

llama.cpp server在 2025年12月11日發佈的版本中正式引入了 router mode(路由模式),如果你習慣了 Ollama 那種處理多模型的方式,那這次 llama.cpp 的更新基本就是對標這個功能去的,而且它在架構上更進了一步。
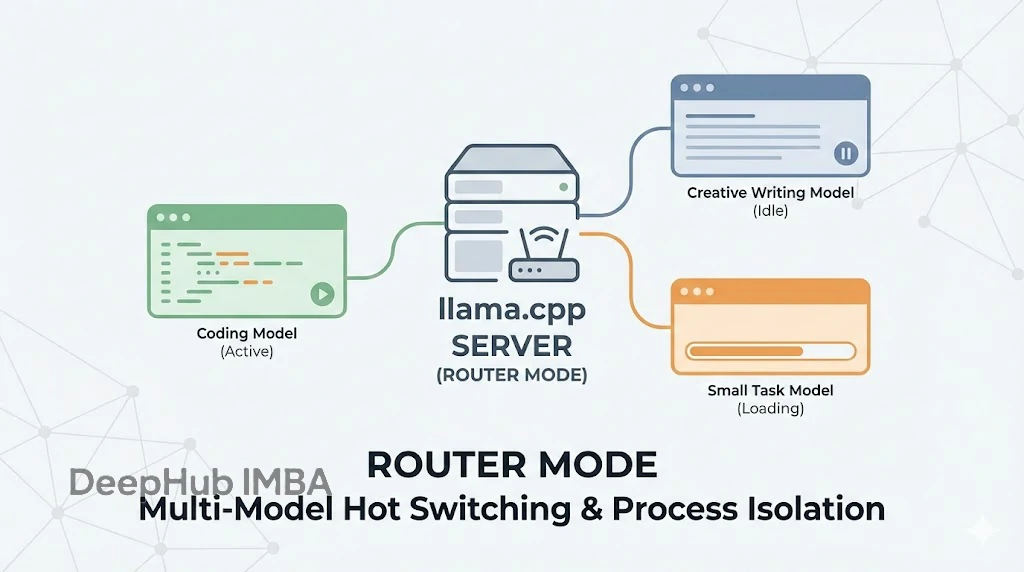
路由模式的核心機制
簡單來説,router mode 就是一個內嵌在 llama.cpp 裏的模型管理器。
以前跑 server,啓動時需要指定一個模型,服務就跟這個模型綁定了。要想換模型?要麼停服務、改參數、重啓,要麼直接啓動多個服務,而現在的路由模式可以動態加載多個模型、模型用完後還可以即時卸載,並且在不同模型間毫秒級切換,最主要的是全過程無需重啓服務,這樣我們選擇一個端口就可以了。
這裏有個技術細節要注意:它的實現是多進程的(Each model runs in its own process)。也就是説模型之間實現了進程級隔離,某個模型如果跑崩了,不會把整個服務帶崩,其他模型還能正常響應。這種架構設計對穩定性的考慮還是相當周到的。
啓動配置與自動發現
啓用方式很簡單,啓動 server 時不要指定具體模型即可:
llama-server
服務啓動後會自動掃描默認緩存路徑(LLAMA_CACHE 或 ~/.cache/llama.cpp)。如果你之前用 llama-server -hf user/model 這種方式拉取過模型,它們會被自動識別並列入可用清單。
但是我們一般會把模型存放在特定目錄,指定一下就行:
llama-server --models-dir /llm/gguf這個模式不僅是“能加載”那麼簡單,它包含了一套完整的資源管理邏輯:
- Auto-discovery(自動發現):啓動即掃描指定目錄或緩存,所有合規的 GGUF 文件都會被註冊。
- On-demand loading(按需加載):服務啓動時不佔滿顯存,只有當 API 請求真正過來時,才加載對應模型。
- LRU eviction(LRU 淘汰):可以設置最大駐留模型數(默認是 4)。當加載新模型導致超出限制時,系統會自動釋放那個最近最少使用的模型以騰出 VRAM。
- Request routing(請求路由):完全兼容 OpenAI API 格式,根據請求體中的
model字段自動分發流量。
調用實測
通過 API 調用特定模型,如果該模型未加載,首個請求會觸發加載過程(會有冷啓動延遲),後續請求則是熱調用。
curl http://395-1.local:8072/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf",
"messages": [{"role": "user", "content": "打印你的模型信息"}]
}'
查看模型狀態
這對於監控服務狀態很有用,能看到哪些模型是 loading,哪些是 idle。
curl http://395-1.local:8072/models
手動資源管理
除了自動託管,也開放了手動控制接口:
加載模型:
curl -X POST http://395-1.local:8072/models/load \
-H "Content-Type: application/json" \
-d '{"model": "Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-GGUF/Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-00001-of-00003.gguf"}'
卸載模型:
curl -X POST http://395-1.local:8072/models/unload \
-H "Content-Type: application/json" \
-d '{"model": "Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-GGUF/Qwen3-Next-80B-A3B-Instruct-1M-MXFP4_MOE-00001-of-00003.gguf"}'
常用參數與全局配置
這幾個參數在路由模式下使用頻率很高:
--models-dir PATH: 指定你的 GGUF 模型倉庫路徑。--models-max N: 限制同時駐留顯存的模型數量。--no-models-autoload: 如果不想讓它自動掃描目錄,可以用這個關掉。
比如下面這個啓動命令,設定了全局的上下文大小,所有加載的模型都會繼承這個配置:
llama-server --models-dir ./models -c 8192
進階:基於預設的配置
全局配置雖然方便,但是不同的模型有不同的配置方案,比如你想讓 Coding 模型用長上下文,而讓寫作模型一部分加載到cpu中。
這時候可以用 config.ini 預設文件:
llama-server --models-preset config.ini配置文件示例:
[oss120]
model = gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf
ctx-size = 65536
temp = 0.7
這樣就能實現針對特定模型的精細化調優
同時官方自帶的 Web 界面也同步跟進了。在下拉菜單裏直接選模型,後端會自動處理加載邏輯,對於不想寫代碼測試模型的人來説也很直觀。
總結
Router mode 看似只是加了個多模型支持,實則是把 llama.cpp 從一個單純的“推理工具”升級成了一個更成熟的“推理服務框架”。
不僅是不用重啓那麼簡單,進程隔離和 LRU 機制讓它在本地開發環境下的可用性大幅提升。對於那些要在本地通過 API 編排多個模型協作的應用(Agent)開發來説,這基本是目前最輕量高效的方案之一。