

單機 PyTorch 模型跑推理沒什麼問題,但數據量一旦上到萬級、百萬級,瓶頸就暴露出來了:內存不夠、GPU 利用率低、I/O 拖後腿,更別説還要考慮容錯和多機擴展。
傳統做法是自己寫多線程 DataLoader、管理批次隊列、手動調度 GPU 資源,這哥工程量可不小,調試起來也麻煩。Ray Data 提供了一個更輕量的方案:在幾乎不改動原有 PyTorch 代碼的前提下,把單機推理擴展成分佈式 pipeline。
原始的 PyTorch 代碼
典型的推理場景:模型加載、預處理、批量預測,一套下來大概長這樣:
import torch
import torchvision
from PIL import Image
from typing import List
class TorchPredictor:
def __init__(self, model: torchvision.models, weights: torchvision.models):
self.weights = weights
self.model = model(weights=weights)
self.model.eval()
self.transform = weights.transforms()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
def predict_batch(self, batch: List[Image.Image]) -> torch.Tensor:
with torch.inference_mode():
batch = torch.stack([
self.transform(img.convert("RGB")) for img in batch
]).to(self.device)
logits = self.model(batch)
probs = torch.nn.functional.softmax(logits, dim=1)
return probs處理幾張圖片完全沒問題:
predictor = TorchPredictor(
torchvision.models.resnet152,
torchvision.models.ResNet152_Weights.DEFAULT
)
images = [
Image.open('/content/corn.png').convert("RGB"),
Image.open('/content/corn.png').convert("RGB")
]
predictions = predictor.predict_batch(images)大數據量
圖片數量從幾張變成幾萬張、幾百萬張,情況完全不一樣了。
內存撐不住,不可能把所有圖一股腦塞進去;GPU 利用率上不去,多卡場景下吞吐量優化是個棘手的問題;萬一跑到一半掛了怎麼辦?分佈式部署能不能用上集羣資源?還有個容易被忽視的點:數據加載的 I/O 往往才是真正的瓶頸。
自己從頭寫一套健壯的 pipeline 處理這些問題,少説得折騰好幾天。
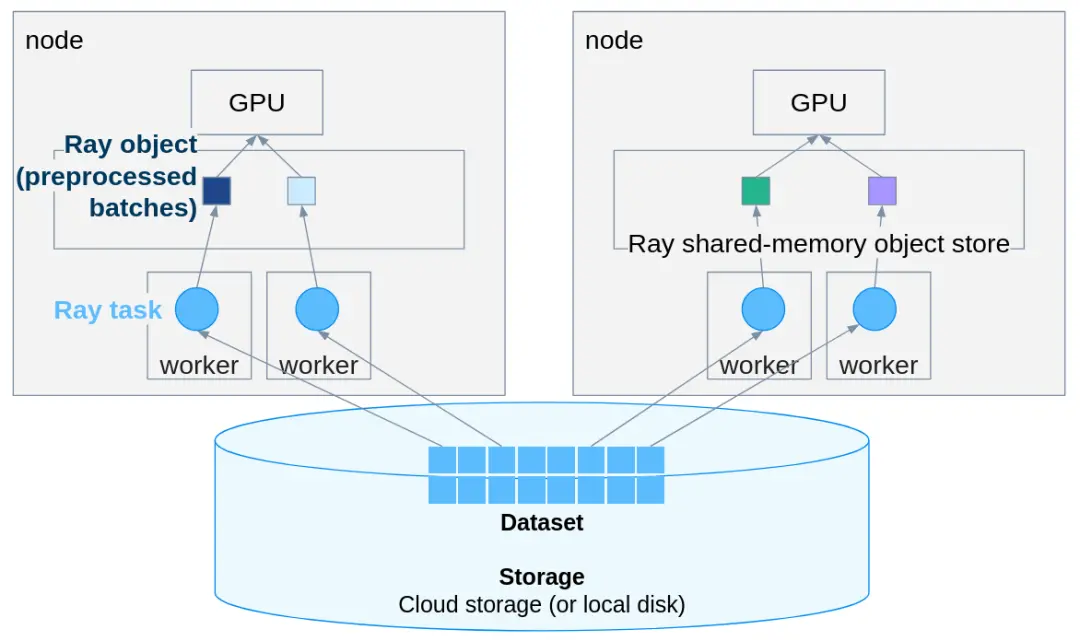
Ray Data 的思路
Ray Data 是個分佈式數據處理框架,跟 PyTorch 配合得很好。關鍵是改造成本極低,原有代碼基本不用大動。
第一步:改造 Predictor 類
把
predict_batch方法換成
__call__,輸入從 PIL Image 列表改成包含 numpy 數組的字典:
import numpy as np
from typing import Dict
class TorchPredictor:
def __init__(self, model: torchvision.models, weights: torchvision.models):
self.weights = weights
self.model = model(weights=weights)
self.model.eval()
self.transform = weights.transforms()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
def __call__(self, batch: Dict[str, np.ndarray]):
"""Ray Data passes a dict batch with numpy arrays."""
# Convert numpy arrays back to PIL Images
images = [Image.fromarray(img_array) for img_array in batch["image"]]
with torch.inference_mode():
tensor_batch = torch.stack([
self.transform(img.convert("RGB")) for img in images
]).to(self.device)
logits = self.model(tensor_batch)
probs = torch.nn.functional.softmax(logits, dim=1)
# Get top prediction
top_probs, top_indices = torch.max(probs, dim=1)
return {
"predicted_class_idx": top_indices.cpu().numpy(),
"confidence": top_probs.cpu().numpy()
}改動點説明:
__call__替代
predict_batch;輸入類型從
List[Image.Image]變成
Dict[str, np.ndarray];方法內部把 numpy 數組轉回 PIL Image;輸出改成 dict 格式;結果要搬回 CPU(數據在進程間的移動由 Ray 負責)。
還有個細節要注意,Ray Data 用 numpy 數組而非 PIL Image,因為 numpy 數組跨進程序列化效率更高。
第二步:構建 Ray Dataset
根據場景選擇合適的創建方式,小數據集直接從內存構建:
import ray
import numpy as np
ray.init()
# Convert PIL Images to numpy arrays
images = [
Image.open("/path/to/image1.png").convert("RGB"),
Image.open("/path/to/image2.png").convert("RGB")
]
# Create Ray Dataset from numpy arrays
ds = ray.data.from_items([{"image": np.array(img)} for img in images])中等規模數據集推薦從文件路徑延遲加載:
# Create dataset from paths
image_paths = ["/path/to/img1.png", "/path/to/img2.png"]
ds_paths = ray.data.from_items([{"path": path} for path in image_paths])
# Load images lazily
def load_image(batch):
images = [np.array(Image.open(path).convert("RGB")) for path in batch["path"]]
return {"image": images}
ds = ds_paths.map_batches(load_image, batch_size=10)生產環境首選
read_images(),Ray 全權接管:
# Most efficient - Ray handles everything
ds = ray.data.read_images("/path/to/image/directory/")
# or with specific files
ds = ray.data.read_images(["/path/img1.png", "/path/img2.png"])第三步:跑分佈式推理
核心代碼如下:
weights = torchvision.models.ResNet152_Weights.DEFAULT
# Distributed batch inference
results_ds = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1,
compute=ray.data.ActorPoolStrategy(size=4) # 4 parallel actors
)
# Collect results
results = results_ds.take_all()
# Process results
for result in results:
class_idx = result['predicted_class_idx']
confidence = result['confidence']
print(f"Predicted: {weights.meta['categories'][class_idx]} ({confidence:.2%})")搞定了。新版 Ray 裏
concurrency參數已經廢棄,要換成
compute=ActorPoolStrategy(size=N)這種寫法。
改動總結:
自動分批,Ray 自己決定最優 batch size;
分佈式執行,多 worker 並行跑;
GPU 調度,自動把卡分配給 worker;
流式處理,數據在 pipeline 裏流動,不用一次性全加載進內存;
容錯機制,worker 掛了會自動重試。
生產環境
RAY還可以直接讀雲存儲的數據,S3、GCS、Azure Blob 都支持:
# Read directly from S3, GCS, or Azure Blob
ds = ray.data.read_images("s3://my-bucket/images/")
results = ds.map_batches(
predictor,
batch_size=64,
num_gpus=1,
concurrency=8 # 8 parallel GPU workers
)多節點集羣也可以用同一套代碼,10 台機器還是 100 台機器,根本不用改:
# Connect to your Ray cluster
ray.init("ray://my-cluster-head:10001")
# Same code as before
ds = ray.data.read_images("s3://my-bucket/million-images/")
results = ds.map_batches(predictor, batch_size=64, num_gpus=1)進階用法
每個 batch 都重新加載模型太浪費了,用 ActorPoolStrategy 讓模型實例常駐內存:
from ray.data import ActorPoolStrategy
results = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1,
compute=ActorPoolStrategy(size=4) # Keep 4 actors alive
)這樣吞吐量提升很明顯。
CPU、GPU 資源可以細調
results = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1, # 1 GPU per actor
num_cpus=4, # 4 CPUs per GPU worker
compute=ActorPoolStrategy(size=8)
)推理完直接寫到雲存儲:
results.write_parquet("s3://my-bucket/predictions/")幾個容易踩的坑
Ray Data 沒法直接序列化 PIL Image 對象,得先轉成 numpy 數組:
# ❌ This will fail
ds = ray.data.from_items([{"image": pil_image}])
# ✅ This works
ds = ray.data.from_items([{"image": np.array(pil_image)}])
# ✅ Or use read_images() (best)
ds = ray.data.read_images("/path/to/images/")Ray 2.51 之後
concurrency不能用了:
# ❌ Deprecated
ds.map_batches(predictor, concurrency=4)
# ✅ New way
ds.map_batches(predictor, compute=ActorPoolStrategy(size=4))batch size 太大容易 OOM,保守起見可以從小的開始試:
# Monitor GPU memory and adjust batch_size accordingly
results = ds.map_batches(
predictor,
batch_size=16, # Start conservative
num_gpus=1
)實踐建議
batch size 可以從小往大試,觀察 GPU 顯存佔用:
# Too small: underutilized GPU
batch_size=4
# Too large: OOM errors
batch_size=256
# Just right: depends on your model and GPU
# For ResNet152 on a single GPU, 32-64 works well
batch_size=32ActorPoolStrategy 處理 20 張圖大概要 9.7 秒,而原生 PyTorch 跑 2 張圖幾乎瞬間完成。所以圖片量少的時候 Ray Data 的啓動開銷反而不划算,所以這個方案是幾百上千張圖的場景才能體現優勢。
Ray 自帶 dashboard,默認在 8265 端口:
# Check Ray dashboard at http://localhost:8265
ray.init(dashboard_host="0.0.0.0")代碼中可以包一層 try-except 防止單個樣本出錯拖垮整個任務:
def safe_predictor(batch: dict):
try:
return predictor(batch)
except Exception as e:
return {"error": str(e), "probs": None}跑之前加個計時,可以進行性能 profiling:
import time
start = time.time()
results = ds.map_batches(predictor, batch_size=32)
results.take_all()
print(f"Processed in {time.time() - start:.2f} seconds")總結
適合的場景:數據集太大內存放不下;需要多卡或多機並行;長時間任務需要容錯;不想自己寫分佈式代碼。
不太必要的場景:圖片量在百張以內;數據集輕鬆塞進內存;只有一張卡而且短期內不打算擴展。
Ray Data 的好處在於遷移成本低。PyTorch 代碼改動很小,換個方法簽名、把數據包成 Ray Dataset,就能換來從單卡到多機的無痛擴展、自動 batching 和並行優化、內置容錯、雲存儲無縫對接等功能。
如果你下次寫多線程 data loader 或者手動管理 GPU pool 之前,可以先考慮一下這哥方法,把分佈式系統的髒活累活交給 Ray,精力留給構建模型本身。
https://avoid.overfit.cn/post/6320b9b6e1a14e0ba4c3384c83d06986
作者:Moutasem Akkad