

過去2年,整個行業彷彿陷入了一場參數競賽,每一次模型發佈的敍事如出一轍:“我們堆了更多 GPU,用了更多數據,現在的模型是 1750 億參數,而不是之前的 1000 億。”
這種慣性思維讓人誤以為智能只能在訓練階段“烘焙”定型,一旦模型封裝發佈,能力天花板就被焊死了。

但到了 2025 年,這個假設徹底被打破了。
先是 DeepSeek-R1 證明了只要給予思考時間,Open-weights 模型也能展現出驚人的推理能力。緊接着 OpenAI o3 登場,通過在單個問題上消耗分鐘級而非毫秒級的時間,橫掃了各大基準測試。
大家突然意識到我們一直優化錯了變量。技術突破點不在於把模型做得更大,而在於讓模型在輸出結果前學會暫停、思考和驗證。
這就是 Test-Time Compute(測試時計算),繼 Transformer 之後,數據科學領域最重要的一次架構級範式轉移。
推理側 Scaling Law:比 GPT-4 更深遠的影響
以前我們奉 Chinchilla Scaling Laws 為圭臬,認為性能嚴格受限於訓練預算。但新的研究表明,Inference Scaling(訓練後的計算投入)遵循着一套獨立的、往往更為陡峭的冪律曲線。
幾項關鍵研究數據揭示了這一趨勢:
arXiv:2408.03314 指出,優化 LLM 的測試時計算往往比單純擴展參數更有效。一個允許“思考” 10 秒的小模型,其實際表現完全可以碾壓一個瞬間給出答案但規模大 14 倍的巨型模型。
實戰數據也印證了這一點。2025 年 1 月發佈的 DeepSeek-R1,其純強化學習版本在 AIME 數學基準測試中,僅通過學習自我驗證(Self-Verify),得分就從 15.6% 暴漲至 71.0%;引入 Majority Voting(多數投票)機制後,更是飆升至 86.7%。到了 4 月,OpenAI o3 在 AIME 上更是達到了驚人的 96.7%,在 Frontier Math 上拿到 25.2%,但代價是處理每個複雜任務的成本超過 $1.00。
結論很明顯:在推理階段投入算力的回報率,正在超越訓練階段。
新的“思考”格局
到了 2025 年底,OpenAI 不再是唯一的玩家,技術路徑已經分化為三種。

這裏需要潑一盆冷水:Google 的 Gemini 2.5 Flash Thinking 雖然展示了透明的推理過程,但當我讓它數“strawberry”裏有幾個 R 時,它自信滿滿地列出邏輯,最後得出結論——兩個。這説明展示過程不等於結果正確,透明度固然好,但沒有驗證閉環(Verification Loop)依然是徒勞。
在效率方面,DeepSeek-R1 的架構設計值得玩味。雖然它是一個擁有 6710 億參數的龐然大物,但得益於 Mixture-of-Experts (MoE) 技術,每次推理僅激活約 370 億參數。這好比一個存有 600 種工具的巨型車間,工匠幹活時只取當下最順手的 3 件。這種機制讓它的成本比 o1 低了 95% 卻保持了高密度的推理能力。正是這種 MoE 帶來的經濟性,才讓超大模型跑複雜的多步 Test-Time Compute 循環在商業上變得可行。
現成的工程模式:Best-of-N with Verification
搞 Test-Time Compute 不需要千萬美元的訓練預算,甚至不需要 o3 的權重。其核心架構非常簡單,普通開發者完全可以復刻。
核心就三步:
- Divergent Generation(發散生成): 提高 Temperature,讓模型對同一問題生成 N 種不同的推理路徑。
- Self-Verification(自我驗證): 用模型自身(或更強的 Verifier)去批判每一個方案。
- Selection(擇優): 選出置信度最高的答案。
學術界稱之為 Best-of-N with Verification,這與論文 [s1: Simple test-time scaling (arXiv:2501.19393)] 的理論高度吻合。
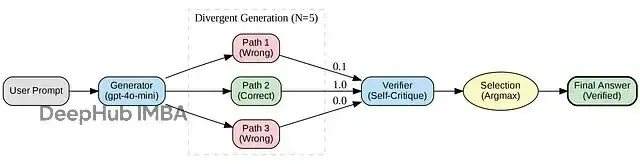
你只需要任何一個主流 LLM API(OpenAI, DeepSeek, Llama 3 均可)、幾分錢的額度和一個簡單的 Python 腳本。
代碼實現如下:
import os
import numpy as np
from typing import List
from pydantic import BaseModel, Field
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define structure for "System 2" thinking
class StepValidation(BaseModel):
is_correct: bool = Field(description="Does the solution logically satisfy ALL constraints?")
confidence_score: float = Field(description="0.0 to 1.0 confidence score")
critique: str = Field(description="Brief analysis of potential logic gaps or missed constraints")
# 2. Divergent Thinking (Generate)
def generate_candidates(prompt: str, n: int = 5) -> List[str]:
"""Generates N distinct solution paths using high temperature."""
candidates = []
print(f"Generating {n} candidate solutions with gpt-4o-mini...")
for _ in range(n):
response = client.chat.completions.create(
model="gpt-4o-mini", # Small, fast generator
messages=[
{"role": "system", "content": "You are a thoughtful problem solver. Show your work step by step."},
{"role": "user", "content": prompt}
],
temperature=0.8 # High temp for diverse reasoning paths
)
candidates.append(response.choices[0].message.content)
return candidates
# 3. Convergent Thinking (Verify)
def verify_candidate(problem: str, candidate: str) -> float:
"""
Uses the SAME small model to critique its own work.
This proves that 'time to think' > 'model size'.
"""
verification_prompt = f"""
You are a strict logic reviewer.
Review the solution below for logical fallacies or missed constraints.
PROBLEM: {problem}
PROPOSED SOLUTION:
{candidate}
Check your work. Does the solution actually fit the constraints?
Rate the confidence from 0.0 (Wrong) to 1.0 (Correct).
"""
response = client.beta.chat.completions.parse(
model="gpt-4o-mini", # Using the small model as a Verifier
messages=[{"role": "user", "content": verification_prompt}],
response_format=StepValidation
)
return response.choices[0].message.parsed.confidence_score
# 4. Main loop
def system2_solve(prompt: str, effort_level: int = 5):
print(f"System 2 Activated: Effort Level {effort_level}")
candidates = generate_candidates(prompt, n=effort_level)
scores = []
for i, cand in enumerate(candidates):
score = verify_candidate(prompt, cand)
scores.append(score)
print(f" Path #{i+1} Confidence: {score:.2f}")
best_index = np.argmax(scores)
print(f"Selected Path #{best_index+1} with confidence {scores[best_index]}")
return candidates[best_index]
# 5. Execute
if __name__ == "__main__":
# The "Cognitive Reflection Test" (Cyberpunk Edition)
# System 1 instinct: 500 credits (WRONG)
# System 2 logic: 250 credits (CORRECT)
problem = """
A corporate server rack and a cooling unit cost 2500 credits in total.
The server rack costs 2000 credits more than the cooling unit.
How much does the cooling unit cost?
"""
answer = system2_solve(problem, effort_level=5) # Increased effort to catch more failures
print("\nFINAL ANSWER:\n", answer)實測案例:“服務器機架”陷阱
我在認知反射測試(Cognitive Reflection Test)的一個變體上跑了這個腳本。這是一種專門設計用來誘導大腦(和 AI)做出快速錯誤判斷的邏輯題。
題目是:“總價 2500,機架比冷卻單元貴 2000,冷卻單元多少錢?”System 1(直覺) 幾乎總是脱口而出 500(因為 2500-2000=500)。System 2(邏輯) 才會算出 250(x + x + 2000 = 2500)。
運行結果非常典型:
System 2 Activated: Effort Level 5
Generating 5 candidate solutions...
Path [#1](#1) Confidence: 0.10 <-- Model fell for the trap (500 credits)
Path [#2](#2) Confidence: 1.00 <-- Model derived the math (250 credits)
Path [#3](#3) Confidence: 0.00 <-- Model fell for the trap
...
Selected Path [#2](#2) with confidence 1.0注意
Path [#1](#1)。在常規應用中,用户直接拿到的就是這個 500 credits(錯誤) 的答案。通過生成 5 條路徑,我們發現 40% 的結果都掉進了陷阱。但關鍵在於,作為驗證者的同一個小模型,成功識別了邏輯漏洞,並將包含正確推導的
Path [#2](#2)撈了出來。
僅僅是“多想一會兒”,一個可靠性 60% 的模型就被強行拉到了 100%。
算力經濟賬
這肯定更貴。但值不值?
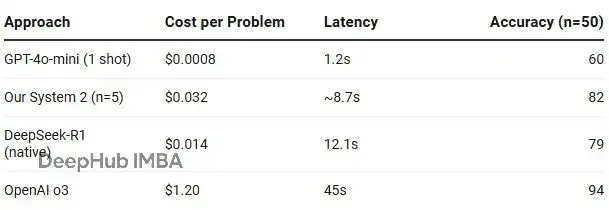
我的實驗成本確實增加了 40 倍,但別忘了絕對值只有 3 美分。這 3 美分換來的是 22% 的準確率提升。如果你在做醫療推理或生產環境 Debug,這簡直是白菜價;如果你只是做個閒聊機器人,那確實是貴了。
新的模型:Inference Budget
展望 2026 年,架構討論的焦點將從“誰的模型更聰明”轉移到“我們的推理預算(Inference Budget)是多少”。
未來的決策可能會變成這樣:
- System 1 (Standard API):延遲要求 < 2秒,或者搞搞創意寫作。
- System 2 (DeepSeek-R1 / o3):準確性至上(數學、代碼、邏輯),且能容忍 10-30 秒的延遲。
- System 3 (Custom Loops):需要形式化保證,必須依賴多 Agent 投票和驗證的關鍵決策。
建議大家把上面的代碼拷下來跑一跑,找一個你現在的 LLM 經常翻車的邏輯題或冷門 Bug 試一下,看着它實時自我修正。
你會發現,我們不該再把 LLM 當作“神諭(Oracle)”,而應將其視為預算可配置的“推理引擎”。懂 Inference-time compute 的數據科學家,才是 2026 年定義下一代 AI 產品的人。
相關閲讀:
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (arXiv:2408.03314).
- s1: Simple test-time scaling (arXiv:2501.19393).
- DeepSeek AI (2025) — DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(arXiv:2501.12948).
https://avoid.overfit.cn/post/a2f09be2577e48b59d2f9f2fc5e6549c
作者:Cagatay Akcam