

視頻作為一種富含信息且密集的媒介,已廣泛應用於娛樂、社交媒體、安全監控和自動駕駛等領域。人類能夠輕鬆理解視頻內容,例如理解因果關係、定位特定時刻以及關聯動作。
但是人工智能,尤其是大型語言模型(LLM)及其多模態(MLLM)變體,在視頻理解方面仍然面臨挑戰,尤其是在處理長視頻時。儘管像 GPT-4V 或 Claude 這樣的模型可以詳細描述圖像或短片,但在需要根據長序列中特定時間間隔推斷事件時,它們往往表現不佳。它們雖然可以提供籠統的總結,但難以精確定位事件發生的時刻,或理解事件之間的因果關係。標準的 Chain-of-Thought (CoT) 技術在基於文本的推理中表現出色,但在需要將“思考”與精確時間相關聯的視覺證據時,會遇到困難。
視頻不僅僅是一系列靜態圖像,它還包含一個至關重要的時間維度。理解視頻不僅需要識別“正在發生什麼”,還需要識別“何時發生”、“持續多久”以及“與什麼相關”。當前的 MLLM 通常通過抽樣幀來處理視頻,這可能會錯過關鍵時刻或難以在較長時間內保持上下文。它們缺乏一種強大的時間定位機制,無法將推理和答案明確地鏈接回視頻中特定的、可驗證的時間段。
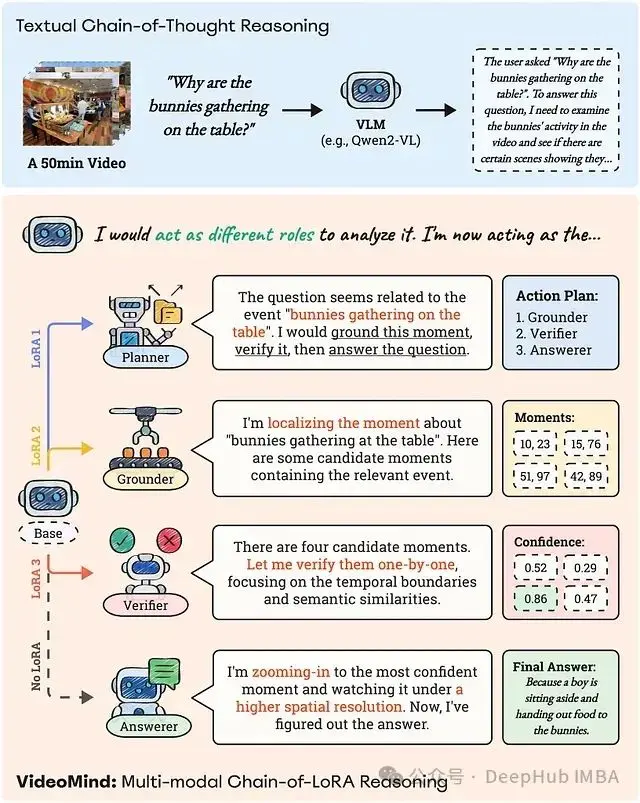
圖 1:VideoMind 的 Chain-of-LoRA 推理策略應用於一個 50 分鐘長視頻的複雜問題。問題由 Planner 分解,並分發給 Grounder、Verifier 和 Answerer,以系統地定位、驗證和解釋相關的視頻時刻。與純文本 CoT 過程相比,這種基於角色的管道能夠實現更像人類的視頻推理。
VideoMind 是一種專為應對長視頻中時間定位理解挑戰而設計的新型視頻語言代理。它不僅“觀看”視頻,還“分析”視頻,採用一種結合了專門角色和名為 Chain-of-LoRA 的創新技術的策略。
本文將深入探討 VideoMind,分析其克服的侷限性,剖析其獨特的代理工作流程,揭示 Chain-of-LoRA 機制,介紹其採用的專業 AI“角色”,評估其性能,並討論其對 AI 發展的更廣泛影響。
時間盲點:長視頻為何使 AI 模型失效
試圖通過觀看隨機快照或閲讀沒有提及關鍵事件發生時間的文本摘要來理解複雜電影的情節,可能會導致對情節的模糊理解,並錯過細微之處和因果關係。這類似於當前許多 AI 模型在處理長視頻時遇到的困難。
以下是導致這種“時間盲點”的核心挑戰:
數據量巨大: 長視頻包含大量信息,處理每一幀在計算上是不可行的。模型通常採用抽樣幀的方法,但這可能會錯過關鍵事件,例如體育比賽中快速的動作或改變對話含義的表情。
長程上下文維護: Transformer 架構是大多數 LLM/MLLM 的基礎,但在處理極長序列時存在侷限性,因為計算複雜度高。儘管稀疏注意力和線性 Transformer 等技術有所幫助,但在幾十分鐘或幾小時內保持精確的時間關係和依賴性仍然困難。模型可能會忘記之前發生的事情,或難以將相隔很長時間的事件聯繫起來。
精確對齊需求: 與回答整個圖像相關的圖像問答不同,視頻問答通常需要精確定位事件發生的時間。例如,對於問題“這個人什麼時候踩到香蕉皮滑倒的?”,籠統的答案“這個人摔倒了”是不夠的,答案需要與特定的時間戳或時間間隔對齊。
文本 CoT 的侷限性: Chain-of-Thought 推理可以幫助 LLM 逐步分解複雜的問題。將其直接應用於視頻通常會導致一個純粹的文本推理鏈,而該鏈並沒有明確地鏈接回時間上的視覺證據。模型可能推斷出兔子聚集在一起的原因,但難以説明“我得出這個結論是因為我觀察到男孩在 [X, Y] 時間段分發食物”,因為它缺乏可靠地找到該時間段的機制。
模糊性和細微差別: 視頻通常包含多個類似事件的發生,或需要仔細觀察才能正確解釋的事件。模型可能會找到兔子聚集的一個時刻,但它是否是用户詢問的相關時刻?這需要不僅找到潛在的時刻,還要驗證它們的關聯性和準確性。
這些挑戰表明,簡單地擴大現有 MLLM 的規模或應用標準的推理技術,對於需要深入的時間定位的視頻理解任務來説,通常會產生不理想的結果。因此,需要一種從根本上不同的方法,明確地處理時間維度,並模仿人類使用的分析過程。
VideoMind:一種模仿人類視頻理解的 AI 代理
VideoMind 採用一種具有四個不同角色的代理工作流程來實現視頻理解:
- Planner(計劃者): 協調員,負責分析用户查詢,並確定回答查詢的最佳行動順序,以有效地回答問題。
- Grounder(定位器): 時間定位器,負責根據文本描述(由 Planner 或原始查詢提供)精確地定位視頻中的相關時刻或時間間隔。
- Verifier(驗證器): 事實核查員,負責獲取 Grounder 識別出的候選時刻,並仔細檢查它們,以確認它們的準確性和相關性。
- Answerer(回答者): 溝通者,基於經過驗證的證據(特定的視頻片段),生成對用户問題的最終答案。
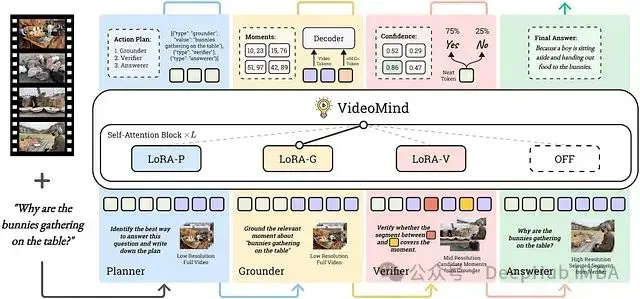
圖 2:VideoMind 的整體工作流程。給定一個視頻和一個查詢,VideoMind 自適應地激活不同的角色(在本例中為 Planner → Grounder → Verifier → Answerer),並通過調用各個模塊執行逐步推理。
這種基於角色的方法允許每個組件高度專業化,並針對其特定的子任務進行優化。Planner 確保靈活性,根據查詢的性質調整工作流程。Grounder 專注於時間定位,而 Verifier 則專注於準確性檢查。
VideoMind 的核心創新在於 Chain-of-LoRA,它能夠在沒有運行四個獨立的、大型 AI 模型開銷的情況下高效地實現這些角色的協作。
Chain-of-LoRA:技術詳解
Chain-of-LoRA 採用類似於多功能工具的 AI 模型原理。它使用一個可以接受各種輕量級附件的單一多功能手柄,而不是攜帶一個裝滿笨重工具的工具箱。
LoRA 簡介
LoRA(Low-Rank Adaptation,低秩適應)是一種用於微調大型預訓練模型(如 LLM 或 MLLM)的技術。LoRA 不是重新訓練模型中所有參數,而是在原始模型的特定層(通常是注意力層)中注入少量新的、可訓練的參數,這些參數採用低秩矩陣的形式。原始模型權重保持凍結,僅更新這些小的 LoRA 適配器。這降低了計算成本、縮短了訓練時間,並減少了存儲需求。
Chain-of-LoRA 詳解
VideoMind 利用 LoRA 的效率,併為其代理工作流程中的不同角色(Planner、Grounder、Verifier)訓練單獨的適配器。所有這些角色都在同一個基礎 MLLM 上運行(在論文的實現中,具體來説是 Qwen2-VL)。
以下是 Chain-of-LoRA 在推理期間的工作方式:
基礎模型: VideoMind 從預訓練的 Qwen2-VL 模型開始。
角色激活: 當需要特定角色時(由 Planner 確定),其相應的預訓練 LoRA 適配器會被動態“激活”或“插入”到基礎模型的層中。
專業處理: 基礎模型現在由活動角色的 LoRA 適配器增強,執行該角色的專業功能(例如,Grounder LoRA 幫助模型專注於時間定位)。
角色切換: 當工作流程需要下一個角色時,先前的 LoRA 適配器會被停用,而新角色的適配器會被激活。這種切換是無縫的,並且計算成本很低。
執行鏈: 這種動態激活和切換會按照計劃繼續進行,形成“Chain-of-LoRA”執行流程。
Chain-of-LoRA 的優勢
效率: 避免了為每個角色加載和運行多個不同的大型模型的計算和內存開銷,以最少的額外參數實現了功能專業化。消融研究表明,Chain-of-LoRA 以與單個基礎模型相同的低內存佔用(4.2G)實現了最佳性能,而使用單獨模型的分佈式方法需要更多的內存(16.6G)。
靈活性: Planner 可以根據查詢動態地以不同的順序鏈接角色,從而動態地調整推理過程。
有效性: 允許使用其專門的 LoRA 適配器微調每個角色,優化每個子任務(計劃、定位、驗證)的性能,而不是試圖讓單個模型同時完成所有任務或僅僅依賴於文本 CoT。
極簡主義: 通過巧妙地調整單個核心模型來實現複雜的行為。
Chain-of-LoRA 是架構支柱,它以高效和有效的方式實現了 VideoMind 複雜的、多步驟推理過程。它有力地證明了輕量級自適應技術如何能夠釋放大型模型中複雜的代理行為。
VideoMind 的角色詳解
下面將更仔細地瞭解 VideoMind 代理中的每個專業角色。
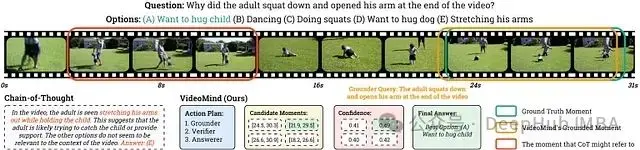
圖 3:VideoMind 工作流程的可視化。Planner 首先確定對函數調用的需求,並使用 Grounder 生成多個候選時刻。然後,它應用 Verifier 來選擇最相關的視頻片段(以黃色突出顯示)。放大後,該片段將傳遞給 Answerer。通過鏈接 Grounder、Verifier 和 Answerer 角色,VideoMind 可以準確定位關鍵時刻並選擇正確的答案,從而避免了來自不正確片段的混淆(紅色框)。
Planner(計劃者):協調分析
充當中央協調員,理解用户的查詢,並通過決定調用哪些角色以及以什麼順序調用來制定最佳執行計劃。
工作方式:
- 將視頻和用户的文本查詢作為輸入。
- 分析查詢以確定所需的功能,例如是否需要定位或驗證。
- 輸出一個計劃,該計劃被制定為 JSON 動作列表。該論文確定了三個主要計劃:- [Grounder, Verifier, Answerer]:對於在回答之前需要精確定位和驗證的複雜查詢(例如,“當嬰兒哭泣時,男孩在做什麼?”)。- [Grounder, Verifier]:對於答案是時間戳的時刻檢索任務(例如,“女人什麼時候下樓?”)。- [Answerer]:對於不需要特定時刻定位的簡單問題(例如,“總結此視頻”)。
- 查詢改寫: 如果原始查詢含糊不清或缺乏有效定位的細節,Planner 可以將其改寫為更適合 Grounder 的描述性查詢。這是使用 GPT-40 mini 訓練的,以生成查詢改寫對。
訓練: 使用其特定的 Planner LoRA 適配器進行微調,使用從 NExT-QA 和 QVHighlights 等數據集中重新利用的數據,將問題映射到適當的計劃和潛在的改寫。
Grounder(定位器):精確定位時間點
核心時間定位引擎,給定文本描述(查詢),識別視頻中相應事件的開始和結束時間戳。
工作方式(技術細節):
- 時間戳解碼器頭: 一個自定義解碼器頭構建在基礎 MLLM 功能之上,不依賴於 LLM 的文本生成功能來獲取時間戳。
- 特殊 Token <REG>: 引入了一個特殊 token <REG>,當 LLM 生成此 token 時,它會發出執行定位的信號。
- 特徵提取: 與 <REG> token(表示查詢)和視覺 token(表示視頻幀)關聯的隱藏狀態從 MLLM 的最後一層提取。
- 時間特徵金字塔: 視覺特徵通過 1D 卷積金字塔處理,以捕獲多個時間分辨率的信息,創建視頻時間動態的多尺度表示。
- 集成與解碼: 查詢特徵和多尺度視頻特徵(以及模態和位置嵌入)被饋送到 Transformer 解碼器中。
- 密集預測頭: 兩個頭對輸出進行操作:- 分類頭: 預測幀級別置信度分數(此幀是否在目標時刻內?),使用二元焦點損失進行優化。- 迴歸頭: 預測從每幀到目標時刻的開始和結束邊界的偏移量,使用 L1 損失進行優化。
- 對比損失: 鼓勵在目標時刻內的幀的特徵比在時刻外的幀的特徵更類似於查詢特徵,從而改善對齊。
訓練: Grounder LoRA 適配器和時間戳解碼器在各種時間定位數據集(QVHighlights、DiDeMo、TACOS 等)的集合上一起訓練。
圖 4:VideoMind 的監督微調數據集。計劃數據集是從 NExT-QA 和 QVHighlights 重新利用的。驗證數據集是從預訓練的 Grounder 的預測生成的。mr 和 step 分別表示 HiREST 的時刻檢索和步驟定位子集。
採用這種方法的原因: 與依賴於可能脆弱的時間戳字符串的文本生成相比,直接從豐富的視覺和查詢特徵解碼時間戳可以實現更精確和魯棒的定位。多尺度金字塔有助於處理不同持續時間的事件。
Verifier(驗證器):通過仔細觀察確保準確性
充當質量控制步驟,評估 Grounder 提出的候選時刻,並選擇最準確和相關的時刻。
工作方式:
- Top-N 候選: 接收來自 Grounder 的前 N 個候選時刻。
- 通過放大進行回顧: 對於每個候選時刻:- 擴展: 時間邊界略有擴展。- 裁剪: 視頻在時間上被裁剪為此擴展的片段。- 提高分辨率: 可能會提高此裁剪片段中幀的空間分辨率。- 這種“放大”使 Verifier 能夠以更高的保真度和更多的周圍上下文檢查關鍵時刻。
- 布爾判斷: 放大後的視頻片段和原始查詢被饋送到 Verifier,要求它判斷此片段是否完美地覆蓋查詢的時刻。特殊 token(<SEG_START>、<SEG_END>)被插入到視覺 token 序列中,以明確標記擴展片段中原始提議的邊界,從而增強邊界意識。Verifier 輸出“是”或“否”。
- 評分和選擇: 該模型計算生成 <Yes> token (Ly) 和 <No> token (Ln) 的可能性。候選者的置信度分數為 Sigmoid(Ly — Ln)。選擇具有最高置信度分數的候選時刻作為最終定位的時刻。
訓練: Verifier LoRA 在通過獲取 Grounder 在其訓練集上的預測並根據它們與真實時間戳的 Intersection-over-Union (IoU) 將它們標記為“是”或“否”來生成的數據上進行微調。
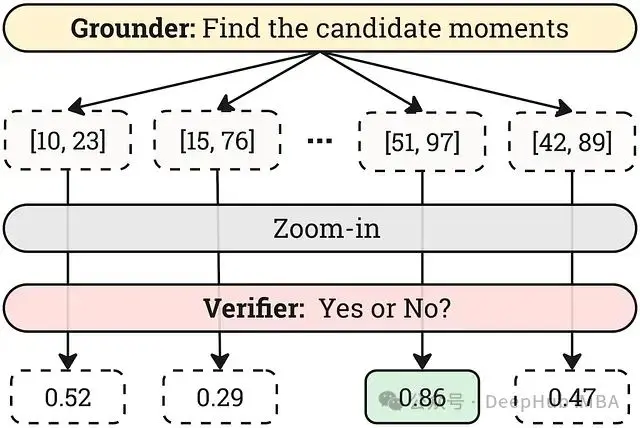
圖 5:Grounder 生成多個候選時刻,然後通過應用放大策略並由 Verifier 評估來優化這些時刻,以選擇最佳時刻。
Answerer(回答者):傳達發現
生成對原始查詢的最終答案。
工作方式:
- 接收由 Verifier 識別的經過驗證的視頻片段(如果 Planner 確定不需要定位,則接收整個視頻)。
- 接收原始用户查詢。
- 直接使用基礎預訓練的 MLLM (Qwen2-VL),沒有任何特定的 Answerer LoRA 或進一步的微調。
- 根據提供的視覺證據生成自然語言答案。
沒有 LoRA 的原因: 假設是,當提供正確的視覺上下文時,基礎 MLLM 已經非常擅長問答。其他角色解決的關鍵挑戰是查找和驗證該上下文。
通過 Chain-of-LoRA 機制結合這些專業角色,VideoMind 實現了一個複雜的推理過程,該過程直接解決了長視頻中時間定位的挑戰。
VideoMind 的性能評估
VideoMind 研究人員在 14 個不同的公共基準上進行了實驗,涵蓋了視頻理解任務的三個主要類別:
- Grounded Video Question-Answering (Grounded VideoQA): 需要回答問題並提供特定時間間隔作為證據的任務。
- Video Temporal Grounding (VTG): 專注於定位文本查詢描述的時刻的任務。
- General Video Question-Answering (General VideoQA): 標準視頻 QA 任務,通常在較長的視頻上進行,其中時間理解仍然有益。
實驗結果表明:
- 最先進的性能: VideoMind 在所有三個類別中的眾多基準上都實現了 SOTA 結果。
- 在長視頻定位中的優勢: 在具有挑戰性的長視頻定位 QA 基準(如 CG-Bench)上,VideoMind 明顯優於以前的開源模型。值得注意的是,VideoMind 的 7B 參數版本超過了更大的閉源 GPT-4o 的定位性能,甚至輕量級 2B VideoMind 模型在定位指標方面也與許多更大的模型具有競爭力或更好。
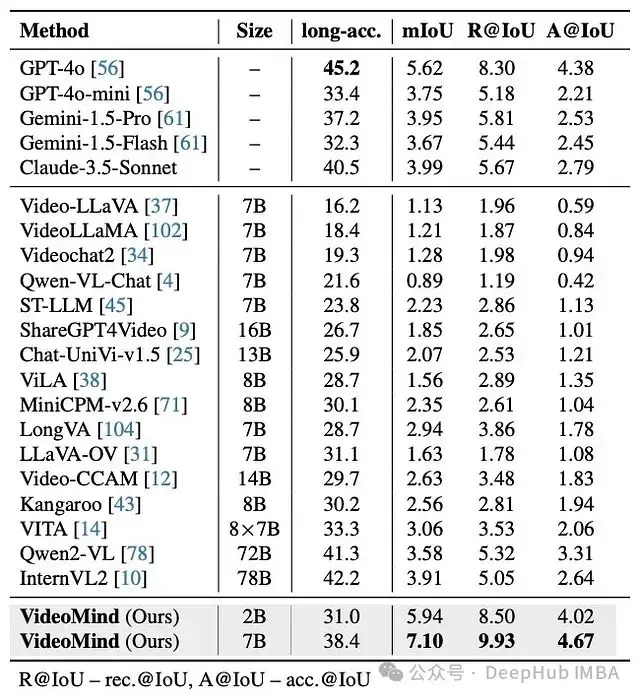
圖 6:CG-Bench 上的 Grounded VideoQA。儘管尺寸較小,但 VideoMind 在這個具有挑戰性的長視頻基準上超過了 GPT-4o 和開源基線。
- 強大的泛化能力: 在 ReXTime 上,VideoMind 展示了出色的零樣本性能,優於其他零樣本模型,甚至超過了已在該任務上進行微調的幾個模型。
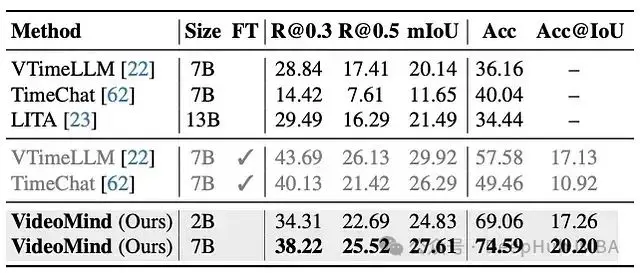
圖 7:ReXTime 上的 Grounded VideoQA。FT 表示是否在下游訓練集上進行了微調。VideoMind 展示了強大的泛化能力;其零樣本分數優於所有零樣本基線,並超過了微調變體。
- 零樣本時間定位能力: 當僅在時間定位任務上進行評估時,VideoMind 的 Grounder 和 Verifier 組合實現了令人印象深刻的零樣本結果,超過了許多基於 LLM 的專用定位方法,並且接近在這些數據集上明確微調的專家的性能。
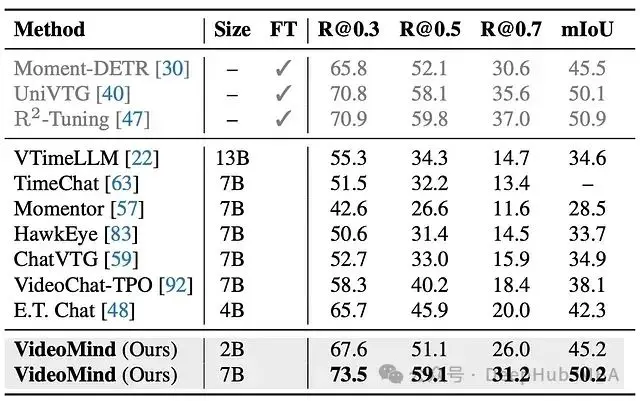
圖 8:CharadesSTA 上的零樣本視頻時間定位。VideoMind 明顯優於同類產品。
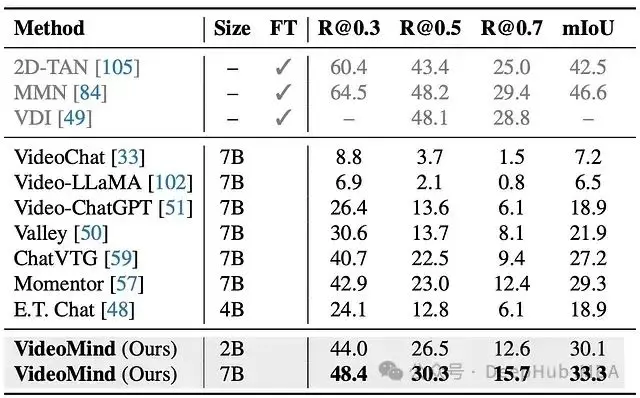
圖 9:ActivityNetCaptions 上的零樣本視頻時間定位。VideoMind 優於基於 LLM 的方法。
- 提升通用 VideoQA: 即使在通用 VideoQA 基準上,與其他 MLLM 相比,VideoMind 也表現出卓越的性能。
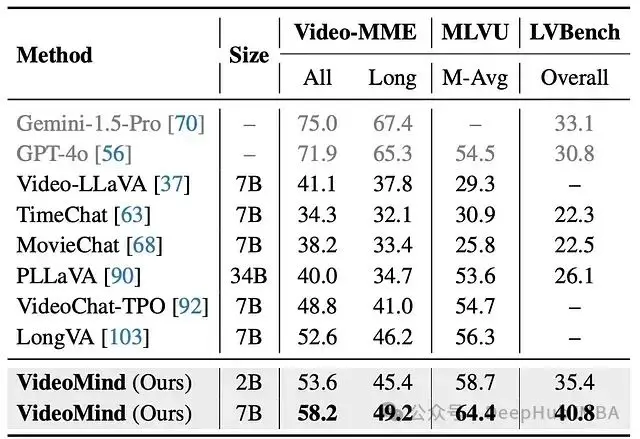
圖 10:Video-MME、MLVU 和 LVBench 上的 VideoQA。VideoMind 在長視頻上表現出卓越的性能。
- 效率驗證: 消融研究證實,Chain-of-LoRA 方法在提供最佳性能的同時,還具有很高的內存效率,明顯優於樸素 CoT 或在單個模型上的標準多任務訓練,並且與更重的分佈式模型設置的性能相匹配。
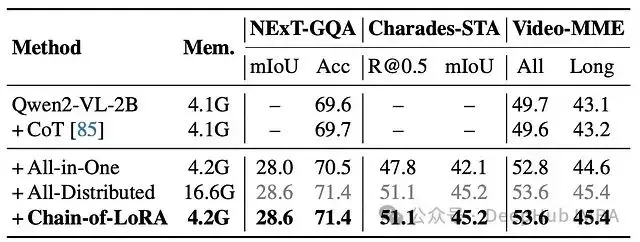
圖 11:用於研究具有不同角色集成的測試時間策略的關鍵消融,包括基礎模型、使用文本 CoT 的版本以及集成多個角色的三種實現。Mem. 表示 GPU 內存使用情況。值得注意的是,Chain-ofLoRA 以最小的內存成本實現了最佳性能。
這些結果表明,VideoMind 的代理工作流程和 Chain-of-LoRA 策略對於解決視頻中時間推理的細微差別非常有效,尤其是在以前的模型難以處理的長時間內。
技術細節
時間戳解碼器
- 輸入: 採用 <REG> token (hr) 的 1 x D 維隱藏狀態和幀 token (hv,在 1D 池化到 T x DL 之後) 的 T x D 維隱藏狀態。
- 投影: 線性層 Er 和 Ev 將這些投影到維度 D。
- 集成 Transformer: 在將可學習的模態嵌入 (mr, mv) 和正弦位置編碼 (ep) 添加到幀嵌入後,將投影的查詢嵌入 (er) 和幀嵌入 (ev) 連接起來。此組合序列 [ev + mv + ep; er + mr] 通過標準 Transformer 編碼器饋送。
- 時間特徵金字塔: 輸出幀嵌入 (e’v) 通過並行 Conv1D-LayerNorm-SiLU 塊傳遞。每個級別應用步幅為 2 的卷積,有效地將時間分辨率下采樣 2。使用 4 個級別創建以 T、T/2、T/4 和 T/8 分辨率捕獲動態的特徵。
- 連接和預測: 來自所有金字塔級別的特徵沿時間維度連接成長度為 L = T + T/2 + T/4 + T/8 的單個序列 p。此組合特徵圖被饋送到分類 (CLS) 和迴歸 (REG) 頭。- CLS 頭: 兩個 Conv1D 層 + Sigmoid,輸出幀級別置信度 ĉi。損失:二元焦點損失。- REG 頭: 兩個 Conv1D 層 + 指數激活,輸出每幀的開始/結束邊界偏移量 [bi_s, bi_e]。損失:L1 損失。
- 對比損失: 計算上下文查詢嵌入 (e’r) 和所有上下文幀嵌入 (e’v) 之間的餘弦相似度。使用 InfoNCE 損失將正幀特徵(在真實值內)拉近到查詢特徵,而不是負幀特徵。L = Lcls + Lreg + Lcon。
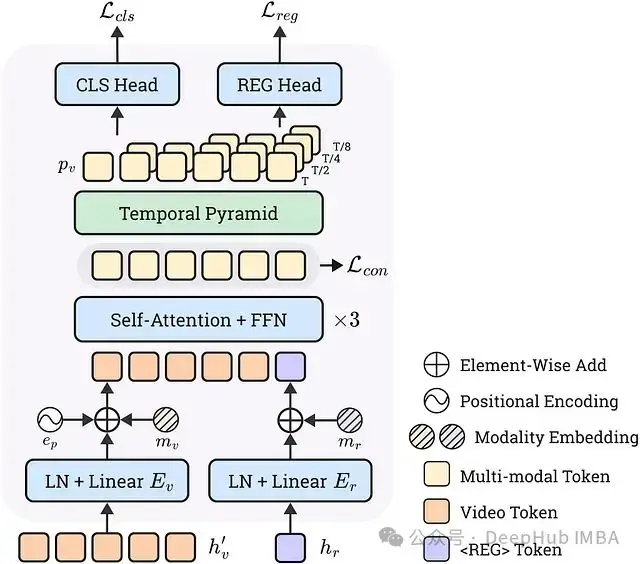
圖 12:時間戳解碼器的詳細架構。此模塊接受幀 token 和 <REG> token 的隱藏狀態,將它們解碼為開始和結束時間戳。
驗證器的評分
驗證器使用以下公式計算置信度分數:Score = Sigmoid(Ly — Ln)。此分數衡量了模型對該特定候選時刻的“是”的置信度比“否”高多少。
Chain-of-LoRA 實現
該機制涉及為 Planner、Grounder 和 Verifier 角色的基礎 Qwen2-VL 模型的層訓練單獨的 LoRA 權重(適配器矩陣)。
def videomind_inference(video V, query Q):
# 1. Planning (using Planner LoRA)
plan = Planner.generate_plan(V, Q) # e.g., ["grounder", "verifier", "answerer"]
rephrased_query = plan.get_rephrased_query_if_any(Q) # Optional
grounded_moment = None
verified_segment = V # Default to whole video
# 2. Grounding (if needed)
if "grounder" in plan:
# Activate Grounder LoRA
candidate_moments = Grounder.localize_moments(V, rephrased_query or Q) # List of [ts, te]
# Deactivate Grounder LoRA
# 3. Verification (if needed)
if "verifier" in plan:
# Activate Verifier LoRA
best_moment_index = -1
best_score = -1
scores = []
zoomed_segments = []
for i, moment in enumerate(candidate_moments):
# Apply Recap-by-ZoomIn
zoomed_segment_i = Verifier.zoom_in(V, moment)
zoomed_segments.append(zoomed_segment_i)
# Get Yes/No likelihoods and calculate score
score_i = Verifier.calculate_confidence(zoomed_segment_i, Q, moment)
scores.append(score_i)
if score_i > best_score:
best_score = score_i
best_moment_index = i
grounded_moment = candidate_moments[best_moment_index]
verified_segment = zoomed_segments[best_moment_index]
# Deactivate Verifier LoRA
# 4. Answering (if needed)
final_answer = "Grounding complete." # Default if no answerer
if "answerer" in plan:
# Use BASE MLLM (no specific LoRA)
final_answer = Answerer.generate_answer(verified_segment, Q)
return final_answer, grounded_moment總結
VideoMind 通過結合受人類啓發的代理工作流程與 Chain-of-LoRA 技術,使 AI 模型具備了計劃、定位、驗證和解釋基於特定視頻時刻的事件所需的專業技能。
VideoMind 推動了多模態 AI 的發展,為構建更復雜、高效和上下文感知的系統提供了藍圖。
https://avoid.overfit.cn/post/8155100cbbd041e28439d64974789287