

用過聊天機器人的人都遇到過這種情況:你剛説喜歡科幻小説,幾輪對話後它給你推薦言情小説。你告訴聊天機器人升職了,但是過會兒又他又問你職業。這種情況不只是健忘而是根本性的bug——AI不僅會丟上下文,還會憑空編造、記錯、甚至生成自相矛盾的內容。
這就是記憶幻覺(memory hallucination)。相比那些編造世界知識的"生成幻覺",記憶幻覺是更上游的問題。一旦AI的記憶庫被污染,後續所有的推理、建議、回覆都建立在錯誤基礎上。如果記憶本身不可靠,哪何談可信的AI呢?
ArXiv最近一篇名為"HaluMem: Evaluating Hallucinations in Memory Systems of Agents"的論文提供了一個非常最新可靠的診斷工具。
AI記憶系統的工作原理與失效模式
現代AI系統依賴記憶系統(memory system)來實現持久化的長期記憶。這不是模型訓練參數中的"隱式記憶",而是外部組件。打個比方:LLM的訓練數據是它的"書本知識",靜態的世界知識庫;記憶系統則是它的"個人日記",記錄與特定用户的獨特交互。
Mem0、Memobase、Supermemory這類系統負責管理這份"日記",執行幾個核心操作:
提取(Extract):從對話中抽取關鍵信息,比如"用户升職為高級研究員"、"用户不喜歡鸚鵡"。
存儲(Store):將這些事實保存為結構化的"記憶點",通常帶時間戳等元數據。
更新(Update):遇到矛盾信息時更新舊記憶,比如"健康狀況從良好變為較差"。
檢索(Retrieve):回答問題時從日記中找出相關記憶來輔助LLM生成答案。
理想情況下確實很神奇——AI記得你女兒叫什麼、職業目標是啥、對花生過敏。但一旦出錯,就會產生各種記憶幻覺:
捏造(Fabrication):憑空編造從未發生的記憶。用户明明説現在喜歡鸚鵡了,系統卻記成"不喜歡鸚鵡"。
錯誤(Error):提取了記憶但關鍵細節錯了。你説朋友叫Joseph,它記成Mark。
衝突(Conflict):沒更新舊記憶,知識庫裏同時存在"健康良好"和"健康較差"兩條矛盾記錄。
遺漏(Omission):壓根沒提取關鍵信息,直接失憶。
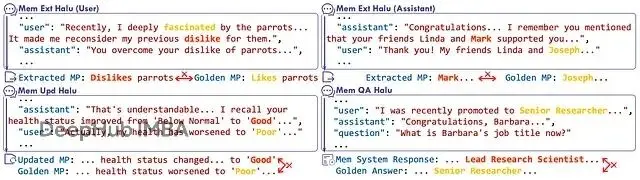
記憶系統中操作級幻覺的示例,展示了記憶提取、更新和問答幻覺的具體例子。
這些不是小問題。單個提取錯誤會引發錯誤更新,進而導致問答環節的幻覺回答。隨着時間推移問題會累積惡化,把AI的"個人日記"變成超現實主義小説。
端到端評估的侷限性
傳統的端到端評估(end-to-end evaluation)是黑盒測試——跟AI長時間對話,最後問個問題,看答案對不對。知道系統掛了,但不知道哪裏掛的、為什麼掛,所以沒法有效測量這個問題。
PersonaMem、LOCOMO、LongMemEval這些基準都是端到端方法。它們能測最終輸出,但給不出診斷細節,無法定位幻覺到底產生在記憶提取、更新還是答案生成階段。
HaluMem要填的就是這個空白——不只要成績單,還要診斷報告。得打開黑盒檢查整條記憶完整流程。
HaluMem的核心創新:操作級評估
HaluMem從端到端評估轉向操作級評估(operation-level evaluation)。不只看最終答案,而是把記憶過程拆成三個最容易出幻覺的關鍵階段,分別獨立評估:
記憶提取評估:給定對話,系統提取的記憶點集合是否正確?
記憶更新評估:需要修改記憶時,系統執行得對不對,有沒有錯誤或遺漏?
記憶問答評估:傳統的端到端任務,現在被看作所有上游錯誤彙總的最終環節。

HaluMem在每個環節都設了質檢點:
提取:對比系統選擇提取的組件(
ʆMext)和應該提取的清單(
Gext)。用記憶召回率(Memory Recall,拿齊了嗎)、記憶準確性(Memory Accuracy,有瑕疵嗎)、虛假記憶抵抗力(False Memory Resistance,識別假貨了嗎)來衡量。
更新:檢查系統有沒有正確用新組件替換舊的。對比更新日誌(
ʆGupd)和真實更新指令(
Gext)。測量記憶更新準確性、幻覺率、遺漏率。
問答:現在如果有問題,那就追溯到源頭——是原料就有問題,還是裝配出錯?
要實現這種細粒度評估,得先有支持這種評估的數據集。不能隨便抓網上的聊天記錄,需要大規模、連貫的長期對話,而且每個記憶點和更新都有已知的"ground truth"。
所以研究團隊就自己造了一個。
HaluMem數據集
HaluMem基準揹包含兩個新數據集——
HaluMem-Medium和
HaluMem-Long。它通過六階段流程生成高度真實的合成人機交互數據。
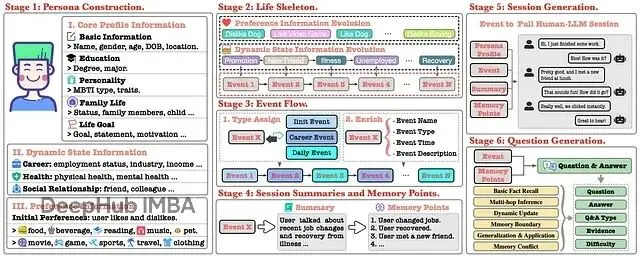
階段1:人物構建(Persona Construction):創建詳細的虛擬用户檔案,不止姓名年齡,還包括MBTI性格、家庭、教育背景、人生目標。每個角色都是複雜個體。
階段2:生活骨架(Life Skeleton):為每個人物編寫完整生活軌跡,定義職業大事件、健康變化、社交關係演變,形成連貫的敍事線。
階段3:事件流(Event Flow):把抽象骨架具體化成按時間順序的事件流。晉升變成一系列子事件;偏好改變(比如養狗後開始喜歡狗)變成具體日常事件。相當於給用户生活建了完整的"記憶交易日誌"。
階段4:會話摘要與記憶點(Session Summaries and Memory Points):每個事件生成摘要和ground truth的記憶點。這些是完美記憶系統該提取和更新的原子級事實。工作變動事件會產生"用户升職"、"用户薪資增加"這類記憶點。
階段5:會話生成(Session Generation):生成用户和AI之間真實的多輪對話,用户自然地聊生活中的事。關鍵是加入了對抗性內容注入——AI有時會提到虛假但相似的記憶作為干擾項,測試系統能不能忽略未確認信息。
階段6:問題生成(Question Generation):生成數千個測試題,不是簡單的事實查詢。涵蓋六個類別,從基礎事實回憶到複雜的多跳推理、動態更新跟蹤、甚至故意包含錯誤前提的記憶衝突問題,看AI能否糾正。
數據集規模達到了數萬輪對話。
HaluMem-Long單個用户的上下文能超過一百萬token。為保證質量,相當大一部分數據經過人工標註驗證,正確性一致度達95.7%。
有了這個數據集,HaluMem的細粒度診斷才成為可能,能對記憶系統的每個操作給出評判標準。
測試結果:當前記憶系統的全面失敗
研究團隊評估了幾個SOTA記憶系統,包括Mem0(及其圖變體)、Memobase、Supermemory。評估完全自動化,用GPT-4o配合詳細提示給各系統在提取、更新、問答階段打分。
論文表格里的數據相當震撼,揭示了全面的系統性故障。記憶幻覺不是偶發bug,而是當前架構的普遍缺陷。
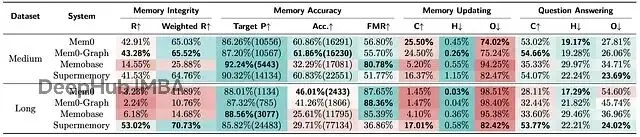
所有記憶系統在HaluMem上的評估結果。"R"表示召回率,"Target P"表示目標記憶精度,"Acc."表示準確性,"FMR"表示虛假記憶抵抗力,"C"表示正確率(準確性),"H"表示幻覺率,"O"表示遺漏率。"Target P"和"Acc."列中括號內的值表示提取的記憶數量。顏色刻度反映性能(紅色=較差,綠色=較好);最佳值以粗體顯示。
提取階段:源頭就出問題
記憶提取這第一步就有問題
嚴重失憶:記憶召回率(R)指標很不好了。
HaluMem-Medium數據集上,最好的系統Mem0和Mem0-Graph也只捕獲了約43%該提取的記憶。超過一半的重要信息直接被忽略或遺漏。Memobase更慘,召回率才14.5%。
猖獗幻覺:記憶準確性(Acc.)更離譜。這測的是系統實際提取的記憶裏有多少是對的。沒有系統超過62%。意味着系統費勁保存的記憶,一大堆是編的、錯的或不相關的。Supermemory提取了超過22,000條記憶,準確率只有60.8%,幾千條都是垃圾。
長上下文崩潰:
HaluMem-Long引入長的無關對話模擬現實噪音,情況急劇惡化。Mem0召回率從43%暴跌到災難性的3.2%,從噪音中找信號的能力完全崩了。只有Supermemory維持住了,但代價是提取了海量記憶(超過77,000條),導致準確率最低(29.7%)、虛假記憶抵抗力極差。
當前系統在最基礎的記憶功能上表現糟糕。既健忘(低召回)又妄想(低準確)。可以看到錯誤從源頭就開始了。
更新階段:也有很多缺失
連提取都做不好,更新就更不用説了。記憶更新任務評估系統遇到新的矛盾信息(比如升職後改職位)能否正確修改現有記憶。
結果是最差的。
記憶更新的正確率(C)低到離譜。
HaluMem-Medium上,最好的Mem0也只在25.5%的情況下正確執行了更新。
遺漏率(O)超高,多數系統在74%以上的時候壓根沒執行該做的更新。
論文指出一個關鍵原因:原始記憶都沒提取,哪來的更新?這是典型的級聯錯誤。提取階段的失敗直接造成更新階段的災難。
這也暴露了當前架構的根本問題——提取和更新環節沒有可靠的關聯機制。系統找不到、改不了特定記憶,導致記憶庫裏全是過時和矛盾的信息。
問答階段:最終崩盤
記憶庫本身就不完整、充斥幻覺、信息過時,最終問答在預料之中,上游的糟糕表現直接傳導到輸出。
問答正確率(C)在中等數據集上全都低於55%,長上下文版本更差。幻覺率(H)和遺漏率(O)相應很高。
比如
HaluMem-Long上Mem0的問答遺漏率54.6%,主要因為一開始就沒提取到回答問題需要的記憶。
按問題類型分解的性能分析很有意思。
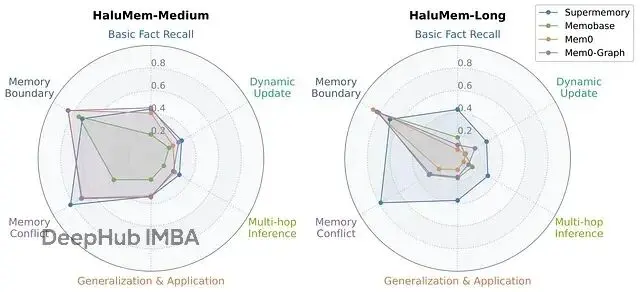
所有系統在記憶邊界和記憶衝突問題上表現還行,説明它們在識別"不知道"或問題包含錯誤前提時還可以,這對安全性是好事。
但需要深度理解的問題上表現很差——多跳推理、動態更新、泛化應用。這表明當前系統在複雜推理和隨時間追蹤用户偏好方面有嚴重短板,而這恰恰是真正智能助手的核心能力。
可信AI記憶的技術路徑
HaluMem首次為黑盒內部提供了高分辨率視圖,從"壞了"進化到"具體在哪壞了"。
這個診斷是可以説是治療的第一步。論文指出方向:"未來研究應該專注於開發可解釋和受約束的記憶操作機制,系統性地抑制幻覺、提升記憶可靠性"。
具體來説:
可解釋機制:得能看到系統為啥決定提取或更新某個記憶。過程不能是黑盒套黑盒。需要清晰的日誌和操作理由。
受約束機制:記憶的形成和修改需要規則。也許記憶只能在用户明確確認時創建;也許更新需要"diff"檢查,系統必須明確標識改了什麼、為什麼改,而不是直接加條矛盾的新事實。
解耦與專業化:結果顯示單一整體式方法在失敗。可能需要為每個操作配備專門的模型或模塊。優化高召回、高準確提取的模型,跟優化邏輯更新一致性的模型,應該是不同的。
HaluMem提供了測試這些新想法的框架。開發者現在能設計新的提取算法,跑HaluMem基準,直接看記憶召回率和準確性有沒有提升,不用跑完整的昂貴端到端評估。可以迭代更新邏輯,直接測量對更新遺漏率的影響。
總結
"HaluMem"論文是一個基礎性工作,提供了看待問題的新視角。給出了詞彙表、方法論和工具,讓記憶幻覺問題變得可以系統性處理。
通過這個方法的初步診斷,當今最先進代理的記憶系統是脆弱的、健忘的、容易編造的。完美可靠的AI伴侶夢想還很遙遠。雖然路還很長,但至少知道從哪開始了。
論文
https://avoid.overfit.cn/post/1498f9f3e067465bac33344d124128a1
