

大過節的qwen發佈了image 2512,DeepSeek這邊就偷摸的在arXiv 上掛出了這篇 mHC: Manifold-Constrained Hyper-Connections (arXiv:2512.24880),哪個正經公司在最後一天還發論文啊。
簡單的看了一下,説説我的看法: 這回DeepSeek又要對 殘差連接(Residual Connection)出手了。
現在我們模型的底層架構就是疊 Transformer Block,而過去這十年,對於每一層的堆疊,愷明大神的 ResNet 也就是那個 y=x+f(x),幾乎行業的“公理”。它通過 Identity Mapping(恆等映射),可以讓信號能無損傳下去,梯度也能無損傳上來,這就保證了咱們能把模型堆到幾百上千層還不崩。
但 DeepSeek 團隊之前(大概是去年 9 月那會兒)提了個 Hyper-Connections (好像看的人不多,我當時沒太注意這個) 的概念,覺得簡單的相加太浪費了就搞了個更復雜的連接方式來擴寬層間的信息通路。但是一旦你動了那個“相加”,Identity 的屬性就沒了,梯度傳播就開始不穩定,這樣訓練起來特別容易炸他們管這叫 Seesaw Effect(蹺蹺板效應)。
這篇 mHC 就是來填這個坑的,咱們順着邏輯拆解一下。
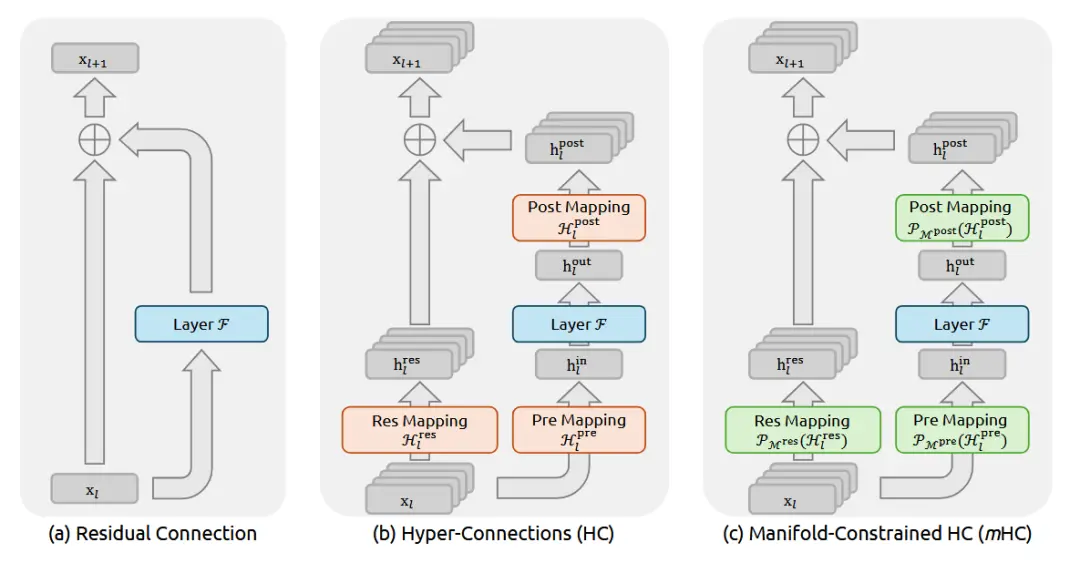
這就引出了 mHC 的核心:流形約束(Manifold Constraint)。
別被這數學名詞嚇着:之前的 HC 是想讓連接權重隨便長,結果就長歪了;現在的 mHC 就是給這些權重矩陣加了個限制。DeepSeek 在數學上證明了,如果把這些超連接的權重矩陣強制投影到一個特定的流形空間裏就能在保留 HC 那種高帶寬、多通路優勢的同時,還把 Identity Mapping 的屬性給找補回來。
也就是説他們在數學層面上造了一個“既要有又要”的結構:既要連接方式足夠複雜多變,能捕捉更高級的特徵交互;又要信號傳播像 ResNet 一樣順滑,不至於在深層網絡裏迷路。
這裏的“流形”具體由兩個關鍵的數學性質構成:
第一是 譜範數約束(Spectral Norm Constraint),他們強制要求連接矩陣的譜範數 ∥W∥2≤1。這在動力系統裏叫“非擴張”(Non-expansive)。只有當矩陣的最大奇異值被摁在 1 附近,信號能量在深層傳播時才不會發散。
第二是 雙重隨機矩陣(Doubly Stochastic Matrices), 這是一類行和、列和都為 1 的非負矩陣。這玩意兒有個極好的代數性質叫 閉包性(Compositional Closure)。兩個雙重隨機矩陣乘起來它還是雙重隨機的,所以這就保證了無論網絡堆多深,整體的變換性質不變。更重要的是,這讓每一層的輸出變成了上一層的 凸組合(Convex Combination),從根本上恢復了訓練的穩定性。
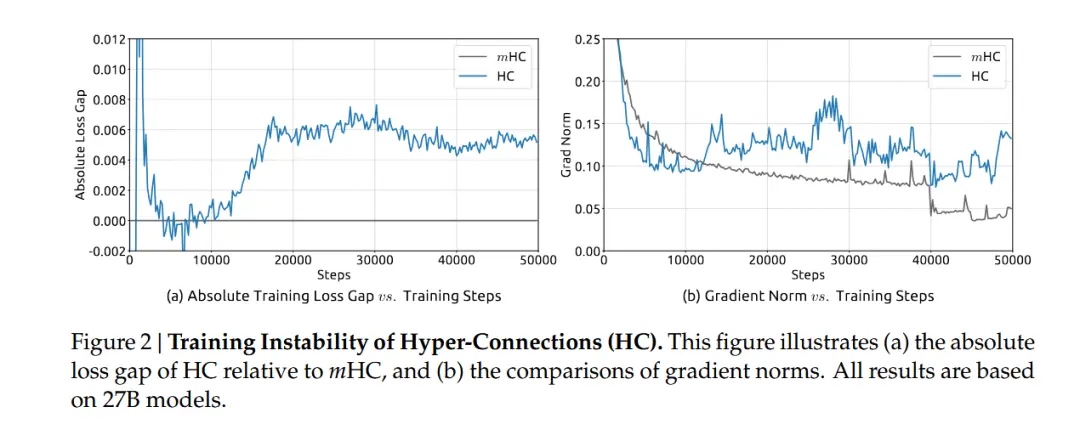
並且論文裏面包含了很強的理論推導,對於信號傳播(Signal Propagation)的分析非常紮實,直接指出了為什麼之前的架構在超深層會遇到瓶頸,而 mHC 是怎麼通過約束奇異值分佈來解決這個問題的。(ps:DeepSeek 的日子也是好起來了,做實驗都敢用27B的模型了,HC那篇用的可以是7B的)
論文裏還有一段非常精彩的理論分析,是從 動態系統(Dynamical Systems) 的角度去看的。
如果你把層數看作時間步,深層網絡其實就是一個離散的動態系統。而且這篇論文證明了在流形約束下,這個系統的 Lyapunov 指數是受控的。他們通過一種類似 Projecting(投影)的手法,確保權重矩陣始終保持良好的 譜性質(Spectral Properties)。説的通俗點就是:不管怎麼更新,這些矩陣在數學性質上必須看起來像一個“稍微扭曲了一點點的 Identity Matrix”,而不是一個完全隨機的矩陣。
這就從理論上解釋了為什麼 mHC 可以堆疊到成百上千層而不崩塌,這部分其實是對現有架構理論的一個重要補充。以前我們只知道“加個殘差就好使”,現在 mHC 告訴我們:“只要你在流形上走路,哪怕姿勢複雜點,也不會摔倒”。
而且熟悉 DeepSeek 風格的朋友都知道,他們從來不只聊數學,還必須要聊 System Efficiency。
mHC 這個架構顯然是做過嚴格的 Infrastructure Optimization 的。如果只是理論上好使但拖慢了訓練速度,DeepSeek 是絕對不會用的。他們在論文裏也提到了這點,這種特殊的連接方式配合專門優化的 CUDA kernel,可以把額外的計算開銷壓縮到了幾乎可以忽略不計的程度。
這就很可怕了,等於是在算力成本幾乎不變的情況下,白嫖了模型表達能力的上限。在實際的大規模訓練吞吐上並沒有造成明顯的 overhead。
這對咱們行業意味着什麼?
我覺得這可能是“後 Transformer 時代”的一個重要信號。以前咱們擴模型,就是簡單粗暴地增加層數、增加寬度,屬於“堆料”。但 mHC 提示了一個新的方向:層與層之間的拓撲結構(Topology)本身,還有巨大的挖掘空間。
如果這種基於流形約束的連接方式被驗證能 scaling up 到萬億參數級別(論文説 671B 的 MoE 模型是ok的),那咱們以後設計大模型,可能就不再是簡單的搭積木而是要開始研究積木之間的粘合劑怎麼調配了。
mHC 的出現不僅修復了 Hyper-Connections 的缺陷,更重要的是它將深度學習架構設計的視角從單純的“連接圖”提升到了“參數流形”的高度。隨着基礎模型對效率和能力的要求日益嚴苛,mHC 所代表的幾何約束設計理念,極有可能成為未來幾年 AI 基礎設施的核心標準之一。
論文:
https://avoid.overfit.cn/post/51f0eb0654f744878511b56befd42a77