

過去這些年語言模型的效率優化基本圍繞着兩條主線展開:參數規模和注意力機制的複雜度。但有個更根本的問題一直被忽視,那就是自迴歸生成本身的代價。這種逐token生成的模式讓模型具備了強大的通用性,同時也帶來了難以迴避的計算開銷。
現在有一種思路值得關注:不去替換現有的優化手段,而是在上層加一個潛在空間的映射層,直接削減前向傳播的次數。
每次讓GPT-5寫封郵件模型都得一個token一個token地往外蹦字。每個token意味着一次完整的前向計算,要把數十億參數全過一遍。生成1000個token的回覆那就是1000次前向傳播,整個神經網絡要走1000遍,計算資源和延遲就這樣一點點累積起來。自迴歸架構就是這麼設計的現在這個機制正變成AI系統效率的最大瓶頸。
找到比token更高層次的表示形式,對降低延遲、提升吞吐量都有直接作用。換句話説,用更少的資源幹同樣的活兒。
token本身已經是詞彙表規模和表達能力之間比較精妙的平衡了,想在這個基礎上再優化並不簡單。
詞彙表示的粒度選擇
主流語言模型的詞彙表通常在3萬到25萬個token之間。每個token對應一個學習出來的嵌入向量,存在查找表裏,和transformer的層一起訓練。模型就是靠拼接這些子詞片段來還原文本。
看看其他方案就知道為什麼這個設計能勝出了。
如果往上走用完整的詞或短語來表示,詞彙表會膨脹到無法控制。 詞級分詞得為每種語言的每個詞形都建條目,短語級更不用説,光是兩個詞的組合就能把查找表撐爆。
往下走又會碰到另一個極端,字符級模型處理英文ASCII只要95個條目左右,內存佔用看起來很好。 但問題是要把所有語言知識塞進這麼小的嵌入空間(這事兒本身就夠嗆),更要命的是生成變成了逐字符進行。本來就貴的自迴歸循環直接翻4到5倍。
子詞token正好卡在中間這個位置。語義信息足夠豐富,詞彙表又不會大到裝不下。transformer普及這麼多年,分詞方式基本沒變過,原因就在這兒。
得換個角度,不是去替換token,而是在token之上再搭一層。
Continuous Autoregressive Language Models(CALM)做的就是這個思路。整個框架包含好幾個模塊,這篇文章先聚焦基礎部分:把token序列壓縮成密集向量的自編碼器。

自編碼器的作用
在講CALM架構之前,得先理解自編碼器為什麼重要,最直觀的例子是圖像生成。
傳統自編碼器的基本原理
自編碼器的設計目標很明確:把輸入數據壓縮成緊湊的表示,然後從這個表示裏把原始數據重建回來。
編碼器負責壓縮,解碼器負責還原。
自編碼器在擴散模型裏才真正展現了威力
玩過Stable Diffusion或Midjourney就知道自編碼器是怎麼工作的,這些系統不是在原始的高維空間裏一個像素一個像素地生成圖像。

傳統自編碼器創建潛在空間 z,用作解碼器重建輸入的先驗知識,公式摘自原始 CALM 論文。
實際流程是先用自編碼器把圖像壓縮到更小的潛在空間。擴散過程完全在這個壓縮後的空間裏進行,根據文本提示不斷調整,把噪聲逐步變成有意義的潛在表示。最後一步才是解碼器把潛在向量展開成完整圖像。
不過傳統自編碼器有個硬傷:單純為了重建而訓練的自編碼器,會把每個輸入映射到潛在空間裏一個特定的點。解碼器記住瞭如何反向操作。
聽上去挺高效但實際上系統很脆弱,稍微偏離那些記住的點——生成模型必然會產生這種偏移——解碼器就會輸出一堆亂碼。
學習到的脆弱空間可能與學習目標完美對齊,但這可以被解釋為過擬合。學習到的空間過於嚴格,無法很好地泛化,這意味着缺乏泛化性性。
變分自編碼器帶來的改進
變分自編碼器的做法是把目標放鬆。編碼器輸出的不是精確的點,而是一個分佈用均值和方差來定義。
訓練目標里加入了Kullback-Leibler散度這一項,輕輕地把這些分佈往標準高斯分佈推,潛在空間就變得平滑了。
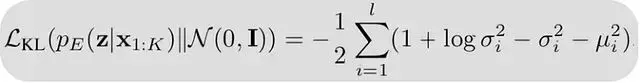
KL 組件懲罰編碼器的高斯後驗 pE(z ∣x)(由其均值和方差參數化)與固定先驗 N(0,I ) 之間的散度,從而鼓勵每個輸入的潛在表示遵循該先驗分佈,公式摘自原始 CALM 論文。
不強制編碼器把輸入精確映射到某個點,允許它定義一小片區域——一個帶均值和方差的概率分佈。從這個區域裏隨機採樣,解碼出來的結果應該大致相同。
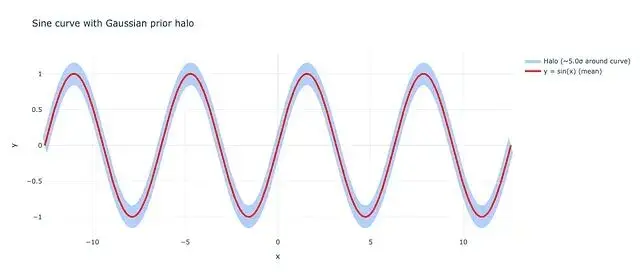
KL 散度目標,當使用較小的權重時,允許我們學習相對於目標目標的一些方差。在這種情況下藍色光暈是紅色表示的目標函數所允許的邊距,所有這些共同代表變分自編碼器的允許區域。
在重建損失里加上這個KL散度項(權重通常設得比較小),相當於告訴模型:「重建要準確,但在潛在空間裏放哪兒不用太較真。」
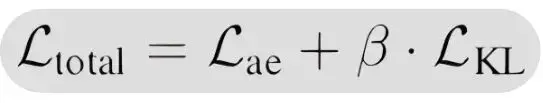
變分自編碼器學習目標的表示,beta 作為平衡 KL 散度貢獻的小超參數,允許對潛在空間採樣的空間約束較少。公式摘自原始 CALM 論文。
得到的流形更平滑,相鄰的點編碼的輸出也相似。解碼器學會處理變化而不是期待完美輸入,這種泛化性正是另一個模型預測這些潛在向量時需要的特性。
解碼器對噪聲的容忍度變高了。潛在空間裏的小擾動只會讓輸出產生小變化,不會導致徹底崩潰。
這種平滑性讓擴散模型可以在潛在空間裏遊走,大概率能落在有意義的圖像上。
提升語義帶寬的自編碼器方案
前面講的自編碼器都針對圖像,跟文本沒什麼關係,那為什麼對CALM重要?
在不拋棄子詞token的前提下提升語義帶寬,辦法是用變分自編碼器把 k 個連續token壓縮成一個密集向量。
編碼器把token序列壓成一個潛在向量,解碼器再把它還原成原始token。語言模型一次前向傳播就能生成一個代表 k 個token的向量,不用每次只蹦一個token了。
所以繞道擴散模型這一圈是值得的。泛化性在這裏同樣關鍵,語言模型預測潛在向量時肯定會帶入誤差。
脆弱的自編碼器會把那些稍有偏差的向量解碼成完全錯誤的token序列。變分自編碼器憑藉平滑的潛在流形,照樣能把它們解碼成正確的token。
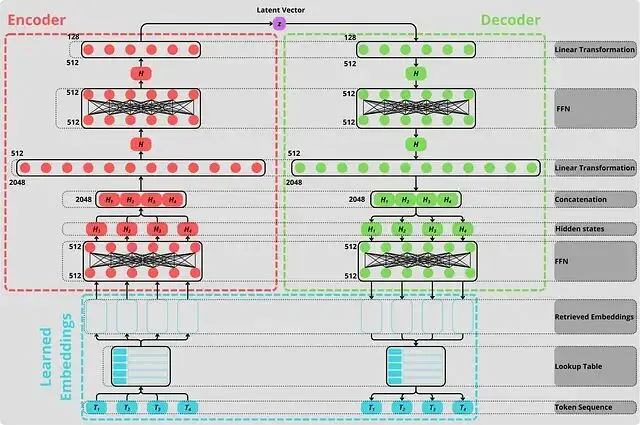
CALM 中提出的自編碼器的完整架構,正如我們所看到的,編碼器(紅色)和解碼器(綠色)是鏡像,一個用於生成潛在空間,另一個用於解碼它。從這個意義上説,這個自編碼器是創新的,因為它學習表示比token更高的語義單元,學習自己的token嵌入(藍色)。圖片由作者創建。
為不同任務定製的嵌入
編碼器第一件事是把token轉成能處理的數字。跟普通語言模型一樣,需要學習嵌入——一張把每個token映射到密集向量的查找表。
k 個token嵌入各自通過一個前饋網絡,然後拼接起來經過線性層壓縮成最終的潛在向量 z,解碼器按相反方向做鏡像操作。
為什麼要從頭學新嵌入,不直接借用現成語言模型的?
每個模型需要為自己的任務學嵌入,不同任務需要不同的嵌入:
語言模型的嵌入是為下一個token預測服務的——捕捉哪些token傾向跟在哪些token後面這類模式。自編碼器的嵌入是為序列壓縮和重建服務的——捕捉哪些token傾向於在一個塊裏同時出現這類模式。
三重泛化性機制
讓自編碼器在下游生成任務裏足夠泛化,訓練時還需要疊加幾種技術。
第一層是變分目標本身,損失函數里加的那個小KL散度項讓潛在空間變平滑,前面已經説過了。
第二層是對潛在向量做dropout,訓練時 z 裏大約15%的維度會被清零再去解碼。這逼着解碼器學冗餘表示——不能指望某個維度一定存在,得把信息分散到整個向量裏。
第三層是對輸入token做dropout。每個訓練序列里約15%的token會被遮掉。本質上就是把掩碼語言建模用在自編碼器上:模型得根據上下文推斷缺失的token,潛在表示最終編碼的是語義含義不只是token索引的壓縮查表。
維度坍縮的隱患
即便做了這些還有一種失效模式要處理:潛在表示坍縮。
損失函數裏的KL散度項會懲罰偏離標準高斯先驗的維度。有些維度發現直接變成先驗更省事——坍縮到零均值單位方差——不用編碼任何信息。CALM的自編碼器裏,放任不管的話128個維度裏有71個會坍縮。
維度坍縮時,好幾個維度會降到某個特定值,對優化目標來説挺方便。
這造成兩個問題,都源於損失函數裏的兩項(原始自編碼器損失和KL散度損失)計算時用同一個均值:
第一,潛在空間信息貧乏,得到的是稀疏嵌入而非密集嵌入。模型發現少數幾個維度就能承載所需信息,其他維度多餘。第二,坍縮的維度給解碼器注入純噪聲,因為它們只是從沒有信號的高斯分佈採樣。解碼器拿不到真實的token。
解決辦法是KL裁剪,不讓每個維度的KL損失降到零,設個下限(這裏是0.5)。任何維度的KL貢獻低於這個閾值,損失就鉗制在最小值。
現在想降低總損失,唯一的辦法是讓每個維度都編碼點有用的東西。
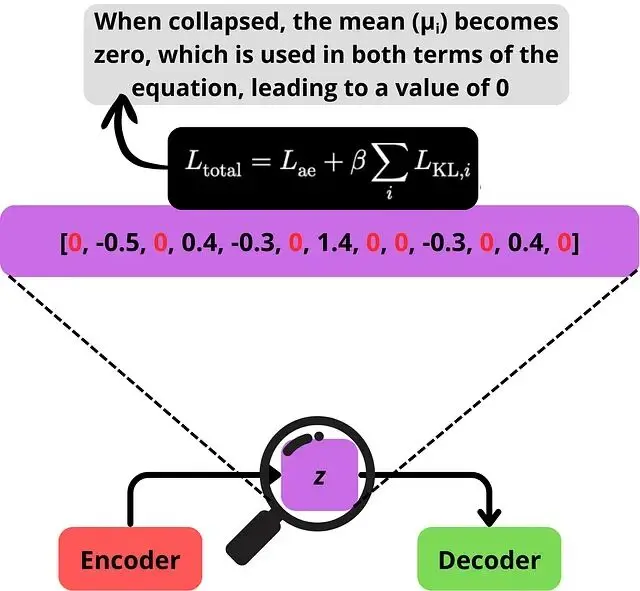
當維度崩潰時,大多數座標收斂到相同的值(這裏是零),因此只有少數維度攜帶信息,其餘的向解碼器添加噪聲。
這樣一來全部128個維度都保持活躍,都在傳遞信息。解碼器接收到的是密集、有意義的信號,而不是被噪聲稀釋的稀疏信號。
面向語言建模的潛在空間
到這一步,有了個能把 k 個token壓縮成密集、泛化潛在向量的自編碼器,重建準確率超過99.9%(token級別)。潛在空間平滑,所有維度都攜帶信號,解碼器能優雅地處理帶噪輸入。
這是CALM的基礎,接下來是訓練一個完全在潛在空間操作的語言模型——預測下一個向量而非下一個token。每個預測的向量經過凍結的自編碼器解碼器,生成 k 個實際token。
但生成式語言模型依賴在有限詞彙表上計算概率。連續向量沒有詞彙表——只有個無限維空間,似然變得無從計算。也就是説
整套訓練和評估框架得從頭重新設計。
似然計算的困境
訓練自編碼器、從文本塊預計算潛在空間,這只是第一步。讓語言模型適應這種增強的語義帶寬,需要徹底改造建模框架:
無似然訓練:標準的最大似然(token交叉熵)算不出來了。目標損失得完全重新構思。
無似然評估:沒有token概率就沒法算困惑度。得用新指標衡量語言模型在潛在空間裏的學習效果。
無似然採樣:温度控制沒法重新縮放logits,拿不到每個token的概率分佈了不像下一個token預測那樣。得開發新的採樣方法來處理文本生成。
工程實現的考量
CALM的自編碼器從根本上改變了LLM技術棧裏的語義表示,對訓練和部署都有實際影響。
專用嵌入層 自編碼器學自己的token嵌入——任務性質(聯合k-token壓縮/重建)跟自迴歸的下一token預測不同,優化的是「批量共現」模式而非「逐步遞進」的幾何關係。
離線訓練開銷 變分目標、KL裁剪、潛在/輸入dropout,再加上全語料編碼——預訓練/微調/對齊之上又多了一大塊一次性計算成本,好在推理階段不涉及。
後期集成 比較適合作為完整LLM生命週期後的附加層,凍結解碼器實現「下一潛在向量」生成,用前期成本換延遲/吞吐量的大幅改善。
正交優化 跟高效注意力機制/量化是互補關係,從結構上削減每個輸出的前向傳播次數。
無似然訓練:從離散到連續的範式轉換
有了自編碼器下一步是訓練能在潛在空間操作的語言模型。但傳統的最大似然估計(交叉熵損失)在這裏完全失效了:沒有有限詞彙表,就算不出softmax,也就沒法得到顯式的概率分佈。
下一向量預測
自編碼器建立了K個token和單個連續向量之間的雙向映射。現在可以把語言建模從「預測下一個token」重新定義為「預測下一個向量」。
給定T個token的序列 X = (x₁, ..., xₜ),先分成L = T/K個不重疊的塊,編碼器把原始序列轉換成更緊湊的連續向量序列:
Z = (z₁, z₂, ..., z_L),其中 z_i = f_enc(x_(i-1)K+1, ..., x_iK)
自迴歸目標變成預測序列中的下一個向量:p(Z) = ∏ p(z_i | z_<i)
問題在於z_i 存在於無限的實數空間ℝˡ中。softmax在這個不可數集合上不適用,顯式概率密度 p(z_i | z_<i) 無法計算。這帶來兩個核心挑戰:訓練沒法用最大似然估計,評估沒法算困惑度。
生成頭的設計約束
處理連續數據的生成模型(VAE、GAN、擴散模型)已經研究得很充分了,圖像和音頻合成領域都在用。最近有個趨勢是把這些方法跟自迴歸模型結合:Transformer主幹預測條件隱藏狀態,後續的生成模型在每一步產生連續輸出。
CALM採用了這個架構,但有個硬性約束:計算效率。擴散模型或流匹配需要迭代採樣——生成一個向量要幾十甚至上百次網絡評估,這直接抵消了減少自迴歸步驟帶來的加速。所以CALM需要的是能高質量單步生成的生成頭。
這個組件被設計成輕量級的「生成頭」。形式上,它是個隨機函數,接收Transformer的隱藏狀態 h_i-1 ∈ ℝᵈ,從條件分佈中抽取樣本 z_i ∈ ℝˡ:
h_i-1 = Transformer(z_1:i-1),z_i ~ p(· | h_i-1)
能量損失:嚴格適當評分規則
訓練目標借鑑了嚴格適當評分規則(strictly proper scoring rules)的理論。評分規則 S(P, y) 給預測分佈P在觀察到結果y時打分,分數越高越好。預測分佈P相對於真實分佈Q的質量用期望得分衡量:S(P, Q) = 𝔼_y~Q [S(P, y)]
如果期望得分在P = Q時達到最大,這個評分規則就是「適當的」(proper):
S(P, Q) ≤ S(Q, Q) 對所有分佈P成立
如果等號僅在P = Q時成立,就是「嚴格適當的」(strictly proper)。這保證了評分規則不會激勵模型預測有偏或扭曲的分佈。
用嚴格適當評分規則作為訓練目標,最大化期望得分就等價於讓模型的預測分佈逼近真實分佈。這其實是最大似然估計的直接推廣,負對數似然就是對數得分的特例。雖然連續域的似然算不出來,評分規則理論提供了豐富的替代方案。
訓練目標採用能量得分(Energy Score),一個在多種生成任務中都表現不錯的嚴格適當評分規則。能量得分完全不需要似然,而是通過樣本距離來衡量預測和觀測的對齊程度。對於預測分佈P和真實觀測 y:
S(P, y) = 𝔼x',x''~P [‖x' - x''‖^α] - 2𝔼x~P [‖x - y‖^α]
第一項鼓勵多樣性,懲罰產生塌陷或過度自信預測(所有樣本都相同)的模型。第二項鼓勵保真度,驅動模型的預測接近真實觀測。這裏的α通常設為1,對於α ∈ (0, 2),得分都是嚴格適當的。
雖然期望無法精確計算,可以構造無偏的蒙特卡洛估計器作為實際的損失函數「能量損失」。在每一步i,從生成頭抽取N個候選樣本 {z̃i,1, ..., z̃i,N}。另外自編碼器不是把token塊映射到固定點,而是映射到條件高斯後驗 z_i ~ q(· | x_(i-1)K+1:iK)。依賴單個樣本 z_i 作為真值會給能量損失帶來高方差。為了緩解這個問題並穩定訓練從這個後驗抽取M個目標樣本 {z_i,1, ..., z_i,M}。
這樣就得到了最終的能量損失:
ℒenergy = Σi (2/NM Σn Σm ‖z_i,m - z̃i,n‖ - 1/N(N-1) Σn≠k ‖z̃i,n - z̃i,k‖)
實踐中設N = 8,M = 100。模型樣本數N直接影響訓練成本,因為每個樣本都需要評估一次生成頭,所以用小N保持訓練效率。從已知高斯後驗抽取目標向量的開銷幾乎可以忽略,所以用大M來降低損失的方差。
這個無似然訓練目標的關鍵優勢是靈活性:只要求能從生成頭抽樣,對內部架構的約束很少,允許簡單高效的設計。
能量Transformer架構
生成頭的輸入有兩部分:Transformer主幹輸出的隱藏狀態 h_i-1(提供條件上下文),和隨機噪聲向量 ε ∈ ℝᵈⁿᵒⁱˢᵉ(提供採樣所需的隨機性)。ε 的每個維度從均勻分佈 U[-0.5, 0.5] 獨立採樣。隱藏狀態和噪聲向量都通過獨立的線性層投影到生成頭的內部維度,這個維度設為跟Transformer的隱藏維度d相同。
生成頭的核心是L個殘差MLP塊的堆疊,逐步把初始噪聲表示 ε₀ = ε 精煉成最終的輸出向量。每個MLP塊先通過兩個線性層把當前表示 ε_l 和隱藏狀態融合,然後是中間維度為d的SwiGLU層。殘差連接把塊的輸入加到輸出上。最後用一個線性層把表示投影到目標維度l,產生輸出向量 z_i。
單個MLP塊包含約6d²個參數。塊的數量設為Transformer層數的四分之一,整個生成頭只佔總模型參數的10%左右,計算開銷很小。
離散token輸入的必要性
對於模型輸如:一般做法是把上一步預測的潛在向量 z_i-1 用線性投影嵌入到Transformer的隱藏維度d。但實驗發現用這些潛在向量作為Transformer的輸入會導致性能明顯下降,模型難以從這麼緊湊的輸入表示中解包語義信息。
解決辦法是把模型的自迴歸過程基於離散token空間。訓練時,每步的輸入由上一步的K個token構成。為了保持效率用輕量級的輸入壓縮模塊——兩層MLP——把K個嵌入映射成單個輸入表示。推理流程如下:
輸入處理:在步驟i,前面生成的K個token被嵌入並壓縮成單個輸入表示送入Transformer。
連續預測:Transformer輸出隱藏狀態 h_i-1,能量生成頭用它預測下一個連續向量 z_i。
離散反饋循環:預測的向量 z_i 立即通過凍結的預訓練自編碼器解碼器 g_dec重建下一個K個離散token。
這個設計保證了模型始終在語義豐富的離散空間進行條件化同時在潛在空間完成高效的預測。
BrierLM:無似然評估指標
還有一個問題就是困惑度(Perplexity)無法用了,需要新的評估指標。CALM提出BrierLM,基於布賴爾得分(Brier score)評分規則,現在廣泛用於評估神經網絡的校準性。
對於預測分佈P和真實結果y,布賴爾得分定義為:
Brier(P, y) = 2P(y) - Σ_x P(x)²
跟只衡量準確性的原始似然P(y)不同,布賴爾得分包含額外項 Σ_x P(x)² 來量化預測不確定性。這個結構平衡了兩個競爭目標,最終獎勵良好校準的預測。期望布賴爾得分可以分解為:
𝔼y~Q [Brier(P, y)] = -Σx (P(x) - Q(x))² + Σ_x Q(x)²
第一項是平方誤差,在P = Q時最小化。第二項是數據方差,是常數。所以期望布賴爾得分僅在P = Q時唯一最大化,確保了它是嚴格適當的。
BrierLM的優勢是可以僅通過從模型抽樣來無偏估計不需要顯式概率,對於傳統自迴歸模型可以從最終的softmax分佈抽樣來應用BrierLM估計器,實現跟無似然框架的直接公平比較。
實驗驗證顯示,在訓練傳統自迴歸模型的整個過程中BrierLM和交叉熵高度一致,呈現近乎線性的關係,皮爾遜相關係數-0.966,斯皮爾曼等級相關-0.991。這種強單調對齊確認BrierLM是可靠的語言建模能力度量,建立了它作為困惑度的可信無似然替代品的地位。
實驗結果與性能分析
實驗在標準語言建模基準上驗證CALM框架,展現了更優的性能-計算權衡。當K = 4時(一個向量代表4個token),CALM達到了與強離散基線相當的性能,但計算成本顯著更低。
隨着K增加所需計算量按比例減少,並且性能只有輕微下降。這確認了語義帶寬是優化語言模型性能-計算比的高效縮放軸。在K = 1時CALM的性能落後於離散模型,説明當前設計還有很大改進空間。
對比了三種生成頭:基於能量的方法、擴散和流匹配。擴散模型表現不好,流匹配初期收斂更快,但基於能量的頭達到了更高的性能上限。能量頭單步生成其他兩種方法依賴迭代採樣,這讓能量頭成為以效率為目標的框架的明確選擇。
371M參數的CALM-M模型達到了與281M參數離散基線相當的BrierLM分數,但FLOPs更少。CALM建立了新的、更高效的語言建模性能-計算前沿。增加每個自迴歸步驟的語義帶寬,允許CALM在參數數量上顯著更大的同時,訓練和推理所需的FLOPs更少。
這些發現確立了下一向量預測作為通向超高效語言模型的強大且可擴展路徑。語義帶寬這個新的設計軸,跟KV緩存、量化一樣,可能成為LLM的標配優化方向。
論文:
https://avoid.overfit.cn/post/0c9c3766205f44e5bc74fcf9328468ec