

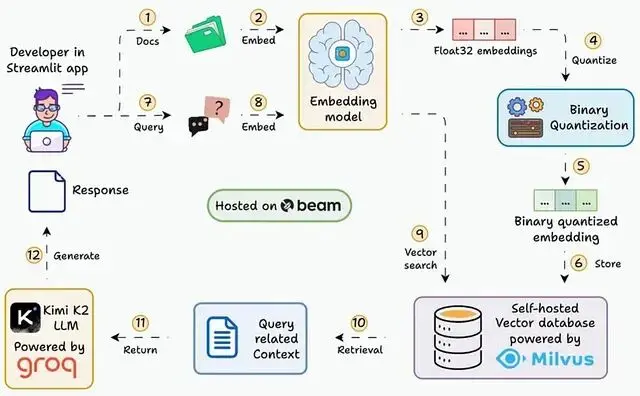
當文檔庫規模擴張時向量數據庫肯定會跟着膨脹。百萬級甚至千萬級的 embedding 存儲,float32 格式下的內存開銷相當可觀。
好在有個經過生產環境驗證的方案,在保證檢索性能的前提下大幅削減內存佔用,它就是Binary Quantization(二值化量化)
本文會逐步展示如何搭建一個能在 30ms 內查詢 3600 萬+向量的 RAG 系統,用的就是二值化 embedding。
二值化量化解決什麼問題
常規 embedding 用 float32 存儲:單個 embedding(1024 維)佔 4 KB 左右,3600 萬個 embedding 就是 144 GB
二值化量化把每個維度壓縮成 1 bit:同樣的 embedding 只需 128 bytes,3600 萬個 embedding 降到 4.5 GB
內存直接減少約 32 倍,而且位運算做相似度搜索更快。
精度損失與應對策略
二值化量化確實會帶來精度損失,這點不能迴避。
從 float32 直接壓縮到 1 bit信息丟失不可避免,根據測試數據顯示純二值檢索的準確度會下降到 92.5% 左右。不過這個問題有成熟的解決方案。
Oversampling(過採樣)
檢索時多拿一些候選結果。比如本來只需要 top-5,可以先檢索 top-20 或 top-50,用數量換精度抵消量化造成的分辨率損失。
Rescoring(重排序)
先用二值向量快速篩選候選集,然後用原始的 float32 向量重新計算相似度並排序。
具體做法是:把全精度向量存在磁盤、二值向量和索引放內存,檢索時先用內存裏的二值索引快速找到候選,再從磁盤加載原始向量做精確評分。
這兩個技術組合使用,能把準確度拉回到 95%-96%,對大多數 RAG 應用來説夠用了。
使用限制
維度小於 1024 的 embedding 不建議用二值化。維度太小時,1 bit 能保留的信息不足,準確度會掉得比較厲害。所以這個技術更適合高維向量(≥1024 維)和大規模數據集。
相比之下,float8 這類低位浮點格式在 4 倍壓縮下性能損失不到 0.3%,但內存節省遠不如二值化激進。32 倍的壓縮率帶來的精度代價,需要根據具體場景權衡。
數據加載
先用 LlamaIndex 的 directory reader 讀取文檔。
支持的格式挺全:PDF、Word、Markdown、PowerPoint、圖片、音頻、視頻都行。
LLM 配置
from llama_index.llms.groq import Groq
from llama_index.core.base.llms.types import (
ChatMessage, MessageRole )
llm = Groq(
model="MiniMaxAI/MiniMax-M2.1",
api_key=groq_api_key,
temperature=0.5,
max_tokens=1000
)
Moonshot Al
prompt_template = (
"Context information is below.\n"
"-----\n"
"CONTEXT: {context}\n"
"Given the context information above think step by step
"to answer the user's query in a crisp and concise manner.
"In case you don't know the answer say 'I don't know!'.\n"
"QUERY: {query}\n"
"ANSWER:
)
= query "Provide concise breakdown of the document"
prompt = prompt_template.format(context=full_context, query=query)
user_msg = ChatMessage(role=MessageRole.USER, content=prompt)
# Stream response from LLM
streaming_response = llm.stream_complete(user_msg.content)LLM 配置完成,下一步開始對文件進行索引
二值 Embedding 生成
我們先生成標準 float32 embedding,然後用簡單閾值轉成二值向量。
每個維度的轉換規則:
- 值 > 0 →
1 - 否則 →
0
Query Embedding 和二值化
# Generate float32 query embedding
query_embedding = embed_model.get_query_embedding(query)
# Apply binary quantization to query
binary_query = binary_quantize(query_embedding)
# Perform similarity search using Milvus
search_results = client.search(
)
collection_name="fastest-rag",
data=[binary_query],
Similarity search
anns_field="binary_vector",
search_params={"metric_type": "HAMMING"},
output_fields=["context"],
limit=5 # Retrieve top 5 similar chunks
# Store retrieved context
full_context = []
for res in search_results:
context = res ["payload"]["context"]
full_context.append(context)為什麼用 Hamming distance? 它是二值向量的天然相似度度量,計算速度極快。
Milvus Schema 和索引設置
from pymilvus import MilvusClient, DataType
# Initialize client and schema
client = MilvusClient("milvus_binary_quantized.db")
schema = client.create_schema (auto_id=True, enable_dynamic_fields=True)
# Add fields to schema
schema.add_field(field_name="context", datatype=DataType. VARCHAR)
schema.add_field(field_name="binary_vector", datatype=DataType.BINARY_VECTOR)
# Create index parameters for binary vectors
index_params = client.prepare_index_params()
index_params.add_index(
Specify index params
field_name="binary_vector",
index_name="binary_vector_index",
index_type="BIN_FLAT",
# Exact search for binary vectors
metric_type="HAMMING" # Hamming distance for binary vectors
)
# Create collection with schema and index
client.create_collection(
collection_name="fastest-rag",
schema=schema,
)
index_params=index_params
Create collection
# Insert data to index
client.insert(
collection_name="fastest-rag",
Insert data
data=[
{"context": context, "binary_vector": binary_embedding}
for context, binary_embedding in zip(batch_context, binary_embeddings)
]
)這套配置能讓 Milvus 高效處理數千萬級別的向量。
檢索流程
檢索時的數據流:
- 用户 query 轉 embedding
- embedding 轉二值向量
- 用 Hamming distance 做二值檢索
- 返回 top-k 相關文本塊
文檔 Embedding 的二值化處理
import numpy as np
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-en-v1.5",
trust_remote_code=True,
cache_folder='./hf_cache'
)
for context in batch_iterate(documents, batch_size=512):
# Generate float32 vector embeddings
batch_embeds = embed_model.get_text_embedding_batch(context)
# Convert float32 vectors to binary vectors
embeds_array = np.array(batch_embeds)
binary_embeds = np.where(embeds_array > 0, 1, 0).astype(np.uint8)
# Convert to bytes array
packed_embeds = np.packbits(binary_embeds, axis=1)
byte_embeds = [vec.tobytes() for vec in packed_embeds]
binary_embeddings.extend(byte_embeds)這個轉換過程快、簡單、效果好。
LLM 生成環節
檢索到 top-k 文本塊後,用結構化 prompt 餵給 LLM。
# Combine retrieved contexts
full_context = "\n\n".join(full_context)
# Format prompt with context and query
prompt = prompt_template.format(context=full_context, query=query)
# Create chat message
user_msg = ChatMessage(role=MessageRole.USER, content=prompt)
# Stream response from LLM
streaming_response = llm.stream_complete(user_msg.content)
# Display streaming response
for chunk in streaming_response:
print(chunk.delta, end="", flush=True)這裏把檢索到的多個文本塊拼接起來,填充到 prompt template 裏。LLM 會基於這些上下文生成回答。如果檢索內容裏沒有答案,LLM 會直接回復 "I don't know!"。
總結
二值化量化在大規模 RAG 系統中的價值已經得到驗證。32 倍的內存壓縮率配合 Hamming distance 的計算效率,使得在資源受限環境下部署千萬級向量檢索成為可能。
精度損失是這個方案的代價,但 oversampling + rescoring 的組合能將準確度維持在 95% 以上,這對多數應用場景足夠。
Perplexity、Azure、HubSpot 的生產實踐説明這套方案已經過大規模驗證。不過具體部署時還是要根據數據特徵做測試,尤其是 rescoring 的候選集大小(oversampling factor)需要根據實際召回率調整。
https://avoid.overfit.cn/post/3a922ea4c69b4e2883a63da1d314dadb
作者:Algo Insights