

PyTorch是一個流行的深度學習框架,一般情況下使用單個GPU進行計算時是十分方便的。但是當涉及到處理大規模數據和並行處理時,需要利用多個GPU。這時PyTorch就顯得不那麼方便,所以這篇文章我們將介紹如何利用torch.multiprocessing模塊,在PyTorch中實現高效的多進程處理。
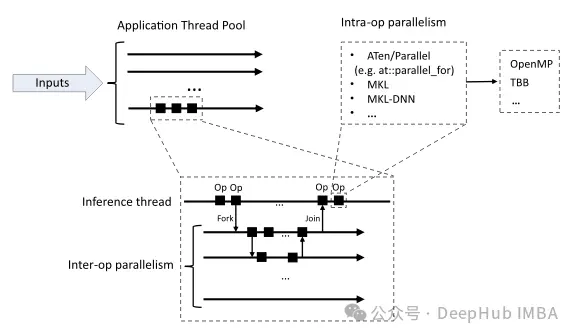
多進程是一種允許多個進程併發運行的方法,利用多個CPU內核和GPU進行並行計算。這可以大大提高數據加載、模型訓練和推理等任務的性能。PyTorch提供了torch.multiprocessing模塊來解決這個問題。
導入庫
import torch
import torch.multiprocessing as mp
from torch import nn, optim對於多進程的問題,我們主要要解決2方面的問題:1、數據的加載;2分佈式的訓練
數據加載
加載和預處理大型數據集可能是一個瓶頸。使用torch.utils.data.DataLoader和多個worker可以緩解這個問題。
from torch.utils.data import DataLoader, Dataset
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
data = [i for i in range(1000)]
dataset = CustomDataset(data)
dataloader = DataLoader(dataset, batch_size=32, num_workers=4)
for batch in dataloader:
print(batch)num_workers=4意味着四個子進程將並行加載數據。這個方法可以在單個GPU時使用,通過增加數據讀取進程可以加快數據讀取的速度,提高訓練效率。
分佈式訓練
分佈式訓練包括將訓練過程分散到多個設備上。torch.multiprocessing可以用來實現這一點。
我們一般的訓練流程是這樣的
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
def train(rank, model, data, target, optimizer, criterion, epochs):
for epoch in range(epochs):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f"Process {rank}, Epoch {epoch}, Loss: {loss.item()}")要修改這個流程,我們首先需要初始和共享模型
def main():
num_processes = 4
data = torch.randn(100, 10)
target = torch.randn(100, 1)
model = SimpleModel()
model.share_memory() # Share the model parameters among processes
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
processes = []
for rank in range(num_processes):
p = mp.Process(target=train, args=(rank, model, data, target, optimizer, criterion, 10))
p.start()
processes.append(p)
for p in processes:
p.join()
if __name__ == '__main__':
main()上面的例子中四個進程同時運行訓練函數,共享模型參數。
多GPU的話則可以使用分佈式數據並行(DDP)訓練
對於大規模的分佈式訓練,PyTorch的torch.nn.parallel.DistributedDataParallel(DDP)是非常高效的。DDP可以封裝模塊並將其分佈在多個進程和gpu上,為訓練大型模型提供近線性縮放。
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP修改train函數初始化流程組並使用DDP包裝模型。
def train(rank, world_size, data, target, epochs):
dist.init_process_group("gloo", rank=rank, world_size=world_size)
model = SimpleModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
criterion = nn.MSELoss()
for epoch in range(epochs):
optimizer.zero_grad()
output = ddp_model(data.to(rank))
loss = criterion(output, target.to(rank))
loss.backward()
optimizer.step()
print(f"Process {rank}, Epoch {epoch}, Loss: {loss.item()}")
dist.destroy_process_group()修改main函數增加world_size參數並調整進程初始化以傳遞world_size。
def main():
num_processes = 4
world_size = num_processes
data = torch.randn(100, 10)
target = torch.randn(100, 1)
mp.spawn(train, args=(world_size, data, target, 10), nprocs=num_processes, join=True)
if __name__ == '__main__':
mp.set_start_method('spawn')
main()這樣,就可以在多個GPU上進行訓練了
常見問題及解決
1、避免死鎖
在腳本的開頭使用mp.set_start_method('spawn')來避免死鎖。
if __name__ == '__main__':
mp.set_start_method('spawn')
main()因為多線程需要自己管理資源,所以請確保清理資源,防止內存泄漏。
2、異步執行
異步執行允許進程獨立併發地運行,通常用於非阻塞操作。
def async_task(rank):
print(f"Starting task in process {rank}")
# Simulate some work with sleep
torch.sleep(1)
print(f"Ending task in process {rank}")
def main_async():
num_processes = 4
processes = []
for rank in range(num_processes):
p = mp.Process(target=async_task, args=(rank,))
p.start()
processes.append(p)
for p in processes:
p.join()
if __name__ == '__main__':
main_async()3、共享內存管理
使用共享內存允許不同的進程在不復制數據的情況下處理相同的數據,從而減少內存開銷並提高性能。
def shared_memory_task(shared_tensor, rank):
shared_tensor[rank] = shared_tensor[rank] + rank
def main_shared_memory():
shared_tensor = torch.zeros(4, 4).share_memory_()
processes = []
for rank in range(4):
p = mp.Process(target=shared_memory_task, args=(shared_tensor, rank))
p.start()
processes.append(p)
for p in processes:
p.join()
print(shared_tensor)
if __name__ == '__main__':
main_shared_memory()共享張量shared_tensor可以被多個進程修改
總結
PyTorch中的多線程處理可以顯著提高性能,特別是在數據加載和分佈式訓練時使用torch.multiprocessing模塊,可以有效地利用多個cpu,從而實現更快、更高效的計算。無論您是在處理大型數據集還是訓練複雜模型,理解和利用多處理技術對於優化PyTorch中的性能都是必不可少的。使用分佈式數據並行(DDP)進一步增強了跨多個gpu擴展訓練的能力,使其成為大規模深度學習任務的強大工具。
https://avoid.overfit.cn/post/a68990d2d9d14d26a4641bbaf265671e
作者:Ali ABUSALEH