

今年開始LLM驅動的Agentic AI發展速度非常驚人。而我們現在面臨一個實際問題:到底是上全自主的AI智能體,還是讓人類繼續參與決策?從大量實際案例來看Agent-Assist(也就是Human-in-the-Loop系統)既能帶來自動化的效率提升,又能有效規避那些可能造成重大損失的錯誤。
而且如果系統設計得當的化,還可以從人類每次糾正中學習,持續積累組織自己的專業知識庫。
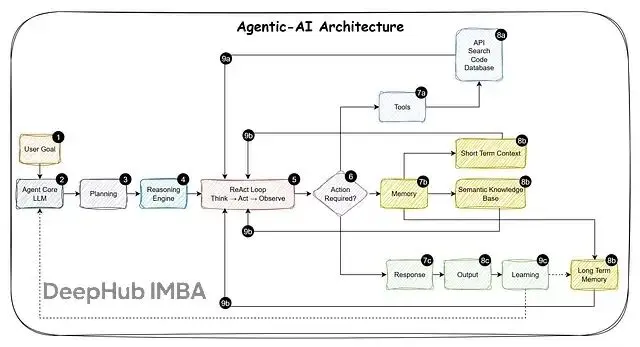
概念回顧
Human-in-the-Loop (HITL):這個概念範圍比較廣,一般指的是人類參與AI決策流程,負責審查、糾正或引導AI的輸出。在機器學習訓練、內容審核、模型優化這些場景裏很常見。
Agent-Assist:這是HITL的一種具體應用形式,專注於實時操作支持。AI負責起草郵件、總結通話內容、提供背景信息或者寫代碼,但最終決策和執行還是由人來完成。
Agent-Assist是HITL原則在實際業務場景中的落地:
兩者核心思路一致——人類保留決策權而AI充當輔助角色。這兩個的主要區別在於,Agent-Assist更強調實時的生產力提升(幫知識工作者提高效率),而HITL是個更宏觀的框架,還包含了訓練、質控、系統改進等流程。所以一般討論Agent-Assist時,通常説的就是那些專門為提升知識工作者生產力而優化的HITL系統。
2025年Agentic AI大爆發
ChatGPT剛出來的時候,大家覺得它能寫郵件、解釋概念已經很厲害了。而現在的AI智能體能做的事情完全不是一個量級:
Lindy和Operator可以自動幫你約會議,讀你的日曆和郵件就行;Cursor、Claude Code、Devin、GitHub Copilot Workspace這些工具能自主寫代碼並部署;Sierra和Ada CX可以端到端處理客户支持;Bloomberg GPT智能體在執行復雜金融交易;Honeycomb的AI操作員在大規模管理雲基礎設施。
Agentic AI系統能獨立規劃任務、執行多步驟操作、調用各種工具,並根據結果動態調整策略,遠不止聊天機器人那麼簡單。核心能力包括:LLM推理、工具使用(API、數據庫、代碼執行)、記憶系統、決策循環。
所以問題就來了這些智能體該完全自主運行,還是應該保持人類在關鍵決策環節?
兩種方案的實際對比
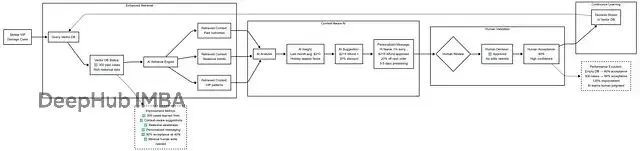
場景:客户退款請求
方案1:完全自動化
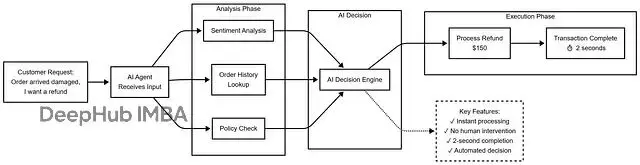
方案2:Agent-Assist (Human-in-the-Loop)

對比結果:
自主版本處理快,但錯失了維護VIP客户的戰略機會。Agent-Assist版本雖然慢一點點,但AI這次學到了要區別對待VIP客户下回會建議更合適的方案。
核心優勢:持續學習能力
Agent-Assist能創建一個持續學習循環,而且不需要昂貴的模型重訓。
RAG(Retrieval-Augmented Generation)
不用微調或重訓LLM,直接用RAG配合向量數據庫來建立組織記憶。
每個人類決策都存進向量數據庫(Pinecone、Weaviate、Qdrant、PgVector、Milvus等等),記錄包括:上下文(客户類型、具體情況)、AI原始建議、人類最終決策、修改理由、執行結果。
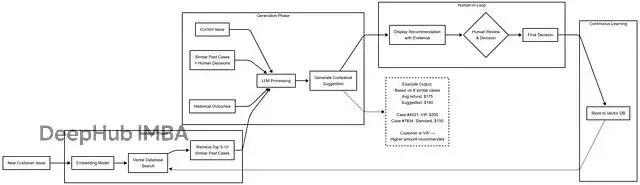
學習曲線(假設場景)
第1個月:AI建議,人類批准或編輯60%的內容。系統開始收集真實決策數據,學到"客户説X時,人類傾向選擇Y"、"VIP客户待遇不同"、"時機有講究(比如假期會更慷慨)"。
第6個月:接受率升至80%。向量庫已經有幾千條人類決策記錄了。每個新案例AI會檢索5-10個最相似的歷史決策。AI看到"8/10的類似案例裏,人類都選了Z方案",然後根據這些組織知識調整建議。人類編輯的時間少多了,因為AI有了上下文記憶。
第12個月:接受率到90%。向量庫存了3萬多條決策,這就是全面的組織記憶了。AI同時檢索短期模式和長期經驗,初級員工通過RAG能獲取到資深專家的決策智慧。系統改進靠的是知識庫擴充,不是模型重訓。
實際效果對比
第1周:空白狀態
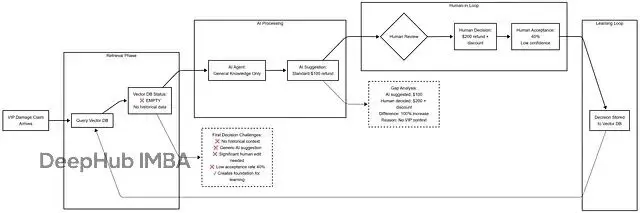
第12周:豐富記憶
這些進步來自向量數據庫的擴充,跟重訓LLM沒關係。
RAG為什麼比微調更適合Agent-Assist
不需要搞複雜的重訓流程,往向量庫加數據就行;新決策實時可用,立即生效;完全透明能看到哪些歷史案例影響了當前建議;隨時編輯、刪除壞例子或更新策略都很方便;成本低不用GPU集羣也不用重訓算力;可解釋性強能説清"基於這5個類似案例...";多模態記憶,決策、結果、上下文、用户反饋都存;還能做版本控制,跟蹤組織知識怎麼演化的。
而工程複雜(訓練管道、GPU基礎設施)、費用高、迭代慢(更新要好幾天甚至幾周)、有災難性遺忘風險(新訓練覆蓋舊知識)、黑盒操作(不知道具體改了啥)、需要ML/DL專業技能。
系統如何從人類反饋中學習
人類每次跟AI建議互動,系統都會捕獲這個決策存檔。不同類型的反饋教會AI不同的東西:
1、直接批准:"這次對了"
人類不做任何修改就批准AI建議時,系統記為成功模式。
比如AI建議對損壞商品退款150美元,人類點了批准,系統就知道這個因素組合(損壞類型、客户等級、訂單金額)適合150美元退款。
學到的經驗:"這個模式有效,類似情況繼續用"。
2、編輯修改:"方向對了,但具體操作要這樣"(價值最高)
人類修改AI建議時,其實是在傳授任何訓練數據裏都沒有的公司特定知識。
例子:
AI建議:"尊敬的客户,您的退款已處理。"
人類改成:"嗨Victor,很抱歉你收到的訂單有損壞。我已經處理了200美元退款,另外給你下次購買提供20%折扣。退款會在3-5個工作日到賬,感謝你的耐心。"
AI學到:VIP客户要稱呼名字、表達真誠歉意、説明時間線、附加補償措施。下次類似情況AI會自動建議這種個性化處理。
這是最有價值的信號,因為它捕獲了沒法手動編程的專家經驗。
3、完全拒絕:"這不是正確處理方式"
人類拒絕AI建議並選擇完全不同的方案時,説明AI對情況的理解根本就錯了。比如AI按標準政策建議退50美元,人類拒絕後批准200美元加折扣碼,因為識別出這是個有流失風險的高價值VIP客户。
AI學到:"這類客户檔案 + 這類情況 = 需要高級處理,不能套標準政策"。以後遇到VIP損壞問題,初始建議額度就會更高。
4、結果追蹤:"決策效果如何"
系統能跟蹤決策後續,客户滿意嗎?有沒有復購?問題解決了嗎?
例如那個200美元退款決策,兩週後的數據 客户滿意度9.5/10、續訂了年度訂閲、又買了2000美元的東西、狀態:成功保留。
AI學到:"對VIP客户的慷慨策略能創造長期價值,繼續推薦這個方向"。時間長了,AI會建立起基於實際結果的理解,知道哪些方法真正有效,而不只是看起來不錯。
什麼情況適合完全自動化
説了很多不適合自動化的場景,我們再説説有些場景確實適合完全自主。
高頻低風險操作
垃圾郵件過濾(Gmail每天處理數十億封,出錯可以容忍)、內容推薦(Netflix、Spotify)、廣告競價(毫秒級決策、易回退)、日誌聚合和基礎監控。
邊界清晰的窄領域
雲基礎設施自動擴容(規則明確、可逆)、基礎客服FAQ(事實性問答、低風險)、數據驗證格式化、常規代碼檢查和格式化。
速度是硬性要求
欺詐檢測(毫秒內必須攔截)、DDoS防禦(等不了人工批准)、高頻交易(雖然要有嚴格護欄)。
決策框架
什麼時候該用Agent-Assist?
滿足以下任一條件就該用:錯誤成本超過1000美元(看具體組織風險承受度)、影響客户資金/隱私/安全、有行業監管要求(金融/醫療/法律)、涉及模糊性或強上下文依賴、需要持續學習改進、經常遇到新情況、人類有值得保留的專業經驗、錯誤難以回退。
什麼時候考慮完全自動化?
必須同時滿足所有條件:高頻(每小時1000+決策)、低風險(單次錯誤成本<100美元)、易回退、規則明確、無人工審核的監管要求、完成充分測試(影子模式>90天)、監控告警到位、驗證過回滾機制。
建議:就算完全自動化看起來沒問題,也最好先從Agent-Assist開始,收集訓練數據並建立信心。
總結
LLM和Agentic AI能力在爆炸式增長,完全自動化的誘惑確實很大。但真正能贏的公司,是那些懂得增強人類智能而非取代人類的公司,構建的系統能從團隊每天的決策中不斷變聰明。
Agent-Assist不是要減慢創新速度,恰恰相反它是為了構建這樣的AI系統:學習組織的獨特專業知識、在錯誤造成損失前就攔截、自然符合監管要求、無需昂貴重訓就能持續改進、讓核心人才專注高價值工作。
聰明的自動化策略是讓AI處理速度和規模,人類貢獻判斷和適應能力。工作的未來不是人類對抗AI,而是人類與AI協作。
https://avoid.overfit.cn/post/a1f74d75739b4bef930e92517cf497a3
