

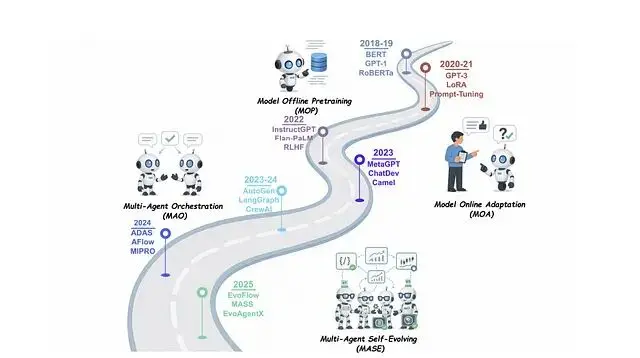
傳統AI智能體有個老問題:部署之後就"定住了"。工程師手工打磨的提示詞和規則,遇到新場景就容易失靈,性能曲線到達某個點後趨於平緩。而自我進化智能體(Self-Evolving Agent)的思路就是打破這種靜態模式,讓智能體在運行過程中持續收集反饋,自動調整自身策略,形成一個閉環:執行任務 → 獲取反饋 → 自我調整 → 繼續執行。
這套機制把基礎模型的能力與在線學習結合起來。用更學術的表述,自我進化智能體是"通過與環境交互持續優化內部組件的自主系統,目標是適應變化的任務、上下文和資源"。比如説這類智能體不只是做題,還會批改自己的作業、找出哪裏寫錯了、然後調整學習策略,整個過程不需要人類介入。
上圖展示了典型的反饋循環結構。基線智能體執行任務產生輸出,由人類評審或LLM評判者打分,反饋信息(分數、錯誤描述、改進建議)彙總後用於更新智能體,可能是調整提示詞、微調參數、或修改配置。這個循環反覆執行直到達成性能目標。
與固定配置的傳統方案相比,自我進化智能體的核心差異在於能夠監控自身表現並主動適應。多數已部署的智能體依賴人工設定的規則或提示,無法跟上數據分佈的漂移或任務需求的演變。反饋循環解決了這個問題:每次任務完成後收集評估信號,識別薄弱環節,針對性地更新智能體。長期來看,系統的準確性和泛化性都會持續提升。這種機制對需要高準確率或面對動態環境的場景尤為關鍵,人類的角色從逐條修bug變成了設定目標和把握方向。
從架構視角看,自我進化系統可以抽象為四個核心要素:輸入、智能體系統、環境、優化器,它們在迭代循環中交互。最近有綜述將這類系統正式定義為"持續優化內部組件的自主系統,在保持安全性的前提下適應變化的任務與資源"。實際運行時,智能體執行標準的感知-推理-行動循環,但增加了自我評估和參數優化的元步驟。
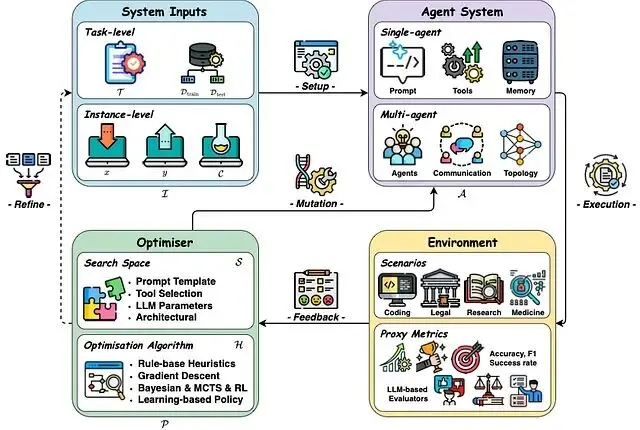
反饋循環的運作方式:從基線智能體開始(比如一個執行文檔摘要的Agent),人類或LLM評判者對其輸出進行評估。反饋信號既包括定量指標(0-1評分)也包括定性評論("摘要漏掉了關鍵細節")。多個信號彙總成綜合得分,如果得分低於閾值(假設是0.8),就調整提示或策略重新測試。新版本達標後替換舊版本,循環繼續。幾輪迭代下來,智能體具備了自我修復能力。
這種設計的優勢在於可擴展性(用LLM評估替代昂貴的人工標註)和適應性(自動響應新的失敗模式,不需要手動改代碼)。但也需要明確的安全約束:智能體在進化過程中必須保持穩定性(變化時不引入安全隱患)和性能單調性(不允許任務效果下降)。
自我進化循環的核心步驟
OpenAI Cookbook裏有個經典示例,把進化循環拆成四步:
第一步,基線智能體:準備一個初始版本,比如用特定提示詞做文本摘要的Agent。
第二步,收集反饋:讓智能體跑一批任務,收集輸出的評價,人工打分或者"LLM-as-Judge"的自動評分都行。評估內容包括摘要是否準確、是否簡潔、是否符合業務規則等。
第三步,量化評分:把反饋轉成可度量的指標。可以是規則校驗器、也可以是GPT評分標準,最後合成一個綜合質量分。
第四步,更新優化:如果得分沒達標,就調整智能體內部——優化提示詞、微調參數、或者換一個更好的版本,然後重新跑循環。
循環持續到性能超過閾值或達到重試上限。
agent = BaselineAgent()
score = evaluate(agent)
while score < target_score and tries < max_retries:
feedback = get_feedback(agent)
agent = optimize_agent(agent, feedback)
score = evaluate(agent)每輪迭代都用收集到的反饋調整智能體。如果優化成功,新版本替換舊版本,成為下一輪的基線。
關鍵模塊解析
自我進化智能體由幾個緊密耦合的模塊構成。
智能體循環是最核心的部分,智能體接收輸入(比如文檔片段),更新內部記憶或上下文,運行LLM推理,產出結果(比如摘要)。這個流程通常用某種Agent SDK實現,負責管理LLM調用和工具使用。自我進化層包裹在外面,根據需要觸發重跑或修改循環。架構上可以是單模塊也可以是多模塊——比如醫療場景可能同時有Summarizer和Compliance Checker兩個子智能體。持續的"思考-行動"循環產生可評估的輸出,為後續改進提供素材。
任務性能監控負責追蹤智能體的表現,典型配置包括自動評估器和可選的人工複核。以摘要任務為例,每個輸出會經過四個評分器檢查:
(1) Python函數檢查關鍵術語(如化學名稱)是否保留在摘要中;(2) 長度檢查器控制冗長度;(3) 餘弦相似度檢測摘要與原文的語義一致性;(4) LLM評判者按評分標準給出綜合評價。
前兩個是確定性規則,第三個是模糊匹配,第四個提供靈活的語言理解評估。多個評分器協作,既產出量化分數也生成定性反饋。監控模塊輸出數字分數或pass/fail標誌,外加描述問題的反饋文本。加權平均後得到彙總分數,決定輸出是否可接受。這個監控信號驅動整個改進流程。
內存模塊對持續學習,短期記憶存儲當前對話和規劃狀態,長期記憶保存累積知識、歷史解法、總結出的規則。RAG(檢索增強生成)讓智能體能從知識庫中拉取相關上下文。更復雜的系統會維護"記憶庫",存放過去的決策和推理軌跡。記憶幫助智能體保留學到的經驗:比如記住哪些提示模式效果更好,或者存儲之前遇到的拒絕案例。進化循環可以把反饋和結果寫入記憶,後續迭代查詢時就能避免重蹈覆轍。
獎勵/反饋建模把原始反饋轉換成訓練信號,對於LLM智能體,通常會構建獎勵模型或評分函數。每個評分器產出0-1分數,系統檢查是否過閾值(比如0.85)。多個分數可以合併成單一指標(比如取均值),這個綜合分數就是智能體的"獎勵"。用強化學習的視角看,智能體被優化來最大化這個獎勵。反饋也可以定性分類:如果某個評分器掛了,失敗原因可以轉成糾正指令。LLM評判者特別有用,因為它提供自然語言反饋("摘要需要更多細節"),智能體能直接用這些描述來改進輸出。總之,獎勵模塊確保優化目標清晰——"所有評分器通過,或者均分超過0.8"。
重訓練/優化模塊在性能不達標時更新智能體,提示詞調優、參數微調、結構變化(如添加新工具)。一種常見做法是用LLM做提示改進而非直接訓模型——"MetaPrompt"智能體拿到當前提示和反饋,被要求生成更好的版本。代碼用新提示替換舊提示。更進階的系統可能在收集的(輸入,輸出,反饋)數據上微調LLM,或用強化學習更新策略權重。核心思想是:根據反饋修改智能體內部組件(系統提示、模型權重、工具配置),讓下一次執行有更大成功概率。重訓後循環再次評估更新版本,形成閉環。
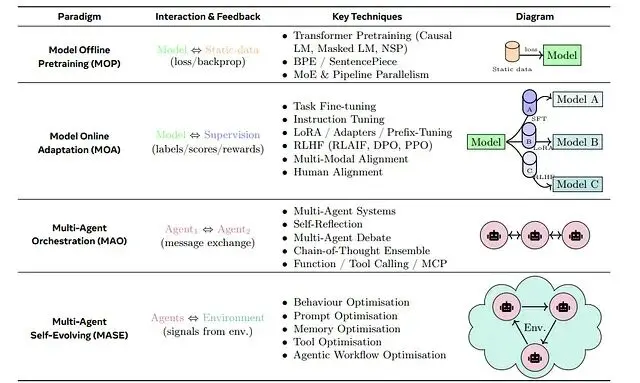
反饋收集與重訓練流程
自我進化智能體的反饋主要靠自生成或眾包。系統在一批任務上跑智能體,收集性能數據,包括:
分數和標籤:輸出是否滿足長度約束?是否包含必需實體?這些由自動檢查器記錄。
文本反饋:LLM評判者輸出解釋性語句,説明哪裏不足。
日誌和診斷:生成的token數、運行時統計、錯誤堆棧。
人工標註:如果有人工複核,評級和評論會被記錄。
智能體生成摘要後,評估代碼調用各評分器,把輸出解析成結構化結果(評分器名稱、數字分數、pass/fail、推理描述)。輔助函數如
parse_eval_run_output提取這些信息。智能體不依賴外部數據——自己的輸出就是訓練數據。隨着時間推移,這會積累起(輸入,輸出,反饋)三元組的數據集。
import time
import json
def run_eval(eval_id: str, section: str, summary: str):
"""使用輸入部分和輸出摘要創建評估運行。"""
return client.evals.runs.create(
eval_id=eval_id,
name="self-evolving-eval",
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": [
{
"item": {
"section": section,
"summary": summary,
}
}
],
},
},
)
def poll_eval_run(eval_id: str, run_id: str, max_polls = 10):
"""
輪詢評估運行直到完成或超時。
此函數的存在是為了通過定期檢查運行狀態來處理評估服務中的異步行為。
它通過在固定間隔輪詢而不是無限期阻塞來平衡響應性和資源使用。
重試限制可以防止在服務從不返回完成狀態的情況下出現失控循環。
"""
run = None
for attempt in range(1, max_polls + 1):
run = client.evals.runs.retrieve(eval_id=eval_id, run_id=run_id)
if run.status == "completed":
break
if attempt == max_polls:
print("Exceeded retries, aborting")
break
time.sleep(5)
run_output_items = client.evals.runs.output_items.list(
eval_id=eval_id, run_id=run_id
)
return run_output_items
def parse_eval_run_output(items):
"""提取所有評分器分數和任何可用的結論輸出。"""
all_results = []
for item in items.data:
for result in item.results:
grader_name_full = result.name
score = result.score
passed = result.passed
reasoning = None
try:
sample = result.sample
if sample:
content = result.sample["output"][0]["content"]
content_json = json.loads(content)
steps = content_json["steps"]
reasoning = " ".join([step["conclusion"] for step in steps])
except Exception:
pass
all_results.append(
{
"grader_name": grader_name_full,
"score": score,
"passed": passed,
"reasoning": reasoning,
}
)
return all_results重訓練流程:反饋收集完畢後,智能體進入更新階段。摘要評估失敗時,循環調用"MetaPrompt"智能體——輸入原始提示、源文檔、生成的摘要、失敗原因。MetaPrompt LLM輸出新提示。系統用這個新提示創建新版SummarizationAgent。本質上,智能體通過LLM重寫指令完成了"重訓練"。更高級的系統可能微調模型權重或調整其他模塊(更新記憶條目、更換工具)。關鍵點是智能體從錯誤中學習。
每輪迭代都應該帶來性能提升。示例循環給每個部分最多3次改進機會。如果新提示版本讓摘要通過所有評分器(寬鬆閾值),循環繼續;否則重複嘗試。代碼追蹤哪個提示版本綜合得分最高,處理完所有部分後部署最優版本。這種重訓既可以離線批量做,也可以在線隨新數據持續適應。最終產出一個只靠自生成反饋就進化得更準確的智能體。
代碼實現詳解
下面是OpenAI Notebook實現的關鍵部分。
1、評估配置
先定義帶多個評分器的Eval來給智能體輸出打分,用的是OpenAI Evals API。每個評分器檢查特定標準:chemical_name_grader(Python代碼)計算化學名稱在摘要中的出現比例,保證領域關鍵詞不丟失;word_length_deviation_grader控制摘要長度在容差範圍內;cosine_similarity測量源文和摘要的語義重疊度;llm_as_judge用GPT-4.1按評分標準給綜合分。這些評分器收集到
testing_criteria列表,然後創建評估:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
data_source_config = {
"type": "custom",
"item_schema": {"type": "object", "properties": {"section": {"type": "string"}, "summary": {"type": "string"}}, "required": ["section", "summary"]},
"include_sample_schema": False
}
testing_criteria = [
{
"type": "python",
"name": "chemical_name_grader",
"pass_threshold": 0.8,
"source": r"""
def grade(sample: dict, item: dict) -> float:
section = item["section"]
summary = item["summary"]
# 預期化學名稱列表
CHEMICALS_MASTER = [...]
present = [chem for chem in CHEMICALS_MASTER if chem in section]
if not present:
return 1.0
correct = sum(1 for chem in present if chem in summary)
return correct / len(present)
"""
},
{
"type": "python",
"name": "word_length_deviation_grader",
"pass_threshold": 0.85,
"source": r"""
def grade(sample: dict, item: dict) -> float:
summary = item["summary"]
word_count = len(summary.split())
expected = 100
tolerance = 0.2
deviation = abs(word_count - expected) / expected
if deviation <= tolerance:
return 1.0
score = max(0.0, 1.0 - (deviation - tolerance))
return score
"""
},
{
"type": "text_similarity",
"name": "cosine_similarity",
"input": "{{ item.summary }}",
"reference": "{{ item.section }}",
"evaluation_metric": "cosine",
"pass_threshold": 0.85,
},
{
"type": "score_model",
"name": "llm_as_judge",
"model": "gpt-4.1",
"input": [
{
"role": "system",
"content": (
"You are an expert summarization evaluator. Score the summary between 0 and 1..."
)
},
{
"role": "user",
"content": (
"Section:\n{{item.section}}\nSummary:\n{{sample.output_text}}"
)
}
],
"range": [0, 1],
"pass_threshold": 0.85,
},
]
eval = client.evals.create(
name="self_evolving_eval",
data_source_config=data_source_config,
testing_criteria=testing_criteria
)
print(f"Created Eval: {eval.id}")這段代碼導入OpenAI客户端,配置自定義數據schema(每個item有section和summary),定義四個評分器。Python評分器用內聯代碼(raw string)定義
grade函數。
client.evals.create()創建評估但還不執行。這些規則會對智能體生成的每個摘要自動打分。
2、執行評估
接着定義輔助函數,在給定的section-summary對上跑評估並解析結果:
import time, json
def run_eval(eval_id: str, section: str, summary: str):
"""使用一個示例(section+summary)安排評估運行。"""
return client.evals.runs.create(
eval_id=eval_id,
name="self-evolving-eval",
data_source={"type": "jsonl", "source": {"type": "file_content", "content": [
{"item": {"section": section, "summary": summary}}
]}}
)
def poll_eval_run(eval_id: str, run_id: str, max_polls=10):
"""輪詢直到評估運行完成,然後返回輸出項。"""
for attempt in range(max_polls):
run = client.evals.runs.retrieve(eval_id=eval_id, run_id=run_id)
if run.status == "completed":
break
time.sleep(5)
return client.evals.runs.output_items.list(eval_id=eval_id, run_id=run_id)
def parse_eval_run_output(items):
"""從評估運行輸出中提取評分器分數和推理。"""
all_results = []
for item in items.data:
for result in item.results:
score = result.score
passed = result.passed
reasoning = None
try:
content = result.sample["output"][0]["content"]
reasoning = json.loads(content)["steps"][0]["conclusion"]
except Exception:
pass
all_results.append({
"grader_name": result.name,
"score": score,
"passed": passed,
"reasoning": reasoning
})
return all_results
# 示例運行
EVAL_ID = eval.id
SECTION = "...some section text..."
SUMMARY = "...agent's summary..."
eval_run = run_eval(EVAL_ID, section=SECTION, summary=SUMMARY)
run_output = poll_eval_run(EVAL_ID, run_id=eval_run.id)
grader_scores = parse_eval_run_output(run_output)
print(grader_scores)run_eval函數把一個樣本(section+摘要)發送給評估服務,然後輪詢等待完成(
poll_eval_run),最後解析結果。輸出是字典列表,每個評分器一條,格式類似
{"grader_name": ..., "score": ..., "passed": ..., "reasoning": ...}。多數評分器只返回分數和pass/fail,LLM評分器會額外附帶推理文本。這種結構化反饋供循環決定如何改進智能體。比如
chemical_name_grader失敗,説明摘要漏掉了關鍵術語。
3、智能體與提示版本管理
下一步配置智能體本身和提示版本追蹤的數據結構,用OpenAI Agents SDK定義智能體並管理提示。
配置包括:
VersionedPrompt類(基於Pydantic)記錄提示版本和元數據;
PromptVersionEntry存儲每個版本的文本、版本號、模型、時間戳等;兩個智能體——SummarizationAgent(執行實際任務)和MetaPromptAgent(負責改寫提示)。
from datetime import datetime
from typing import Any, Optional
from pydantic import BaseModel, Field
class PromptVersionEntry(BaseModel):
"""存儲提示的一個版本和相關元數據。"""
version: int
model: str = "gpt-5"
prompt: str
timestamp: datetime = Field(default_factory=datetime.utcnow)
metadata: Optional[dict[str, Any]]
class Config:
validate_assignment = True
extra = "forbid"
class VersionedPrompt:
"""跟蹤PromptVersionEntry列表並允許更新。"""
def __init__(self, initial_prompt: str, model: str = "gpt-5"):
self._versions = [PromptVersionEntry(version=0, model=model, prompt=initial_prompt)]
def current(self) -> PromptVersionEntry:
return self._versions[-1]
def update(self, new_prompt: str, model: Optional[str] = None, metadata: Optional[dict]=None):
next_version = self.current().version + 1
entry = PromptVersionEntry(version=next_version,
model=model or self.current().model,
prompt=new_prompt, metadata=metadata)
self._versions.append(entry)
return entry
# 創建智能體和初始提示
from agents import Agent # 假設的agents SDK
METAPROMPT_TEMPLATE = """
Context:
Original prompt: {original_prompt}
Section: {section}
Summary: {summary}
Reason to improve: {reasoning}
Task:
Write an improved summarization prompt that is more specific and preserves all details...
"""
metaprompt_agent = Agent(name="MetaPromptAgent", instructions="You are a prompt optimizer.")
summarization_prompt = VersionedPrompt(initial_prompt="You are a summarization assistant. Given a section, produce a summary.")
summarization_agent = Agent(name="SummarizationAgent", instructions=summarization_prompt.current().prompt, model=summarization_prompt.current().model)VersionedPrompt確保每次提示變更都有記錄(版本1、2、3...)。
PromptVersionEntry存儲文本及相關模型、版本號等信息。代碼實例化了一個"MetaPromptAgent"專門負責重寫提示,以及一個用簡單初始提示的SummarizationAgent。循環中每次更新提示時調用
summarization_prompt.update(...),新條目追加到版本列表,需要時可以回滾。這套機制讓提示演變過程可追溯。
4、自我進化循環編排
最後是核心的自我改進循環實現。單次迭代的邏輯:
- 智能體用當前提示生成摘要;
- 在(section, summary)上跑評估拿到評分;
- 計算綜合分數(評分器均值),檢查是否過寬鬆閾值;
- 通過則成功;未通過則收集反饋並改進提示;
- 每個部分最多重試若干次;
- 所有部分處理完後,選擇綜合得分最高的提示版本。
簡化代碼如下:
MAX_RETRIES = 3
for section, content in dataset:
for attempt in range(1, MAX_RETRIES+1):
# 運行總結智能體
result = Runner.run(summarization_agent, content)
summary = result.final_output
# 用評分器評估
grader_scores = await get_eval_grader_score(eval_id=EVAL_ID, section=content, summary=summary)
avg_score = calculate_grader_score(grader_scores)
passed = is_lenient_pass(grader_scores, avg_score)
print(f"Attempt {attempt}: avg score={avg_score}, passed={passed}")
if passed:
break
# 如果失敗,收集文本反饋並向MetaPromptAgent詢問新提示
feedback = collect_grader_feedback(grader_scores)
prompt_input = METAPROMPT_TEMPLATE.format(
original_prompt=summarization_prompt.current().prompt,
section=content,
summary=summary,
reasoning=feedback
)
meta_result = await Runner.run(metaprompt_agent, prompt_input)
improved_prompt = meta_result.final_output
# 更新總結智能體的提示
summarization_prompt.update(new_prompt=improved_prompt, metadata={"section": content, "summary": summary})
summarization_agent = Agent(name="SummarizationAgent", instructions=improved_prompt, model=summarization_prompt.current().model)
print(f" Improved prompt to version {summarization_prompt.current().version}")對每個文檔部分,
SummarizationAgent生成摘要,然後跑評估(
get_eval_grader_score)計算分數。未通過檢查時,組裝反饋字符串(如"化學名稱缺失"或LLM給的原因描述),調用MetaPrompt智能體傳入原始提示、文檔片段、摘要和反饋。MetaPrompt LLM返回新提示,更新
VersionedPrompt並重建SummarizationAgent。重試最多
MAX_RETRIES次直到通過或放棄。處理完所有數據後,追蹤哪個提示版本綜合得分最高。實際循環會記錄每一步並最終打印最優版本。這展示了自生成反饋(評分器結果)如何驅動迭代改進——智能體在教自己如何寫更好的提示。
總結
自我進化智能體適用於任何任務複雜且持續演變的領域。除了醫療文檔,金融(智能體跟隨市場變化更新策略)、編程(代碼生成智能體適應新庫和新錯誤模式)、生物醫學(研究助手迭代優化文獻綜述)都是潛在場景。相關研究已經指出生物醫學、編程、金融這些垂直領域的具體策略。代碼生成智能體可以根據測試結果持續改進編碼風格或錯誤檢測邏輯;客服聊天機器人可以從新類型的用户諮詢中在線學習。
隨着AI智能體被部署到關鍵任務,自動自我改進能把人力從繁瑣的debug轉移到高層決策——設定目標、確保安全。能夠自我糾錯的智能體長期來看更可靠。
最後這個領域還很新,算是對這個方向的首批系統性審視之一,開放問題很多。比如説如何安全地允許智能體改寫自身行為?什麼評估基準最適合持續學習?但前景很有吸引力:未來的助手能優雅地從經驗中學習;工廠機器人隨生產需求自我調整;教育導師為每個學生個性化自己的教學策略。從靜態AI到真正的終身學習智能體,這條路剛剛開始。
https://avoid.overfit.cn/post/39758407b909479aab400a01b29bac65
作者:DhanushKumar