

Swarm sAmpling Policy Optimization,簡稱SAPO,這個名字聽起來有點學術,但它解決的問題很實際。大規模語言模型的後訓練一直是個讓人頭疼的事情——要麼資源不夠,要麼效率太低。SAPO提出了一種去中心化的異步RL方案,讓各個計算節點之間可以互相分享rollouts,避開了傳統並行化訓練的各種瓶頸。
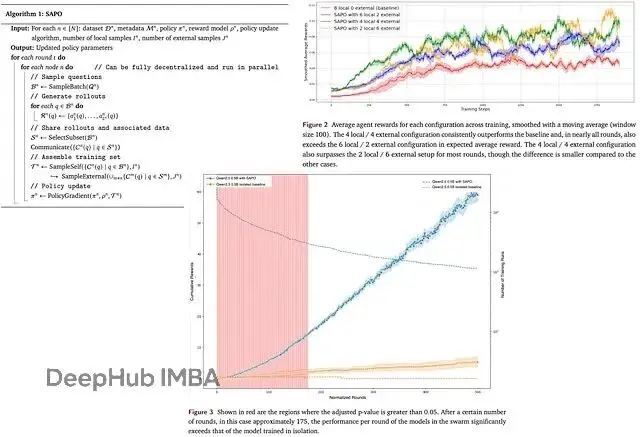
論文的實驗結果。在成千上萬個社區節點的測試中,這套方法能帶來94%的回報提升。
核心機制
整個系統的設計思路其實不復雜。想象一下有N個節點組成的網絡,每個節點都在不停地生成和交換rollouts。節點上跑着可驗證的任務數據集,包含標準答案和驗證邏輯,語言模型會針對每個任務輸出多個候選答案。
關鍵在於rollouts的兼容性——不同節點之間必須能夠理解彼此的輸出格式。數據集內容、答案數量這些都可以動態調整,甚至可以控制提示的複雜度來調節任務難度。
還有個很有趣的設定:節點不一定非要參與訓練。你可以讓人類專家或者其他非傳統的生成器加入進來,只要輸出格式兼容就行。

訓練流程看起來是這樣的:每輪訓練中,節點先採樣一批任務,生成對應的rollouts,然後把其中一部分(連同元數據和標準答案)分享給整個網絡。
各個節點收到這些分享後,會把自己的rollouts和別人的混合起來構建訓練集。這裏的靈活性很高,節點可以自己決定怎麼篩選和組合這些數據。訓練集構建完成後,用本地的獎勵模型計算分數,再用PPO或GRPO這類策略梯度方法更新模型。整個過程循環往復。
實驗設計和效果分析
研究團隊選擇了ReasoningGYM作為測試平台,這個數據集能夠無限生成代數、邏輯、圖推理等領域的驗證題目。實驗中設定了九個不同的專業方向,每個智能體每輪在每個方向上都會拿到一道題,然後生成8個候選答案。
策略更新用的是GRPO,沒有加KL懲罰項。獎勵機制比較直接:ReasoningGYM自帶的規則驗證器,答對得1分,答錯得0分。有個細節值得注意——他們沒有專門設置格式獎勵,因為正確的格式會在節點間的分享過程中自然傳播。
整個實驗跑在GenRL框架上,這是個專門為去中心化多智能體RL設計的平台,和ReasoningGYM集成得不錯。
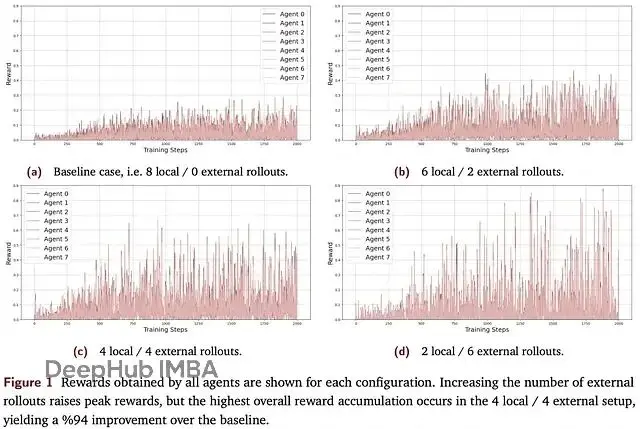
對比實驗的設計很清楚:標準RL微調(不分享)vs SAPO的幾種配置。在保持總訓練樣本數不變的前提下,他們測試了不同的本地/外部rollouts混合比例。
結果顯示,4本地+4外部的配置效果最好,累計獎勵最高,2/6和6/2的配置次之。和基線相比,4/4配置的提升幅度達到94%,而且在各個訓練輪次中都能保持更高的平均獎勵。
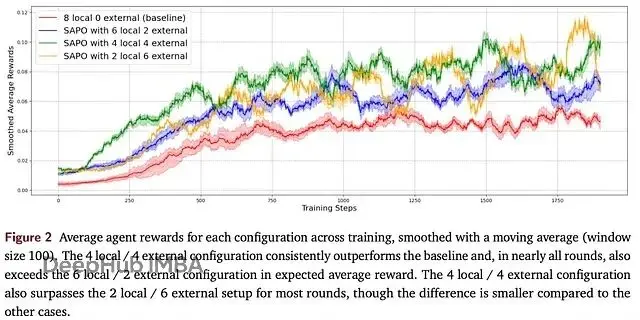
但是過度依賴外部rollouts也會出問題。2/6的配置就出現了明顯的震盪,性能反而下降了。分析原因,主要是太依賴其他(可能較弱的)節點輸出,導致共享池的質量被稀釋。
所以平衡很重要。適度的經驗分享既能讓好的想法在網絡中傳播,又不會因為過度依賴外部數據而影響穩定性。研究者用了個很形象的詞:"Aha moments"——那種突然想通某個解法的時刻,確實能夠在羣體中擴散。
大規模實測
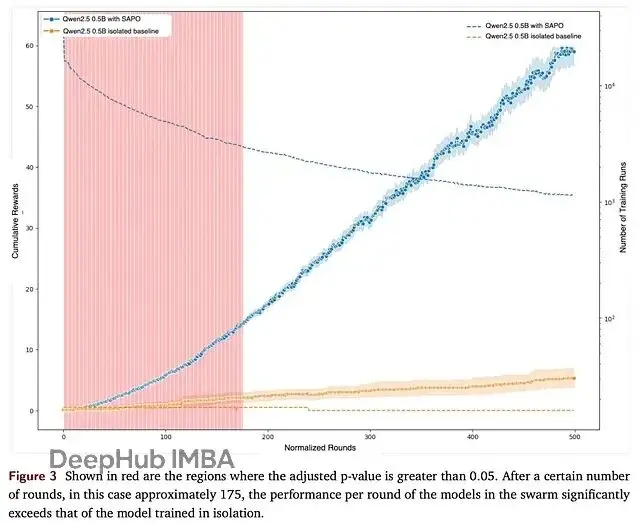
理論歸理論,真正的考驗在大規模異構環境下。研究團隊搞了個包含數千個社區節點的演示,讓這些節點用ReasoningGYM任務接受統一評估。
SAPO對中等規模模型的幫助更明顯。比如Qwen2.5(0.5B參數),在175輪訓練後的表現明顯超過單機訓練。但對於Qwen3(0.6B參數)這樣的大模型,改善就不太明顯了。
這個現象其實也好理解——中等容量的模型更容易從集體經驗中受益,而大模型本身能力已經比較強,外部rollouts的價值相對有限。
還有個技術細節:實驗中的rollouts是均勻隨機採樣的,沒有做特別的質量篩選。這意味着大量低價值樣本會拖累整體效果。如果能設計更好的採樣策略,説不定連大模型也能從中獲益。
這個研究提出的SAPO方法,在去中心化訓練這個方向上確實開了個好頭。雖然還有一些細節需要完善,但基本思路值得關注。
論文地址:
https://avoid.overfit.cn/post/7e17063b4d354b1c80a7b3e933dded91