

刷短視頻本來只想看幾分鐘,不知不覺一個多小時就沒了。每條視頻都恰好戳中你的興趣點,這種精準推送背後其實是一套相當複雜的工程架構。
這種"讀心術"般的推薦效果並非偶然。驅動這種短視頻頁面的核心引擎,正是業內廣泛採用的雙塔推薦系統(Two-Tower Recommendation System)。
本文將從技術角度剖析:雙塔架構的工作原理、為何在短視頻場景下表現卓越,以及如何構建一套類似的推薦系統。
推薦系統:注意力經濟的核心武器
注意力經濟時代,個性化推薦已經成為平台的基本能力。傳統的"熱門榜單"模式早已過時——因為用户很快就會感到內容乏味,並且推薦內容單一,無法吸引用户最終流失。
而短視頻的成功在於能夠預判用户需求,這也就是説為什麼推薦系統成為當今最具商業價值的 AI 應用之一:
Netflix 通過推薦決定你下一部追的劇,YouTube 用算法填滿你的首頁和 Shorts 流,Amazon 靠推薦驅動購買決策,Spotify 的 Discover Weekly 幫你發現新音樂。
但論推薦效果,TikTok/抖音應該説是做到了極致。除了響應速度極快,個性化程度還極高。
雙塔架構:兩個"大腦"的協作機制
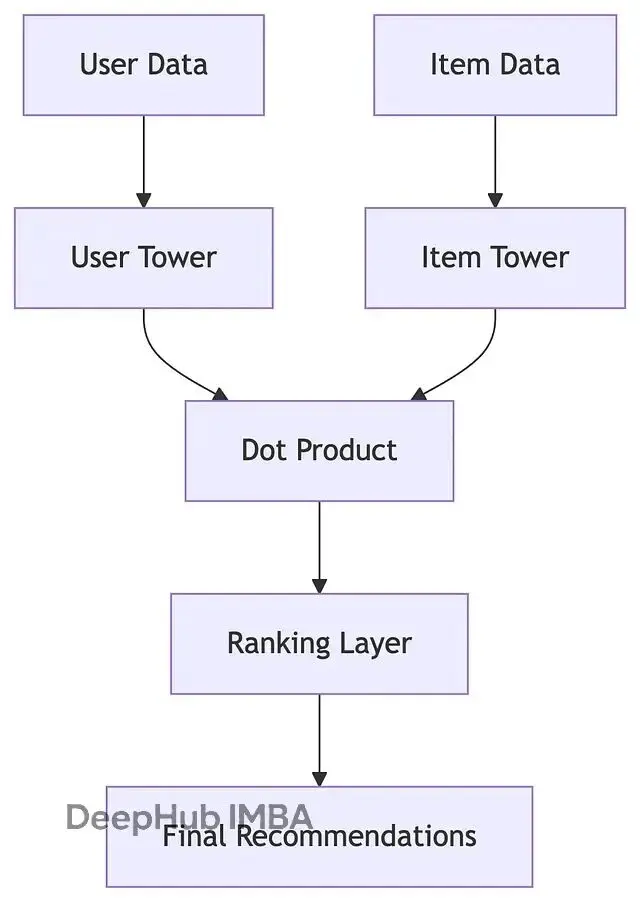
雙塔系統本質上是兩個獨立但協調的神經網絡模塊:
用户塔(User Tower)專門建模用户特徵——偏好習慣、行為模式、上下文信息等等。物品塔(Item Tower)則負責理解內容特徵——視頻屬性、創作者風格、話題標籤等。
這種設計的巧妙之處在於將複雜的用户-內容匹配問題,轉化為兩個向量空間的相似度計算。
技術實現細節拆解
用户塔的特徵工程
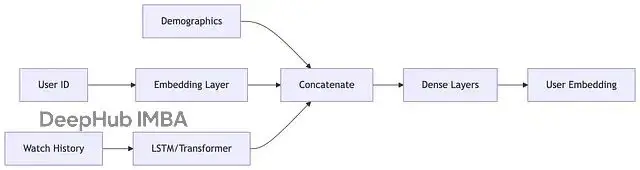
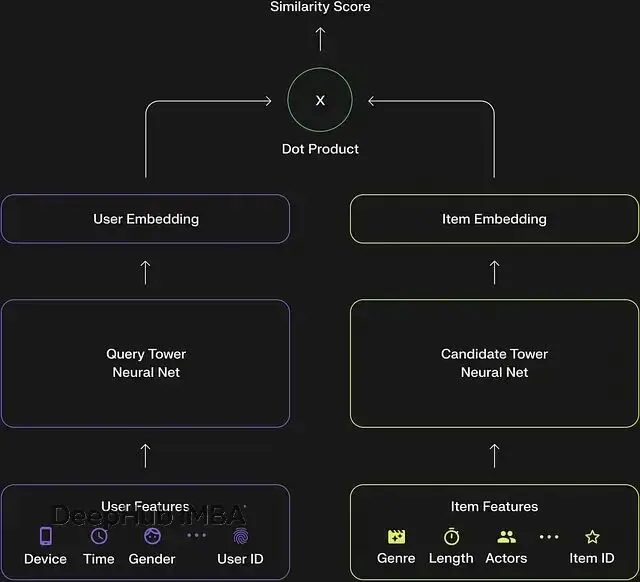
用户塔的任務是將用户的所有行為數據壓縮成一個稠密向量表示,這個向量可以理解為用户的"數字指紋"。
輸入特徵通常包括:歷史觀看記錄及停留時長、互動行為(點贊、分享、評論、關注),時間和地理位置等上下文信息,以及用户基礎屬性(年齡、性別等,如果可獲取)。
這些原始特徵經過 embedding 層和多層神經網絡處理,最終輸出一個固定維度的向量。這個向量在某種程度上"記住"了用户的興趣偏好。
物品塔的內容理解
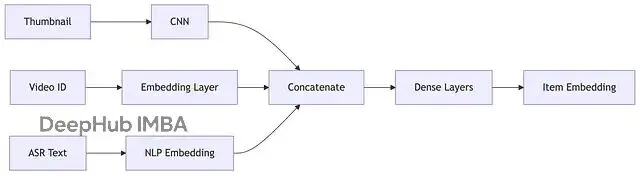
物品塔負責將每條物品轉換為相應的向量表示。
以視頻為例視頻特徵相對更加多元化:基礎 ID 信息(視頻 ID、創作者 ID),內容標籤和話題分類,音頻特徵(BGM、音效等),文本信息(標題、字幕、ASR 轉錄文本),視覺特徵(通常使用預訓練的 CNN 模型提取關鍵幀或縮略圖的特徵向量)。
同樣經過神經網絡處理後,每條視頻都得到一個與用户向量處於同一語義空間的表示向量。
向量匹配與相似度計算
兩個塔產生的向量如何進行匹配?最直接的方法是計算向量間的點積或餘弦相似度。相似度越高,表明用户對該視頻的潛在興趣越大。
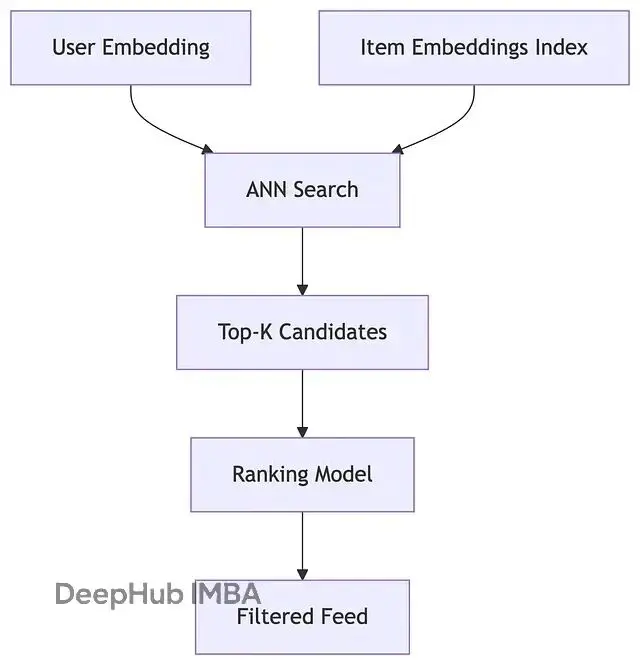
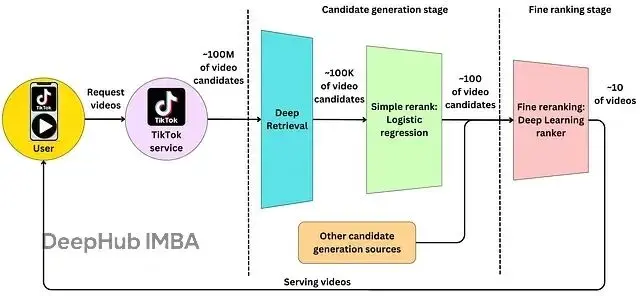
但是面對百萬級別的視頻庫,逐一計算顯然不現實。所以就需要用到近似最近鄰搜索(ANN)技術,比如 Facebook 開源的 Faiss 或者 Google 的 ScaNN。這些工具能夠在毫秒級時間內從海量向量中找出最相似的候選集合。
從啓動到推薦:完整的數據流

當用户打開 短視頻時,後台的推薦流程大致如下:
首先實時計算或獲取用户的最新特徵向量。接着通過 ANN 檢索從全量視頻庫中召回幾千個潛在候選。然後使用更復雜的排序模型對候選視頻進行精排,考慮預期觀看時長、互動概率等多個目標。
在內容輸出前還會應用各種業務規則:內容去重避免相似視頻連續出現,新內容扶持保證流量分配的公平性,安全審核過濾違規內容。最後將排序好的視頻推送到用户端,整個過程只需要幾十毫秒以內就可以完成。
雙塔模型的代碼實現
想要實現一個簡化版的雙塔模型,可以參考以下代碼框架。
數據準備階段
# Example log data (user_id, video_id, watch_time, liked)
logs = [
("user1", "video123", 5.2, True),
("user1", "video456", 1.1, False),
("user2", "video789", 8.5, True),
]特徵存儲系統
實際生產環境中需要構建實時特徵存儲系統。用户特徵可能包括不同類別內容的觀看統計、活躍時段分佈等。視頻特徵則涵蓋分類標籤、互動指標聚合值等。
特徵存儲的核心是保證訓練和推理階段特徵的一致性,同時滿足低延遲的在線服務需求。
模型訓練
雙塔模型採用對比學習的訓練方式。正樣本來自真實的用户-視頻交互記錄,負樣本則通過隨機採樣生成。訓練目標是讓正樣本對應的用户向量和視頻向量儘可能接近,負樣本對應的向量儘可能遠離。
常用的損失函數包括 InfoNCE,配合 in-batch negatives 策略能夠有效提升訓練效率。
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Embedding, Dot
# User Tower
user_input = Input(shape=(1,), name="user_id")
user_embedding = Embedding(num_users, 64)(user_input)
user_vec = Dense(32, activation="relu")(user_embedding)
# Item Tower
item_input = Input(shape=(1,), name="item_id")
item_embedding = Embedding(num_items, 64)(item_input)
item_vec = Dense(32, activation="relu")(item_embedding)
# Dot Product (Interaction)
dot_product = Dot(axes=1)([user_vec, item_vec])
model = tf.keras.Model(inputs=[user_input, item_input], outputs=dot_product)
model.compile(optimizer="adam", loss="binary_crossentropy")
model.fit([user_ids, item_ids], labels, epochs=10)向量索引構建
模型訓練完成後,需要為所有視頻預計算向量表示,並構建 ANN 索引以支持快速檢索。
import faiss
# Store all item embeddings in Faiss for fast search
item_embeddings = model.get_layer("item_embedding").get_weights()[0]
index = faiss.IndexFlatIP(32) # Inner Product search
index.add(item_embeddings)
# Get recommendations for a user
user_embedding = user_model.predict(["user123"])
_, recommended_ids = index.search(user_embedding, k=10) # Top 10 videos線上服務部署
生產環境的推薦服務需要處理實時用户請求。系統接收用户特徵後,調用用户塔計算向量表示,然後查詢 ANN 索引獲取候選集,最後經過排序模型輸出最終推薦結果。
整個鏈路的延遲控制是關鍵指標,通常要求在 100 毫秒以內完成。
import tensorflow as tf
# A simple two-tower model using user IDs and item IDs
class TwoTowerModel(tf.keras.Model):
def __init__(self, user_vocab_size, item_vocab_size, embed_dim):
super().__init__()
# Embedding layers for users and items (learnable lookup tables)
self.user_embedding = tf.keras.layers.Embedding(input_dim=user_vocab_size, output_dim=embed_dim)
self.item_embedding = tf.keras.layers.Embedding(input_dim=item_vocab_size, output_dim=embed_dim)
def call(self, inputs):
user_id, item_id = inputs # expecting user and item IDs as inputs
# Get embeddings for user and item
user_vec = self.user_embedding(user_id) # shape: [batch_size, embed_dim]
item_vec = self.item_embedding(item_id) # shape: [batch_size, embed_dim]
# Compute dot product similarity (and squeeze to 1D)
score = tf.reduce_sum(user_vec * item_vec, axis=1)
return score
# Example usage:
model = TwoTowerModel(user_vocab_size=10000, item_vocab_size=50000, embed_dim=32)
user_ids = tf.constant([123]) # a sample user ID
item_ids = tf.constant([456]) # a sample item ID
predicted_score = model((user_ids, item_ids)).numpy()
print("Predicted score:", predicted_score)工程實踐中的核心挑戰
冷啓動問題是推薦系統的經典難題。新用户缺乏歷史行為數據,新視頻沒有互動反饋,這時需要依賴內容特徵和一些啓發式規則來進行推薦。
流行度偏差同樣需要重點關注。熱門內容容易獲得更多曝光,形成馬太效應。平衡熱門內容和長尾內容的分發比例,關係到內容生態的健康發展。
特徵一致性在工程實踐中經常被忽視。離線訓練和在線推理使用的特徵定義必須嚴格一致,否則會導致模型效果大幅下降。
效果評估體系
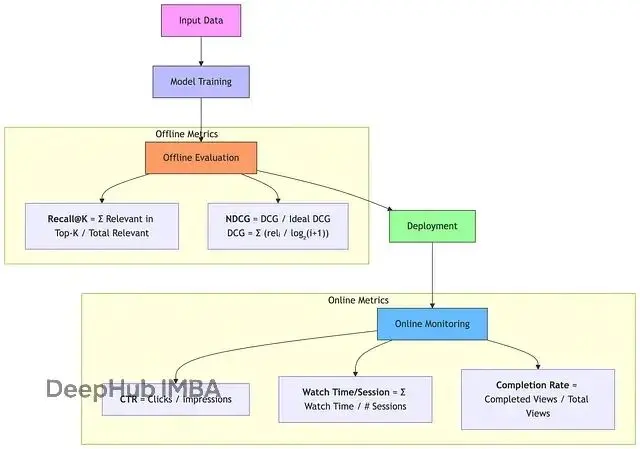
推薦系統的評估需要結合在線和離線指標。
在線指標主要關注用户實際行為:點擊率(CTR)、觀看時長、完播率、互動率等。這些指標直接反映推薦效果對用户體驗的影響。
離線指標則用於模型開發階段的快速評估:召回率@K 衡量候選召回的質量,NDCG 評估排序效果,AUC 反映分類性能等。

雙塔架構的核心優勢
短視頻推薦對響應速度要求極高,用户不會為了等待推薦結果而忍受幾秒鐘的加載時間。
雙塔架構在這方面表現出色:向量可以離線預計算,大幅減少在線計算開銷;架構簡單清晰,容易做水平擴展;能夠自然地融合協同過濾和內容過濾的優勢。
相比於複雜的深度模型,雙塔系統在保證效果的同時更易於工程實現和維護。

短視頻推薦效果看似神奇,實際上是大量工程優化和算法創新的結果。
整個系統的核心邏輯其實不復雜:把用户偏好和內容特徵都編碼成向量,然後在高維空間中進行相似度匹配。難點在於如何設計特徵、如何訓練模型、如何優化工程性能。
用户塔將觀看歷史、互動行為、時間上下文等信息壓縮為 256 維向量,例如
[0.2, -0.7, ..., 0.4]。
視頻塔將內容元數據、音頻特徵、創作者信息等編碼為同樣維度的向量,例如
[-0.1, 0.5, ..., 0.3]。
實時匹配通過餘弦相似度計算用户向量和視頻向量的匹配程度,使用 FAISS 等工具實現毫秒級的近似最近鄰檢索,找出最相關的 50 條候選視頻。
最終的推薦列表還會根據時效性、多樣性等業務規則進行調整,確保在 10 毫秒內完成整個推薦流程。
總結
我們上面這只是推薦系統的基礎架構。真正的產品化還需要考慮更多細節:多目標優化、實時反饋、AB 測試、內容安全等等。但雙塔模型為這些複雜需求提供了一個穩定可靠的技術基礎。
完整代碼:
https://avoid.overfit.cn/post/8a6c8f94d2764cc9bdf9e7fc781e09f5
作者:Prem Vishnoi