

斯坦福和SambaNova AI最近聯合發了一篇論文,Agentic Context Engineering (ACE)。核心思路:不碰模型參數,專注優化輸入的上下文。讓模型自己生成prompt,反思效果,再迭代改進。
可以把這個過程想象成模型在維護一本"工作手冊",失敗的嘗試記錄成避坑指南,成功的案例沉澱為可複用的規則。
數據表現
論文給出的數字:
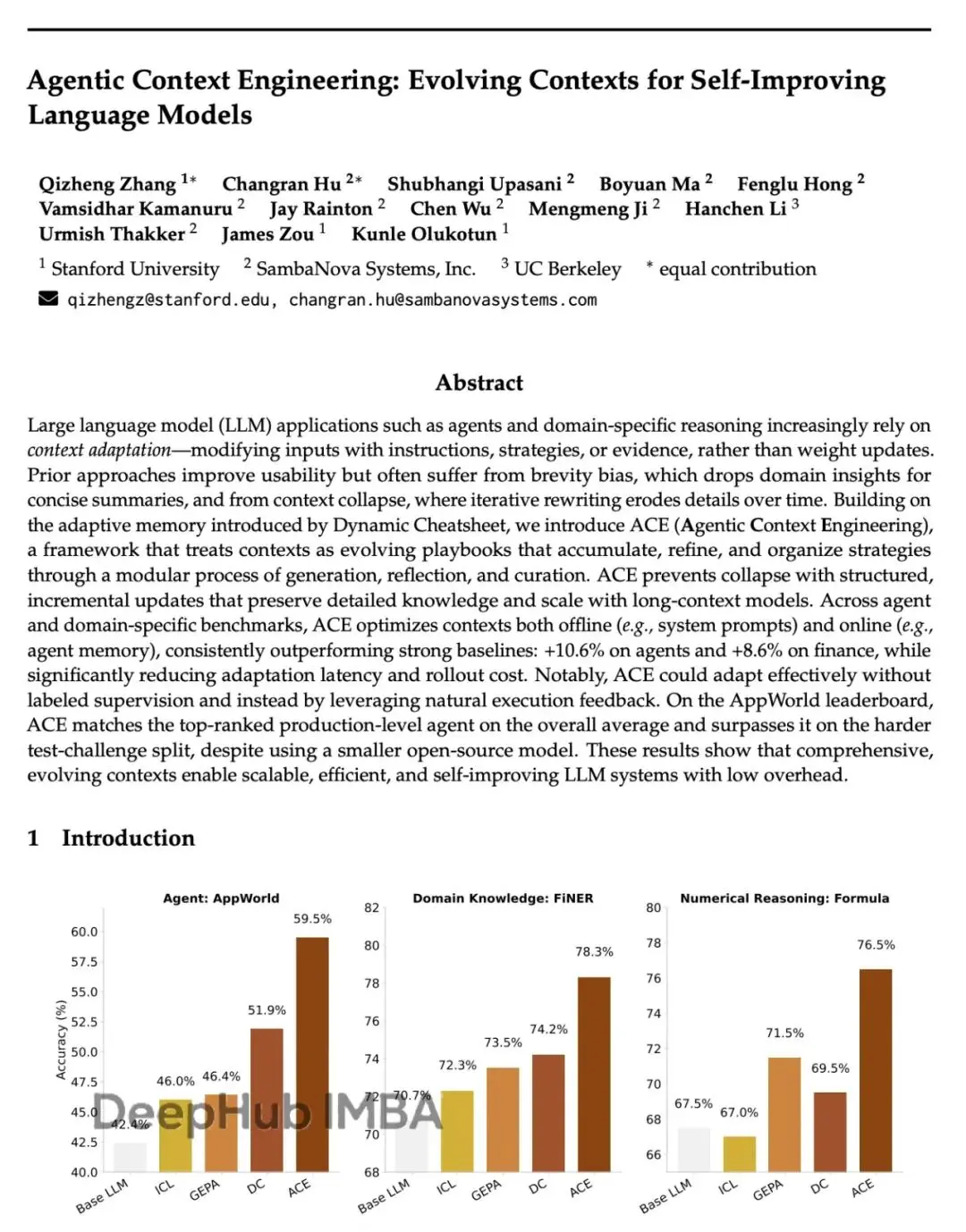
AppWorld任務準確率比GPT-4驅動的agent高10.6%
金融推理任務提升8.6%
成本和延遲降低86.9%
這個全程不需要人工標註,只靠反饋循環就能完成優化
有個違反常識的點:現在主流觀點都在追求簡潔prompt、精煉指令,ACE反倒構建了一個信息密集、持續增長的"操作手冊"。隨着時間推移,這個手冊會越來越厚,但有效性也在累積。大模型似乎並不需要簡潔——它們需要的是足夠的上下文密度。(我個人也覺得prompt不需要過於簡潔,要精練和提供足夠的信息)
ACE指向的方向是:可能我們過於關注模型本身,而忽略瞭如何更有效地與它對話。這不僅是技術層面的問題,也是思維方式的轉變。
論文技術細節
研究動機
基於LLM的AI應用,像LLM agent和複合AI系統,越來越依賴上下文適應 (context adaptation)。和修改模型權重不同,上下文適應直接在輸入中加入明確指令、結構化推理步驟或領域特定的格式來提升性能。
上下文在AI系統的很多組件中都是基礎:指導下游任務的system prompt,存儲歷史事實和經驗的memory,還有減少幻覺、補充知識的事實證據。
通過上下文而非權重來適應有幾個明顯優勢。上下文對用户和開發者來説可解釋、可理解,能在運行時快速整合新知識,還能在複合系統的不同模型或模塊之間共享。隨着長上下文LLM的進步,以及KV cache複用這類推理技術的發展,基於上下文的方法在工程部署上變得越來越可行。上下文適應正在成為構建強大、可擴展、自我改進AI系統的核心範式。
現有方法的兩個核心問題
儘管有進展,現有的上下文適應方法面臨兩個關鍵限制。
第一個是簡潔性偏差 (brevity bias)。很多prompt優化器優先考慮簡潔、通用的指令,而不是全面積累知識。比如GEPA就把簡潔當作優點,但這種抽象會丟失實踐中重要的領域啓發式、工具使用指南、常見失敗模式。這種設計在某些驗證指標上看起來合理,但往往抓不住agent和知識密集型應用需要的詳細策略。
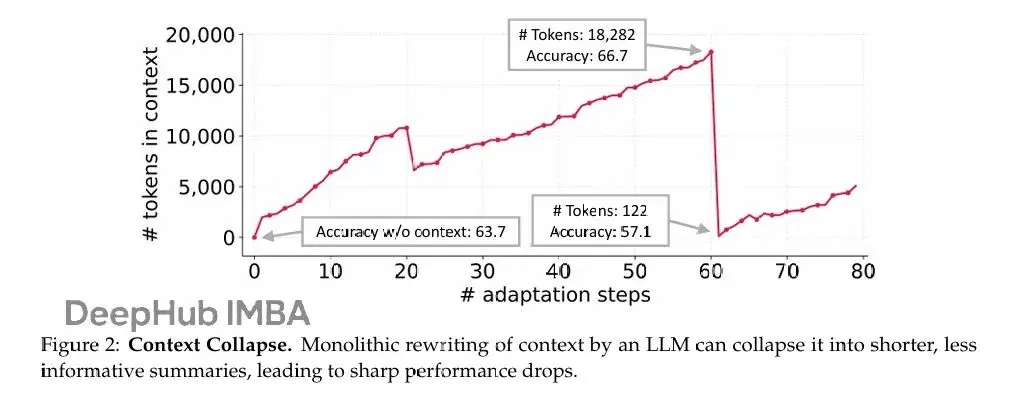
第二個是上下文崩潰 (context collapse)。依賴LLM整體重寫的方法常常隨時間退化成更短、信息更少的摘要,導致性能驟降(圖2)。在交互式agent、領域特定編程、金融或法律分析這些領域,強性能依賴於保留詳細的任務特定知識,而非壓縮它們。
論文在AppWorld benchmark上做了個實驗來觀察這個現象。當LLM被要求在每個適應步驟完全重寫累積的上下文時,上下文會發生崩潰。第60步時上下文有18,282個token,準確率66.7%,但下一步就崩潰到122個token,準確率掉到57.1%——比不適應的baseline 63.7%還差。雖然論文用Dynamic Cheatsheet舉例,但這不是那個方法特有的問題,而是用LLM端到端重寫上下文的根本風險——累積的知識可能突然被抹掉。
隨着agent和知識密集推理應用對可靠性要求越來越高,最近的工作轉向用豐富、詳細的信息填充上下文,這得益於長上下文LLM的進步。論文認為上下文不該是簡潔摘要,而應該是一個全面、演化的playbook——詳細、包容、充滿領域內容。不像人類受益於簡潔概括,LLM在提供長而詳細的上下文時更有效,能自主提煉相關性。與其壓縮掉領域特定的啓發式和策略,上下文應該保留它們,讓模型在推理時決定什麼重要。
ACE框架設計
針對這些限制,論文提出ACE (Agentic Context Engineering) 框架,用於離線場景(比如system prompt優化)和在線場景(比如測試時memory適應)的全面上下文適應。ACE不把上下文壓縮成精煉摘要,而是把它們當作隨時間累積和組織策略的演化playbook。
基於Dynamic Cheatsheet的agentic架構,ACE加入了generation、reflection和curation的模塊化工作流,同時添加了由grow-and-refine原則指導的結構化增量更新。這個設計保留詳細的領域特定知識,防止上下文崩潰,產生的上下文在整個適應過程中保持全面和可擴展。
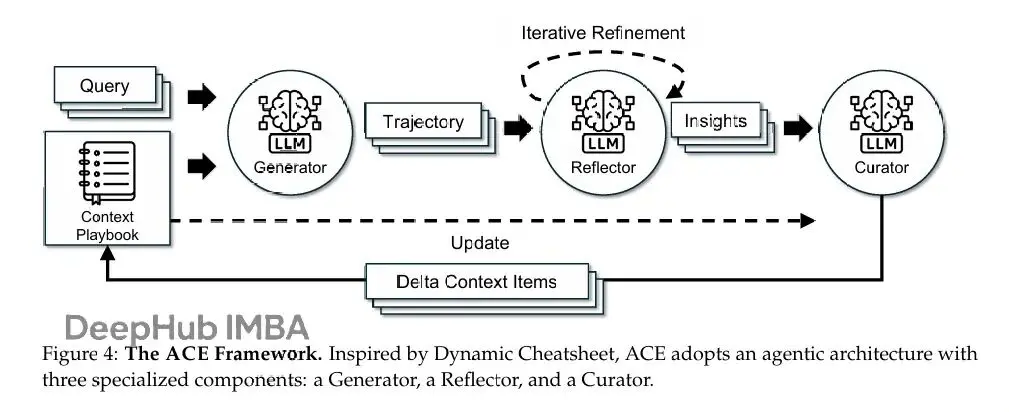
如論文圖4,工作流從Generator開始,為新query生成推理軌跡,暴露有效策略和反覆出現的問題。Reflector批判這些trace來提取經驗教訓,可選地跨多次迭代精煉它們。然後Curator把這些教訓合成緊湊的delta條目,通過輕量級非LLM邏輯確定性地合併到現有上下文中。因為更新是分項的、局部的,多個delta可以並行合併,支持大規模batch適應。ACE還支持多epoch適應,同一個query可以被重新訪問來逐步強化上下文。
增量Delta更新
ACE的核心設計原則是把上下文表示為結構化、分項的bullet集合,而不是單一整體prompt。bullet的概念類似LLM memory框架(比如Dynamic Cheatsheet和A-MEM)裏的memory條目,但更進一步,包含:
- 元數據:唯一標識符和計數器,跟蹤它被標記為helpful或harmful的次數
- 內容:捕獲一個獨立單元,比如可複用策略、領域概念、常見失敗模式
解決新問題時,Generator會標註哪些bullet有用或誤導,提供反饋指導Reflector提出修正更新。
這種分項設計實現三個關鍵屬性:
- 局部化:只有相關bullet被更新
- 細粒度檢索:Generator能專注最相關知識
- 增量適應:允許推理期間高效合併、修剪、去重
ACE不完全重新生成上下文,而是增量產生緊湊的delta contexts——Reflector提煉、Curator整合的候選bullet小集合。這避免了完全重寫的計算成本和延遲,同時確保過去知識被保留、新信息穩步追加。隨着上下文增長,這個方法提供長週期或領域密集應用需要的可擴展性。
Grow-and-Refine機制
除了增量增長,ACE通過週期性或lazy refinement確保上下文保持緊湊和相關。在grow-and-refine中,帶新標識符的bullet被追加,現有bullet就地更新(比如增加計數器)。然後去重步驟通過語義embedding比較bullet來修剪冗餘。這個refinement可以主動做(每個delta後),也可以lazy做(只在超出上下文窗口時),取決於應用對延遲和準確率的要求。
增量更新和grow-and-refine一起,維護了能自適應擴展、保持可解釋、避免整體上下文重寫帶來的潛在方差的上下文。
實驗評估
論文的評估表明:
讓高性能自我改進agent成為可能。ACE讓agent能動態精煉輸入上下文實現自我改進。單靠從執行反饋中學習來工程化更好的上下文,不需要ground-truth標籤,就在AppWorld benchmark上把準確率提升了17.1%。這種上下文驅動的改進讓更小的開源模型能達到排行榜頂級專有agent的性能。
領域特定benchmark上的大幅提升。在複雜金融推理benchmark上,ACE通過構建包含領域特定概念和信息的全面playbook,比強baseline平均提升8.6%。
設計選擇的有效性。消融研究證實各設計選擇是成功的關鍵,Reflector和多epoch refinement等組件各自都貢獻了可觀的性能提升。
更低成本和適應延遲。ACE高效地達成這些提升,平均減少86.9%適應延遲,同時需要更少rollout和更低token成本。
任務和數據集
論文在兩類最受益於全面演化上下文的LLM應用上評估ACE:
agent benchmark,需要多輪推理、工具使用、環境交互,agent能跨episode和環境累積複用策略
領域特定benchmark,需要掌握專門概念和策略,這裏聚焦金融分析作為case study
LLM Agent: AppWorld 是一套自主agent任務集,涉及API理解、代碼生成、環境交互。它提供真實執行環境,有常見應用和API(比如email、文件系統),以及兩個難度級別(normal和challenge)的任務。公開排行榜跟蹤性能,提交時最好的系統只達到60.3%平均準確率,凸顯benchmark的難度和真實性。
金融分析:FiNER和Formula測試LLM在依賴eXtensible Business Reporting Language (XBRL) 的金融推理任務上的表現。FiNER要求用139種細粒度實體類型標註XBRL金融文檔裏的token,這是監管領域金融信息提取的關鍵步驟。Formula專注從結構化XBRL文件提取值並執行計算來回答金融query,即數值推理。
評估指標:AppWorld遵循官方benchmark協議,報告test-normal和test-challenge split上的Task Goal Completion (TGC) 和Scenario Goal Completion (SGC)。FiNER和Formula遵循原始設置報告準確率,衡量為預測答案與ground truth完全匹配的比例。
所有數據集遵循原始train/validation/test split。離線上下文適應時,方法在訓練集上優化、在測試集上以pass@1準確率評估。在線上下文適應時,方法在測試集上順序評估:每個樣本先用當前上下文預測,然後基於該樣本更新上下文。所有方法用相同的shuffled測試集。
Baseline和方法對比
Base LLM:基礎模型直接在每個benchmark上評估,不做任何上下文工程,用數據集作者提供的默認prompt。AppWorld上遵循benchmark作者發佈的官方ReAct實現,所有其他baseline和方法都基於這個框架構建。
In-Context Learning (ICL):在輸入prompt裏提供任務演示(few-shot或many-shot)。讓模型推斷任務格式和期望輸出,不更新權重。當訓練樣本能裝進模型上下文窗口時提供所有樣本,否則儘可能多地填充演示。
MIPROv2:流行的LLM應用prompt優化器,通過貝葉斯優化聯合優化system指令和上下文演示。用官方DSPy實現,設置auto="heavy"來最大化優化性能。
GEPA:基於reflective prompt evolution的sample-efficient prompt優化器。收集執行trace(推理、工具調用、中間輸出)並應用自然語言reflection來診斷錯誤、分配credit、提出prompt更新。genetic Pareto搜索維護高性能prompt的frontier,緩解局部最優。實驗上GEPA優於GRPO等強化學習方法和MIPROv2等prompt優化器,達到高10-20%的準確率,rollout少35倍。用官方DSPy實現,設auto="heavy"最大化優化性能。
Dynamic Cheatsheet (DC):測試時學習方法,引入可重用策略和代碼片段的自適應外部memory。通過持續用新遇到的輸入輸出更新memory,DC讓模型累積知識並跨任務複用,往往帶來比靜態prompting方法大幅改進。DC的關鍵優勢是不需要ground-truth標籤:模型能從它的generation策展自己的memory,讓方法高度靈活和廣泛適用。用作者發佈的官方實現,設為使用cumulative mode (DC-CU)。
ACE (ours):ACE通過agentic上下文工程框架優化離線和在線適應的LLM上下文。為確保公平比較,Generator、Reflector和Curator用同一個LLM(DeepSeek-V3.1的非thinking模式),防止從更強Reflector或Curator向更弱Generator的知識遷移。這隔離了上下文構建本身的收益。採用batch size為1(從每個樣本構建delta上下文)。離線適應時Reflector refinement輪數和最大epoch數都設為5。
Agent benchmark結果
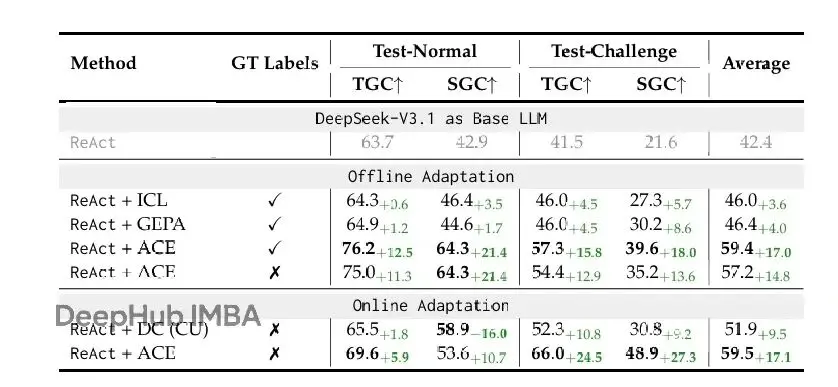
表1顯示,ACE在AppWorld benchmark上一致性地改進強baseline。離線設置中,ReAct + ACE大幅超過ReAct + ICL和ReAct + GEPA(分別12.3%和11.9%),證明結構化、演化、詳細的上下文比固定演示或單個優化指令prompt能更有效地讓agent學習。這些提升延伸到在線設置,ACE繼續超過Dynamic Cheatsheet等先前自適應方法平均7.6%。
在agent用例裏,ACE即使在適應期間沒有ground-truth標籤也保持有效:這個設置下ReAct + ACE比ReAct baseline平均改進14.8%。這種魯棒性源於ACE利用執行期間自然可得的信號(比如代碼執行成功或失敗)來指導Reflector和Curator形成結構化的成功失敗教訓。
這些結果確立ACE為構建自我改進agent的強大通用框架,能在有標籤和無標籤監督下可靠適應。
值得注意的是,在最新AppWorld排行榜上(截至2025年9月20日,圖5),平均來看ReAct + ACE (59.4%) 匹配頂級的IBM CUGA (60.3%),一個生產級GPT-4.1基礎的agent,儘管用的是更小的開源模型DeepSeek-V3.1。在線適應時,ReAct + ACE甚至在更難的test-challenge split上超過IBM CUGA,TGC高8.4%、SGC高0.7%,凸顯ACE在為agent構建全面自演化上下文方面的有效性。
領域特定benchmark結果
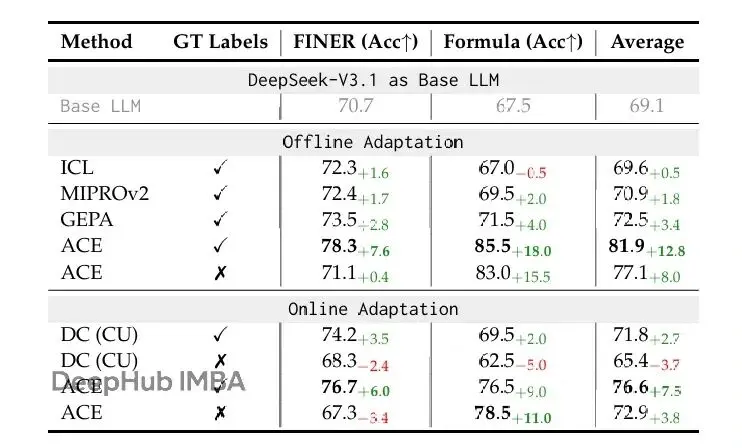
表2顯示,ACE在金融分析benchmark上提供強勁改進。離線設置中,當提供訓練集ground-truth答案時,ACE以明顯差距超過ICL、MIPROv2和GEPA(平均10.9%),顯示當任務需要精確領域知識(比如金融概念、XBRL規則)時,結構化演化上下文特別有效,超越固定演示或整體優化prompt。在線設置中,ACE繼續超過DC等先前自適應方法平均6.2%,進一步確認agentic上下文工程對跨專門領域累積可重用信息的好處。
另外,也觀察到當ground-truth監督或可靠執行信號缺失時,ACE和DC都可能性能下降。這種情況下構建的上下文可能被虛假或誤導性信號污染,凸顯推理時適應在沒有可靠反饋時的潛在限制。這表明雖然ACE在豐富反饋下(比如agent任務裏的代碼執行結果或formula正確性)很魯棒,但其有效性依賴於允許Reflector和Curator做出合理判斷的信號可得性。
消融研究
表3報告AppWorld benchmark上的消融研究,分析ACE的各個設計選擇如何促成有效上下文適應。檢查三個因素:
- 帶迭代refinement的Reflector,這是超越Dynamic Cheatsheet的agentic框架的增加部分
- 多epoch適應,多次在訓練樣本上精煉上下文
- 離線warmup,在線適應開始前通過離線適應初始化上下文
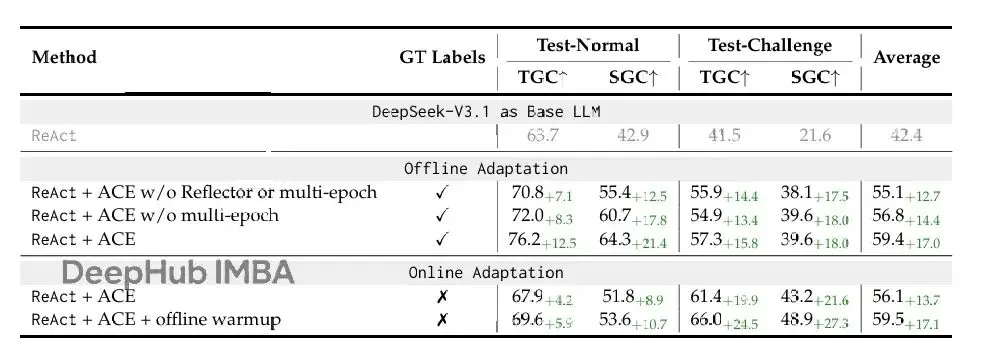
結果表明每個組件都對最終性能有貢獻。移除Reflector導致性能顯著下降,證明反思機制對提取高質量教訓至關重要。多epoch適應進一步提升性能,允許上下文在相同數據上多次精煉。離線warmup在在線場景中特別有價值,為適應提供更好的起點。
成本和速度分析
由於支持增量"delta"上下文更新和基於非LLM的上下文合併去重,ACE在降低適應成本(rollout數量或token攝取/生成的dollar成本方面)和延遲方面展現特別優勢。
舉例來説,AppWorld離線適應上,ACE相比GEPA達到82.3%適應延遲減少和75.1% rollout數量減少(表4a)。FiNER在線適應上,ACE相比DC達到91.5%適應延遲減少和83.6% token dollar成本減少(表4b)。

這些效率提升主要來自兩個設計:
- 增量更新避免了完全重寫上下文的開銷
- 並行處理多個delta允許batch適應
幾點討論
更長上下文≠更高服務成本。雖然ACE產生比GEPA等方法更長的上下文,但這不會線性轉化為更高推理成本或GPU內存使用。現代服務基礎設施越來越針對長上下文工作負載優化,通過KV cache的複用、壓縮、卸載等技術。這些機制讓頻繁複用的上下文段被本地或遠程緩存,避免重複昂貴的prefill操作。ML系統的持續進步表明處理長上下文的攤銷成本會繼續下降,讓ACE這類上下文豐富的方法在部署中越來越實用。
對在線和持續學習的啓示。在線和持續學習是機器學習應對分佈偏移和有限訓練數據等問題的關鍵研究方向。ACE提供了傳統模型微調的靈活高效替代方案,因為適應上下文通常比更新模型權重便宜。而且因為上下文人類可解釋,ACE支持選擇性遺忘——無論是因為隱私或法律約束,還是當領域專家識別出過時或錯誤信息時。這些是未來工作的有前景方向,ACE能在推進持續和負責任學習方面發揮核心作用。
侷限性
ACE的一個潛在限制是依賴相當強的Reflector:如果Reflector無法從生成的trace或結果提取有意義信息,構建的上下文可能變得混亂甚至有害。在沒有模型能提取有用信息的領域特定任務裏,產生的上下文自然缺乏價值。這種依賴類似Dynamic Cheatsheet,適應質量取決於底層模型策展memory的能力。
也要注意不是所有應用都需要豐富或詳細上下文。像HotPotQA這類任務往往更受益於簡潔高級指令(比如如何檢索和綜合證據),而不是長上下文。類似地,Game of 24這類有固定策略的遊戲可能只需要單個可重用規則,讓額外上下文冗餘。
總體上來説,ACE在需要詳細領域知識、複雜推理鏈或長期策略累積的應用中最有效。對於結構簡單或策略固定的任務,傳統的簡潔prompt優化可能依然足夠。
總結
論文提出Agentic Context Engineering (ACE),一個通用框架用離線和在線上下文適應。ACE通過增量delta更新和grow-and-refine原則,構建全面、演化的上下文,避免簡潔性偏差和上下文崩潰。
在agent benchmark和領域特定任務上的評估顯示ACE持續超過強baseline,同時顯著降低適應成本和延遲。ACE讓更小的開源模型達到頂級專有系統的性能,展示上下文工程作為模型適應強大替代方案的潛力。
未來工作可以探索ACE在更廣泛領域和應用中的應用,以及與其他適應技術(如參數高效微調)的集成。支持選擇性遺忘和解決上下文可解釋性的機制也是有前景的研究方向。
ACE代表向更靈活、可解釋、高效的LLM適應邁進的一步,為構建能持續從經驗學習和改進的AI系統開啓新可能性。
論文
https://arxiv.org/pdf/2510.04618