正確的binary operator。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> max = (a, b) -> a > b ? a: b;//提供具體函數即可
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = max.apply(result, ints.get(index));
}
System.out.println("max = " + result);結論是,您確實可以僅提供binary operator來計算reduce。這就是 reduce()) 方法在 Stream API 中的工作方式。
選擇可以並行使用的binary operator
不過,您需要了解兩個注意事項。讓我們在這裏介紹第一個。
第一個是可以並行計算的流。本教程稍後將更詳細地介紹這一點,但現在需要討論它,因為它對這個binary operator有影響。數據源分為兩部分,每部分單獨處理。每個進程都與您剛剛看到的進程相同,它使用binary operator。然後,在處理每個部分時,兩個部分結果將使用相同的binary operator合併。
並行處理這個數據流非常簡單:只需在給定流上調用 parallel()) 即可。
讓我們來看看事情是如何工作的,為此,您可以編寫以下代碼。您只是在模擬如何並行執行計算。當然,這是並行流的過度簡化版本,只是為了解釋事情是如何工作的。
讓我們創建一個 reduce()) 方法,該方法接收binary operator並使用它來reduce整數列表。代碼如下。
int reduce(List<Integer> ints, BinaryOperator<Integer> sum) {
int result = ints.get(0);
for (int index = 1; index < ints.size(); index++) {
result = sum.apply(result, ints.get(index));
}
return result;
}下面是使用此方法的主要代碼。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;//兩個Integer的具體操作
int result1 = reduce(ints.subList(0, 2), sum);
int result2 = reduce(ints.subList(2, 4), sum);
int result = sum.apply(result1, result2);
System.out.println("sum = " + result);為了讓過程更明顯,我們將您的數據源分為兩部分,並將它們分別reduce為兩個整數:reduce1和reduce2 。然後,我們使用相同的binary operator合併了這些結果。這基本上就是並行流的工作方式。
這段代碼非常簡化,它只是為了顯示你的binary operator應該具有的一個非常特殊的屬性。拆分流的方式不應影響計算結果。以下所有拆分都應提供相同的結果:
3 + (6 + 2 + 1)(3 + 6) + (2 + 1)(3 + 6 + 2) + 1
這表明您的binary operator應該具有一個稱為結合性 associativity的已知屬性。傳遞給 reduce()) 方法的binary operator應該是可結合的。
Stream API 的 reduce()) 重載版本, JavaDoc API 文檔指出,您作為參數提供的binary operator必須是可結合的。
如果不是這樣,會發生什麼?嗯,這正是問題所在:編譯器和 Java 運行時都不會檢測到它。因此,您的數據將被處理,沒有明顯的錯誤。你可能有正確的結果,也可能沒有;這取決於內部處理數據的方式。事實上,如果你多次運行代碼,你最終可能會得到不同的結果。這是您需要注意的非常重要的一點。
如何測試binary operator是否可結合?在某些情況下,這可能非常簡單:SUM,MIN,MAX是眾所周知的可結合運算符。在其他一些情況下,這可能要困難得多。檢查的一種方法,可以是在隨機數據上運行binary operator,並驗證是否始終獲得相同的結果。
管理具有幺元的binary operator
第二個是binary operator這種結合性產生的結果。
此結合性屬性是由以下事實保證的:數據的拆分方式不應影響計算結果。如果將集合 A 拆分為兩個子集 B 和 C,則reduce A 應該得到與reduce (B 的reduce和 C 的reduce)相同的結果。
可以將前面的屬性寫入更通用的表達式:
A = B ⋃ C ⇒ Red(A) = Red(Red(B), Red(C))
事實證明,這導致了另一個問題。假設事情出了意外,B實際上是空的。這種情況下,C = A。前面的表達式變為以下內容:
Red(A) = Red(Red(∅), Red(A)) //必須成立才行
當且僅當空集 (∅) 的reduce是reduce操作的幺元identity element時,才是正確的。
這是數據處理中的一種屬性:空集的reduce是reduce操作的幺元。
在數據處理中這確實是一個問題,尤其是在並行處理中,一些非常經典的binary operator並沒有幺元,比如 MIN 和 MAX。空集的最小元素沒有定義,因為 MIN 操作沒有幺元。
此問題必須在Stream API 中解決,因為您可能必須處理空流。您看到了創建空流的模式,很容易看出 filter()) 可以filter掉所有數據,從而返回空流。
Stream API 是這樣處理的。幺元未知(不存在或未提供)的reduce將返回 Optional 類的實例。我們將在本教程後面更詳細地介紹此類。此時您需要知道的是,此 Optional 類是一個可以為空的包裝類。每次對沒有已知幺元的流調用末端操作時,Stream API 都會將結果包裝在該對象中。如果處理的流為空,則此Optional對象也將為空,下一步如何處理將由您和您的應用程序決定。
探索Stream API 的reduce方法
正如我們前面提到的,Stream API 有三個重載的 reduce()) 方法,我們現在可以詳細介紹這些重載。
使用幺元進行reduce
第一個接收幺元和 BinaryOperator 的實例。由於您提供的第一個參數是binary operator的已知幺元,因此具體實現可能會使用它來簡化計算。從這個幺元開始,啓動進程,而不是選兩個元素。使用的算法具有以下形式。
List<Integer> ints = List.of(3, 6, 2, 1);
BinaryOperator<Integer> sum = (a, b) -> a + b;
int identity = 0;
int result = identity;//人為設定幺元,初始值
for (int i: ints) {
result = sum.apply(result, i);
}
System.out.println("sum = " + result);你可以注意到,即使你需要處理的列表是空的,這種編寫方式也能很好地工作。這種情況下,它將返回幺元,這是您需要的。
API 不會檢查您提供的元素確實是binary operator的幺元這一事實。提供不對的元素將返回錯誤的結果。
您可以在以下示例中看到這一點。
Stream<Integer> ints = Stream.of(0, 0, 0, 0);
int sum = ints.reduce(10, (a, b) -> a + b);//初始值為10
System.out.println("sum = " + sum);您希望此代碼在控制枱上打印值 0。因為 reduce()) 方法調用的第一個參數不是binary operator的幺元,所以結果實際上是錯誤的。運行此代碼將在主機上打印以下內容。
sum = 10這是您應該使用的正確代碼。
Stream<Integer> ints = Stream.of(0, 0, 0, 0);
int sum = ints.reduce(0, (a, b) -> a + b);//初始值為0
System.out.println("sum = " + sum);此示例説明在編譯或運行代碼時傳遞錯誤的幺元不會觸發任何錯誤或異常。具體取決於您。
此屬性的測試方式可以跟測試結合性相同。將候選幺元與儘可能多的值組合在一起。如果您找到一個因組合而改變的值,那麼您的幺元就不是合適的候選。反之並不成立,如果您找不到任何錯誤的組合,並不一定意味着您的候選就是正確的。
不使用幺元進行reduce
reduce()) 方法的第二個重載接收沒有幺元的 BinaryOperator 實例作為參數。正如預期的那樣,它返回一個 Optional 對象,包裝reduce的結果。使用Optional做的最簡單的事情,就是打開並查看其中是否有任何東西。
讓我們舉一個沒有幺元的reduce示例。
Stream<Integer> ints = Stream.of(2, 8, 1, 5, 3);
Optional<Integer> optional = ints.reduce((i1, i2) -> i1 > i2 ? i1: i2);//大於空集沒有意義,可能為null
if (optional.isPresent()) {
System.out.println("result = " + optional.orElseThrow());
} else {
System.out.println("No result could be computed");
}運行此代碼將產生以下結果。
result = 8請注意,此代碼使用 orElseThrow()) 方法打開可選代碼,該方法現在是執行此操作的首選方法。此模式已在 Java SE 10 中添加,以取代最初在 Java SE 8 中引入的更傳統的 get()) 方法。
get())方法的問題在於,如果Optional為空,可能會拋出一個NoSuchElementException。此方法的命名 orElseThrow)() 比 get()) 更直觀,它提醒您,打開空的Optional您將收到異常。
使用Optional可以完成更多操作,您將在本教程後面瞭解。
在一種方法中組合map和reduce
第三個稍微複雜一些。它使用多個參數組合combine了內部mapping和reduce。
讓我們檢查一下此方法的簽名。
<U> U reduce(U identity,//幺元
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);//兩個U類型的具體操作類型U在本地定義並由binary operator使用。binary operator的工作方式與 reduce()) 剛才那個重載相同,只是它不應用於流的元素,而僅應用於它們mapping後的版本。
這種mapping和reduce本身實際上組合為一個操作:累加器accumulator。請記住,在本部分的開頭,您看到reduce是逐步進行的,並且一次消費一個元素。在每一步,reduce操作的第一個參數是到目前為止消費的所有元素的reduce部分。
幺元是combiner的幺元。的確是這樣。
假設您有一個 String 實例流,您需要對所有字符串的長度求和。
combiner組合了兩個部分:到目前處理的字符串長度的部分總和,兩個整數。
accumulator從流中獲取一個元素,將其map為一個整數(該字符串的長度),並將其添加到到目前為止計算的總和中。
以下是該算法的工作原理。

相應的代碼如下。
Stream<String> strings = Stream.of("one", "two", "three", "four");
BinaryOperator<Integer> combiner = (length1, length2) -> length1 + length2;//兩個Integer部分總和,具體操作
//累加mapping操作:部分總和Integer,跟新元素String作運算,返回新的部分總和Integer
BiFunction<Integer, String, Integer> accumulator =
(partialReduction, element) -> partialReduction + element.length();
int result = strings.reduce(0, accumulator, combiner);//combiner的初始值為0
System.out.println("sum = " + result);運行此代碼將生成以下結果。
sum = 15在上面的示例中,mapping過程實際為以下函數。
Function<String, Integer> mapper = String::length;因此,您可以將accumulator重寫為以下模式。這種寫法清楚地顯示了mapping的組合過程。
Function<String, Integer> mapper = String::length;//mapping
BinaryOperator<Integer> combiner = (length1, length2) -> length1 + length2;
BiFunction<Integer, String, Integer> accumulator =
(partialReduction, element) -> partialReduction + mapper.apply(element);在流上添加末端操作
避免使用reduce方法
如果流不以末端操作結束,則不會處理任何數據。我們已經介紹了末端操作 reduce(),)您在其他示例中看到了幾個末端操作。現在讓我們介紹其他幾個。
使用 reduce()) 方法並不是reduce流的最簡單方法。您需要確保您提供的binary operator是可結合的,然後您需要知道它是否具有幺元。您需要檢查許多點,以確保您的代碼正確併產生您期望的結果。如果你可以避免使用 reduce()) 方法,那麼你絕對應該這樣做,因為它很容易出錯。
幸運的是,Stream API 為您提供了許多其他reduce流的方法:我們在介紹專門的數字流時介紹的 sum()、min() 和 max()) 是您可以使用的便捷方法。事實上,你只能吧 reduce()) 方法作為最後的手段,只有當你沒有其他解決方案時。
計算元素數量
count()) 方法存在於所有流接口中,包括專用流和對象流。它用long返回該流處理的元素數。這個數字可能很大,實際上大於 Integer.MAX_VALUE。
您可能想知道為什麼需要如此多的數字。實際上,您可以從許多源創建流,包括可以生成大量元素的源,大於 Integer.MAX_VALUE。即使不是這種情況,也很容易創建一箇中繼操作,將流處理的元素數量成倍增加。我們在本教程前面介紹的 flatMap()) 方法可以做到這一點。有很多方法可以讓你最終超過 Integer.MAX_VALUE 。這就是 Stream API 支持它的原因。
下面是 count()) 方法的一個示例。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
long count =
strings.stream()
.filter(s -> s.length() == 3)
.count();
System.out.println("count = " + count);運行此代碼將生成以下結果。
count = 4逐個消費元素
Stream API 的 forEach()) 方法允許您將流的每個元素傳遞給Consumer接口的實例。此方法對於打印流處理的元素非常方便。這就是以下代碼的作用。
Stream<String> strings = Stream.of("one", "two", "three", "four");
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.forEach(System.out::println);運行此代碼將打印以下內容。
ONE
TWO這種方法非常簡單,但您可能會用錯。
請記住,您編寫的 lambda 表達式應避免改變其外部作用域。有時,在狀態外發生突變稱為傳導副作用。剛才的Consumer很特殊,因為沒有什麼特別的副作用。實際上也有,調用 System.out.println()) 會對應用程序的控制枱產生副作用。
讓我們考慮以下示例。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result = new ArrayList<>();
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.forEach(result::add);
System.out.println("result = " + result);運行前面的代碼會打印出以下內容。
result = [ONE, TWO]因此,您可能會想使用此代碼,因為它很簡單,而且能“正常工作”。好吧,這段代碼正在做一些錯誤的事情。讓我們來看看它們。
從流中調用result::add,將該流處理的所有元素添加到外部result列表中。此Consumer正在對流本身範圍之外的變量產生副作用。
訪問此類變量會使您的 lambda 表達式成為捕獲式 lambda 表達式。創建這樣的 lambda 表達式雖然完全合法,但會降低性能。如果性能是應用程序中的重要問題,則應避免編寫捕獲式 lambda。
此外,這種方式也會阻止此流的並行。實際上,如果您嘗試使此流並行,您將有多個線程並行訪問您的result列表。而 ArrayList 並不是併發安全的類。
有兩種變通模式收集到列表。下面的示例演示使用集合對象。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toList());這段代碼同樣創建 ArrayList 的實例,並將流處理的元素添加到其中。不會產生任何副作用,因此不會對性能造成影響。
並行性和併發性由Collector API 本身處理,因此您可以安全地使此流並行。
從Java SE 16開始,您有第二種更簡單的模式,使用collector對象。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toList();此模式生成 List 的特殊不可變實例。如果你需要一個可變列表,你應該使用上一種。另外,它還比在 ArrayList 中收集流的性能更好。這一點將在下一段介紹。
收集到集合或數組中
Stream API 提供了多種將流元素收集到集合中的方法。在上一節中,您初步瞭解了其中兩種。讓我們看看其他的。
在選擇所需的模式之前,您需要問自己幾個問題。
- 是否需要構建不可變列表?
- 你對
ArrayList的實例感到滿意嗎?或者你更喜歡LinkedList? - 您是否確切地知道您的流將處理多少個元素?
- 您是否需要在精確的、可能是第三方或自制的
List中收集您的元素?
Stream API 可以處理所有這些情況。
在ArrayList中收集
您已經在前面的示例中使用了此模式。它是您可以使用的最簡單的方法,並返回 ArrayList 實例中的元素。
下面是這種模式的實際示例。
Stream<String> strings = Stream.of("one", "two", "three", "four");
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toList());此模式創建 ArrayList 的簡單實例,並在其中累積流的元素。如果有太多元素, ArrayList 的內部數組無法存儲它們,則當前數組將被複制到一個更大的數組中,並由GC回收。
如果你想避免這種情況,並且知道你的流將產生的元素數量,那麼你可以使用 Collectors.toCollection()) ,它以supplier作為參數來創建集合,你將在其中收集處理的元素。以下代碼使用此模式創建初始容量為 10,000 的 ArrayList 實例。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toCollection(() -> new ArrayList<>(10_000)));在不可變List中收集
在某些情況下,您需要在不可變列表中累積元素。這聽起來可能自相矛盾,因為收集意味着將元素添加到必須可變的容器中。實際上,這就是Collector API 的工作方式,本教程後面將詳細介紹。在此累加操作結束時,Collector API 可以繼續執行最後一個可選操作,本例中,在返回之前密封這個列表。
為此,您只需使用以下模式。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toUnmodifiableList()));在此示例中,result是一個不可變列表。
從 Java SE 16 開始,有一種更好的方法可以在不可變列表中收集數據,這在某些情況下可能更有效。模式如下。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toList();如何提高效率的?第一種模式是建立在使用collector的基礎上的,首先在普通 ArrayList 中收集元素,然後將其密封,使其在處理完成後不可變。您的代碼看到的只是從此 ArrayList 構建的不可變列表。
如您所知,ArrayList 的實例是在具有固定大小的內部數組上構建的。此列表可能已滿。這種情況下,ArrayList 實現會檢測到並將其複製到更大的數組中。此機制對使用者是透明的,但會帶來開銷:複製此數組需要一些時間。
在某些情況下,在消費所有流之前,Stream API 可以跟蹤要處理的元素數量。這種情況下,創建大小合適的內部數組更有效,因為它避免了將小數組到較大數組的開銷。
Stream.toList()) 方法已添加到 Java SE 16 中。如果您需要的是不可變的列表,那麼您應該使用此模式。
在自制List中收集
如果您需要在自己的列表或 JDK 之外的第三方List中收集數據,則可以使用 Collectors.toCollection()) 模式。用於調整 ArrayList 初始大小的supplier也可用於構建 Collection 的任何實現,包括不屬於 JDK 的實現。您所需要的只是一個supplier。在以下示例中,我們提供了一個supplier來創建 LinkedList 的實例。
Stream<String> strings = ...;
List<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toCollection(LinkedList::new));在Set中收集
由於 Set 接口是 Collection 接口的擴展,因此可以使用 Collectors.toCollection(HashSet::new)) 在 Set 實例中收集數據。這很好,但 Collector API 仍然為您提供了一個更簡潔的模式:Collectors.toSet()。)
Stream<String> strings = ...;
Set<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toSet());您可能想知道這兩種模式之間是否有任何區別。答案是肯定的,存在細微的區別,您將在本教程後面看到。
如果你需要的是一個不可變的集合,Collector API 還有另一種模式:Collectors.toUnmodifiableSet()。)
Stream<String> strings = ...;
Set<String> result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.collect(Collectors.toUnmodifiableSet());在數組中收集
Stream API 也有自己的一組 toArray()) 方法重載。其中有兩個。
第一個是普通的 toArray()) 方法,它返回Object[] .使用此模式會丟失元素的確切類型。
第二個參數接收 IntFunction<A[]> 類型的參數,按照size返回一個數組。乍一看可能很嚇人,但編寫此函數的實現實際上非常容易。如果需要構建一個字符串數組,則此函數的實現為 String[]::new。
Stream<String> strings = ...;
String[] result =
strings.filter(s -> s.length() == 3)
.map(String::toUpperCase)
.toArray(String[]::new);
System.out.println("result = " + Arrays.toString(result));運行此代碼將生成以下結果。
result = [ONE, TWO]提取流的最大值和最小值
Stream API 為此提供了幾種方法,具體取決於您當前正在使用的流。
我們已經介紹了來自專用數字流的 max()) 和 min()) 方法:IntStream、LongStream 和 DoubleStream。您知道這些操作沒有幺元,因此所有都將返回Optional。
順便説一下,同樣來自數字流的 average()) 方法也返回一個Optional對象,因為 average 操作也沒有幺元。
Stream 接口也有兩個方法 max()) 和 min(),)它們也返回一個Optional對象。與數字流的區別在於,Stream的元素實際上可以是任何類型的。為了能夠計算最大值或最小值,實現需要比較這些對象。這就是您需要為這些方法提供comparator的原因。
這是 max()) 方法的實際應用。
Stream<String> strings = Stream.of("one", "two", "three", "four");
String longest =
strings.max(Comparator.comparing(String::length))//對象Stream
.orElseThrow();
System.out.println("longest = " + longest);它將打印以下內容。
longest = three請記住,嘗試打開空的Optional對象會拋出 NoSuchElementException,這是您不希望在應用程序中看到的內容。僅當您的流沒有任何要處理的數據時,才會這樣。在這個簡單的示例中,你有一個流,它處理多個字符串,沒有filter操作。此流不會為空,因此您可以安全地打開。
在流中查找元素
Stream API 為您提供了兩個末端操作來查找元素:findFirst()) 和 findAny()。)這兩個方法不接受任何參數,並返回流的單個元素。為了正確處理空流的情況,此元素包裝在Optional對象中。如果流為空,則此Optional也為空。
瞭解返回哪個元素需要您瞭解流可能是順序的。順序流只是一種流,其中元素的順序很重要,並由Stream API 保存。默認情況下,在任何順序源(例如 List 接口的實現)上創建的流本身都是順序的。
在這樣的流上,稱呼第一個、第二個或第三個元素是有意義的。找到這樣一個流的第一個元素也是完全有意義的。
如果您的流無序,或者如果順序在流處理中丟失了,則查找第一個元素是無法定義的,並且調用 findFirst()) 實際上會返回流的任何元素。您將在本教程後面看到有關順序流的更多詳細信息。
請注意,調用 findFirst()) 會在流實現中觸發一些檢查,以確保在對該流進行排序時獲得該流的第一個元素。如果您的流是並行流,這可能代價很高。在許多情況下,獲取的是不是第一個元素並無所謂,比如流僅處理單個元素的情況。在所有這些情況下,您應該使用 findAny()) 而不是 findFirst()。)
讓我們看看 findFirst()) 的實際效果。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
String first =
strings.stream()
// .unordered()
// .parallel()
.filter(s -> s.length() == 3)
.findFirst()
.orElseThrow();
System.out.println("first = " + first);此流是在 List 的實例上創建的,這使它成為順序流。請注意,在第一個版本中註釋了 unordered()) 和 parallel()) 兩行。
多次運行此代碼將始終得到相同的結果。
first = oneunordered()) 中繼方法調用使順序流成為無序流。這種情況下,它沒有任何區別,因為您的流是按順序處理的。您的數據是從始終以相同順序遍歷其元素的列表中提取的。出於同樣的原因,將 findFirst()) 方法調用替換為 findAny()) 方法調用也沒有任何區別。
可以對此代碼進行的第一個修改是取消註釋 parallel()) 方法調用。現在,您有一個並行處理的順序流。多次運行此代碼將始終得到相同的結果:one。這是因為您的流是順序的,因此無論您的流是如何處理的,第一個元素都是確定的。
要使此流無序,您可以取消註釋 unordered()) 方法調用,或者將 (List.of) )替換為 Set.of()。)在這兩種情況下,使用 findFirst()) 終止流將從該並行流返回一個隨機元素。並行流的處理方式使其如此。
您可以在此代碼中進行的第二個修改是將 List.of()) 替換為 Set.of()。)現在不再是順序的。此外,Set.of()) 返回的實現,使得集合元素的遍歷以隨機順序發生。多次運行此代碼會顯示 findFirst()) 和 findAny)() 都返回一個隨機字符串,即使 unordered)() 和 parallel()) 都註釋掉。查找無序源的第一個元素無法定義,結果是隨機的。
從這些示例中,您可以推斷出在並行流的實現中採取了一些預防措施來跟蹤哪個元素是第一個。這造成了開銷,因此,只有在確實需要時才應調用 findFirst()。)
檢查流的元素是否與Predicate匹配
在某些情況下,在流中查找元素或未能在流中找到元素可能是您真正需要的。您查找的元素不一定與您的應用程序有關;但是否存在非常重要。
以下代碼將用於檢查給定元素是否存在。
boolean exists =
strings.stream()
.filter(s -> s.length() == 3)
.findFirst()
.isPresent();實際上,此代碼檢查返回的Optional是否為空。
上面的模式工作正常,但Stream API 提供了一種更有效的方法。實際上,構建此Optional對象是一種開銷,如果您使用以下三種方法之一,則無需支付該開銷。這三種方法將Predicate作為參數。
anyMatch(Predicate):)如果找到與給定Predicate匹配的一個元素,則返回trueallMatch(Predicate):)如果流的所有元素都與Predicate匹配,則返回truenoneMatch(Predicate):)相反
讓我們看看這些方法的實際應用。
Collection<String> strings =
List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
boolean noBlank =
strings.stream()
.allMatch(Predicate.not(String::isBlank));
boolean oneGT3 =
strings.stream()
.anyMatch(s -> s.length() == 3);
boolean allLT10 =
strings.stream()
.noneMatch(s -> s.length() > 10);
System.out.println("noBlank = " + noBlank);
System.out.println("oneGT3 = " + oneGT3);
System.out.println("allLT10 = " + allLT10);運行此代碼將生成以下結果。
noBlank = true
oneGT3 = true
allLT10 = true短路流的處理
您可能已經注意到我們在此處介紹的不同末端操作之間的重要差異。
其中一些需要處理流消費的所有數據。COUNT、MAX、MIN、AVERAGE操作以及forEach)()、toList)()或toArray())方法調用就是這種情況。
我們介紹的最後一個末端操作並非如此。一旦找到元素,findFirst()) 或 findAny()) 方法就會停止處理您的數據,無論還有多少元素需要處理。anyMatch()、allMatch() 和 noneMatch() 也是如此:它們可能會中斷流的處理並得到結果,而不必消費源所有元素。
這些方法在Stream API 中稱為短路方法,因為它們可以半路生成結果,而無需處理流的所有元素。
在某些情況下,這些最後的方法仍然可能處理所有元素:
findFirst()) 和findAny())返回了空的Optional,只能在所有元素都已處理後。anyMatch()返回了false。- allMatch() 和
noneMatch())返回 了true。
查找流的特徵
流的特徵
Stream API 依賴於一個特殊的對象,即 Spliterator 接口的實例。此接口的名稱來源於這樣一個事實,即Stream API 中spliterator的角色類似於iterator在集合 API 中的角色。此外,由於Stream API 支持並行處理,因此spliterator對象還控制流在處理並行化時,不同 CPU 之間如何拆分其元素。名稱是split和iterator的組合。
詳細介紹此spliterator對象超出了本教程的範圍。您需要知道的是,此spliterator對象具有流的特徵。這些特徵不是您經常使用到的,但瞭解它們是什麼將幫助您在某些情況下編寫更好、更高效的管道。
流的特徵如下。
| 特徵 | 評論 |
|---|---|
| ORDERED | 順序的,處理流元素的順序很重要。 |
| DISTINCT | 去重的,該流處理的元素中沒有重複出現。 |
| NONNULL | 該流中沒有空元素。 |
| SORTED | 排序的,對該流的元素已經進行排序。 |
| SIZED | 有數量的,此流處理的元素數是已知的。 |
| SUBSIZED | 拆分此流會產生兩個 SIZED 流。 |
有兩個特徵,不可變 IMMUTABLE和併發的 CONCURRENT,本教程未介紹。
每個流在創建時都設置或取消設置了所有這些特徵。
請記住,可以通過兩種方式創建流。
- 您可以從數據源創建流,我們介紹了幾種不同的模式。
- 每次對現有流調用中繼操作時,都會創建一個新流。
給定流的特徵取決於創建它的源,或者創建它的流的特徵,以及創建的操作。如果您的流是使用源創建的,則其特徵取決於該源,如果您使用另一個流創建它,則它們將取決於該其他流以及您正在使用的操作類型。
讓我們更詳細地介紹每個特徵。
ORDERED流
順序流是使用順序數據源創建的。可能想到的第一個示例是 List 接口的任何實例。還有其他的:Files.lines(path)) 和 Pattern.splitAsStream(string)) 也生成 ORDERED 流。
跟蹤流元素的順序可能會導致並行流的開銷。如果不需要此特性,則可以通過在現有流上調用 unordered()) 中繼方法來刪除它。這將返回沒有此特徵的新流。你為什麼要這樣做?在某些情況下,保持流 ORDERED 可能會很昂貴,例如,當您使用並行流時。
SORTED流
SORTED的流是已排序的流。可以從已排序的源(如 TreeSet 實例)或通過調用 sorted()) 方法創建此流。知道流已被排序可能會被流的某些實現拿來用,以避免再次進行排序。但排序後的順序可能會變,因為 SORTED 流可能會使用與第一次不同的comparator再次排序。
有一些中繼操作可以清除 SORTED 特徵。在下面的代碼中,您可以看到strings,filteredStream兩者都是 SORTED 流,而lengths不是。
Collection<String> stringCollection = List.of("one", "two", "two", "three", "four", "five");
Stream<String> strings = stringCollection.stream().sorted();
Stream<String> filteredStrings = strings.filtered(s -> s.length() < 5);
Stream<Integer> lengths = filteredStrings.map(String::length);mapping或flatmapping SORTED 流會從生成的流中刪除此特徵。
DISTINCT流
DISTINCT 流是它正在處理的元素之間沒有重複項的流。例如,當從 HashSet 構建流時,或者從對 distinct()) 中繼方法調用的調用中構建流時,可以獲得這樣的特徵。
DISTINCT 特徵在filtering流時保留,但在mapping或flatmapping流時丟失。
讓我們檢查以下示例。
Collection<String> stringCollection = List.of("one", "two", "two", "three", "four", "five");
Stream<String> strings = stringCollection.stream().distinct();
Stream<String> filteredStrings = strings.filtered(s -> s.length() < 5);
Stream<Integer> lengths = filteredStrings.map(String::length);stringCollection.stream()) 不是 DISTINCT 的,因為它是從List的實例構建的。strings是 DISTINCT 的,因為此流是通過調用distinct()) 中繼方法創建的。filteredStrings仍然是 DISTINCT:從流中刪除元素不會創造重複項。length已被map,因此 DISTINCT 特徵丟失。
NONNULL 流
非空流是不包含null值的流。集合框架中的一些結構不接受空值,包括 ArrayDeque 和併發結構,如 ArrayBlockingQueue、ConcurrentSkipListSet 和調用 ConcurrentHashMap.newKeySet()) 返回的併發Set。使用 Files.lines(path)) 和 Pattern.splitAsStream(line)) 創建的流也是非空流。
至於前面的特徵,一些中繼操作可以產生具有不同特徵的流。
- filtering或排序非空流將返回非空流。
- 在 NONNULL 流上調用
distinct()) 也會返回一個 NONNULL 流。 - mapping或flatmapping NONNULL 流將返回沒有此特徵的流。
SIZED和SUBSIZED流
SIZED流
當您想要使用並行流時,最後一個特徵非常重要。本教程稍後將更詳細地介紹並行流。
SIZED 流是知道它將處理多少個元素的流。從 Collection 的任何實例創建的流都是這樣的流,因為 Collection 接口具有 size()) 方法,因此獲取此數字很容易。
另一方面,在某些情況下,您知道流的元素是有限數的,但除非您處理流本身,否則您無法知道此數量。
對於使用 Files.lines(path)) 模式創建的流,情況就是如此。您可以獲取文本文件的大小(以字節為單位),但此信息不會告訴您此文本文件有多少行。您需要分析文件以獲取此信息。
Pattern.splitAsStream(line)) 模式也是。知道您正在分析的字符串中的字符數並不能給出任何關於此模式將產生多少元素的提示。
SUBSIZED流
SUBSIZED 特徵,與並行流的拆分方式有關。簡單説,並行化機制將流分成兩部分,並在 CPU 正在執行的不同可用內核之間分配計算。此拆分由流使用的 Spliterator 實例實現。具體實現取決於您使用的數據源。
假設您需要在 ArrayList 上打開一個流。此列表的所有數據都保存在 ArrayList 實例的內部數組中。也許您還記得 ArrayList 對象上的內部數組是一個緊湊數組,每當數組中刪除元素時,所有後續元素都會向左移動一個單元格,不會留下任何空位。
這使得拆分 ArrayList 變得簡單明瞭。要拆分 ArrayList 的實例,您可以將此內部數組拆分為兩部分,兩部分中的元素數量相同。這使得在 ArrayList 實例上創建的流具有 SUBSIZED特性:您甚至可以設定拆分後每個部分中將保留多少個元素。
假設現在您需要在 HashSet 實例上打開一個流。HashSet 將其元素存儲在數組中,但此數組的使用方式與 ArrayList 使用的數組不同。實際上,多個元素可以存儲在此數組的一個單元格中。拆分這個數組沒有問題,但是如果不計算一下,就無法提前知道每個部分中將保留多少個元素。即使你把這個數組從中間分開,也無法保證兩半的元素數量就是相同。這就是為什麼在 HashSet 實例上創建的流是 SIZED而不是 SUBSIZED 。
map流可能會更改返回流的 SIZED 和 SUBSIZED 特徵。
- mapping和排序流會保留 SIZED 和 SUBSIZED特徵。
- flatmapping、filtering和調用
distinct()) 會擦除這些特徵。
最好用有 SIZED 和 SUBSIZED 的流進行並行計算。