

本文將詳細解讀NeurIPS 2024最佳論文:"Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction(視覺自迴歸建模:基於下一尺度預測的可擴展圖像生成)"。
該論文提出了視覺自迴歸建模(Visual Autoregressive Modeling,VAR)方法,在圖像生成領域實現了重要突破。VAR通過精確捕捉圖像結構特徵,實現了高效率、高質量的圖像生成。該方法對當前以擴散模型為主導的圖像生成領域提出了新的技術方向,為自迴歸模型開闢了新的發展空間。本文將從技術原理、實現方法、應用場景及侷限性等方面進行詳細分析。
圖像生成的兩大技術路線:擴散模型與自迴歸模型
圖像生成技術主要包含兩個主要分支。第一個分支是擴散模型(Diffusion Models),其核心原理是通過逐步添加噪聲並隨後反向去噪來生成圖像。近年來擴散模型在圖像生成領域取得了顯著進展,併成為主流技術方案。
第二個分支是自迴歸模型(Autoregressive Models,AR Models)。這類模型採用逐步構建的方式生成圖像,即基於已生成的部分預測圖像的下一個組成部分。自迴歸模型是GPT等大型語言模型的核心技術,同時在圖像生成領域也取得了重要進展。自迴歸模型通常基於卷積神經網絡或Transformer架構實現。本文重點討論的VAR模型即屬於自迴歸模型家族。
傳統自迴歸模型的技術侷限
傳統自迴歸模型將二維圖像轉換為一維token序列,並按照光柵掃描模式順序預測這些token。這種方法存在以下技術侷限:
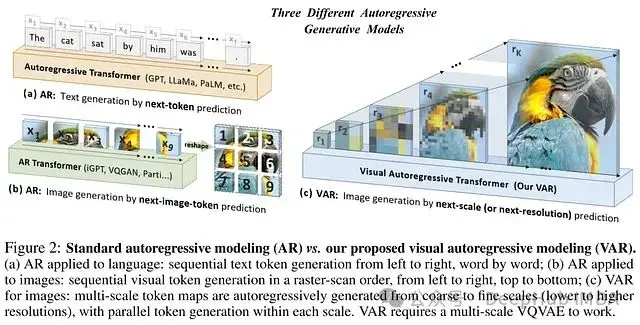
- 二維結構信息損失: 圖像token在水平和垂直方向上均存在關聯性,但傳統自迴歸模型的順序生成機制難以有效建模這種二維依賴關係,影響了圖像結構的完整性建模。
- 泛化能力受限: 順序生成模式導致模型對生成順序具有強依賴性。例如一個按照從上到下順序訓練的模型,在要求反向生成時性能會顯著降低。
- 空間信息缺失: 將二維圖像壓縮為一維序列的過程中,相鄰token之間的空間關係信息會丟失,這限制了模型對圖像結構的理解和重建能力。
- 計算效率低下: 傳統自迴歸模型的計算複雜度隨圖像token數量呈O(n⁶)增長,這種複雜度使得高分辨率圖像的生成在計算資源方面面臨嚴峻挑戰。
VAR:基於下一尺度預測的技術創新
VAR模型通過引入"下一尺度預測"範式來解決傳統自迴歸模型的技術侷限。該方法將圖像表示為多尺度token圖,並採用從低分辨率到高分辨率的粗細層次結構進行自迴歸生成。
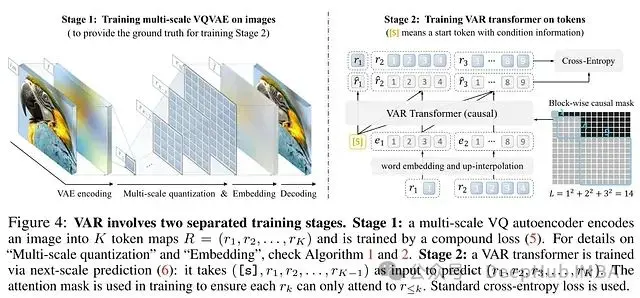
- 多尺度VQVAE架構: VAR首先採用向量量化變分自編碼器(Vector Quantized Variational Autoencoder,VQVAE)將圖像編碼為多尺度token圖。VQVAE能夠將圖像的高維特徵向量量化為離散碼向量。系統在不同分辨率層次提取的特徵圖通過碼本量化得到對應的token圖表示。
- VAR Transformer結構: VAR Transformer模塊基於已生成的低分辨率token圖預測下一個更高分辨率的token圖。系統支持每個分辨率層次的token圖並行生成,顯著提升了計算效率。訓練過程中採用塊狀因果掩碼確保token圖的生成僅依賴於較低分辨率的信息。
VAR系統工作機制
- 多尺度VQVAE編碼環節:輸入圖像經由多尺度VQVAE編碼器處理,生成多個分辨率層次的特徵圖,隨後將各特徵圖量化為相應的token圖表示。
- VAR Transformer生成過程:VAR Transformer從最低分辨率token圖開始,逐步自迴歸地生成更高分辨率的token圖序列。在每個生成步驟中,系統輸入已有的全部token圖及其位置編碼信息。
- 多尺度VQVAE解碼過程:生成的多尺度token圖通過多尺度VQVAE解碼器重建為最終圖像。解碼器利用token圖的索引信息從碼本中檢索相應的碼向量,並通過插值和卷積操作重建圖像。
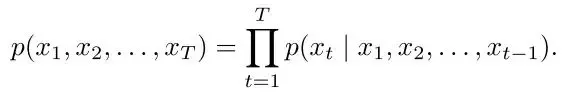
技術説明: 在公式1中,圖像片段序列的生成概率被定義為各個片段條件概率的乘積,表示為P(x₁, x₂, …, xₜ) = ∏ P(xᵢ | x₁…xᵢ₋₁)。其中xᵢ表示單個圖像片段,t代表片段總數。
VAR的技術優勢
VAR系統在多個方面突破了傳統自迴歸模型的侷限:
- 數學建模優化: VAR通過粗細層次的生成機制有效解決了二維結構建模問題,通過整體token圖的預測處理了複雜的依賴關係。
- 泛化性能提升: VAR系統通過學習圖像的整體結構特徵,在各類輸入場景下表現穩定,包括零樣本圖像修復和擴展任務。
- 空間信息保持: VAR在處理token圖的過程中保持二維圖像結構完整,多尺度架構有效捕捉了空間層次關係。
- 計算效率提升: VAR通過分辨率內的並行token生成和遞歸尺度擴展,將計算複雜度降低至O(n⁴),顯著提升了系統效率。
- 圖像質量改進: VAR在圖像質量和推理速度方面均超越了現有的擴散Transformer模型。
VAR系統的訓練與推理

VAR系統採用兩階段訓練策略:
- 多尺度VQVAE訓練階段(第一階段): 使用原始圖像數據訓練多尺度VQVAE模型。訓練目標是最小化重建圖像與原始圖像之間的誤差,同時生成多分辨率token圖。在訓練過程中,系統同步優化碼本以提升特徵表示能力。
- VAR Transformer訓練階段(第二階段): 利用訓練完成的VQVAE模型將圖像轉換為token圖序列,隨後訓練VAR Transformer模型。VAR Transformer學習利用已有的低分辨率token圖預測下一級token圖,訓練過程中採用因果掩碼確保預測只依賴已知信息。
VAR系統的推理過程包含以下步驟:
- 多尺度VQVAE編碼步驟: 利用訓練好的VQVAE模型將輸入圖像編碼為多尺度token圖序列。
- VAR Transformer生成步驟: 從最低分辨率token圖開始,VAR Transformer逐級生成更高分辨率的token圖。
- 多尺度VQVAE解碼步驟: 利用多尺度VQVAE解碼器將生成的token圖序列重建為最終輸出圖像。
實驗驗證與擴展性分析
論文通過系統實驗驗證了VAR模型的性能優勢。在ImageNet數據集上的測試表明,VAR在圖像生成質量和速度方面均優於現有擴散Transformer模型。實驗結果同時展示了VAR性能隨模型規模增長的良好擴展特性。

實驗還證實了VAR系統在圖像修復、擴展等零樣本任務中的出色泛化能力,表明該模型不僅能夠生成圖像,還能深入理解圖像結構特徵。

技術侷限與未來發展方向
VAR系統雖然實現了重要突破,但仍存在以下技術侷限:
- 文本引導圖像生成能力: 當前VAR系統尚未實現文本條件下的圖像生成功能。未來研究需要着重擴展模型的多模態處理能力。
- 視頻生成應用: VAR在視頻生成領域的應用潛力有待探索。後續研究需要探索VAR框架在時序數據生成中的擴展應用。
- 模型複雜性: VAR採用的兩階段訓練策略(VQVAE和Transformer)增加了系統複雜度,需要進一步研究簡化訓練流程和提升學習效率的方法。
總結
VAR系統在圖像生成領域實現了方法論層面的重要創新,成功克服了傳統自迴歸模型的多項技術侷限。通過引入"下一尺度預測"範式,VAR不僅能夠精確捕捉圖像結構特徵,還實現了高效率的高質量圖像生成。VAR在可擴展性和零樣本泛化能力方面的優勢,預示着該技術將對圖像生成領域產生深遠影響。
論文地址:
https://avoid.overfit.cn/post/6b65bf03189949608b81a8543800521c
作者:Daniel Park