

Polars 最近新開發了一個可以支持 GPU 加速計算的執行引擎。這個引擎可以對超過 100GB 的數據進行交互式操作能。本文將詳細討論 Polars 中DF的概念、GPU 加速如何與 Polars DF協同工作,以及使用新的 CUDA 驅動執行引擎可能帶來的性能提升。

Polars 核心概念
Polars 的核心功能是創建和操作DF,這些DF可以被視為具有高級功能的電子表格。以下是一個簡單的示例,包含了一些人的姓名、年齡和所在城市信息:
""" 在 Polars 中創建一個簡單的DF
"""
importpolarsaspl
df=pl.DataFrame({
"name": ["Alice", "Bob", "Charlie", "Jill", "William"],
"age": [25, 30, 35, 22, 40],
"city": ["New York", "Los Angeles", "Chicago", "New York", "Chicago"]
})
print(df)輸出結果:
shape: (5, 3)
┌─────────┬─────┬─────────────┐
│ name ┆ age ┆ city │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ str │
╞═════════╪═════╪═════════════╡
│ Alice ┆ 25 ┆ New York │
│ Bob ┆ 30 ┆ Los Angeles │
│ Charlie ┆ 35 ┆ Chicago │
│ Jill ┆ 22 ┆ New York │
│ William ┆ 40 ┆ Chicago │
└─────────┴─────┴─────────────┘使用這個DF,我們可以執行多種操作,例如按年齡篩選:
""" 篩選上述DF,僅顯示年齡超過 28 的行
"""
df_filtered=df.filter(pl.col("age") >28)
print(df_filtered)輸出結果:
shape: (3, 3)
┌─────────┬─────┬─────────────┐
│ name ┆ age ┆ city │
│ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ str │
╞═════════╪═════╪═════════════╡
│ Bob ┆ 30 ┆ Los Angeles │
│ Charlie ┆ 35 ┆ Chicago │
│ William ┆ 40 ┆ Chicago │
└─────────┴─────┴─────────────┘我們還可以進行數學運算:
""" 創建一個名為 "age_doubled" 的新列,其值為 age 列的兩倍
"""
df=df.with_columns([
(pl.col("age") *2).alias("age_doubled")
])
print(df)輸出結果:
shape: (5, 4)
┌─────────┬─────┬─────────────┬─────────────┐
│ name ┆ age ┆ city ┆ age_doubled │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ str ┆ i64 │
╞═════════╪═════╪═════════════╪═════════════╡
│ Alice ┆ 25 ┆ New York ┆ 50 │
│ Bob ┆ 30 ┆ Los Angeles ┆ 60 │
│ Charlie ┆ 35 ┆ Chicago ┆ 70 │
│ Jill ┆ 22 ┆ New York ┆ 44 │
│ William ┆ 40 ┆ Chicago ┆ 80 │
└─────────┴─────┴─────────────┴─────────────┘也可以執行聚合函數,如計算每個城市的平均年齡:
""" 按城市計算平均年齡
"""
df_aggregated=df.group_by("city").agg(pl.col("age").mean())
print(df_aggregated)輸出結果:
shape: (3, 2)
┌─────────────┬──────┐
│ city ┆ age │
│ --- ┆ --- │
│ str ┆ f64 │
╞═════════════╪══════╡
│ Chicago ┆ 37.5 │
│ New York ┆ 23.5 │
│ Los Angeles ┆ 30.0 │
└─────────────┴──────┘對於熟悉 Pandas 的讀者來説,Polars 可能看起來很相似。但是Polars 具有一些獨特的特性,使其在某些情況下更為高效。在深入探討 GPU 加速的 Polars 之前,我們先來了解一下 Polars 的一個關鍵特性:LazyFrames。
Polars LazyFrames
Polars 提供了兩種基本的執行模式:"eager"(急切)和"lazy"(惰性)。Eager DF在調用時立即執行計算,完全按照指定的方式進行。例如,對一個列的每個值加 2,然後再加 3,這些操作會按照你期望的順序立即執行。
讓我們通過一個示例來對比 eager 和 lazy 執行模式:
import polars as pl
# 創建一個包含數字列表的 DataFrame
df = pl.DataFrame({
"numbers": [1, 2, 3, 4, 5]
})
# 對每個數字加 2,並覆蓋原始的 'numbers' 列
df = df.with_columns(
pl.col("numbers") + 2
)
# 對更新後的 'numbers' 列再加 3
df = df.with_columns(
pl.col("numbers") + 3
)
print(df)輸出結果:
shape: (5, 1)
┌─────────┐
│ numbers │
│ --- │
│ i64 │
╞═════════╡
│ 6 │
│ 7 │
│ 8 │
│ 9 │
│ 10 │
└─────────┘現在,讓我們使用
.lazy()函數來初始化一個惰性操作:
import polars as pl
# 創建一個惰性 DataFrame,包含數字列表
df = pl.DataFrame({
"numbers": [1, 2, 3, 4, 5]
}).lazy() # <-------------------------- 惰性初始化
# 對每個數字加 2,並覆蓋原始的 'numbers' 列
df = df.with_columns(
pl.col("numbers") + 2
)
# 對更新後的 'numbers' 列再加 3
df = df.with_columns(
pl.col("numbers") + 3
)
print(df)輸出結果:
naive plan: (run LazyFrame.explain(optimized=True) to see the optimized plan)
WITH_COLUMNS:
[[(col("numbers")) + (3)]]
WITH_COLUMNS:
[[(col("numbers")) + (2)]]
DF ["numbers"]; PROJECT */1 COLUMNS; SELECTION: "None"在這個惰性執行模式下,我們得到的不是一個DF,而是一個類似 SQL 的表達式,它概述了需要執行哪些操作才能得到我們想要的DF。要實際執行這些計算並獲得結果,我們需要調用
.collect()方法:
print(df.collect())輸出結果:
shape: (5, 1)
┌─────────┐
│ numbers │
│ --- │
│ i64 │
╞═════════╡
│ 6 │
│ 7 │
│ 8 │
│ 9 │
│ 10 │
└─────────┘惰性執行的優勢不在於計算髮生的時間,而在於實際執行的計算內容。在執行惰性DF之前,Polars 會分析累積的操作,並尋找可能提高執行效率的優化路徑。這個過程被稱為"查詢優化"。
讓我們通過一個更復雜的例子來説明這一點:
# 創建一個包含多個列的 DataFrame
df = pl.DataFrame({
"col_0": [1, 2, 3, 4, 5],
"col_1": [8, 7, 6, 5, 4],
"col_2": [-1, -2, -3, -4, -5]
}).lazy()
# 執行一些隨機操作
df = df.filter(pl.col("col_0") > 0)
df = df.with_columns((pl.col("col_1") * 2).alias("col_1_double"))
df = df.group_by("col_2").agg(pl.sum("col_1_double"))
print(df)輸出結果:
naive plan: (run LazyFrame.explain(optimized=True) to see the optimized plan)
AGGREGATE
[col("col_1_double").sum()] BY [col("col_2")] FROM
WITH_COLUMNS:
[[(col("col_1")) * (2)].alias("col_1_double")]
FILTER [(col("col_0")) > (0)] FROM
DF ["col_0", "col_1", "col_2"]; PROJECT */3 COLUMNS; SELECTION: "None"現在,讓我們看看優化後的執行計劃:
print(df.explain(optimized=True))輸出結果:
AGGREGATE
[col("col_1_double").sum()] BY [col("col_2")] FROM
WITH_COLUMNS:
[[(col("col_1")) * (2)].alias("col_1_double")]
DF ["col_0", "col_1", "col_2"]; PROJECT */3 COLUMNS; SELECTION: "[(col(\"col_0\")) > (0)]"這個優化後的表達式就是在調用
.collect()方法時實際執行的內容。
為了量化惰性執行帶來的性能提升,我們可以進行一個簡單的性能測試,比較 eager 和 lazy 執行模式的速度差異:
import polars as pl
import numpy as np
import time
# 設定常量
num_rows = 20_000_000 # 2千萬行
num_cols = 10 # 10列
n = 10 # 測試重複次數
# 生成隨機數據
np.random.seed(0) # 設置隨機種子以確保可重複性
data = {f"col_{i}": np.random.randn(num_rows) for i in range(num_cols)}
# 定義一個適用於 lazy 和 eager DataFrame 的函數
def apply_transformations(df):
df = df.filter(pl.col("col_0") > 0) # 篩選 col_0 大於 0 的行
df = df.with_columns((pl.col("col_1") * 2).alias("col_1_double")) # 將 col_1 乘以 2
df = df.group_by("col_2").agg(pl.sum("col_1_double")) # 按 col_2 分組並聚合
return df
# 存儲 eager 和 lazy 執行的總持續時間的變量
total_eager_duration = 0
total_lazy_duration = 0
# 執行 n 次測試
for i in range(n):
print(f"運行 {i+1}/{n}")
# 為每次運行創建新的 DataFrame(polars 操作可能是原地的,所以確保 DF 是乾淨的)
df1 = pl.DataFrame(data)
df2 = pl.DataFrame(data).lazy()
# 測量 eager 執行時間
start_time_eager = time.time()
eager_result = apply_transformations(df1) # Eager 執行
eager_duration = time.time() - start_time_eager
total_eager_duration += eager_duration
print(f"Eager 執行時間: {eager_duration:.2f} 秒")
# 測量 lazy 執行時間
start_time_lazy = time.time()
lazy_result = apply_transformations(df2).collect() # Lazy 執行
lazy_duration = time.time() - start_time_lazy
total_lazy_duration += lazy_duration
print(f"Lazy 執行時間: {lazy_duration:.2f} 秒")
# 計算平均執行時間
average_eager_duration = total_eager_duration / n
average_lazy_duration = total_lazy_duration / n
# 計算 lazy 執行比 eager 執行快多少
faster = (average_eager_duration-average_lazy_duration)/average_eager_duration*100
print(f"\n{n} 次運行的平均 Eager 執行時間: {average_eager_duration:.2f} 秒")
print(f"{n} 次運行的平均 Lazy 執行時間: {average_lazy_duration:.2f} 秒")
print(f"Lazy 執行節省了 {faster:.2f}% 的時間")輸出結果:
運行 1/10
Eager 執行時間: 3.07 秒
Lazy 執行時間: 2.70 秒
運行 2/10
Eager 執行時間: 4.17 秒
Lazy 執行時間: 2.69 秒
運行 3/10
Eager 執行時間: 2.97 秒
Lazy 執行時間: 2.76 秒
運行 4/10
Eager 執行時間: 4.21 秒
Lazy 執行時間: 2.74 秒
運行 5/10
Eager 執行時間: 2.97 秒
Lazy 執行時間: 2.77 秒
運行 6/10
Eager 執行時間: 4.12 秒
Lazy 執行時間: 2.80 秒
運行 7/10
Eager 執行時間: 3.00 秒
Lazy 執行時間: 2.72 秒
運行 8/10
Eager 執行時間: 4.53 秒
Lazy 執行時間: 2.76 秒
運行 9/10
Eager 執行時間: 3.14 秒
Lazy 執行時間: 3.08 秒
運行 10/10
Eager 執行時間: 4.26 秒
Lazy 執行時間: 2.77 秒
10 次運行的平均 Eager 執行時間: 3.64 秒
10 次運行的平均 Lazy 執行時間: 2.78 秒
Lazy 執行節省了 23.75% 的時間這個 23.75% 的性能提升是相當可觀的,這種提升是通過惰性執行實現的,而這在 Pandas 中是不存在的。在底層當使用 Polars 惰性DF時,實際上是在定義一個高級計算圖,Polars 會對其進行各種優化處理。在優化查詢之後再執行,這意味着你會得到與 eager DF相同的結果,但通常速度更快。
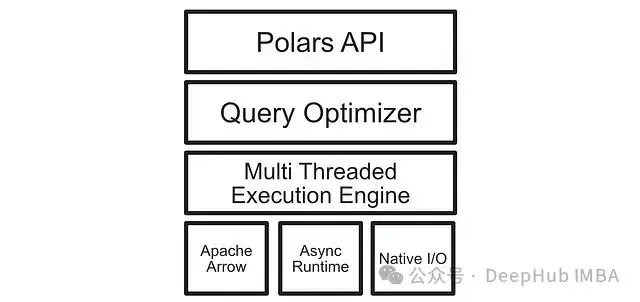
上圖是 Polars 中調用查詢後觸發的操作的高級概述。eager 執行本身就有許多優化改進,如原生多核支持,這在惰性執行中也存在並得到了進一步改進。
儘管 Lazy 執行模式帶來了顯著的性能提升,但對於一些用户來説,這種提升可能還不足以促使他們改變長期使用的工具。接下來我們將介紹的 GPU 加速功能可能會徹底改變這種看法。
GPU 加速 Polars
GPU 加速功能是 Polars 最新引入的特性。在撰寫本文時,這項功能剛剛發佈。要在環境中啓用 GPU 加速,可以使用以下命令安裝支持 GPU 的 Polars:
pip install polars[gpu] --extra-index-url=https://pypi.nvidia.com如果上述命令不起作用,建議查看 Polars 的 PyPI 頁面以獲取最新的安裝説明。
啓用 GPU 加速後,只需在調用
collect()方法時指定 GPU 作為執行引擎即可使用 GPU 加速功能。具體實現如下:
gpu_engine = pl.GPUEngine(
device=0, # 默認設置
raise_on_fail=True, # 如果無法在 GPU 上運行,則拋出異常
)
results = df.collect(engine=gpu_engine)但是GPU 執行引擎並不支持所有的 Polars 功能。如果遇到不支持的操作,默認情況下會回退到 CPU 執行。通過設置
raise_on_fail=True,我們可以在不支持 GPU 執行時得到明確的錯誤提示。
為了量化 GPU 加速帶來的性能提升,我們可以進行一個更全面的性能測試,比較 eager 執行、CPU 上的 lazy 執行和 GPU 上的 lazy 執行:
import polars as pl
import numpy as np
import time
# 創建大型隨機 DataFrame
num_rows = 20_000_000 # 2千萬行
num_cols = 10 # 10列
n = 10 # 測試重複次數
# 生成隨機數據
np.random.seed(0) # 設置隨機種子以確保可重複性
data = {f"col_{i}": np.random.randn(num_rows) for i in range(num_cols)}
# 定義適用於 lazy 和 eager DataFrame 的函數
def apply_transformations(df):
df = df.filter(pl.col("col_0") > 0) # 篩選 col_0 大於 0 的行
df = df.with_columns((pl.col("col_1") * 2).alias("col_1_double")) # 將 col_1 乘以 2
df = df.group_by("col_2").agg(pl.sum("col_1_double")) # 按 col_2 分組並聚合
return df
# 存儲執行時間的變量
total_eager_duration = 0
total_lazy_duration = 0
total_lazy_GPU_duration = 0
# 執行 n 次測試
for i in range(n):
print(f"運行 {i+1}/{n}")
# 為每次運行創建新的 DataFrame
df1 = pl.DataFrame(data)
df2 = pl.DataFrame(data).lazy()
df3 = pl.DataFrame(data).lazy()
# 測量 eager 執行時間
start_time_eager = time.time()
eager_result = apply_transformations(df1) # Eager 執行
eager_duration = time.time() - start_time_eager
total_eager_duration += eager_duration
print(f"Eager 執行時間: {eager_duration:.2f} 秒")
# 測量 CPU lazy 執行時間
start_time_lazy = time.time()
lazy_result = apply_transformations(df2).collect() # CPU Lazy 執行
lazy_duration = time.time() - start_time_lazy
total_lazy_duration += lazy_duration
print(f"CPU Lazy 執行時間: {lazy_duration:.2f} 秒")
# 定義 GPU 引擎
gpu_engine = pl.GPUEngine(
device=0, # 默認設置
raise_on_fail=True, # 如果無法在 GPU 上運行,則拋出異常
)
# 測量 GPU lazy 執行時間
start_time_lazy_GPU = time.time()
lazy_result = apply_transformations(df3).collect(engine=gpu_engine) # GPU Lazy 執行
lazy_GPU_duration = time.time() - start_time_lazy_GPU
total_lazy_GPU_duration += lazy_GPU_duration
print(f"GPU Lazy 執行時間: {lazy_GPU_duration:.2f} 秒")
# 計算平均執行時間
average_eager_duration = total_eager_duration / n
average_lazy_duration = total_lazy_duration / n
average_lazy_GPU_duration = total_lazy_GPU_duration / n
# 計算性能提升
faster_1 = (average_eager_duration-average_lazy_duration)/average_eager_duration*100
faster_2 = (average_lazy_duration-average_lazy_GPU_duration)/average_lazy_duration*100
faster_3 = (average_eager_duration-average_lazy_GPU_duration)/average_eager_duration*100
print(f"\n{n} 次運行的平均 Eager 執行時間: {average_eager_duration:.2f} 秒")
print(f"{n} 次運行的平均 CPU Lazy 執行時間: {average_lazy_duration:.2f} 秒")
print(f"{n} 次運行的平均 GPU Lazy 執行時間: {average_lazy_GPU_duration:.2f} 秒")
print(f"CPU Lazy 比 Eager 快 {faster_1:.2f}%")
print(f"GPU 比 CPU Lazy 快 {faster_2:.2f}%,比 Eager 快 {faster_3:.2f}%")輸出結果:
運行 1/10
Eager 執行時間: 0.74 秒
CPU Lazy 執行時間: 0.66 秒
GPU Lazy 執行時間: 0.17 秒
運行 2/10
Eager 執行時間: 0.72 秒
CPU Lazy 執行時間: 0.65 秒
GPU Lazy 執行時間: 0.17 秒
運行 3/10
Eager 執行時間: 0.82 秒
CPU Lazy 執行時間: 0.76 秒
GPU Lazy 執行時間: 0.17 秒
運行 4/10
Eager 執行時間: 0.81 秒
CPU Lazy 執行時間: 0.69 秒
GPU Lazy 執行時間: 0.18 秒
運行 5/10
Eager 執行時間: 0.79 秒
CPU Lazy 執行時間: 0.66 秒
GPU Lazy 執行時間: 0.18 秒
運行 6/10
Eager 執行時間: 0.75 秒
CPU Lazy 執行時間: 0.63 秒
GPU Lazy 執行時間: 0.18 秒
運行 7/10
Eager 執行時間: 0.77 秒
CPU Lazy 執行時間: 0.72 秒
GPU Lazy 執行時間: 0.18 秒
運行 8/10
Eager 執行時間: 0.77 秒
CPU Lazy 執行時間: 0.72 秒
GPU Lazy 執行時間: 0.17 秒
運行 9/10
Eager 執行時間: 0.77 秒
CPU Lazy 執行時間: 0.72 秒
GPU Lazy 執行時間: 0.17 秒
運行 10/10
Eager 執行時間: 0.77 秒
CPU Lazy 執行時間: 0.70 秒
GPU Lazy 執行時間: 0.17 秒
10 次運行的平均 Eager 執行時間: 0.77 秒
10 次運行的平均 CPU Lazy 執行時間: 0.69 秒
10 次運行的平均 GPU Lazy 執行時間: 0.17 秒
CPU Lazy 比 Eager 快 10.30%
GPU 比 CPU Lazy 快 74.78%,比 Eager 快 77.38%這些結果顯示,GPU 加速帶來了顯著的性能提升。GPU 執行比 CPU 上的 lazy 執行快了 74.78%,比 eager 執行快了 77.38%。這還不是一個特別大的數據集。對於更大的數據集,我們可能會看到更顯著的性能提升。
GPU 加速的工作原理
Polars 的 GPU 加速功能是通過添加一個新的 GPU 執行引擎實現的。這個新引擎與現有的執行引擎並存,Polars 可以根據可用的硬件和正在執行的查詢類型動態選擇最適合的引擎。
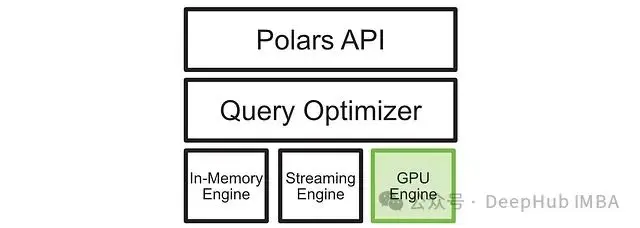
如上圖所示,在輸入查詢後,查詢優化器會優化查詢,並將操作發送到最合適的執行引擎。新增的 GPU 執行引擎為高度可並行化的操作提供了顯著的性能提升。
一些查詢在 GPU 上表現極佳,而其他查詢可能仍然在 CPU 上使用內存引擎完成。這種靈活的設計使得 CUDA 加速的 Polars 在大多數情況下都能提供更快的執行速度,特別是在處理大型數據集時。
抽象的內存管理
Nvidia 和 Polars 團隊在設計新的查詢優化器時,特別關注了 CPU 和 GPU 之間的內存管理問題。對於不熟悉 GPU 編程的讀者來説,需要了解 CPU 和 GPU 使用不同的內存系統:CPU 使用主機內存(RAM),而 GPU 使用設備內存(VRAM)。
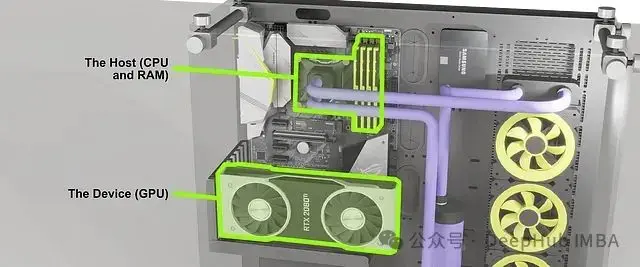
如上圖所示,CPU 和 GPU 可以看作是兩個獨立的計算單元,各自擁有自己的資源,並通過特定的接口進行通信。CPU 進行通用計算並使用 RAM 存儲數據,而 GPU 專門進行並行計算,使用顯卡上的 VRAM 存儲數據。在複雜的數據處理任務中,這兩個系統需要協同工作。
Polars 的查詢優化器能夠智能地處理 CPU 和 GPU 之間的數據傳輸。例如當一個在 GPU 上創建和執行的DF需要與仍在 CPU 上的另一個DF交互時,查詢優化器可以自動處理必要的數據傳輸。
這種抽象的內存管理為用户提供了極大的便利,使得在 GPU 上進行數據處理變得簡單直接。然而對於一些特定的工作流程,如同時進行大規模數據操作和模型訓練的場景,這種自動化的內存管理可能會帶來一些挑戰。在這些情況下可能需要更精細的內存控制。
Nvidia 和 Polars 團隊正在研究顯式內存控制功能,這可能會在未來的版本中推出。對於純數據處理工作負載,當前的自動內存管理機制已經能夠為大多數數據科學家和工程師節省大量時間。
總結
GPU 加速 Polars 的引入為數據處理領域帶來了令人興奮的新可能性。這項技術不僅提供了顯著的性能提升,還保持了 Polars 易用和靈活的特性。
儘管對於一些簡單的數據處理任務,傳統工具如 Pandas 可能仍然足夠,但在面對大型數據集和複雜查詢時,GPU 加速的 Polars 顯示出了巨大的優勢。其提供的性能提升可能會影響許多數據科學家和工程師的工作流程,使得previously耗時的操作變得更加高效。
隨着這項技術的進一步發展和完善,我們可以期待看到更多創新的數據處理應用場景。對於那些經常處理大規模數據的專業人士來説,密切關注 Polars 和 GPU 加速數據處理技術的發展將是十分有益的。
https://avoid.overfit.cn/post/b9974462d508445d821aef4f471793fe